
倒排索引架構
在廣告系統中倒排索引起著至關重要的作用,當請求過來時,需要根據定向信息從倒排索引中匹配合適的廣告。我們的倒排索引采用的是ElasticSearch(后面簡稱ES),考慮點是社區活躍,相關采集、可視化、監控以及報警等組件比較完善,同時ES基于JAVA開發,所以調優和二次開發相對方便
先看下我們的倒排索引的架構圖
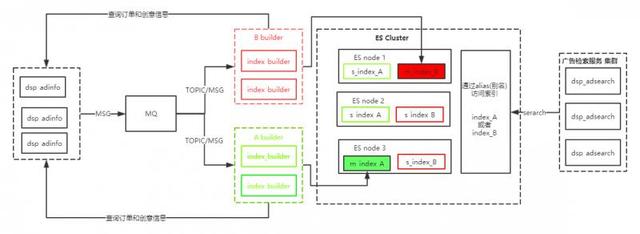
這個架構設計成如上圖這樣,經過了下面的思考與迭代
索引問題與優化
單點與穩定性問題
采用多節點部署
其中 A builder和 B builder都是兩個節點,一個主和一個備,他們通過爭搶鎖(用zookeeper實現)來決定誰是主
多個節點會帶來數據不一致問題
- 多生產者多消費者產生消息時序問題
把消息設置成無狀態的

查詢數據庫獲取最新數據(訂單和創意更新頻率低,所以對數據庫壓力不大)
- 因為出異常導致數據不一致
采用重試(冪等)和定時任務處理異常
- 全量更新索引,影響線上索引查詢功能
采用主備索引
主備索引切換流程:更新備用索引->驗證備用索引->主備切換->更新主索引

索引查詢與重建索引問題與優化
壓測ES QPS不高、CPU負載高、YGC頻繁、索引重建索引耗時長
我們分別從查詢和重建兩個方向來看
查詢
- 1s一次YGC,STW約10ms,對低延遲系統影響較大
調整 -Xmn 3g->7g,調整后10s一次YGC,STW約12ms
調整前YGC頻繁,對低延遲系統影響較大,所以想增大YGC的時間間隔,降低性能抖動,考慮到YGC采用復制算法,每次垃圾回收時間主要包括掃描年輕代存活對象和復制存活對象,掃描對象的成本遠低于復制對象,所以YGC的時間主要取決于存活對象的數量,在對象生命周期沒有較大變化的情況下,YGC的時間自然不會有較大變化
調整后,YGC的時間間隔有了很大改善,GC時間并沒有線性增加
- 調整分片數和副本數,減少線程損耗、較少IO
ES默認分片數是5,默認條件下,索引會被分配到不同的節點,這樣每個節點只有部分索引,會導致一次請求需要合并多個節點的數據,IO數多
如圖所示,假設有3個節點,2個主分片,每個分片有一個副本。當一次查詢過來的時候
查詢流程大致為:首先是node3收到請求,它可能會把請求轉發到node2的R0或node1的P0,然后完成檢索后把數據匯集到node3,最后返回。其中每個索引的內部,數據會保存到多個segment中,而對segment的查詢是串行的

而我們的場景是請求量大,索引小(100M以內),所以把主分片調整為1,副本調整為節點數-1,這樣能保證每個節點都存儲所有索引,這樣只會有一次io操作,如下圖所示

- ES(lucencu) 串行讀取所有segment
索引更新會使segment數量增加,es對segment的查詢是串行的,所以我們采用每分鐘定時用 _forcemerge將segment降為1
- 熱點方法排查發現JSON反序列化占50%cpu
禁用source只采用field存儲必要字段
- 指定查詢偏向本機節點
設置preference:_local
重建
- 全量重建前關閉從分片,禁用實時索引
replicas:0 refresh_interval:-1
減少索引在重建過程中索引同步帶來的消耗
- 批量重建索引
使用 bulk批量重建索引,提高建索引的性能
后記
我們采用的方案,有些并不符合業界常用和推薦的方式,但是符合我們自己的業務,所以方案一定要適合自己團隊的業務,沒有最好的方案,只有更適合的方案





