
如何示例 Excel 數據
我們以Python Pandas數據加載類型表格為例,演示Python Pandas Excel操作。

本文將使用Pandas中 read_excel 函數來讀取 Excel 文件,并存儲成DataFrame格式,本文將介紹如何使用 iloc 、loc 方法獲取 DataFrame中對應的數據,實現Execl數據的獲取。
read_excel的主要參數
- io: excel文檔路徑。
- sheetname : 讀取的excel指定的sheet頁,若多個則為列表。
- header :設置讀取的excel第一行是否作為列名稱。
- skiprows:省略指定行數的數據。
- skip_footer:省略從尾部數的int行數據。
- index_col:設置讀取的excel第一列是否作為行名稱。
- names:設置每列的名稱,數組形式參數。
- usecols:讀取指定的列, 也可以通過名字或索引值。
讀取Excel文件
根據上述參數介紹,我們通過指定表單名和指定列的方式來讀取文件
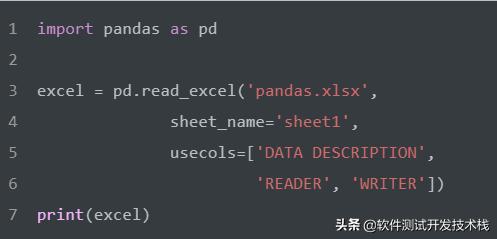
如下,我們可以看到讀取的Excel數據類型為DataFrame類型:

使用 iloc 從DataFrame中篩選數據
iloc 語法
data.iloc[<row selection>, <column selection>]
iloc 在Pandas中是用來通過數字來選擇數據中具體的某些行和列。可以設想每一行都有一個對應的下標(0,1,2,...),通過 iloc 我們可以利用這些下標去選擇對應的行數據。同理,對于行也一樣,通過這些下標也可以選擇對應的列數據。
需要注意的是0表示第一行,但不包含表頭。
選擇單行或單列
選擇數據中的第一行。

選擇數據中的最后一行。

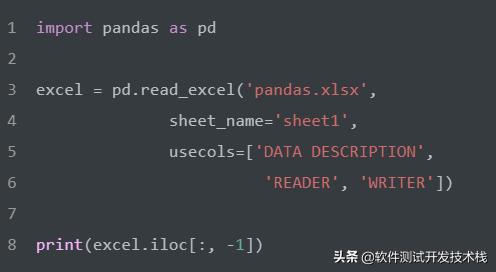
選擇數據中的第一列。

選擇數據中的最后一列。
行列混合選擇
選擇數據中的第 1-3 行的所有列。

選擇數據中的前2列的所有行。

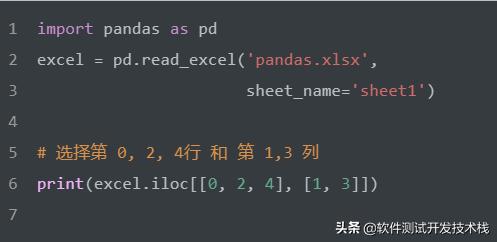
選擇第 0, 2, 4行 和 第 1,3 列。
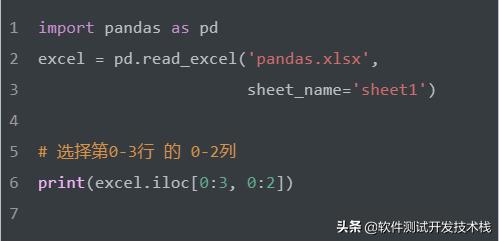
選擇第0 到 第3行 的 第0 到第2列。
使用 iloc 僅選擇了單獨的一行或一列,返回的數據為 Series 類型。若選擇了多行數據則會返回 DataFrame 類型,若只選擇了一行,但需要要返回 DataFrame 類型,可以傳入一個單值列表,如[1],如下:

使用 loc 從DataFrame中篩選數據
data.loc[<row selection>, <column selection>]
ioc 用于以下兩種場景:
- 使用 下標 查找
- 使用 條件 查找
使用 下標 查找
選擇數據中的第一行。
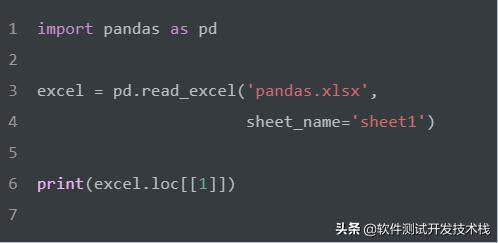
選擇數據中的前二行。

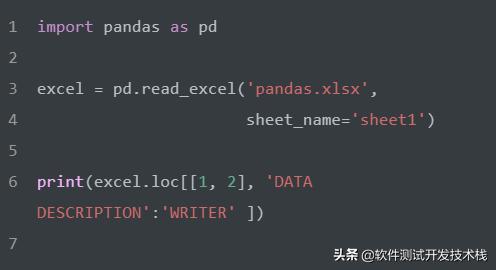
選擇第1到3行的 READER、WRITER列。

選擇第1、2行的 DATA DESCRIPTION 到 WRITER列。
需要注意 excel.loc[[1]] 不等價于 excel.iloc[[1]] ,前者是選擇索引為1的行,而后者是選擇第1行,DataFrame的索引可以是數字或者是字符串。
使用邏輯判斷選擇數據
選擇WRITER列等于to_json的 DATA DESCRIPTION列到 WRITER列。

同樣,如果只選擇了某一列,返回的數據是 Series 類型,若只選擇了一行,但需要要返回 DataFrame 類型,可以傳入一個單值列表,如[1]。
選擇 READER的值中是以 "read" 開頭的行的所有列。

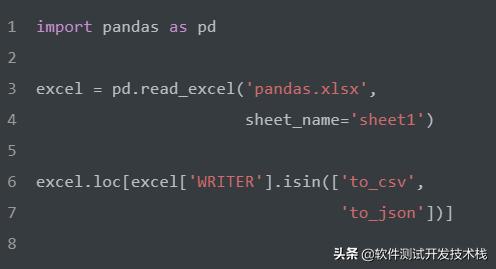
選擇"WRITER" 等于['to_csv', 'to_json']值的行。
選擇READER = 'read_csv' 并且 READER 是以 "read"開頭的行。

利用Apply的lambda函數判斷符合條件的行,如下選擇READER由“_”鏈接的行的所有列。

利用apply的lambda函數判斷符合條件的行的'DATA DESCRIPTION', 'READER' 列。

Pandas中 apply、 applymap、 map 的區別
- map僅是Series中的函數 ,map將函數應用于Series中的每一個元素。
- apply和applymap是僅是DataFrame 中的函數。
- apply 將函數作用于DataFrame中的每一個行或者列。
- applymap將函數作用于DataFrame中的每一個元素。





