
從回歸到SVM再到XGBoost的模型匯總

> Created by katemangostar — www.freepik.com
在準備任何面試時,我想共享一個資源,為每個機器學習模型提供簡要的說明。 它們的含義并不廣泛,相反。 希望通過閱讀本文,您將了解如何以簡單的方式交流復(fù)雜的模型。
涵蓋類型
· 線性回歸
· 嶺回歸
· 套索回歸
· 邏輯回歸
· K最近的鄰居
· 樸素貝葉斯
· 支持向量機
· 決策樹
· 隨機森林
· AdaBoost
· 梯度提升
· XGBoost
線性回歸
線性回歸涉及使用最小二乘法找到代表數(shù)據(jù)集的"最佳擬合線"。 最小二乘方法涉及找到一個線性方程,該方程使殘差平方和最小。 殘差等于實際負預(yù)測值。
舉個例子,紅線比綠線是最適合的更好的線,因為它離點更近,因此殘差較小。

> Image created by Author
嶺回歸
Ridge回歸,也稱為L2正則化,是一種引入少量偏差以減少過度擬合的回歸技術(shù)。 它通過最小化殘差平方和加罰分來實現(xiàn),罰分等于λ乘以斜率平方。 Lambda是指罰分的嚴重性。


> Image Created by Author
如果沒有罰分,則最佳擬合線的斜率會變陡,這意味著它對X的細微變化更敏感。通過引入罰分,最佳擬合線對X的細微變化變得較不敏感。 背后的嶺回歸。
套索回歸
套索回歸,也稱為L1正則化,與Ridge回歸相似。 唯一的區(qū)別是,罰分是使用斜率的絕對值計算的。
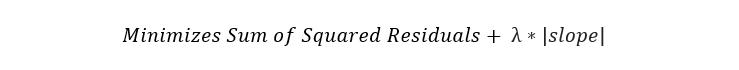
邏輯回歸
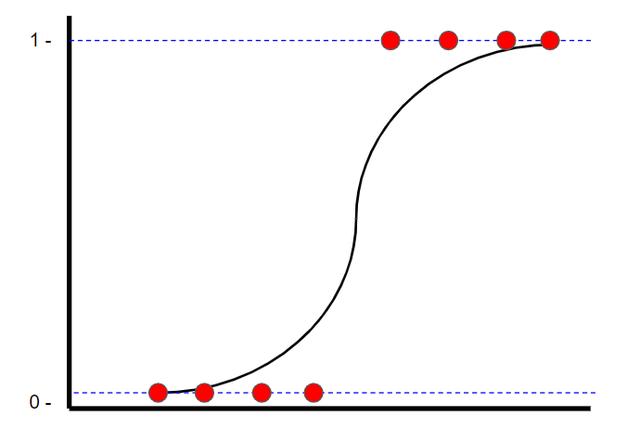
Logistic回歸是一種分類技術(shù),也可以找到"最合適的直線"。 但是,與線性回歸不同的是,線性回歸使用最小二乘方找到最佳擬合線,邏輯回歸使用最大似然法找到最佳擬合線(邏輯曲線)。 這樣做是因為y值只能是1或0。 觀看StatQuest的視頻,了解如何計算最大可能性。
> Image Created by Author
K最近鄰居
> Image Created by Author
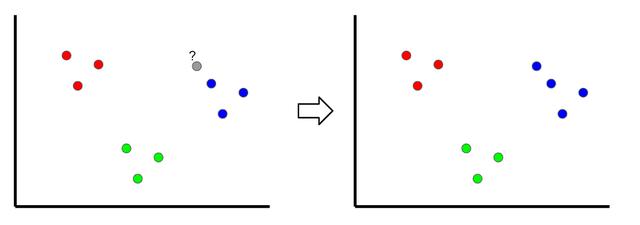
K最近鄰居是一種分類技術(shù),通過查看最近的分類點對新樣本進行分類,因此稱為" K最近"。 在上面的示例中,如果k = 1,則未分類的點將被分類為藍點。
如果k的值太低,則可能會出現(xiàn)異常值。 但是,如果它太高,可能會忽略只有幾個樣本的類。
樸素貝葉斯
樸素貝葉斯分類器是一種受貝葉斯定理啟發(fā)的分類技術(shù),其陳述以下等式:

由于樸素的假設(shè)(因此得名),變量在給定類的情況下是獨立的,因此可以如下重寫P(X | y):
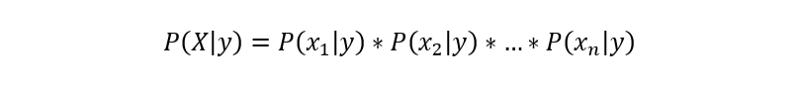
另外,由于我們要求解y,所以P(X)是一個常數(shù),這意味著我們可以從方程中將其刪除并引入比例。
因此,將每個y值的概率計算為給定y時xn的條件概率的乘積。
支持向量機
支持向量機是一種分類技術(shù),可找到稱為超平面的最佳邊界,該邊界用于分隔不同的類別。 通過最大化類之間的余量來找到超平面。

> Image Created by Author
決策樹

決策樹本質(zhì)上是一系列條件語句,這些條件語句確定樣本到達底部之前所采取的路徑。 它們直觀且易于構(gòu)建,但往往不準確。
隨機森林
隨機森林是一種集成技術(shù),這意味著它將多個模型組合為一個模型以提高其預(yù)測能力。 具體來說,它使用自舉數(shù)據(jù)集和變量的隨機子集(也稱為裝袋)構(gòu)建了數(shù)千個較小的決策樹。 擁有1000棵較小的決策樹,隨機森林使用"多數(shù)獲勝"模型來確定目標變量的值。

例如,如果我們創(chuàng)建一個決策樹,第三個決策樹,它將預(yù)測0。但是,如果我們依靠所有4個決策樹的模式,則預(yù)測值為1。這就是隨機森林的力量。
AdaBoost
AdaBoost是一種增強算法,類似于"隨機森林",但有兩個重要區(qū)別:
· AdaBoost通常不是由樹木組成,而是由樹樁組成的森林(樹樁是只有一個節(jié)點和兩片葉子的樹)。
· 每個樹樁的決定在最終決定中的權(quán)重不同。 總誤差較小(準確度較高)的樹樁具有較高的發(fā)言權(quán)。
· 創(chuàng)建樹樁的順序很重要,因為每個后續(xù)樹樁都強調(diào)了在前一個樹樁中未正確分類的樣本的重要性。
梯度提升
Gradient Boost與AdaBoost類似,因為它可以構(gòu)建多棵樹,其中每棵樹都是從前一棵樹構(gòu)建的。 與AdaBoost可以構(gòu)建樹樁不同,Gradient Boost可以構(gòu)建通常具有8至32片葉子的樹木。
更重要的是,Gradient與AdaBoost的不同之處在于構(gòu)建決策樹的方式。 梯度提升從初始預(yù)測開始,通常是平均值。 然后,基于樣本的殘差構(gòu)建決策樹。 通過采用初始預(yù)測+學習率乘以殘差樹的結(jié)果來進行新的預(yù)測,然后重復(fù)該過程。
XGBoost
XGBoost本質(zhì)上與Gradient Boost相同,但是主要區(qū)別在于殘差樹的構(gòu)建方式。 使用XGBoost,可以通過計算葉子與前面的節(jié)點之間的相似性得分來確定殘差樹,以確定哪些變量用作根和節(jié)點。
謝謝閱讀!
希望在閱讀完本文后,您將通過突出重點了解一下如何總結(jié)各種機器學習模型。 同樣,這并不意味著要深入解釋每篇文章的復(fù)雜性。 根據(jù)上面的總結(jié),請隨意學習所有不完全有意義的模型!
特倫斯·辛
ShinTwin的創(chuàng)始人| 讓我們在LinkedIn上建立聯(lián)系| 項目組合在這里。
(本文翻譯自Terence S的文章《How to Explain Each machine Learning Model at an Interview》,參考:
https://towardsdatascience.com/how-to-explain-each-machine-learning-model-at-an-interview-499d82f91470)





