
一個優秀的數據分析師,除了要掌握基本的統計學、數據庫、數據分析方法、思維、數據分析工具技能之外,還需要掌握一些數據挖掘的思想,幫助我們挖掘出有價值的數據,這也是數據分析專家和一般數據分析師的差距之一。
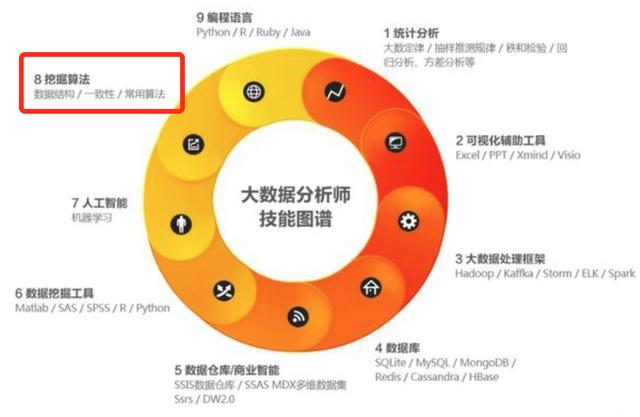
數據挖掘主要分為分類算法,聚類算法和關聯規則三大類,這三類基本上涵蓋了目前商業市場對算法的所有需求。而這三類里又包含許多經典算法。市面上很多關于數據挖掘算法的介紹深奧難懂,今天就給大家用簡單的大白話來介紹數據挖掘十大經典算法原理,幫助大家快速理解。
算法分類
連接分析:PageRank
關聯分析:Apriori
分類算法:C4.5,樸素貝葉斯,SVM,KNN,Adaboost,CART
聚類算法:K-Means,EM
一、PageRank
當一篇論文被引用的次數越多,證明這篇論文的影響力越大。
一個網頁的入口越多,入鏈越優質,網頁的質量越高。
原理
網頁影響力=阻尼影響力+所有入鏈集合頁面的加權影響力之和
- 一個網頁的影響力:所有入鏈的頁面的加權影響力之和。
- 一個網頁對其他網頁的影響力貢獻為:自身影響力/出鏈數量。
- 用戶并不都是按照跳轉鏈接的方式來上網,還有其他的方式,比如直接輸入網址訪問。
- 所以需要設定阻尼因子,代表了用戶按照跳轉鏈接來上網的概率。
比喻說明
1、微博
一個人的微博粉絲數不一定等于他的實際影響力,還需要看粉絲的質量如何。
如果是僵尸粉沒什么用,但如果是很多大V或者明星關注,影響力很高。
2、店鋪的經營
顧客比較多的店鋪質量比較好,但是要看看顧客是不是托。
3、興趣
在感興趣的人或事身上投入了相對多的時間,對其相關的人事物也會投入一定的時間。那個人或事,被關注的越多,它的影響力/受眾也就越大。
關于阻尼因子
1、通過你的鄰居的影響力來評判你的影響力,但是如果不能通過鄰居來訪問你,并不代表你沒有影響力,因為可以直接訪問你,所以引入阻尼因子的概念。
2、海洋除了有河流流經,還有雨水,但是下雨是隨機的。
3、提出阻尼系數,還是為了解決某些網站明明存在大量出鏈(入鏈),但是影響力卻非常大的情形。
- 出鏈例子:hao123導航網頁,出鏈極多入鏈極少。
- 入鏈例子:百度谷歌等搜索引擎,入鏈極多出鏈極少。
二、Apriori(關聯分析)
關聯關系挖掘,從消費者交易記錄中發掘商品與商品之間的關聯關系。
原理
1.支持度
某個商品組合出現的次數與總次數之間的比例。
5次購買,4次買了牛奶,牛奶的支持度為4/5=0.8。
5次購買,3次買了牛奶+面包,牛奶+面包的支持度為3/5=0.6。
2.置信度
購買了商品A,有多大概率購買商品B,A發生的情況下B發生的概率是多少。
買了4次牛奶,其中2次買了啤酒,(牛奶->啤酒)的置信度為2/4=0.5。
買了3次啤酒,其中2次買了牛奶,(啤酒->牛奶)的置信度為2/3-0.67。
3.提升度
衡量商品A的出現,對商品B的出現 概率提升的程度。
提升度(A->B)=置信度(A->B)/支持度(B)。
提升度>1,有提升;提升度=1,無變化;提升度<1,下降。
4.頻繁項集
項集:可以是單個商品,也可以是商品組合。
頻繁項集是支持度大于最小支持度(Min Support)的項集。
計算過程
1、從K=1開始,篩選頻繁項集。
2、在結果中,組合K+1項集,再次篩選。
3、循環1,2步。直到找不到結果為止,K-1項集的結果就是最終結果。
擴展:FP-Growth 算法
Apriori 算法需要多次掃描數據庫,性能低下,不適合大數據量。
FP-growth算法,通過構建 FP 樹的數據結構,將數據存儲在 FP 樹中,只需要在構建 FP 樹時掃描數據庫兩次,后續處理就不需要再訪問數據庫了。
比喻說明:啤酒和尿不濕擺在一起銷售
沃爾瑪通過數據分析發現,美國有嬰兒的家庭中,一般是母親在家照顧孩子,父親去超市買尿不濕。
父親在購買尿不濕時,常常會順便搭配幾瓶啤酒來犒勞自己,于是,超市嘗試推出了將啤酒和尿不濕擺在一起的促銷手段,這個舉措居然使尿不濕和啤酒的銷量都大幅增加。
三、AdaBoost
原理
簡單的說,多個弱分類器訓練成為一個強分類器。
將一系列的弱分類器以不同的權重比組合作為最終分類選擇。
計算過程
1、初始化基礎權重。
2、獎權重矩陣,通過已的分類器計算錯誤率,選擇錯誤率最低的為最優分類器。
3、通過分類器權重公式,減少正確樣本分布,增加錯誤樣本分布,得到新的權重矩陣和當前k輪的分類器權重。
4、將新的權重矩陣,帶入上面的步驟2和3,重新計算權重矩陣。
5、迭代N輪,記錄每一輪的最終分類器權重,得到強分類器。
比喻說明
1、利用錯題提升學習效率
做正確的題,下次少做點,反正都會了。
做錯的題,下次多做點,集中在錯題上。
隨著學習的深入,做錯的題會越來越少。
2、合理跨界提高盈利
蘋果公司,軟硬結合,占據了大部分的手機市場利潤,兩個領域的知識結合起來產生新收益。
四、C4.5(決策樹)
決策就是對于一個問題,有多個答案,選擇答案的過程就是決策。
C4.5算法是用于產生決策樹的算法,主要用于分類。
C4.5使用信息增益率做計算(ID3算法使用信息增益做計算)。
原理
C4.5選擇最有效的方式對樣本集進行分裂,分裂規則是分析所有屬性的信息增益率。
信息增益率越大,意味著這個特征分類的能力越強,我們就要優先選擇這個特征做分類。
比喻說明:挑西瓜。
拿到一個西瓜,先判斷它的紋路,如果很模糊,就認為這不是好瓜,如果它清晰,就認為它是一個好瓜,如果它稍稍模糊,就考慮它的密度,密度大于某個值,就認為它是好瓜,否則就是壞瓜。
五、CART(決策樹)
CART:Classification And Regression Tree,中文叫分類回歸樹,即可以做分類也可以做回歸。
什么是分類樹、回歸樹?
分類樹:處理離散數據,也就是數據種類有限的數據,輸出的是樣本的類別 。
回歸樹:可以對連續型的數值進行預測,輸出的是一個數值,數值在某個區間內都有取值的可能。
回歸問題和分類問題的本質一樣,都是針對一個輸入做出一個輸出預測,其區別在于輸出變量的類型。
原理
CART分類樹
與C4.5算法類似,只是屬性選擇的指標是基尼系數。
基尼系數反應了樣本的不確定度,基尼系數越小,說明樣本之間的差異性小,不確定程度低。
分類是一個不確定度降低的過程,CART在構造分類樹的時候會選擇基尼系數最小的屬性作為屬性的劃分。
CART 回歸樹
采用均方誤差或絕對值誤差為標準,選取均方誤差或絕對值誤差最小的特征。
比喻說明
分類:預測明天是陰、晴還是雨。
回歸:預測明天的氣溫是多少度。
六、樸素貝葉斯(條件概率)
樸素貝葉斯是一種簡單有效的常用分類算法,計算未知物體出現的條件下各個類別出現的概率,取概率最大的分類。
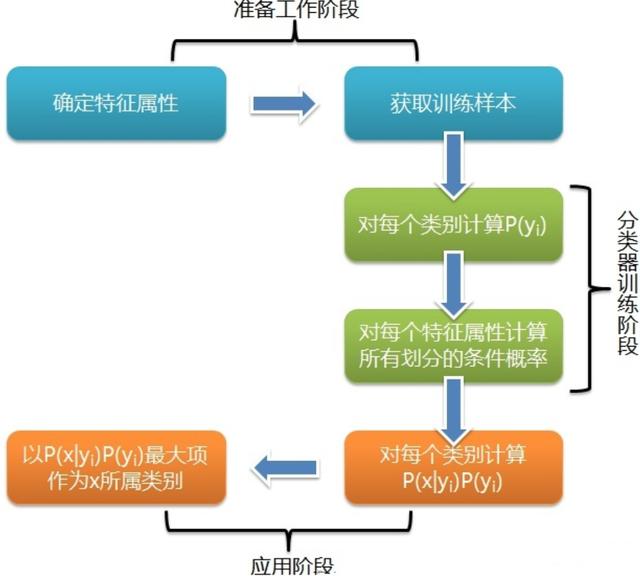
原理
假設輸入的不同特征之間是獨立的,基于概率論原理,通過先驗概率P(A)、P(B)和條件概率推算出后概率出P(A|B)。
P(A):先驗概率,即在B事件發生之前,對A事件概率的一個判斷。
P(B|A):條件概率,事件 B 在另外一個事件 A 已經發生條件下的發生概率。
P(A|B):后驗概率,即在B事件發生之后,對A事件概率的重新評估。
比喻說明:給病人分類。

給定一個新病人,是一個打噴嚏的建筑工人,計算他患感冒的概率。
七、SVM
SVM:Support Vector machine,中文名為支持向量機,是常見的一種分類方法,最初是為二分類問題設計的,在機器學習中,SVM 是有監督的學習模型。
什么是有監督學習和無監督學習 ?
有監督學習:即在已有類別標簽的情況下,將樣本數據進行分類。
無監督學習:即在無類別標簽的情況下,樣本數據根據一定的方法進行分類,即聚類,分類好的類別需要進一步分析后,從而得知每個類別的特點。
原理
找到具有最小間隔的樣本點,然后擬合出一個到這些樣本點距離和最大的線段/平面。
硬間隔:數據是線性分布的情況,直接給出分類。
軟間隔:允許一定量的樣本分類錯誤。
核函數:非線性分布的數據映射為線性分布的數據。
比喻說明
1.分隔桌上一堆紅球和籃球
用一根線將桌上的紅球和藍球分成兩部分。
2.分隔箱子里一堆紅球和籃球
用一個平面將箱子里的紅球和藍球分成兩部分。
八、KNN(聚類)
機器學習算法中最基礎、最簡單的算法之一,既能分類也能回歸,通過測量不同特征值之間的距離來進行分類。
原理
計算待分類物體與其他物體之間的距離,對于K個最近的鄰居,所占數量最多的類別,預測為該分類對象的類別。
計算步驟
1、根據場景,選取距離計算方式,計算待分類物體與其他物體之間的距離。
2、統計距離最近的K個鄰居。
3、對于K個最近的鄰居,所占數量最多的類別,預測為該分類對象的類別。
比喻說明:近朱者赤,近墨者黑。
九、K-Means(聚類)
K-means是一個聚類算法,是無監督學習,生成指定K個類,把每個對象分配給距離最近的聚類中心。
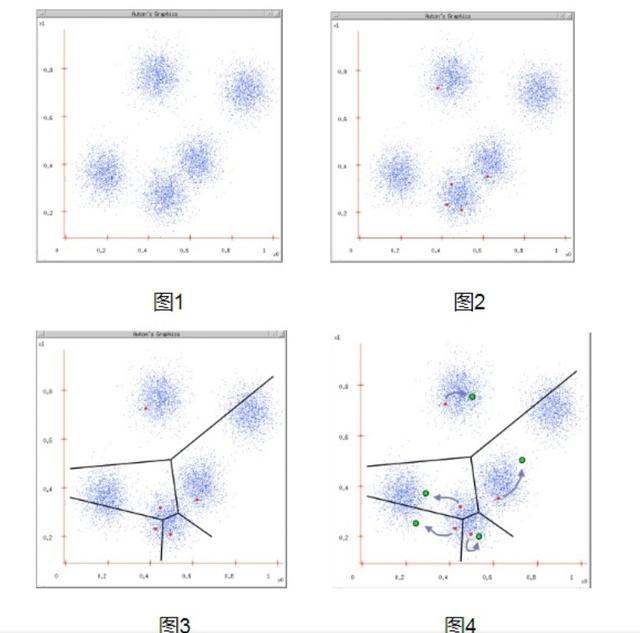
原理
1.隨機選取K個點為分類中心點。
2.將每個點分配到最近的類,這樣形成了K個類。
3.重新計算每個類的中心點。比如都屬于同一個類別里面有10個點,那么新的中心點就是這10個點的中心點,一種簡單的方式就是取平均值。
比喻說明
1.選老大
大家隨機選K個老大,誰離得近,就是那個隊列的人(計算距離,距離近的人聚合在一起)。
隨著時間的推移,老大的位置在變化(根據算法,重新計算中心點),直到選出真正的中心老大(重復,直到準確率最高)。
2.Kmeans和Knn的區別
Kmeans開班選老大,風水輪流轉,直到選出最佳中心老大。
Knn小弟加隊伍,離那個班相對近,就是那個班的。
十、EM(聚類)
EM 的英文是 Expectation Maximization,所以 EM 算法也叫最大期望算法,也是聚類算法的一種。
EM和K-Means的區別:
- EM是計算概率,KMeans是計算距離。
- EM屬于軟聚類,同一樣本可能屬于多個類別;而K-Means屬于硬聚類,一個樣本只能屬于一個類別。所以前者能夠發現一些隱藏的數據。
原理
先估計一個大概率的可能參數,然后再根據數據不斷地進行調整,直到找到最終的確認參數。
比喻說明:菜稱重。
很少有人用稱對菜進行稱重,再計算一半的分量進行平分。
大部分人的方法是:
1、先分一部分到碟子 A 中,再把剩余的分到碟子 B 中。
2、觀察碟子 A 和 B 里的菜是否一樣多,哪個多就勻一些到少的那個碟子里。
3、然后再觀察碟子 A 和 B 里的是否一樣多,重復下去,直到份量不發生變化為止。
10大算法都已經說完了,其實一般來說,常用算法都已經被封裝到庫中了,只要new出相應的模型即可。





