
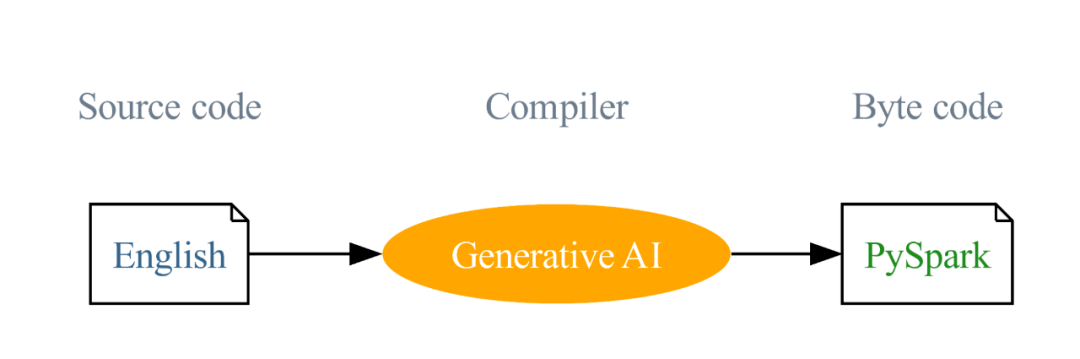
English SDK for Spark : 將英語作為一種新的編程語言,將生成式 AI 當做編譯器, 將 Python/ target=_blank class=infotextkey>Python 視作字節碼!
本文主要介紹了 Apache Spark 的英語軟件開發套件(SDK)的重要性和目標,以及它采用生成式 AI 技術來豐富Spark 的使用體驗。它還提到了Github Copilot 對 AI 輔助代碼開發的影響,以及其存在的限制和問題。本文還紹了英語 SDK 的特性,包括數據獲取、DataFrame 操作、自定義函數(UDFs)和緩存等。最后,鼓勵讀者積極參與英語 SDK 的開發和探索,為擴大 Apache Spark 的影響力貢獻一份力量。
原文鏈接:https://www.databricks.com/blog/introducing-english-new-programming-language-apache-spark
作者 | Gengliang Wang,Xiangrui Meng,Reynold Xin,Allison Wang,Amanda Liu和Denny Lee
譯者 | 明明如月
責編 | 夏萌
出品 | CSDN(ID:CSDNnews)
導言
我們非常激動地向大家介紹 Apache Spark 的英語軟件開發套件(SDK)。這是一個革命性的工具,旨在豐富你的 Spark 使用體驗。Apache Spark™ 在全球范圍內,覆蓋 208 個國家和地區,年下載量超過 10 億次,已經在大規模數據分析領域取得了顯著成績。我們的英語 SDK 采用先進的生成型 AI 技術,旨在擴大這個活躍的社區,使 Spark 在易用性和親和度上達到前所未有的高度!
緣起
GitHub Copilot 對 AI 輔助的代碼開發領域產生了深遠的影響。雖然它功能強大,但用戶需要理解生成的代碼后才能提交。同時,審查者也需要理解代碼才能進行審查。這可能會限制其廣泛應用的一大阻礙。當處理 Spark 表和 DataFrames 時,它偶爾也會生成不正確或不符合預期的代碼。下面的 GIF 動圖展示了這一點,Copilot 提出了一個窗口規范,并引用了不存在的dept_id列,這需要一些專業知識才能理解。

與其將 AI 視為副駕駛,為何不讓 AI 當做司機,我們坐在豪華的后座享受呢?這就是我們英語 SDK 所要扮演的角色。我們發現,尖端的大型語言模型對 Spark 非常了解,這得益于優秀的 Spark 社區,他們在過去十年中,貢獻了大量的開放的、高質量的內容,比如 API 文檔、開源項目、問題和答案、教程和書籍等。現在,我們將這些生成型 AI 對 Spark 的專業知識融入到英文 SDK 中。你不再需要理解復雜的生成代碼,只需用簡單的英文指令即可得到結果:
transformed_df = df.ai.transform('get 4 week moving average sales by dept')英語 SDK 通過理解 Spark 表和 DataFrames 來處理復雜性,并直接返回一個正確的 DataFrame !
我們的愿景是:將英文作為一種編程語言,并使用生成式 AI 將這些英文指令編譯成 PySpark 和 SQL 代碼。這種創新的方式旨在降低編程的門檻和簡化學習曲線。這個愿景是推動英文 SDK 的主要驅動力,我們的目標是擴大 Spark 的影響力,讓 Spark 從一個成功走向另一個成功。
英語 SDK 的特性
英語 SDK 通過實現以下關鍵特性,使 Spark 的開發過程變得更簡單:
-
數據獲取:根據你的描述,SDK 可以進行網絡搜索,運用大型語言模型 (LLM) 確定最佳結果,然后順利地將選定的網絡數據集成到 Spark 中,這些操作都能在一個步驟中完成。
-
DataFrame 操作:SDK 對指定的 DataFrame 提供了功能,根據你的英文描述執行轉換、繪圖和解釋操作。這些功能大大提升了代碼的可讀性和效率,使得對 DataFrames 的操作更加直接和直觀。
-
自定義函數 (UDFs):SDK 提供了簡潔的創建 UDFs 的流程。你只需要提供一段描述,AI 就可以負責代碼的補全。這一特性簡化了 UDF 的創建過程,讓你可以專注于函數定義,而 AI 則會處理其余部分。
-
緩存:SDK 吸取了緩存的優點以提升執行速度,保證結果的可復用性,并節省成本。
示例
為了進一步說明如何使用英語 SDK,我們將通過一些例子進行演示:
數據獲取
如果你是一名數據科學家,需要導入2022年美國全國汽車銷售數據,您只需要兩行代碼即可完成:
spark_ai = SparkAI auto_df = spark_ai.create_df("2022 USA national auto sales by brand")DataFrame 操作
對于給定的 DataFrame 對象,SDK 允許你運行以 df.ai 開頭的方法。這包括轉換、繪圖、DataFrame 解釋等等。
要激活 PySpark DataFrame 的部分函數:
spark_ai.activate要預覽 auto_df:
auto_df.ai.plot要查看各汽車公司的市場份額分布:
auto_df.ai.plot("pie chart for US sales market shares, show the top 5 brands and the sum of others")要獲取增長最快的品牌:
???????auto_top_growth_df=auto_df.ai.transform("top brand with the highest growth") auto_top_growth_df.show要獲取 DataFrame 的解釋:
auto_top_growth_df.ai.explain總的來說,這個 DataFrame 正在查找銷售增長最快的品牌。它將結果按銷售增長率降序排列,并僅返回增長最快的結果。
自定義函數 (UDFs) SDK
支持通過簡單而清晰的方式創建自定義函數。使用@spark_ai.udf裝飾器,你只需定義一個帶有文檔字符串的函數,SDK 就會在后臺自動完成代碼生成:
???????@spark_ai.udf def convert_grades(grade_percent: float) -> str: """Convert the grade percent to a letter grade using standard cutoffs""" ...現在,你可以在 SQL 查詢或 DataFrames 中使用這個自定義函數(UDF)
SELECT student_id, convert_grades(grade_percent) FROM grade總結
Apache Spark 的英語 SDK 是一個既簡潔又強大的工具,能夠顯著提升你的開發效率。它的目標是簡化復雜的任務,減少必需的代碼量,使你可以專注于從數據中挖掘洞察。
雖然英語 SDK 還處于早期的開發階段,但未來可期。我們鼓勵你去嘗試這個創新的工具,親身感受其帶來的便利,并考慮為此項目貢獻自己的一份力量。不要在這場革命中袖手旁觀,而應該積極參與其中。現在就去 pyspark.ai 上探索和體驗英語 SDK 的強大功能吧。你的參與和洞見,將為擴大 Apache Spark 的影響力做出重要貢獻。





