
特斯拉渴望成為世界領(lǐng)先的人工智能公司之一。迄今為止,他們還沒有部署最先進(jìn)的自動駕駛技術(shù);這一榮譽(yù)適用于 Alphabet 的 Waymo 。此外,在生成式人工智能世界中,特斯拉也不見蹤影。話雖如此,由于數(shù)據(jù)收集優(yōu)勢、專業(yè)計算、創(chuàng)新文化和領(lǐng)先的人工智能研究人員,他們可能擁有在自動駕駛汽車和機(jī)器人技術(shù)領(lǐng)域?qū)崿F(xiàn)跨越式發(fā)展的秘訣。
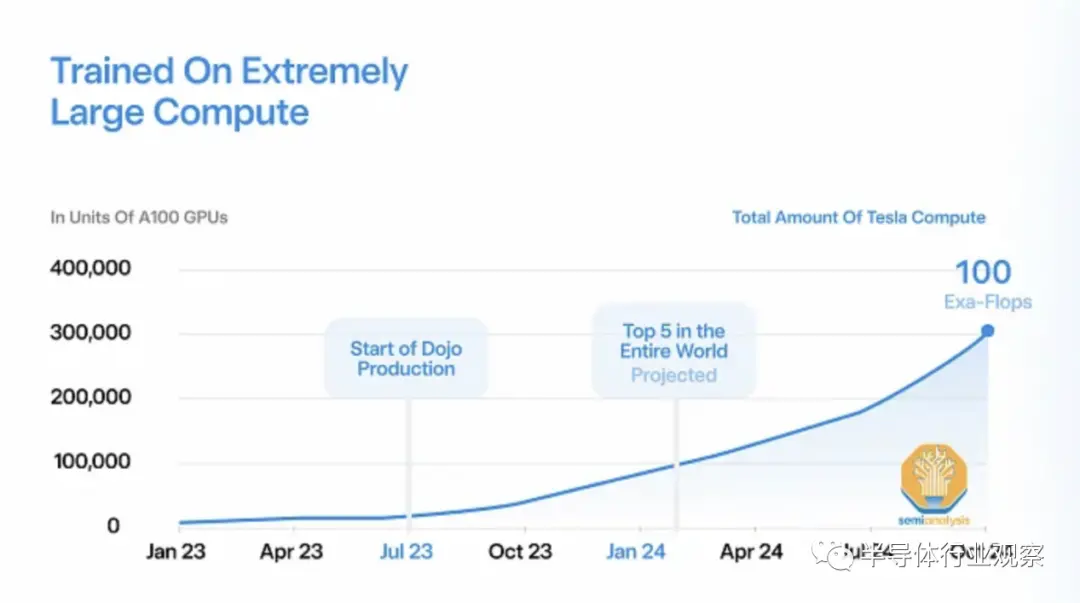
特斯拉目前擁有非常少量的內(nèi)部人工智能基礎(chǔ)設(shè)施,只有約 4000 個 V100 和約 16000 個 A100。與世界上其他大型科技公司相比,這個數(shù)字非常小,因為 Microsoft 和 Meta 等公司擁有超過 10 萬個 GPU,而且他們希望在中短期內(nèi)將這個數(shù)字翻倍。特斯拉人工智能基礎(chǔ)設(shè)施薄弱的部分原因是其內(nèi)部 D1 訓(xùn)練芯片多次延遲。
現(xiàn)在故事正在發(fā)生變化,而且變化很快。
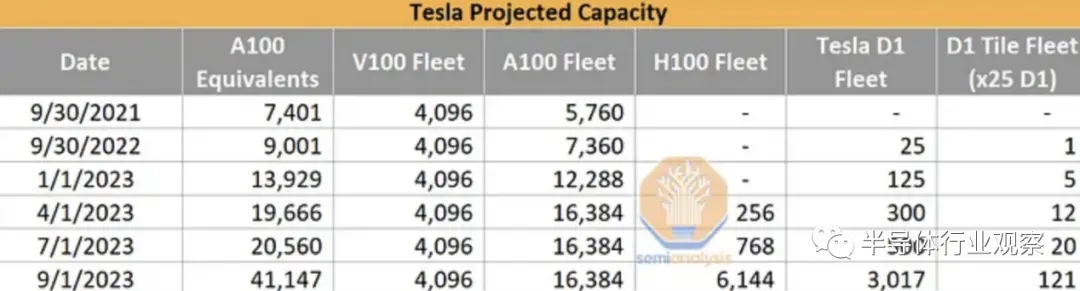
Tesla 正在將其 AI 能力在 1.5 年內(nèi)大幅提高 10 倍以上。這一部分是為了他們自己的能力,但很大一部分也是為了X.AI。今天,我們希望深入了解 Tesla 的 AI 能力、H100 和 Dojo 的季度產(chǎn)能預(yù)估,以及 Tesla 因其模型架構(gòu)、訓(xùn)練基礎(chǔ)設(shè)施和包括 HW 4.0 在內(nèi)的邊緣推理而產(chǎn)生的獨特需求。
D1訓(xùn)練芯片的故事是一個漫長而艱辛的故事。它面臨著從芯片設(shè)計到電力傳輸?shù)膯栴},但現(xiàn)在特斯拉聲稱它已經(jīng)準(zhǔn)備好成為眾人矚目的焦點并開始批量生產(chǎn)。回顧一下,特斯拉自 2016 年以來一直在為其汽車設(shè)計內(nèi)部人工智能芯片,自 2018 年以來一直為數(shù)據(jù)中心應(yīng)用設(shè)計內(nèi)部人工智能芯片。
在芯片發(fā)布之前,我們披露了他們采用的特殊封裝技術(shù)。該技術(shù)稱為 InFO SoW。為了簡單起見,可以將其視為晶圓大小的扇出封裝。這與 Cerebras 原則上所做的類似,但優(yōu)點是——允許進(jìn)行已知良好的芯片測試,這是特斯拉架構(gòu)中最獨特和最有趣的方面,因為這個 InFO-SoW 內(nèi)置了 25 個芯片,沒有直接連接內(nèi)存。
我們還在 2021 年更詳細(xì)地討論了其芯片架構(gòu)的優(yōu)缺點。此后最有趣的方面是,特斯拉必須制造另一個位于 PCIe 卡上的芯片來提供內(nèi)存連接,因為片上內(nèi)存是不夠。
特斯拉本應(yīng)在 2022 年實現(xiàn)多次產(chǎn)能提升,但由于芯片和系統(tǒng)問題而從未實現(xiàn)。現(xiàn)在已經(jīng)是 2023 年中期了,它終于開始提高產(chǎn)量了。該架構(gòu)非常適合特斯拉的獨特用例,但值得注意的是,它對于內(nèi)存帶寬嚴(yán)重瓶頸的LLM來說沒有用。
特斯拉的用例很獨特,因為它必須專注于圖像網(wǎng)絡(luò)。因此,它們的架構(gòu)差異很大。過去,我們討論了深度學(xué)習(xí)推薦網(wǎng)絡(luò)和基于 Transformer 的語言模型如何需要非常不同的架構(gòu)。圖像/視頻識別網(wǎng)絡(luò)還需要不同的計算、片上通信、片上存儲器和片外存儲器要求的組合。
這些卷積模型在訓(xùn)練期間在 GPU 上的利用率非常低。隨著 Nvidia 的下一代產(chǎn)品正在對Transformer(尤其是稀疏 MoE)進(jìn)行進(jìn)一步優(yōu)化,特斯拉對其自己的差異化優(yōu)化卷積架構(gòu)的投資應(yīng)該會取得良好的效果。這些圖像網(wǎng)絡(luò)必須符合特斯拉推理基礎(chǔ)設(shè)施的限制。
HW 4.0,特斯拉第二代 FSD 芯片
雖然訓(xùn)練芯片是由臺積電制造的,但在特斯拉電動汽車內(nèi)運行人工智能推理的芯片被稱為全自動駕駛(FSD)芯片。特斯拉的車輛型號極其有限,因為特斯拉有一個非常頑固的信念,即他們不需要汽車的巨大性能來實現(xiàn)完全自動駕駛。此外,特斯拉的成本限制比 Waymo 和 Cruise 嚴(yán)格得多,因為它們實際上出貨量很大。與此同時,Alphabet Waymo 和 GM Cruise 正在使用全尺寸 GPU,在開發(fā)和早期測試期間,其汽車成本要高出 10 倍,并且正在尋求為自己的車輛制造更快(也更昂貴)的 SoC。
特斯拉第二代芯片自 2023 年 2 月起在汽車中發(fā)貨,該芯片的設(shè)計與第一代設(shè)計非常相似。第一代基于三星 14nm 工藝,圍繞三個四核集群構(gòu)建,總共 12 個 Arm Cortex-A72 核心,運行頻率為 2.2 GHz。然而,在第二代設(shè)計中,該公司將 CPU 核心數(shù)量增加到五個集群,每集群 4 個核心 (20),總共 20 個 Cortex-A72 核心。
第二代FSD芯片最重要的部分是三個NPU核心。三個內(nèi)核各自使用 32 MiB SRAM 來存儲模型權(quán)重和激活(activations)。每個周期,256 字節(jié)的激活數(shù)據(jù)和 128 字節(jié)的權(quán)重數(shù)據(jù)從 SRAM 讀取到乘法累加單元 (MAC)。MAC 設(shè)計為網(wǎng)格,每個 NPU 核心具有 96x96 網(wǎng)格,每個時鐘周期總共有 9,216 個 MAC 和 18,432 次操作。每個芯片有 3 個 NPU,運行頻率為 2.2 GHz,總計算能力為每秒 121.651 萬億次操作 (TOPS)。
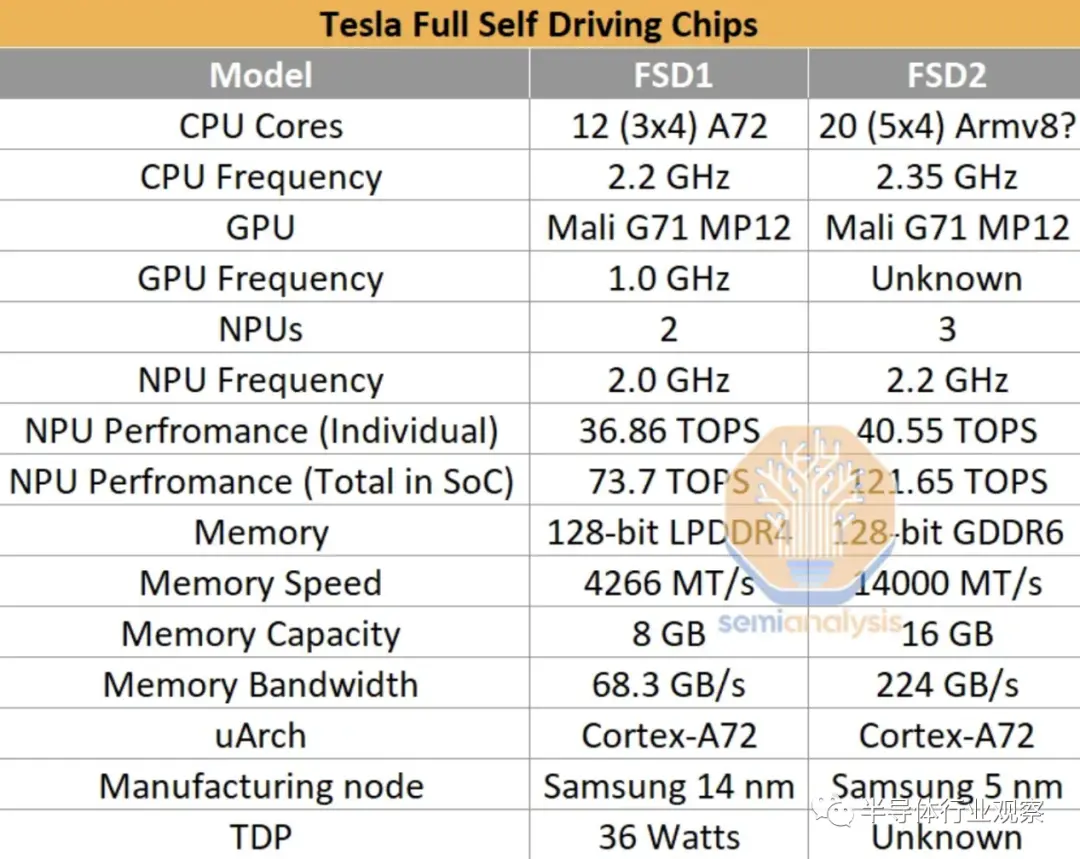
第二代 FSD 擁有 256GB NVMe 存儲和 16GB Micron GDDR6(14Gbps),位于 128 位內(nèi)存總線上,提供 224GB/s 帶寬。后者是最值得注意的變化,因為帶寬逐代增加了約 3.3 倍。FLOP 與帶寬的增加表明 HW3 難以充分利用。每個 HW 4.0 有兩個 FSD 芯片。
HW4 板性能的提高是以額外的功耗為代價的。HW4板的空閑功耗大約是HW3的兩倍。在高峰期,我們預(yù)計它也會更高。HW4的外部電壓為 16 伏,電流為 10 安,即使用的功率為 160 瓦。
盡管 HW4 的性能有所提高,但特斯拉希望 HW3 也能實現(xiàn) FSD,可能是因為他們不想對購買 FSD 的現(xiàn)有 HW3 用戶進(jìn)行改造。
信息娛樂系統(tǒng)采用 AMD GPU/APU。與具有獨立子板的上一代相比,它現(xiàn)在也與 FSD 芯片位于同一塊板上。

HW4 平臺支持 12 個攝像頭,其中 1 個用于冗余目的,因此有 11 個攝像頭正在使用。在舊的設(shè)置中,前置攝像頭中心使用三個較低分辨率的 1.2 兆像素攝像頭。新平臺使用兩個更高分辨率的 5 兆像素攝像頭。
特斯拉目前不使用激光雷達(dá)傳感器或其他類型的非攝像頭方法。過去,他們確實使用了雷達(dá),但在一代中期被刪除了。這大大降低了車輛的制造成本,特斯拉致力于優(yōu)化車輛,該公司相信純攝像頭傳感是自動駕駛車輛的一條可能途徑。然而,他們還指出,如果有可行的雷達(dá)可用,他們會將其與攝像頭系統(tǒng)集成。
在HW4平臺上,有一款自行設(shè)計的雷達(dá),稱為Phoenix。Phoenix 將雷達(dá)系統(tǒng)與攝像頭系統(tǒng)相結(jié)合,旨在利用更多數(shù)據(jù)打造更安全的車輛。Phoenix 雷達(dá)使用76-77 GHz 頻譜,峰值有效各向同性輻射功率 (EIPR) 為 4.16 瓦,平均 EIRP 為 177.4 mW。它是一種具有三種傳感模式的非脈沖汽車?yán)走_(dá)系統(tǒng)。雷達(dá) PCB 包括用于傳感器融合的 Xilinx Zynq XA7Z020 FPGA。
特斯拉 AI 模型差異化
特斯拉的目標(biāo)是生產(chǎn)基礎(chǔ)人工智能模型,為其自動機(jī)器人和汽車提供動力。兩者都需要了解周圍環(huán)境并在周圍導(dǎo)航,因此可以將相同類型的人工智能模型應(yīng)用于兩者。為未來的自主平臺創(chuàng)建有效的模型需要大量的研究,更具體地說,需要大量的數(shù)據(jù)。此外,這些模型的推理必須以極低的功耗和低延遲進(jìn)行。由于硬件限制,這極大地減少了特斯拉可以提供的最大模型尺寸。
在所有公司中,特斯拉擁有最大的可用于訓(xùn)練其深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)的數(shù)據(jù)集。道路上的每輛車都使用傳感器和圖像來捕獲數(shù)據(jù),并將其乘以道路上特斯拉電動汽車的數(shù)量,得到一個龐大的數(shù)據(jù)集。特斯拉將其收集數(shù)據(jù)的部分稱為“fleet scale auto labeling”。每輛 Tesla EV 都會拍攝一段 45-60 秒的密集傳感器數(shù)據(jù)記錄,包括視頻、慣性測量單元 (IMU) 數(shù)據(jù)、GPS、里程計等,并將其發(fā)送到 Tesla 的訓(xùn)練服務(wù)器。
Tesla 的模型接受了分割、掩模、深度、點匹配和其他任務(wù)的訓(xùn)練。通過在道路上擁有數(shù)百萬輛電動汽車,特斯拉擁有大量標(biāo)記和記錄良好的數(shù)據(jù)源可供選擇。這使得能夠在公司設(shè)施的 Dojo 超級計算機(jī)上進(jìn)行持續(xù)訓(xùn)練。
特斯拉對數(shù)據(jù)的信念與該公司已建立的可用基礎(chǔ)設(shè)施相矛盾。特斯拉只使用了他們收集的數(shù)據(jù)的一小部分。由于嚴(yán)格的推理限制,特斯拉因過度訓(xùn)練模型以在給定模型大小內(nèi)實現(xiàn)最佳精度而聞名。
過度訓(xùn)練小模型會導(dǎo)致全自動駕駛的性能停滯不前,并且無法使用收集到的所有數(shù)據(jù)。許多公司同樣選擇進(jìn)行盡可能大規(guī)模的訓(xùn)練,但他們也使用更強(qiáng)大的汽車推理芯片。例如,Nvidia 計劃在 2025 年向汽車客戶提供計算能力超過 2,000 TeraFLOPS 的 DRIVE Thor,這是特斯拉新款 HW4 的 15 倍以上。此外,Nvidia 架構(gòu)對于其他模型類型更加靈活。
【來源:半導(dǎo)體行業(yè)觀察】





