
一款名叫Gaudi2的AI芯片,2022年和2023年英特爾都為其開了一場發布會,為什么?
有兩個方面的原因,一個在當前國際形勢下的合規之舉,另一個在生成式AI熱潮下亮出的入場券。

這里的入場券有兩層含義,一層含義是對正在四處尋找合適芯片的AI大模型算法公司來說,英特爾的Gaudi2能夠成為這些公司發展業務的算力基石,足夠的算力大模型競賽的入場券。
另一層含義是對于英特爾來說,拿出的能和英偉達最先進的H100 GPU比拼的產品,是其在AI大市場里披荊斬棘的入場券,也是一個“大殺器”。
站在AI的變革時刻,手握AI時代入場券的公司,如何才能成為AI時代的領導者?
英特爾有一個十分清晰的路線圖,2025年將會推出更適合AI需求的芯片,新的產品將融合Gaudi和GPU。
Gaudi2再次發布的2個原因
2022年的英特爾On產業峰會上,英特爾發布了新一代高性能深度學習AI訓練處理器Habana Gaudi2,那時的Gaudi2訓練BERT模型的性能相比英偉達A100就有2倍的性能優勢,廣受關注。
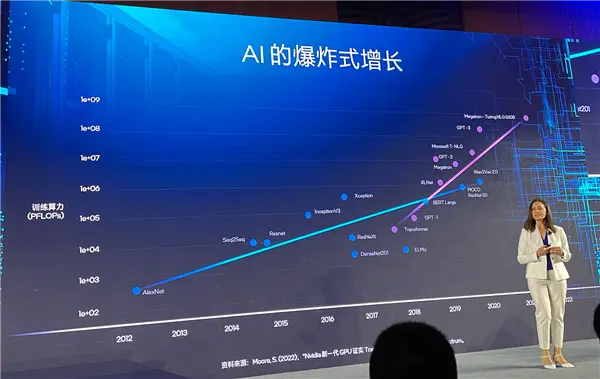
2023年7月,英特爾在北京又舉行了一次Gaudi2的發布會,原因有兩個。
“過去5個月大模型的演進非常快,去年發布audi2之后,我們做了大量軟件模型的優化工作,可為大規模的多模態和語言模型提供出色的推理性能。”英特爾公司執行副總裁,數據中心與人工智能事業部總經理Sandra Rivera說,“這次我們不只是帶來了一顆芯片,還帶來了基于Gaudi2可以大規模部署訓練以及推理大模型的整體解決方案。”
為了市場需求再次發布是一個原因,另一個原因是因為政策。
“這次在中國發布的Gaudi2,是中國定制版產品,對于出口或支持中國的客戶沒有任何問題。”Sandra分享。
中國版Gaudi2和國際版最大的區別是網口的數量,國際版集成以太網端口數量是24個,中國版減少到了21個,這一變化會降低中國版Gadudi2網絡速度,對整體的性能影響不大。

這其實是在滿足互聯總線帶寬不能超過400GB/s的美國出口法規限制。雷峰網(公眾號:雷峰網)了解到,在法規的限制下,下一代Gaudi3在中國市場銷售的版本也會和國際版有所不同。
用性價比和英偉達掰手腕
英特爾發布中國版Gaudi2并積極宣傳的目的非常明確——從英偉達手上分一杯羹。
生成式AI火熱之后,英偉達次新的A100和最新和H100 GPU在全球都成為了緊俏商品。在中國這種情況更加嚴重,并且因為有美國法規的限制,A100和H100并不能直接向中國市場出售,只能銷售互聯帶寬更低的A800和H800。
這給包括英特爾在內的所有高性能AI加速芯片的提供者一個絕佳的機會,能從英偉達手里分一杯羹,就意味著抓住了AI這個未來十年甚至更長時間的大市場。
Gaudi2非常聰明地從性價比的角度與當下最強大的H100和A100競爭,這種聰明更直白的說就是抓住了用戶最急切的需求。
“A100的定價相比此前的產品已經偏貴,到H100時定價已經貴的有些夸張,加上供貨緊缺帶來的價格上漲,H100讓大量公司都對替代產品更有興趣。”多位AI行業從業者都對雷峰網表示,“只要其它AI芯片的性能和體驗達到英偉達的80%,價格是英偉達的一半,就一定有客戶愿意買單。”

性價比可以借用數據直觀體現。最受歡迎的AI開源模型提供商Hugging Face分享性能結果顯示,Gaudi2在多種訓練和推理基準測試中表現出的超過英偉達 A100 GPU的性能。在訓練計算機視覺模型時,Gaudi2的每瓦性能是A100的2倍,對于1760億參數的BLOOMZ推理,Gaudi2的每瓦性能是A100的60%,有全方位的能效比優勢。
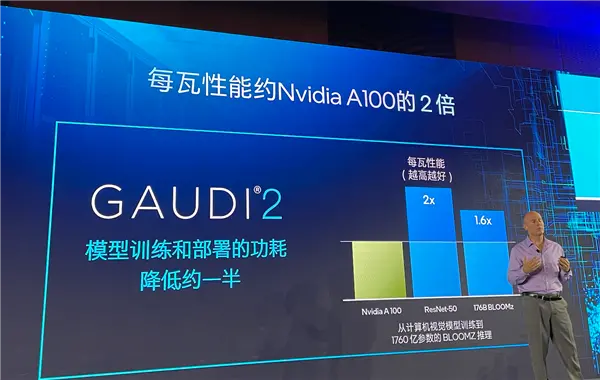
再看AI領域權威的基準測試MLPerf在六月發布的最新結果。
Gaudi2和英偉達H100是唯二提交GPT-3模型訓練結果的半導體解決方案。結果顯示,Gaudi2在384個加速器上訓練GPT-3的時間為311分鐘,英偉達在512個H100 GPU上的訓練時間則為64分鐘。

“這意味著,基于GPT-3模型,每個H100的性能領先于Gaudi2 3.6倍。”Habana Labs首席運營官Eitan Medina直言,“性價比是影響H100和Gaudi2相對價值的一個重要考量因素。Gaudi2服務器的成本要比H100低得多,所以Gaudi2的價格優勢能夠大大縮小了與H100的性價比差距。”


談性價比,不能繞開軟件,也就是使用體驗。
幾分鐘就能遷移代碼,Gaudi2高度適配大模型
芯片的使用體驗,對于有開發經驗的工程師來說是遷移的,對于沒有代碼的工程師來說是上手的難度。
Hugging Face 的首席布道者Julien Simon分享他使用Gaudi的經歷,“在我第一次使用時,只花了10分鐘,其中還包括閱讀文檔。在運行了我的加速腳本后,它立即就可以工作。我必須說這是我見過的最簡單的開發體驗之一,如果你有現成的代碼,可以在幾分鐘內進行遷移。”
幾分鐘就能遷移原有模型的開發體驗來源于英特爾針對Gaudi平臺深度學習訓練和推理優化的SynapseAI軟件套件。這一軟件套件集成PyTorch、TensorFlow、DeepSpeed框架,也支持Kubernetes編排,定制編譯器。

同時,SynapseAI軟件套件也有強大的合作伙伴生態系統,包括Hugging Face、PyTorch Lightning、RedHat。其中,超過5萬個模型在Hugging Face平臺上使用Optimum Habana軟件庫進行了優化。
這讓Gaudi2對大模型開發者非常友好,從github上也能看到Optimum Habana對大量大模型支持的情況。像是對Stable Diffusion(一個用于從文本生成圖像的最先進生成式AI模型之一)訓練,Gaudi2能夠實現從1張卡至64張卡近線性99%的擴展性。
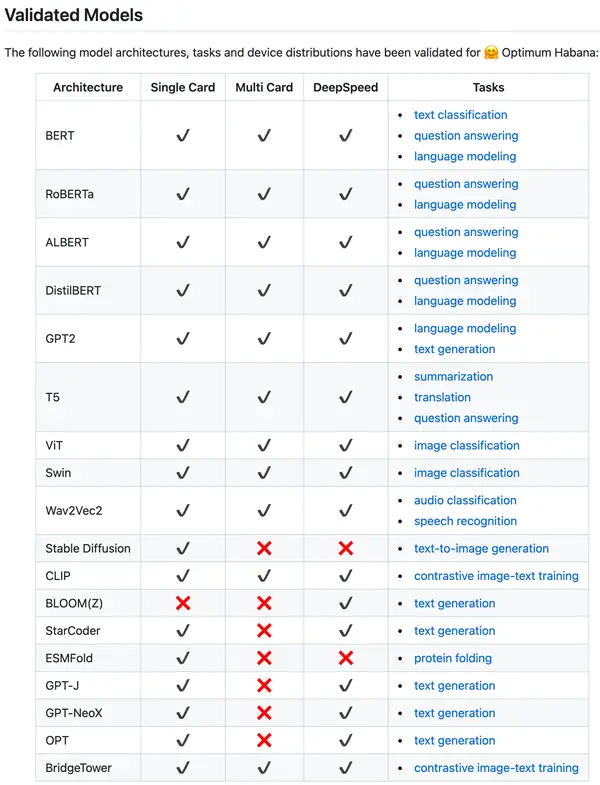
隨著軟件優化的持續深入,開發者能夠擁有更好的開發體驗。而與Hugging Face的合作,也讓開發者不用考慮英偉達的CUDA軟件生態。
“確實很多人在用CUDA進行人工智能運算,但是大模型的開發者,大部分不會做那么底層的開發的,他們是在一個比較高的框架,比如PyTorch、TensorFlow上面做創新。”Sandra十分有信心,“我們和Hugging Face做了一些對策和合作,一些現有模型只花幾十秒的時間就可以調通,能夠運行在Gaudi上。”
“Gaudi2之前已經有一代產品,我們做了好幾年積累,底層軟件庫都已經開發好。”Eitan補充,“我們希望讓開發者能夠在最上層的20%做他的開發,這里的開發和CUDA沒有那么直接的關聯。”
目前,浪潮信息已經發售基于Gaudi2深度學習加速器的浪潮信息AI服務器NF5698G7,這款服務器集成了8顆Gaudi2加速卡HL-225B,還包含雙路第四代英特爾至強可擴展處理器。
英特爾也會打造基于Gaudi2的大規模集群,作為英特爾開發者云的一部分向中國客戶提供。
2025年有更整合的GPU
Gaudi2是英特爾在大模型熱潮里拿出的算力武器,但對于生成式AI的需求顯然還不足夠。
“明年我們會發布下一代產品Gaudi 3。”Sandra還透露,“2025年時,我們會把Gaudi的AI芯片與GPU路線圖合二為一,推出一個更整合的GPU的產品。”
混合DSA(領域專用架構)是AI芯片領域明確的趨勢,將Gaudi和GPU整合,既能發揮DSA的性能和能效優勢,又能擁有GPU的通用性,這是高性能AI芯片公司都在努力的方向,但軟件是一個挑戰。
“從開發者的角度,他們更看重的是可持續的軟件生態。”Sandra非常清楚,“在迭代產品的同時,我們要對開發者做最好的軟件支持,讓他們投入軟件的一些代碼能夠在迭代的時候可以更好復用。”
當然,除了朝混合DSA的方向努力,英特爾還有豐富的AI產品組合的優勢,包括CPU、GPU、FPGA和DSA。

Sandra對雷峰網表示,“很多數據中心的客戶有成百上千個至強,他們可以很方便的在現有的數據中心上用至強做一些簡單的推理工作。對于千億級參數的模型訓練,需要像Gaudi這樣在性能、性價比或者是在供電上都是有平衡考量的產品。GPU Max在科學計算領域可以提供更高的性能和性價比。”
百度智能云服務器高級經理何永占就分享了其使用至強的經驗,集成英特爾AMX加速引擎的第四代英特爾至強可擴展處理器為ERNIE-Tiny模型帶來了多倍的性能優化。
顯然,英特爾在生成式AI熱潮里已經交出了不錯的答卷,接下來就要看其能在AI大市場里俘獲多少客戶的心。
【來源:快科技】





