
基于任何平臺實現的云盤系統,面臨的首要的技術問題就是客戶端上傳和下載效率優化問題。基于Hadoop實現的云盤系統,受到Hadoop文件讀寫機制的影響,采用Hadoop提供的API進行HDFS文件系統訪問,文件讀取時默認是順序、逐block讀取;寫入時是順序寫入。
一、讀寫機制
首先來看文件讀取機制:盡管DataNode實現了文件存儲空間的水平擴展和多副本機制,但是針對單個具體文件的讀取,Hadoop默認的API接口并沒有提供多DataNode的并行讀取機制。基于Hadoop提供的API接口實現的云盤客戶端也自然面臨同樣的問題。Hadoop的文件讀取流程如下圖所示:

使用HDFS提供的客戶端開發庫,向遠程的Namenode發起RPC請求;
Namenode會視情況返回文件的部分或者全部block列表,對于每個block,Namenode都會返回有該block拷貝的datanode地址;
客戶端開發庫會選取離客戶端最接近的datanode來讀取block;
讀取完當前block的數據后,關閉與當前的datanode連接,并為讀取下一個block尋找最佳的datanode;
當讀完列表的block后,且文件讀取還沒有結束,客戶端開發庫會繼續向Namenode獲取下一批的block列表。
讀取完一個block都會進行checksum驗證,如果讀取datanode時出現錯誤,客戶端會通知Namenode,然后再從下一個擁有該block拷貝的datanode繼續讀取。
這里需要注意的關鍵點是:多個Datanode順序讀取。
其次再看文件的寫入機制:
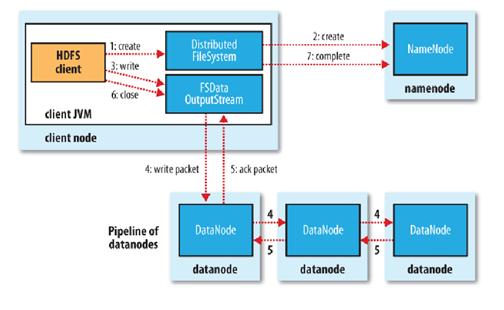
使用HDFS提供的客戶端開發庫,向遠程的Namenode發起RPC請求;
Namenode會檢查要創建的文件是否已經存在,創建者是否有權限進行操作,成功則會為文件創建一個記錄,否則會讓客戶端拋出異常;
當客戶端開始寫入文件的時候,開發庫會將文件切分成多個packets,并在內部以"data queue"的形式管理這些packets,并向Namenode申請新的blocks,獲取用來存儲replicas的合適的datanodes列表, 列表的大小根據在Namenode中對replication的設置而定。開始以pipeline(管道)的形式將packet寫入所有的replicas中。開發庫把packet以流的方式寫入第一個 datanode,該datanode把該packet存儲之后,再將其傳遞給在此pipeline中的下一個datanode,直到最后一個 datanode,這種寫數據的方式呈流水線的形式。
最后一個datanode成功存儲之后會返回一個ack packet,在pipeline里傳遞至客戶端,在客戶端的開發庫內部維護著"ack queue",成功收到datanode返回的ack packet后會從"ack queue"移除相應的packet。
如果傳輸過程中,有某個datanode出現了故障,那么當前的pipeline會被關閉,出現故障的datanode會從當前的 pipeline中移除,剩余的block會繼續剩下的datanode中繼續以pipeline的形式傳輸,同時Namenode會分配一個新的 datanode,保持replicas設定的數量。
關鍵詞:開發庫把packet以流的方式寫入第一個datanode,該datanode將其傳遞給pipeline中的下一個datanode,知道最后一個Datanode,這種寫數據的方式呈流水線方式。
二、解決方案
1.下載效率優化
通過以上讀寫機制的分析,我們可以發現基于Hadoop實現的云盤客戶段下載效率的優化可以從兩個層級著手:
1.文件整體層面:采用并行訪問多線程(多進程)份多文件并行讀取。
2.Block塊讀取:改寫Hadoop接口擴展,多Block并行讀取。
2.上傳效率優化
上傳效率優化只能采用文件整體層面的并行處理,不支持分Block機制的多Block并行讀取。
HDFS處理大量小文件時的問題
小文件指的是那些size比HDFS 的block size(默認64M)小的多的文件。如果在HDFS中存儲小文件,那么在HDFS中肯定會含有許許多多這樣的小文件(不然就不會用hadoop了)。
而HDFS的問題在于無法很有效的處理大量小文件。
任何一個文件,目錄和block,在HDFS中都會被表示為一個object存儲在namenode的內存中,沒一個object占用150 bytes的內存空間。所以,如果有10million個文件,
沒一個文件對應一個block,那么就將要消耗namenode 3G的內存來保存這些block的信息。如果規模再大一些,那么將會超出現階段計算機硬件所能滿足的極限。
不僅如此,HDFS并不是為了有效的處理大量小文件而存在的。它主要是為了流式的訪問大文件而設計的。對小文件的讀取通常會造成大量從
datanode到datanode的seeks和hopping來retrieve文件,而這樣是非常的低效的一種訪問方式。
大量小文件在mapreduce中的問題
Map tasks通常是每次處理一個block的input(默認使用FileInputFormat)。如果文件非常的小,并且擁有大量的這種小文件,那么每一個map task都僅僅處理了非常小的input數據,
并且會產生大量的map tasks,每一個map task都會消耗一定量的bookkeeping的資源。比較一個1GB的文件,默認block size為64M,和1Gb的文件,沒一個文件100KB,
那么后者沒一個小文件使用一個map task,那么job的時間將會十倍甚至百倍慢于前者。
hadoop中有一些特性可以用來減輕這種問題:可以在一個JVM中允許task reuse,以支持在一個JVM中運行多個map task,以此來減少一些JVM的啟動消耗
(通過設置mapred.job.reuse.jvm.num.tasks屬性,默認為1,-1為無限制)。另一種方法為使用MultiFileInputSplit,它可以使得一個map中能夠處理多個split。
為什么會產生大量的小文件?
至少有兩種情況下會產生大量的小文件
1. 這些小文件都是一個大的邏輯文件的pieces。由于HDFS僅僅在不久前才剛剛支持對文件的append,因此以前用來向unbounde files(例如log文件)添加內容的方式都是通過將這些數據用許多chunks的方式寫入HDFS中。
2. 文件本身就是很小。例如許許多多的小圖片文件。每一個圖片都是一個獨立的文件。并且沒有一種很有效的方法來將這些文件合并為一個大的文件
這兩種情況需要有不同的解決方 式。對于第一種情況,文件是由許許多多的records組成的,那么可以通過件邪行的調用HDFS的sync()方法(和append方法結合使用)來解 決。或者,可以通過些一個程序來專門合并這些小文件(see Nathan Marz’s post about a tool called the Consolidator which does exactly this).
對于第二種情況,就需要某種形式的容器來通過某種方式來group這些file。hadoop提供了一些選擇:
* HAR files
Hadoop Archives (HAR files)是在0.18.0版本中引入的,它的出現就是為了緩解大量小文件消耗namenode內存的問題。HAR文件是通過在HDFS上構建一個層次化的文件系統來工作。一個HAR文件是通過hadoop的archive命令來創建,而這個命令實 際上也是運行了一個MapReduce任務來將小文件打包成HAR。對于client端來說,使用HAR文件沒有任何影響。所有的原始文件都 visible && accessible(using har://URL)。但在HDFS端它內部的文件數減少了。
通 過HAR來讀取一個文件并不會比直接從HDFS中讀取文件高效,而且實際上可能還會稍微低效一點,因為對每一個HAR文件的訪問都需要完成兩層index 文件的讀取和文件本身數據的讀取(見上圖)。并且盡管HAR文件可以被用來作為MapReduce job的input,但是并沒有特殊的方法來使maps將HAR文件中打包的文件當作一個HDFS文件處理。 可以考慮通過創建一種input format,利用HAR文件的優勢來提高MapReduce的效率,但是目前還沒有人作這種input format。 需要注意的是:MultiFileInputSplit,即使在HADOOP-4565的改進(choose files in a split that are node local),但始終還是需要seek per small file。
* Sequence Files
通 常對于“the small files problem”的回應會是:使用SequenceFile。這種方法是說,使用filename作為key,并且file contents作為value。實踐中這種方式非常管用。回到10000個100KB的文件,可以寫一個程序來將這些小文件寫入到一個單獨的 SequenceFile中去,然后就可以在一個streaming fashion(directly or using mapreduce)中來使用這個sequenceFile。不僅如此,SequenceFiles也是splittable的,所以mapreduce 可以break them into chunks,并且分別的被獨立的處理。和HAR不同的是,這種方式還支持壓縮。block的壓縮在許多情況下都是最好的選擇,因為它將多個 records壓縮到一起,而不是一個record一個壓縮。
將已有的許多小文件轉換成一個SequenceFiles可能會比較慢。但 是,完全有可能通過并行的方式來創建一個一系列的SequenceFiles。(Stuart Sierra has written a very useful post about converting a tar file into a SequenceFile — tools like this are very useful).更進一步,如果有可能最好設計自己的數據pipeline來將數據直接寫入一個SequenceFile。





