
編輯:Panda W
LLM 面臨哪些挑戰(zhàn)又有哪些應用?系統(tǒng)性的綜述論文來了。
從毫無存在感到無人不談,大型語言模型(LLM)的江湖地位在這幾年發(fā)生了巨變。這個領域的發(fā)展令人目不暇接,但也正因如此,人們難以了解還有什么難題有待解決以及哪些領域已有成熟應用。
為了幫助機器學習研究者更快理解 LLM 領域的當前現(xiàn)狀并提升他們的生產(chǎn)力,來自倫敦大學學院等多家機構(gòu)的研究團隊不畏繁瑣,系統(tǒng)性地總結(jié)了 LLM 領域的艱難挑戰(zhàn)和成功應用。
LLM 研究大熱的現(xiàn)狀也在這篇綜述論文的參考文獻中得到了體現(xiàn) —— 總共 22 頁參考文獻,引用了 688 篇論文!
機器之心對這篇綜述論文的大致框架進行了整理,以便讀者能快速了解 LLM 的挑戰(zhàn)和應用,更詳細的論述和具體文獻請參閱原論文。

論文:
https://arxiv.org/abs/2307.10169
整體而言,這篇綜述論文聚焦于兩大主題:(1) 挑戰(zhàn):哪些問題仍未解決?(2) 應用:LLM 當前的應用以及這些應用面臨哪些挑戰(zhàn)?對于主題 (1),研究者將 LLM 面臨的挑戰(zhàn)分成了三個大類:設計、行為和科學。對于主題 (2),研究者探索了聊天機器人、計算生物學、計算生物學、計算機編程、創(chuàng)意工作、知識工作、法律、醫(yī)學、推理、機器人和社會科學等領域。
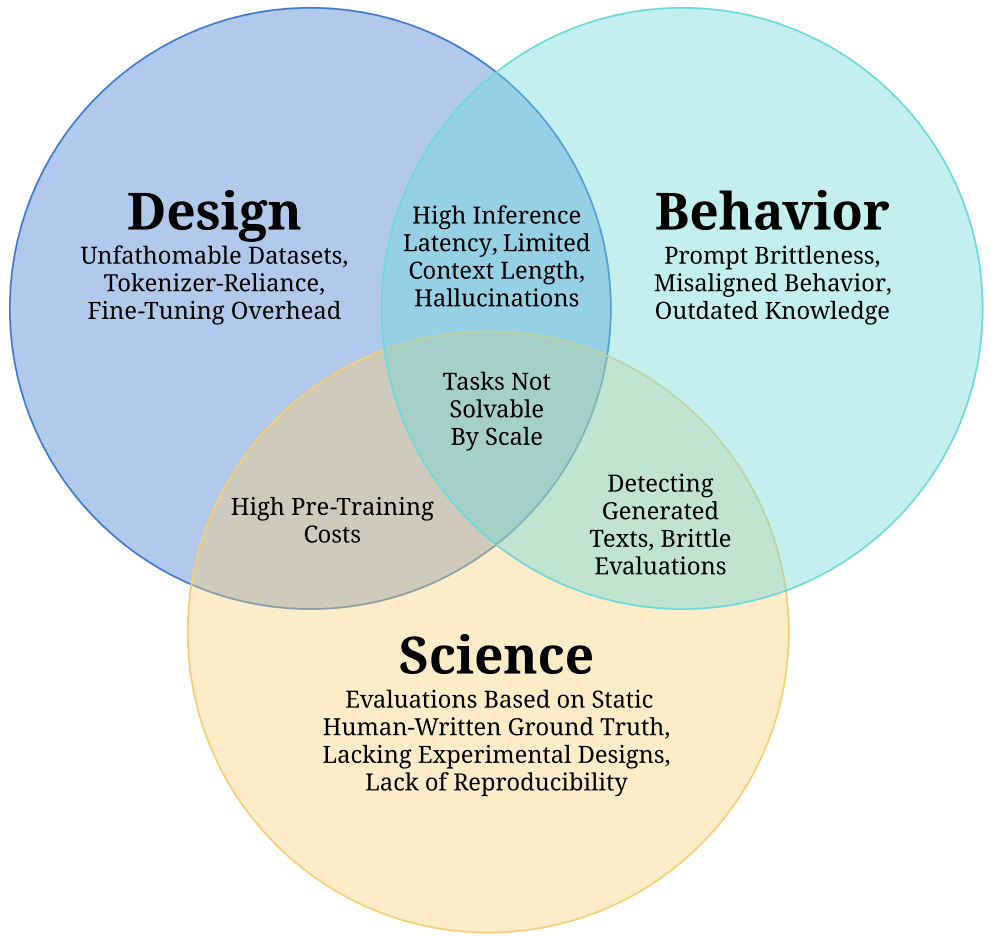
圖 1:LLM 挑戰(zhàn)概況。LLM 的設計與部署前做出的決策有關(guān)。LLM 行為方面的挑戰(zhàn)發(fā)生在部署階段。科學方面的挑戰(zhàn)會阻礙學術(shù)進步。
研究者聲明,這篇論文梳理的內(nèi)容帶有個人傾向性,并且假定讀者已經(jīng)熟悉 LLM 的工作方式。此外,他們更關(guān)注基于文本數(shù)據(jù)訓練的模型。他們的綜述論文也專注于技術(shù)方面,不會討論 LLM 在政治、哲學或道德方面的議題。
挑戰(zhàn)
難以理解的數(shù)據(jù)集
對于 LLM 而言,其預訓練數(shù)據(jù)集的規(guī)模非常大,任何個人都無法徹底閱讀其中的文檔或評估這些文檔的質(zhì)量。這方面涉及的問題包括:
- 有許多非常相近幾乎算是重復的數(shù)據(jù);
- 基準數(shù)據(jù)遭受污染;
- 某些信息可用于識別個人的身份;
- 預訓練的數(shù)據(jù)域混在一起;
- 微調(diào)任務混在一起的情況難以處理。
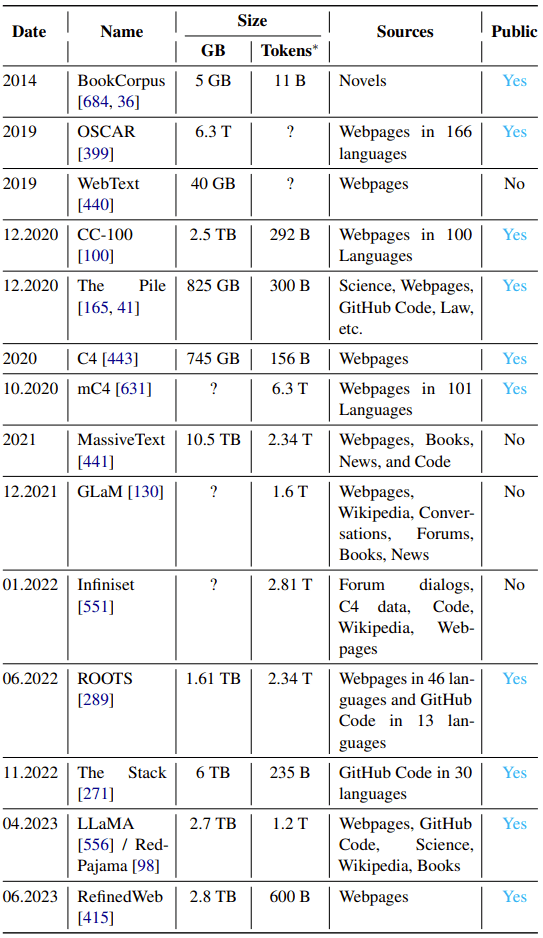
表 1:所選預訓練數(shù)據(jù)集概況
這些年來,預訓練數(shù)據(jù)集變得更加難以理解了:它們的規(guī)模和多樣性都在迅速增長,并且不是所有數(shù)據(jù)集都是公開可用的。
依賴 token 化器
token 化器帶來了一些挑戰(zhàn),比如計算開銷、語言依賴性、對新詞的處理、固定詞匯量、信息丟失和人類可解釋性低。
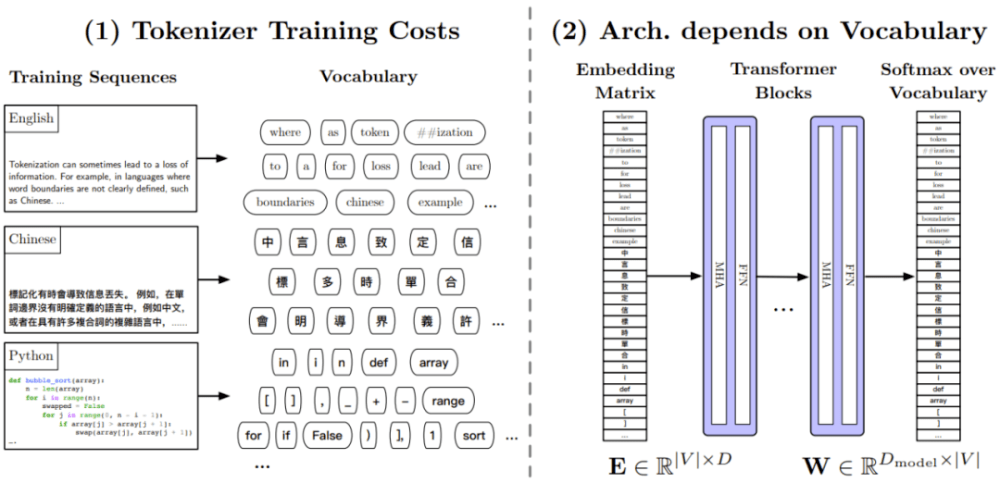
圖 2:依賴 token 化器的典型缺點。(1) token 化器的訓練步驟涉及到復雜繁瑣的計算,比如多次遍歷整個預訓練數(shù)據(jù)集,并且還會導致對預訓練數(shù)據(jù)集的依賴,這在多語言環(huán)境中是個尤其麻煩的問題。(2) LLM 的嵌入層 E 和輸出層 W 與詞匯量有關(guān),比如在 T5 模型中詞匯占到了模型參數(shù)數(shù)量的 66% 左右。
預訓練成本高
通過增加計算預算可以提升模型的性能表現(xiàn),但如果模型或數(shù)據(jù)集大小固定,則增長比率會降低,呈現(xiàn)收益遞減的冪律趨勢。
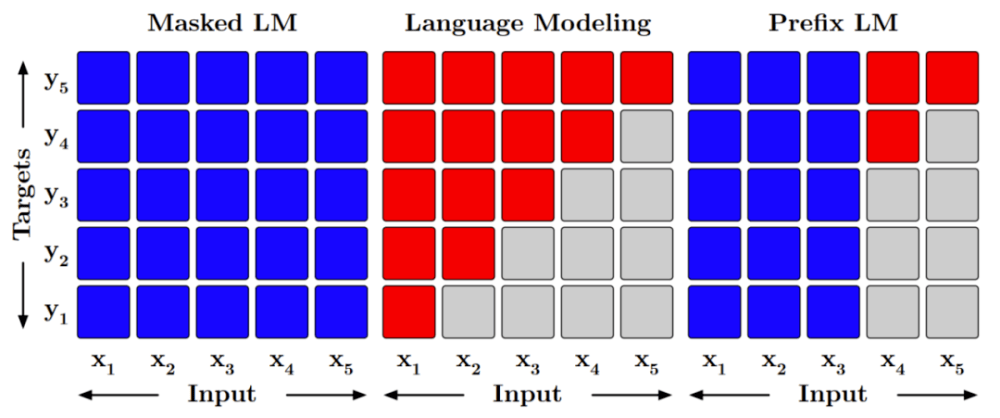
圖 3:掩碼策略。每一行表示一個特定輸出 y_i(行)可以考慮哪些輸入 x_i(列)(紅色表示單向,藍色表示雙向)。
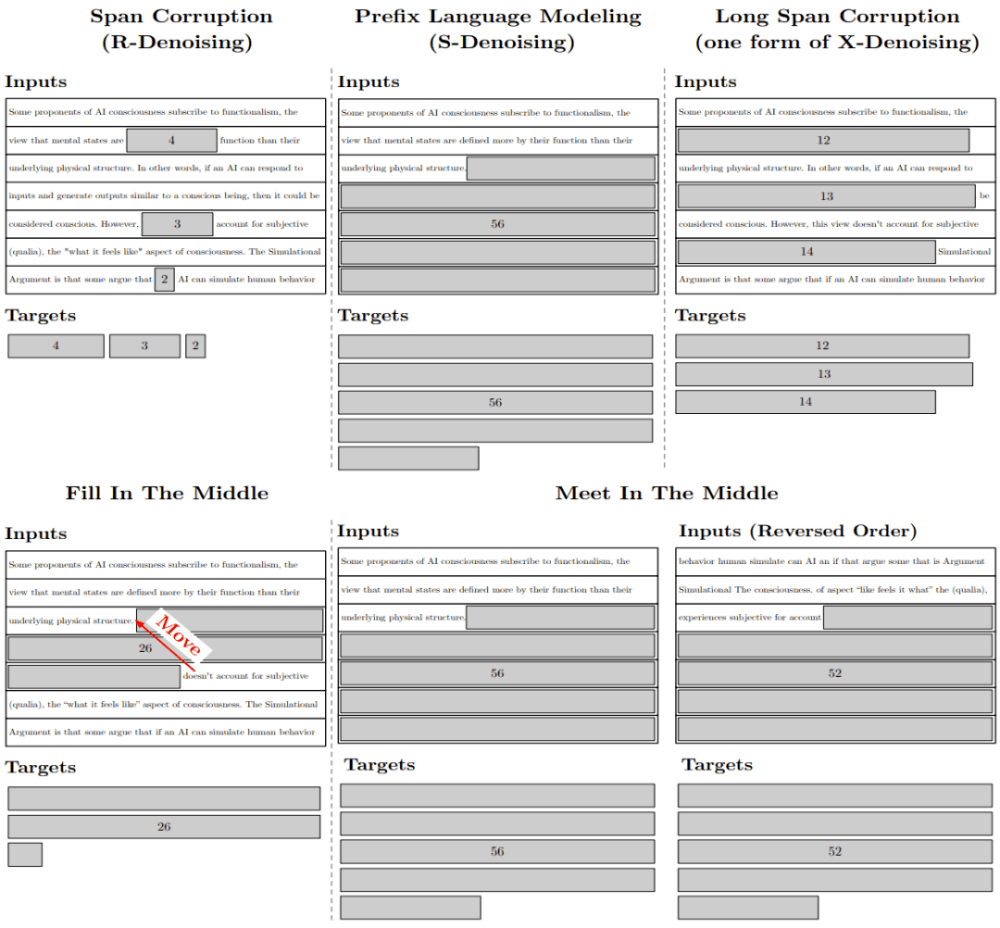
圖 4:根據(jù)預訓練目標進行自監(jiān)督式的數(shù)據(jù)構(gòu)建,來自 Tay et al.
微調(diào)開銷
需要大量內(nèi)存:對整個 LLM 進行微調(diào)時需要預訓練時一樣大的內(nèi)存,但很多從業(yè)者無法辦到。
存儲和加載微調(diào) LLM 的開銷:當通過全模型微調(diào)讓 LLM 適應當前任務時,必須存儲模型的一個副本(這需要數(shù)據(jù)存儲空間),用于任務時還需要進行加載(需要為此分配內(nèi)存)。
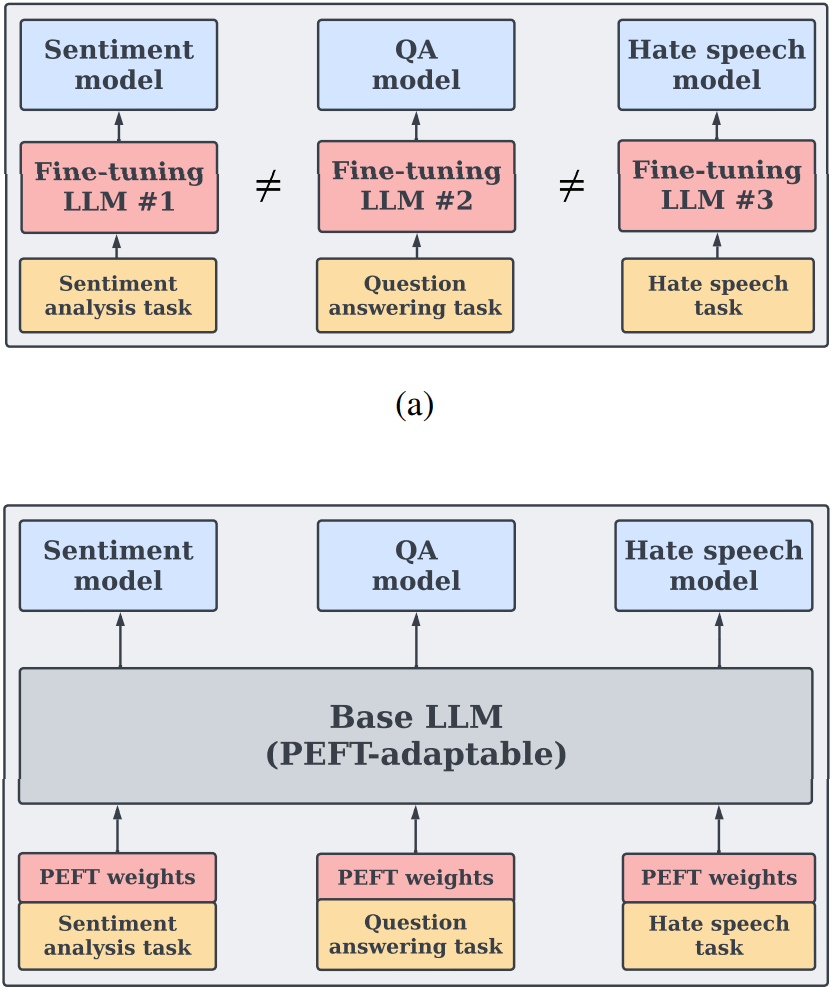
圖 5:針對下游具體任務對 LLM 進行微調(diào)。(a) 展示了簡單普通的微調(diào),這需要更新整個模型,從而為每個任務生成一個新模型。(b) 展示了 PEFT 方法,其為每個任務學習一個模型參數(shù)子集,然后配合固定的基礎 LLM 使用。針對不同任務執(zhí)行推理時,可以復用同一個基礎模型。
全矩陣乘法:若要對 LLM 實現(xiàn)參數(shù)高效的微調(diào),就需要在整個網(wǎng)絡中執(zhí)行完整的前向 / 后向通過。
推理延遲高
LLM 的推理延遲依然很高,原因包括并行性低和內(nèi)存足跡大。
上下文長度有限
上下文長度有限使得 LLM 難以很好地處理長輸入,讓 LLM 不能很好地助力小說或教科書寫作或總結(jié)等應用。
prompt 不穩(wěn)定
prompt 句法的變化導致的結(jié)果變化對人類來說并不直觀,有時候輸入一點小變化就會導致輸出大變樣。
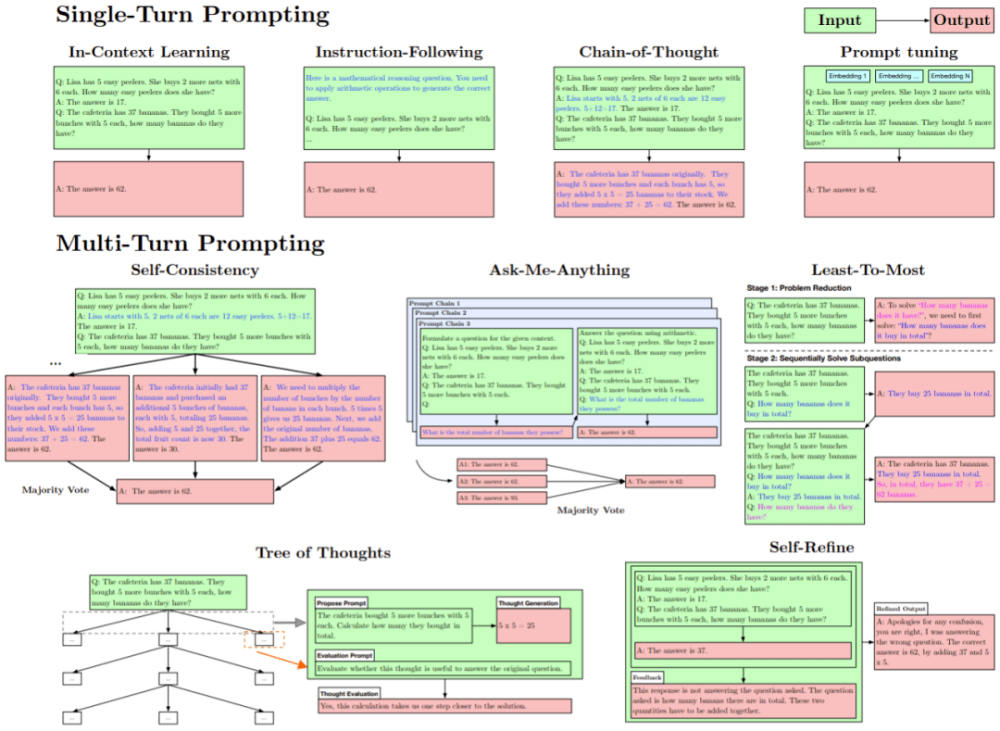
圖 6:所選的 prompt 設計方法概況,分為單輪和多輪 prompt 設計。
幻覺問題
幻覺問題是指生成的文本雖然流暢又自然,但卻不忠實于內(nèi)容來源(內(nèi)在問題)和 / 或不確定(外在問題)。

圖 7:GPT-4 的幻覺問題示例,訪問日期:02/06/2023。
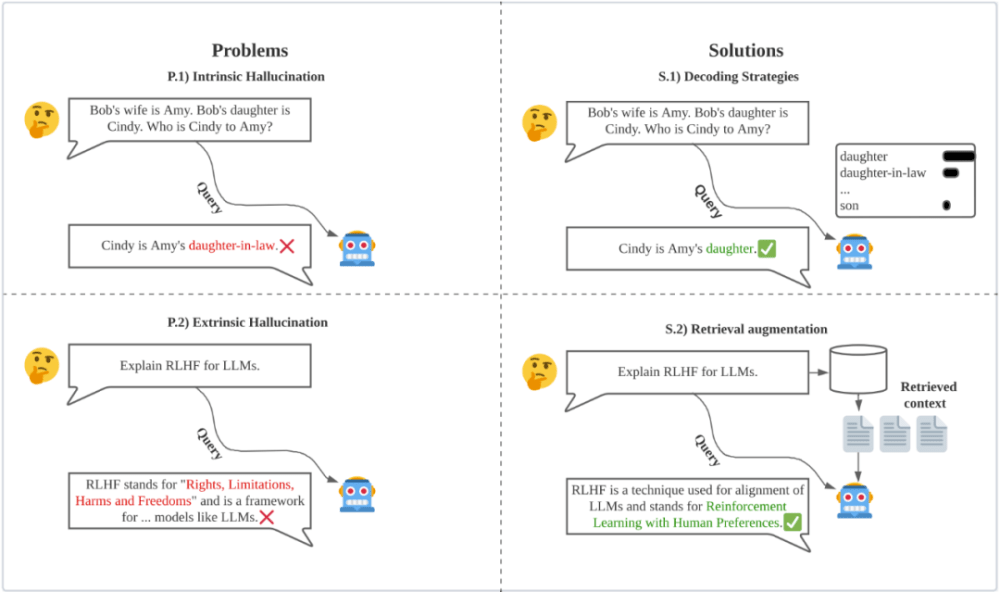
圖 8:用戶與 LLM 互動時的 a) 內(nèi)在和 b) 外在幻覺示例。示例 a) 中,LLM 給出的答案與給定上下文相矛盾,而在 b) 中,上下文沒有提供足夠信息,無法知道生成的答案是否相矛盾。
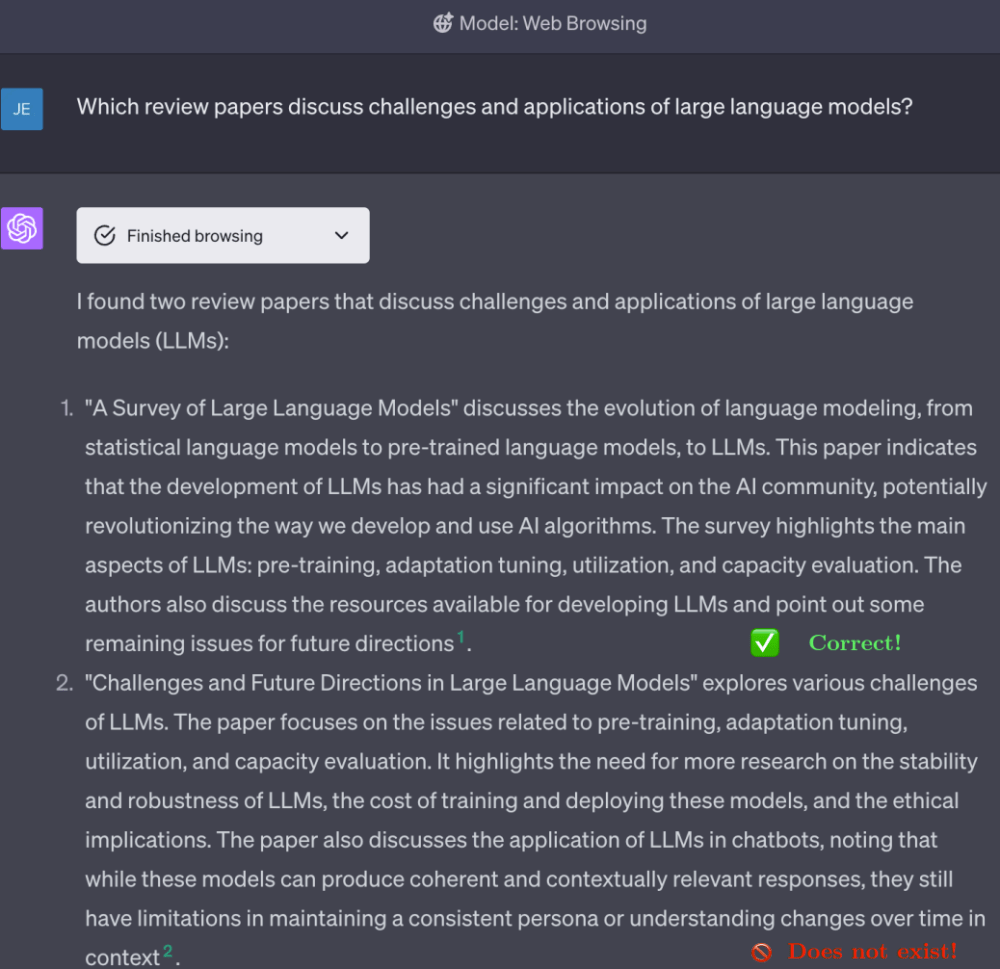
圖 9:檢索增強型 GPT-4 示例,這是幻覺問題的一種潛在解決方法,訪問日期:02/06/2023。
行為不對齊
LLM 常會生成與人類價值或意圖不對齊的輸出,這可能導致意想不到的負面后果。
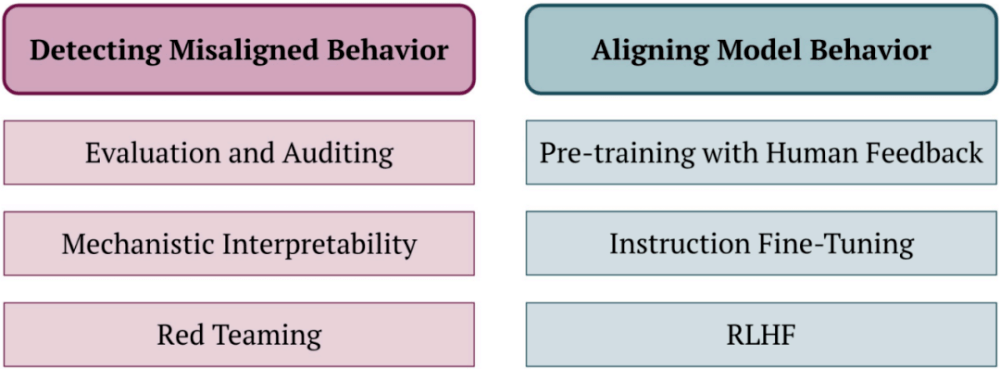
圖 10:對齊。這里將對齊方面的現(xiàn)有研究工作分為兩類:檢測未對齊的行為和實現(xiàn)模型對齊的方法。
過時的知識
LLM 在預訓練期間學到的事實信息可能不準確或隨著時間的推移而變得過時。但是,使用更新的預訓練數(shù)據(jù)重新訓練模型的成本不低,而試圖在微調(diào)階段忘記過時事實并學習新知識的難度也不小。
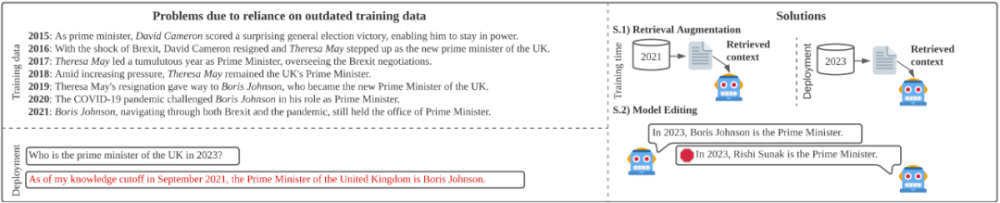
圖 11:知識過時問題的解決方法有:S.1) 通過對基礎檢索索引使用熱交換,使其獲得最新知識,從而增強檢索能力;S.2) 通過應用模型編輯技術(shù)。
評估方法不穩(wěn)定
對基礎 prompt 或評估協(xié)議進行少量修改就可能導致結(jié)果出現(xiàn)巨大變化。
基于靜態(tài)的、人工編寫的 Ground Truth 來執(zhí)行評估
隨著時間的推移,靜態(tài)基準的實用性越來越低,因為模型的能力在變化,而更新這些基準需要人類來編寫 Ground Truth。
難以分辨生成的文本和人類編寫的文本
隨著 LLM 的發(fā)展,人們越來越難以區(qū)分文本是來自 LLM 還是人類。
而就算文本已經(jīng)被發(fā)現(xiàn)是 LLM 生成的,還能通過所謂的轉(zhuǎn)述攻擊(Paraphrasing Attacks)繞開,即用另一個 LLM 重寫生成的文本,使結(jié)果保留大致一樣的意思,但改變詞或句子架構(gòu)。
無法通過模型或數(shù)據(jù)擴展解決的任務
某些任務似乎無法通過進一步擴展數(shù)據(jù)或模型來解決,比如一些組合任務(Compositional tasks)。
缺乏實驗設計
表 2 列出了涉及這方面的一些學術(shù)論文。許多研究工作都沒有做控制變量實驗,如果模型的設計空間很大,那么這個問題就顯得尤為嚴重。研究者認為這會阻礙對 LLM 的科學理解和技術(shù)進步。
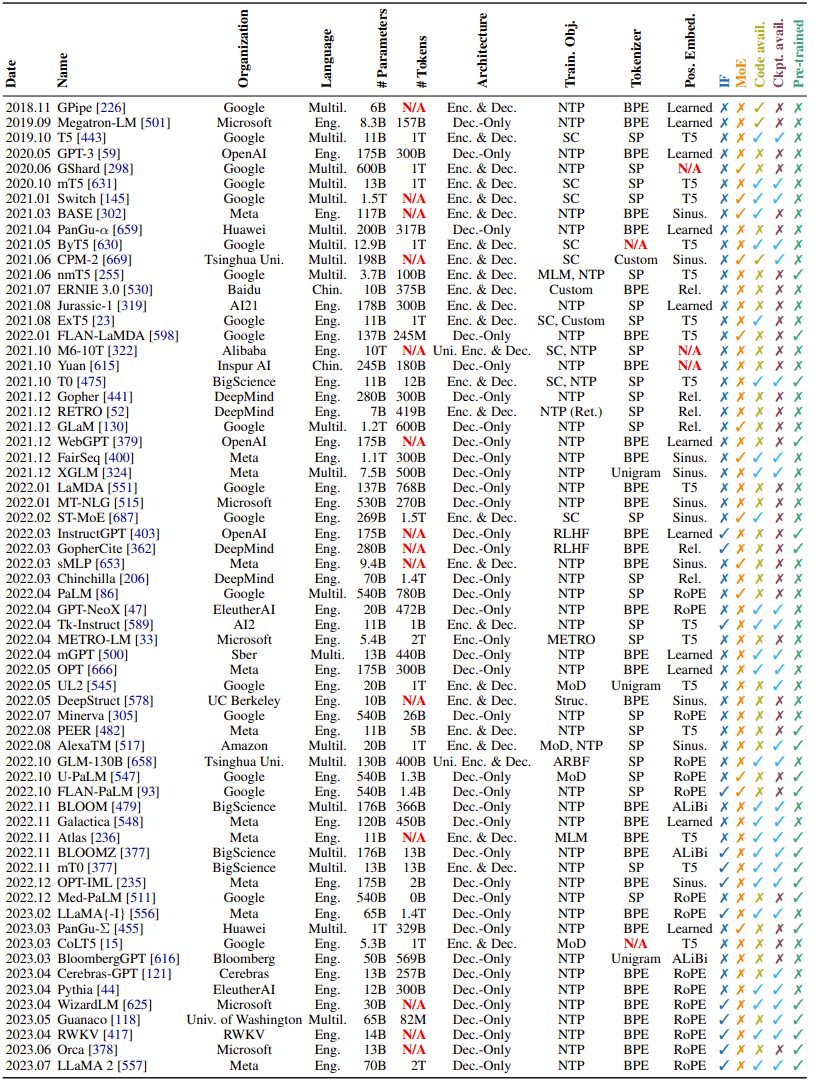
表 2:所選 LLM 概況。N/A 表示細節(jié)缺失。對于研究了多種模型大小的論文,這里僅給出了最大的模型。對于 Tokenizer 項為 SP 的論文,研究者表示無法從相應論文中得知使用的是 BPE 還是 Unigram token 化方法。
對照實驗:介紹新 LLM 的論文通常缺乏對照實驗,這可能是由于訓練足夠多模型的成本過高。
(設計)維度詛咒:通常而言,LLM 實驗的設計空間的維度很高。
難以復現(xiàn)
不可重復的訓練流程:一般來說,現(xiàn)在常用的訓練策略是并行化的,即會將訓練過程分散到許多加速器上,而這個過程是非確定性的,這會使得我們難以復現(xiàn) LLM 的訓練過程。
不可重現(xiàn)的 API:以推理 API 的形式提供服務的模型通常是不可重現(xiàn)的。
應用
下面將聚焦于 LLM 的應用領域,其中重點關(guān)注各領域常見的應用架構(gòu)。
此外還會強調(diào)每個應用領域所面臨的關(guān)鍵局限。
圖 12:LLM 應用概況。不同顏色表示不同的模型適應程度,包括預訓練、微調(diào)、提示策略、評估。
聊天機器人
通用型聊天機器人(對話智能體)包含多種任務,如信息檢索、多輪交互和文本生成(包括代碼)。
保持連貫性:多輪交互使聊天機器人很容易「忘記」對話中更早的部分或重復自己說過的話。
推理延遲高:推理延遲高的話,用戶體驗會大打折扣,尤其是要和聊天機器人進行多輪對話時。
計算生物學
計算生物學關(guān)注的是表示相似序列建模和預測挑戰(zhàn)的非文本數(shù)據(jù)。
難以遷移到下游任務:蛋白質(zhì)語言模型的最終目標是將它們部署到藥物設計等現(xiàn)實項目中。評估通常針對較小和 / 或?qū)iT的數(shù)據(jù)集,而不考慮模型如何有助于生體外或生體內(nèi)的蛋白質(zhì)設計。
上下文窗口有限:最大的基因組的 DNA 序列遠遠長于現(xiàn)有基因組 LLM 的上下文窗口,這會讓研究者難以使用這些 LLM 建模某些基因組類型。
計算機編程
LLM 最先進和廣泛采用的一大應用是用各種編程語言生成和補完計算機程序。
長程依賴:由于上下文長度有限,LLM 通常無法考慮跨代碼庫的長程依賴關(guān)系。
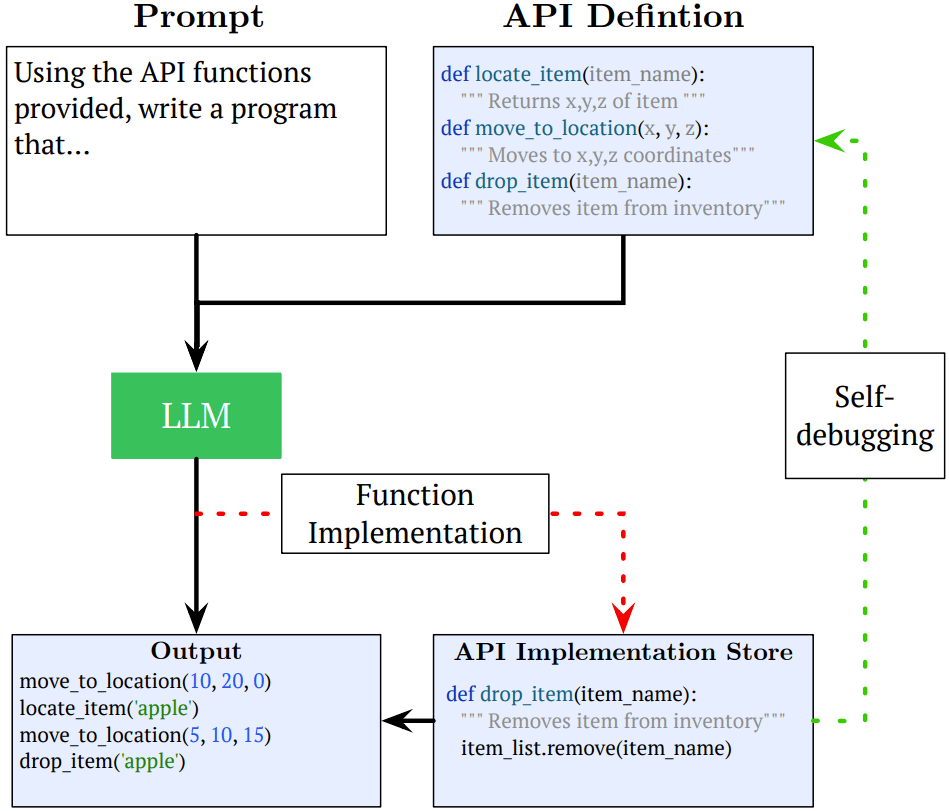
圖 13:API 定義框架。這張示意圖展示了一個 API 定義框架:為了解決特定任務,可以在 prompt 中提供一個通用的 API 定義,從而讓 LLM 可以使用外部代碼或工具。這種方法的擴展包括要求 LLM 實現(xiàn) API 定義中的功能(紅色),以及提示 LLM 自己去調(diào)試任何不執(zhí)行的 API 代碼(綠色)。
創(chuàng)意工作
在創(chuàng)意工作方面,LLM 主要被用于生成故事和劇本。
上下文窗口有限:由于上下文窗口有限,當前的 LLM 無法完整地生成長作品,這會限制它們在長作品方面的應用,也催生了對模塊化 prompt 設計的需求。
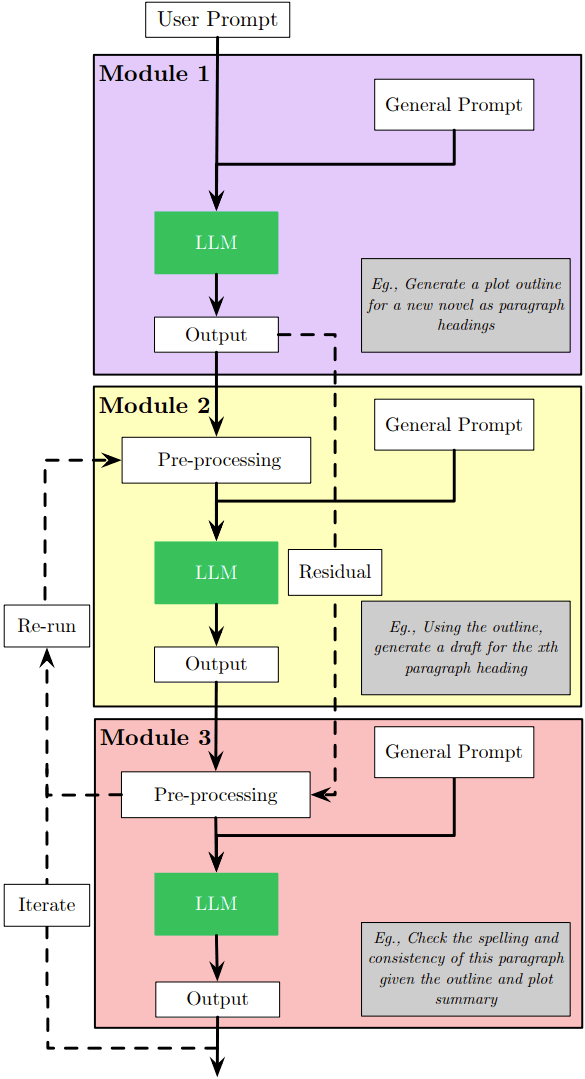
圖 14:模塊化 prompt 設計。通過一系列分立的 prompt 和處理步驟,LLM 可以執(zhí)行無法放入單個上下文窗口中的任務以及解決無法通過單一 prompt 步驟解決的任務。
知識工作
隨著 LLM 在特定領域的知識任務(比如法律或醫(yī)學)上的能力逐漸得到證明,人們也越來越有興趣將 LLM 用于更廣泛的知識工作。這些潛在應用的范圍非常廣泛,據(jù) Eloundou et al. 估計,美國 80% 的勞動力所從事的工作中至少有 10% 的任務會受到 LLM 的影響。
數(shù)值推理:LLM 通常在涉及數(shù)量的任務上表現(xiàn)更差,這可能會限制它們在金融服務或會計等知識工作領域的應用。
法律
LLM 在法律領域的應用與在醫(yī)學領域的有許多相似之處,包括法律問答和法律信息提取。但也有人提出過其它特定領域的應用,比如案件結(jié)果預測、法律研究和法律文本生成。
信息過時問題:由于法律會不斷更新,新的判例也會不斷出現(xiàn),因此訓練 / 檢索數(shù)據(jù)經(jīng)常會遇到過時的問題。
醫(yī)學
醫(yī)學領域已經(jīng)提出了許多 LLM 應用,包括醫(yī)學問答、臨床信息提取、索引、分診、和健康記錄管理。
幻覺和偏見:醫(yī)療領域的安全性是至關(guān)重要的,這意味著出現(xiàn)幻覺的可能性會極大地限制當前的用例。此外,為了降低 LLM 延續(xù)現(xiàn)有臨床數(shù)據(jù)集中的偏見的風險,還需要進一步的研究工作。
推理
數(shù)學和算法任務往往需要不同于傳統(tǒng) NLP 任務的能力集合,比如理解數(shù)學運算、復雜的多步推理和更長期的規(guī)劃。因此,現(xiàn)在人們也在努力研究如何將 LLM 用于這些任務以及如何提升 LLM 的能力。
性能表現(xiàn)不及人類:在推理基準任務上,現(xiàn)有的 LLM 難以比肩人類。
機器人和具身智能體
LLM 也已經(jīng)開始被集成到機器人應用中,以為機器人提供高層規(guī)劃和語境知識能力。
單一模態(tài)問題:盡管 LLM 可以幫助機器人或智能體理解指令和增添高層規(guī)劃能力,但它們卻無法直接學習圖像、音頻或其它感官模態(tài),這就限制了它們的應用。
社會科學和心理學
快速發(fā)展的 LLM 也在心理學和行為科學領域找到了潛在的應用場景。研究者分析了已有的文獻,找到了 LLM 在心理學和行為科學領域得到使用的三個主要方向:使用 LLM 來模擬人類行為實驗、分析 LLM 的人格特質(zhì)、使用 LLM 作為建模社會關(guān)系的人工智能體。如圖 15 所示。

圖 15:LLM 在社會科學和心理學領域的用例。
社會偏見:由于 LLM 的訓練數(shù)據(jù)中存在不平衡的觀點和意見,因此會使其傾向有偏見的人類行為。
生成合成數(shù)據(jù)
LLM 具備在上下文中學習的能力,因此可以通過 prompt 讓其生成合成數(shù)據(jù)集,用于訓練更小型的特定領域的模型。
帶幻覺的分布:由于我們現(xiàn)在還無法驗證生成的合成數(shù)據(jù)是否能否代表對應的真實世界數(shù)據(jù)的分布,因此目前還難以使用 LLM 生成完整的合成數(shù)據(jù)集。





