

作者 | .NEThercote
編譯 | 王瑞平、言征
Nethercote是一位研究Rust編譯器的軟件工程師。最近,他正在探索如何提升Rust編譯器的性能,在他的博客文章中介紹了Rust編譯器是如何將代碼分割成代碼生成單元(CGU)的以及rustc的性能加速。
他解釋了不同數量和大小的CGU之間的權衡以及Rustc是如何使用LLVM并行化代碼生成和優化的。此外,Nethercote還探索了一些形成和排序CGU的替代方法,并報告了他的實驗結果。
Nethercote發現,很多時候,無法在編譯速度、內存占用、編譯體積和質量上都實現提升,一個指標的提升,經常伴隨另一個性能指標的下降。盡管他沒有發現比現有方法更明顯的改進,但還是希望在未來繼續研究這個問題。
如何提升Rust編譯器速度?這篇文章或許能幫助到你!
LLVM:Rust編譯加速的秘訣Rust的MIR是HIR到LLVM IR的中間產物,將MIR轉換為LLVM IR,然后將其傳遞給LLVM,從而生成機器代碼。
在此過程中,LLVM能通過處理多個模塊實現并行。Rustc使用LLVM加速Rust的編譯。我們稱其中的每個模塊為 “代碼生成單元(CGU)”。
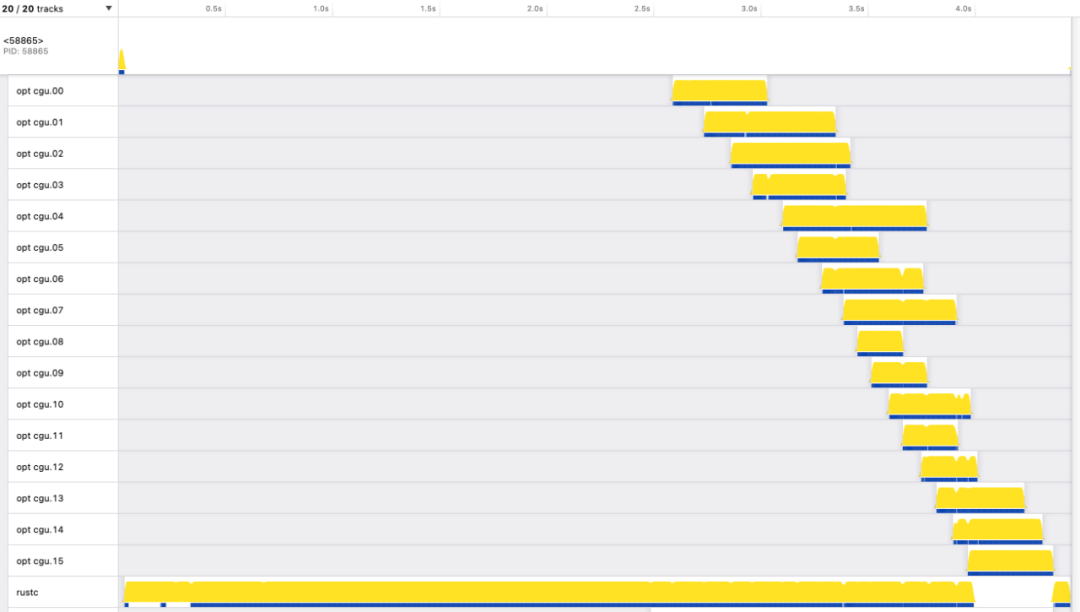
圖:時間位于 x 軸上,每條水平線代表一個線程。主線程顯示在頂部,標有 PID。它在開始時處于活動狀態,時間足以產生另一個標記為 的線程rustc。rustc底部顯示的線程在大部分執行過程中都處于活動狀態。還有 16 個 LLVM 線程標記opt cgu.00為 到opt cgu.15,每個線程都會在短時間內處于活動狀態。
CGU實際上是如何形成的呢?粗略地說,Rust 程序由許多函數組成,這些函數形成一個有向圖,其中從一個函數到另一個函數的調用構成了一條邊。我們需要將這個圖分割成塊(CGU),這是一個圖分區問題。我們希望創建大小大致相等的 CGU(因此 LLVM 處理它們所需的時間長度大致相同),并最大限度地減少它們之間的邊數(因為這使 LLVM 的工作更輕松,并帶來更好的代碼質量) 。
實際上,由于我們上面看到的階梯效應,我們不希望 CGU 的大小完全相同。理想的情況是 CGU 大小存在與梯度相匹配的輕微梯度。這樣,所有 CGU 將完全相同地完成處理,以實現最大程度的并行化。
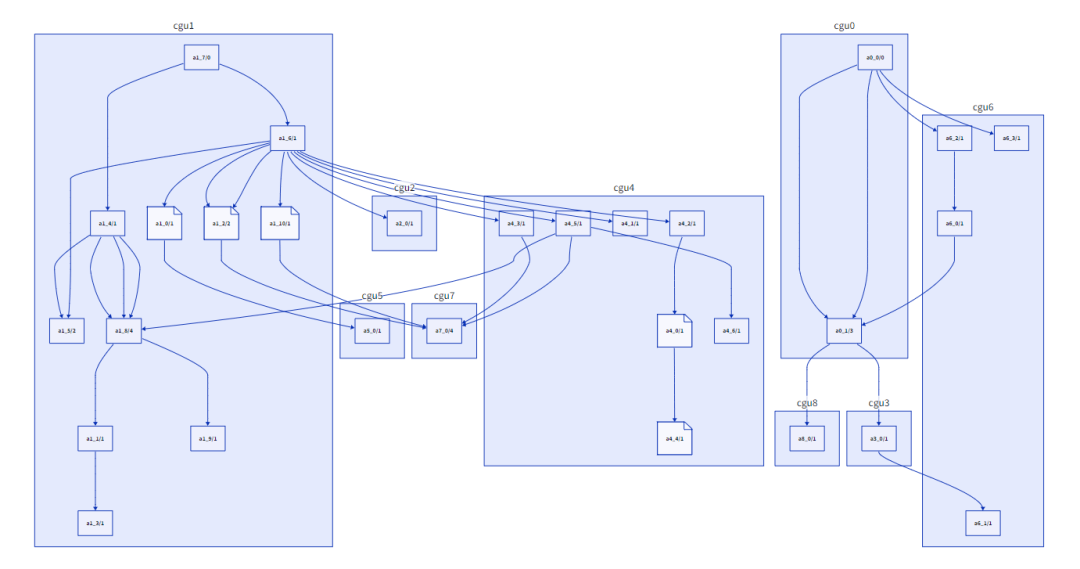
合并之前的CGU(9個)
Nethercote認為在合并之前“調整”CGU可能會有所幫助,在某些情況下將函數從一個CGU移動到另一個。例如,如果在CGU A中被調用f的葉函數(即不調用任何其他函數的葉函數)在CGU B中有一個調用方g,那么將f從A移動到B是有意義的,從而去除CGU間的邊。(還有其他類似的情況涉及非葉函數,移動也有意義)。我實現了這一點,它給出了一些適度的改進,但我目前還沒有決定它是否值得額外的復雜性。
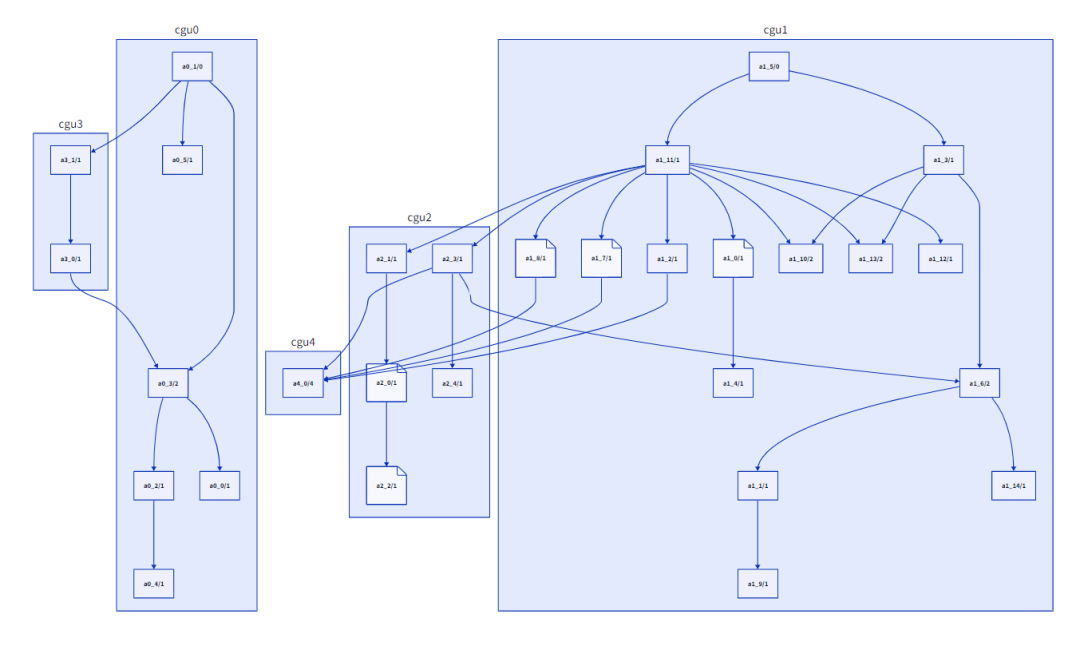
調整之后的CGU(5個)
在實現這一點的同時,我還花了一些時間來可視化調用圖。我從GraphViz開始。這些圖表對于非常小的程序來說看起來不錯,但對于較大的程序來說,它們很快就變得無法讀取和導航。我在Mastodon上抱怨過這一點,并得到了使用d2的建議,d2速度較慢,但圖形可讀性更強。
后端并行方法的軟肋
圖劃分是一個 NP 難題。有幾種常見的算法,實現起來相當復雜。相反,rustc 做了一些更簡單的事情。首先簡單地為每個 Rust 模塊創建一個 CGU:模塊中的每個函數都放入同一個 CGU 中。然后,如果 CGU 數量超過限制(默認情況下,非增量構建為 16 個,增量構建為 256 個),它會重復合并兩個最小的 CGU,直到達到限制。這種方法簡單、快速,并以有用的方式利用特定領域的知識——程序模塊往往提供良好的自然邊界。
所有這一切都依賴于測量 CGU 大小的方法。目前使用CGU中的MIR語句的數量來估計LLVM處理CGU需要多長時間。這里有很大的設計空間,有許多其他可能的形成和規劃CGU 的方法。
這種轉換對Rust眾多語法糖進行了脫糖,并且極大精簡了Rust的語法(但并非其語法子集),是觀察和分析Rust代碼的常用手段,尤其是在控制流圖和借用檢查等方面。
在這篇文章的最后, Nethercote提供了幾個數據集的鏈接,每個數據集都記錄了編譯rust -performance基準時每個CGU的測量值。這些數據集包括許多測量靜態代碼大小的輸入(獨立變量),例如,函數數量和MIR數量等。
Nethercote試著用scikit-learn做一些基本的分析。并且,通過這些基本的分析,能讓 Nethercote仔細推敲到底應該搜集哪些測量值。
通過一系列的改進優化,他獲得的最終數據集比剛開始時的數據更準確。但是,并沒有通過這些數據獲得多少實際的結果。實際上,每次我對測量的內容改變后都會得到完全不同的結果。
實現更快的Lexer
詞法分析(lexical analysis)是編譯器的第一個階段,實現詞法分析的代碼稱為lexer。
有人最近研究了logos(https://Github.com/maciejhirsz/logos)這個在rust中廣受歡迎的lexer。
此前,logos聲稱其目標是能比手動實現的lexer更快,作者提出了質疑,因為在他看來,通用性和性能無法兼得。因此,他一步步實現了lexer,探索了多種優化技巧,并與logos進行了多輪性能對比。
最終的結果表明,手動實現的基于狀態機的lexer比logos實現了20%左右的性能提升。
從錯誤中學習:使用Rust實現DLL注入Rust是一種注重安全性的編程語言,但在某些情況下,開發人員可能需要使用 unsafe關鍵字來執行某些操作。
unsafe可以提供更高的性能,但可能會犧牲安全性。因此,開發人員在使用時需要非常小心。
幾個使用 unsafe的常見場景包括:訪問裸指針、調用外部C函數等,并提供了一些建議和最佳實踐,以確保在使用 unsafe時不會引入潛在的安全隱患。
舉個應用方面的例子:原來,作者一直在用C++編寫逆向工具,但是,C++這門語言并不友好,于是研究了下如何使用Rust實現DLL注入的“工具”。
大致原理就是讓Rust首先生成一個C樣式的DLL,然后,使用 unsafe操作裸指針,操作程序內存,最后實現DLL注入就可以了。
期待更準確的估計函數
Nethercote 希望具有數據分析專業知識的人可以做得更好, 重點關注以下幾個方面:
1.更匹配的估計函數
2.想要使編譯器比現在更快,一個更好的估計函數也許不會達到預期的效果。我提出了一些更好的統計方法,但并沒有提升編譯速度,甚至變差。
3.CGU調度效果不可預測,你不能假設一個估計函數好幾個百分點就會使編譯器更快。話雖如此,我希望改進力度足夠大,能夠轉化為實際的加速。
4.對于估計函數來說,最好高估CGU編譯所需的時間,而不是低估。
5.我很擔心過度擬合。數據集來自一臺機器,但實際上,rustc會運行在不同的機器上,具有各種各樣的體系結構和微體系結構。
6.這些數據集來自單一版本的rustc,使用單一版本的LLVM。我擔心隨著時間的推移準確性可能會漂移。
7.我更喜歡不太復雜且易于理解的估計函數。當前的函數非常簡單,在大多數情況下只是增加了基本模塊和語句的數量。例如:0大小的CGU應該別估計為花費非常接近于0的時間。
8.估計函數有一個明確的問題,即如果不考慮其內部公式,計算MIR語句可能非常不準確。特別是,單個MIR語句可能變得很長。舉個例子:深度向量壓力測試的MIR包含一條語句,該語句定義了包含超過100,000個元素的向量字面量。不出所料,當前的估計函數嚴重低估了編譯這個基準所需的時間。
Nethercote最后提醒: 希望以上的請求是合理的!
以下是上文提到的數據集:
•調試構建,主要基準測試
https://nnethercote.github.io/aux/2023/07/25/Debug-Primary.txt
•選擇構建,主要基準
https://nnethercote.github.io/aux/2023/07/25/Opt-Primary.txt
•調試構建,二級基準測試
https://nnethercote.github.io/aux/2023/07/25/Debug-Secondary.txt
•選擇構建,二級基準
https://nnethercote.github.io/aux/2023/07/25/Opt-Secondary.txt
·順便說一句:在這些數據集中, 主要基準測試比 次要基準測試更重要,次要基準測試包括壓力測試、微基準測試和其它不符合實際的代碼。
參考資料:
1.https://nnethercote.github.io/2023/07/25/how-to-speed-up-the-rust-compiler-data-analysis-assistance-requested.html
2.https://geo-ant.github.io/blog/2023/unsafe-rust-exploration/
3.https://nnethercote.github.io/2023/07/11/back-end-parallelism-in-the-rust-compiler.html
1.從C++98到C++26,經歷了什么? 2.linux桌面版,又被噴了!
3. 堪比Midjourney!妙鴨相機為什么突然火爆?





