
【CSDN 編者按】本文作者非常喜歡 Rust,同時又 Julia 所吸引,當他體驗完 Julia 編程語言后,他覺得 Julia 并未像對外宣傳的那樣,解決了雙語言問題,并且在科學計算方面,他反而更加推薦 Rust,這是為何?
原文鏈接:https://mo8it.com/blog/rust-vs-julia/
作者 | Mo 譯者 | 彎月
責編 | 夏萌
出品 | CSDN(ID:CSDNnews)
Julia 的主要目標之一是解決雙語言問題。這意味著,在使用 Julia 的時候,你不必為了靈活性而使用 Python/ target=_blank class=infotextkey>Python 等動態語言構建原型,然后再為了性能而使用 C/C++ 等編譯語言重寫代碼。
在為大學論文選擇編程語言時,Julia 的這個目標確實吸引了我。但在使用了一段時間 Julie,并負責教授 Julia 之后,我仍然認為 Julia 解決了雙語言問題嗎?
為什么我認為在某些情況下 Rust 才是實際的解決方案?
警告
我必須聲明,我非常喜歡 Rust!
因此,在本文中我會格外偏袒 Rust。但我確實經常使用 Julia,還擔當過 Julia 假期課程的講師,而且我很高興在大學里傳播這門語言。但我認為 Julia 的承諾可能會產生誤導,而且在有些情況下,Rust 確實比 Julia 更適用。詳情參見下文。
文中的示例代碼使用 Rust 1.71.0 和 Julia 1.9.2 進行了測試。
并發
在 Julia 中,多線程的使用非常簡單,你只需要在 for 循環前面加上 @threads 宏!
雖然多線程的使用非常簡單,但 Julia 并沒有確保安全性。下面,我們來看一個眾所周知的例子:

如果你不熟悉多線程,那么肯定會認為結果應該是 10_000。但試著運行幾次,你就會發現得到的結果大致如下:
由于數據爭用,所以輸出是隨機的。
發生這種數據爭用是因為線程會讀取 counter 的當前值,將其加 1,然后將結果存儲在同一個變量中。如果兩個線程同時讀取該變量,然后加 1,則最后的結果相同,而且都會被存儲到同一個變量中,這意味著少了一次加法運算。
下面演示了沒有數據爭用的情況:
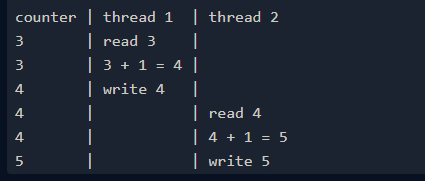
發生數據爭用時,加法運算會少一次:
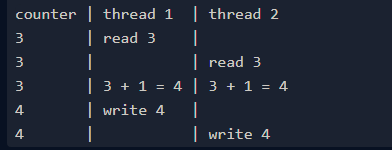
下面,我們將 Julia 轉化為 Rust:
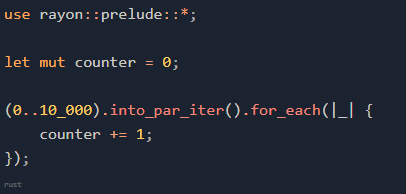
此處,我們使用了 rayon,這個 crate 通過迭代器提供了簡單的多線程處理。
幸運的是,上面的 Rust 代碼無法編譯!
在 Rust 中,你只能有一個可變引用但沒有不可變引用,或者任意數量的不可變引用但沒有可變引用。
數據爭用的發生條件是有多個可變引用。例如,在上面的 Julia 代碼中,每個線程都有自己的 counter 變量的可變引用!上面的借用規則使得 Rust 中的數據爭用變得不可能!
為了讓上述 Rust 代碼通過編譯,我們需要使用 Mutex 或原子。原子可以從硬件級別上確保支持的操作以原子方式完成,也就是說只有一步操作。由于原子比 Mutex 的性能更好,因此我們將使用 AtomicU64(64 位無符號整數):
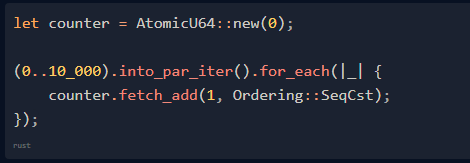
請注意,此處的 counter 不再是可變的!let 后面沒有 mut。由于原子類型的操作不會引入數據爭用,因此它們都是不可變引用 &self(而不是可變引用 &mut self)。這樣,我們就可以在多個線程中使用了(因為 Rust 允許有多個不可變引用)。
上述 Rust 代碼將返回結果 10_000。
如果編譯成功,就不會出現數據爭用的問題。
正確的 Julia 代碼與 Rust 版非常相似:
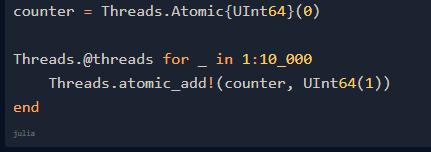
這意味著 Julia 也有原子,但它無法檢測到可能出現的數據爭用,無法給出建議或警告。
Julia 的多線程文檔指出:“確保程序不存在數據爭用由您全權負責。”
如今摩爾定律幾乎已失效,至少對于單核性能而言是如此。因此,我們需要一種語言,降低使用并發的難度,同時確保正確性。
項目的可擴展性
隨著項目的發展,維護、擴展和推理 Julia 代碼的正確性有多困難?
靜態分析
由于即時(JIT)編譯,高度優化的 Julia 代碼的性能可以與 Rust 很接近。
但生成優化的機器代碼并不是編譯器的唯一目標。Julia 缺少編譯器的一個非常重要的優點:靜態分析!
我們來看看如下 Julia 代碼示例:

你發現問題了嗎?Julia 會逐行運行代碼,直到遇到有問題的那一行。
運行上述代碼,你會看到屏幕上輸出 OK,然后才能收到錯誤,因為 pop 的語法有錯,這是 Rust 的寫法,在 Julia 中我們應該使用 pop!(v)。
你可能覺得這不是什么大問題,簡單地運行一下測試就會發現這個 bug。
但是,如果錯誤代碼背后的某些條件取決于程序輸入或只是隨機的(如蒙特卡羅模擬),該怎么辦?下面是一段演示代碼:
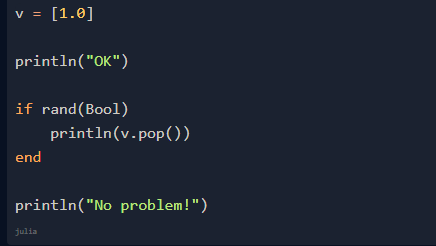
運行上述 Julia 代碼,你應該有大約 50% 的機會順利通過有 bug 的代碼,并輸出 No Problem!。
這是一個很嚴重的問題。這種類型錯誤可以通過簡單的具有靜態分析的類型系統來防止。
為什么我要在可擴展性的主題下談論靜態分析?
假設我們正在編寫一些分子動力學模擬。如下例所示:

為了創建一些粒子,我們需要將它們的位置存檔到向量中。在本示例中,我們來計算它們到原點的距離和質心(假設它們的質量均為 1)。
假設稍后我們需要考慮粒子的電荷,以獲得更好的模擬精度。為此,我們創建一個名為 Particle 的結構來存儲位置和電荷:

如上所示,particles 向量保存的不再是位置,而是 Particle 實例。
現在還沒有使用引入的電荷。我們只是想確保沒有破壞其他代碼。
運行代碼,我們會收到一個錯誤,因為我們在算到原點的距離時嘗試索引到 Particle 結構而不是位置向量。
你可能認為,這不是什么大問題。我們只是忘了修改那行代碼。下面,我們來修改代碼:

修改好代碼,再次運行,我們又遇到了另一個錯誤。我們還需要修改計算質心的那行代碼。
你可能會覺得問題不大,我們可以像下面這樣輕松修復代碼:
如果是修改一個大型程序,你需要花費多少時間來反復修改和運行代碼?
如果代碼正常運行,沒有任何錯誤,你能確保沒有漏掉任何需要修改的代碼嗎?
這種影響大面積代碼庫的變更叫做“重構”。
Rust 中的重構是一個非常絲滑的編譯器驅動過程。編譯器會拋出所有你尚未修改完成的代碼。你只需要按照編譯器的錯誤列表逐個修改即可。解決這些難題后,程序就能通過編譯,而且你基本可以確定沒有遺漏。
運行時不會出錯!
當然,這并不意味著你不會忘記與程序邏輯相關的修改,為此你應該運行一些測試。
用 Rust 編寫測試時,你測試的是程序的邏輯。你應該確保仍然能夠獲得特定輸入的預期輸出。但是你不需要測試代碼是否存在系統錯誤或可能出現的崩潰。
我們可以為 Julia 構建一個 linter,就像 Python 的許多 linter 一樣。動態類型語言的 linter 之類的工具在功能性和正確性上永遠無法企及基于良好類型語言構建的靜態分析。這就像在脆弱的地基上抹水泥,只是為了讓它更加安全一點。
錯誤處理
上述,我們討論了可以通過靜態分析檢測到的系統錯誤。
那么,編譯時無法直接檢測到的錯誤怎么辦?
Julia 提供了處理此類情況的例外。那么 Rust 呢?
Option:存在或不存在,這是一個問題
在Julia 中運行以下代碼,結果會怎樣?
由于只有一個值,因此第二個 pop! 會失敗。但結果如何呢?
Julia 會在運行時出錯。
Rust 可以防止這種情況發生嗎?我們來看看在 Rust 中 Vec(Vec 是向量,T 是泛型)的 pop 簽名:
上述代碼接受保存 T 類型值的向量的可變引用,并返回 Option。
此處的 Option 只是一個枚舉,一個非常簡單但非常強大的枚舉!
標準庫中 Option 的定義如下:

這意味著,Option可以是 None 或 Some(T 類型的 some 值)。
我們再來看看上面的 Julia 代碼在 Rust 中是什么樣子:

嘗試編譯,你會收到一條可愛的錯誤消息,如下所示(Rust 擁有最優秀的錯誤消息):
最簡單的處理 Option 方法是使用 unwrap:
unwrap None 的行為就跟 Julia 一樣,會在運行時引發錯誤。
你不應該在生產代碼中使用 unwrap。在 Rust 中,你應該使用正確的枚舉處理:
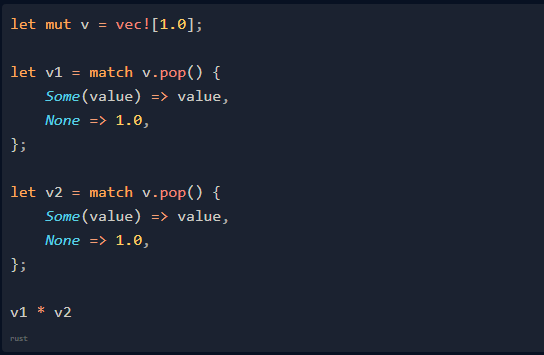
我們使用模式匹配來處理Option, 如果 Option 為 None,則我們使用 1 作為乘法的中性元素。
你可能會認為上述代碼包含很多樣板代碼。沒錯,但這只是模式匹配的演示,為的是說明處理 Option 的工作原理。
上面的代碼可以簡化如下:
Option 的 unwrap_or 實現如下:

你可能會認為如果向量為空,那么不應該是 1。你可以用不同的方式處理。但是,你只需考慮如何正確處理某些代碼未按預期工作的情況。
失敗不是一種選擇,而是一種結果!
假設你想使用 Julia 編寫長時間模擬的結果:
如果 Julia 無法打開文件,例如目錄 results/ 不存在,結果會怎樣?
你可能已經猜到了:運行時錯誤。
這意味著結果會丟失,你必須修復錯誤,然后重新運行模擬。
你可以將上面的代碼包裝在 try/catch 語句中,然后將結果轉儲到 /tmp 中并告訴用戶。
但首先,Julia 不會強迫你處理異常。該語言本身甚至不會告訴你可能出現的異常,使用每個函數之前,你必須閱讀相關文檔,搞明白它是否可能引發異常。如果文檔沒有記載可能出現的異常,該怎么辦?為了安全起見,你可以將所有代碼包裝在 try/catch 語句中。
還有比異常更好的方法嗎?我們來看看上面代碼的 Rust 版本:
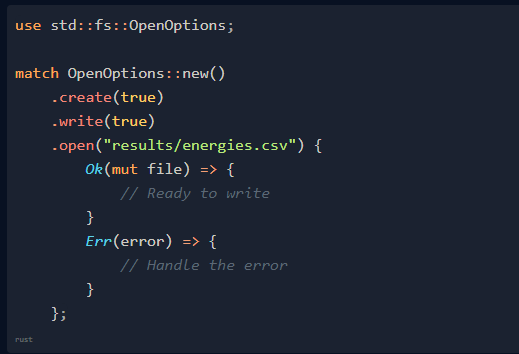
在上面的代碼中,open 會返回 Result。Result(帶有泛型 T 和 E)是 Rust 中第二個重要的枚舉:

open 會強制你處理可能出現的 IO 錯誤,就像 pop 會強制你處理 None 一樣。
有了異常,你就知道函數會返回一些值,而且還可能會出現異常。但對于 Result 和 Option,函數簽名的類型將告訴你是否有可能發生錯誤,不至于出現出人意料的結果。
Rust 可以確保不會漏掉任何一種情況,不會讓程序因你的失誤而崩潰。
你當然可以使用 unwrap 處理 Result,但它不是由于失誤引發的崩潰,而是你故意使其崩潰。
同樣,你需要重復運行多少次 Julia 代碼才能消除所有錯誤?這個周期所需的時間將如何隨著項目的復雜性而變化?
盡管你可以通過一些示例輸入測試 Julia 代碼,但你是否有信心它不會在某些時候崩潰?
而 Rust 可以給你足夠的信心,確保你的代碼是正確的。
接口
Julia 的多重調度和類型層次結構非常靈活。但是,我們假設一個庫引入了一個抽象類型,你可以為其實現具體類型。
如果函數接受該抽象類型作為參數,那么我應該實現哪些方法呢?
由于 Julia 還沒有接口,因此你可以通過以下三種方法來查找所需的方法:
-
直接使用具體類型作為抽象類型,重復運行代碼,同時逐個修復“未實現”的錯誤,然后祈禱最終你能涵蓋所有情況……
-
祈禱標準庫中有這類的文檔。
-
逐層深入閱讀源代碼,并嘗試找出函數內部使用了哪些方法。
公平地說,Julia 2.0 版本已經計劃了接口。但事實上這不是 1.0 的優先事項,這證明我的看法沒錯:Julia 的設計主要面向交互式用例,而非大型項目。
另一方面,Rust 的 trAIts 展示了所有必需以及可選的方法!
例如,Iterator 有一個必需的方法,即 next。你只需實現這個方法,就可以免費獲得所有其他方法!如果你愿意,還可以實現 size_hint 等可選方法。
無需嘗試,無需搜索可能并不存在的隱藏文檔,無需閱讀源代碼。Rust 可以在編譯時確保你實現了所有必需的方法。
性能
如上所述,經過良好優化的 Julia 代碼可以接近 Rust 的性能。但永遠無法達到其性能。
這是因為 Julia 有垃圾收集器,而 Rust 沒有!
Rust 還具有零成本抽象的原則。這意味著迭代器并不比舊的 for 循環慢。
實際上,迭代器甚至比 for 循環更快,因為它們避免了邊界檢查并允許編譯器使用 SIMD。
另一方面,如果你想在 Julia 中獲得最佳性能,則必須編寫 for 循環。
最大的問題在于,Julia 有一個性能絆腳石。
例如,如果你想初始化一個 v = [] 之類的空向量,那么代碼的性能就會降低到與 Python 同等水平,因為向量的類型為 Any,它可以存儲任何值!因此,Julia 無法再優化這個向量。你必須使用 v = Float64[] 等具體類型來初始化空向量,或者使用至少一個值(如 v = [1.0] )來初始化。
Julia并不會告訴你這樣的性能殺手!
我們都知道內存分配通常是一個瓶頸。Julia 提供及建議的預分配如下:
如果你不小心讀取了 undef(未定義)字段,結果會怎樣?v 可能的輸出結果如下:
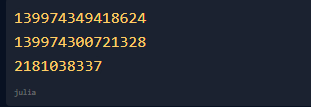
歡迎來到未初始化數據的未定義行為領域。
另一方面,在 Rust 中,你可以使用 with_capacity 初始化向量。但結果為空,長度為0。
容量不是長度。容量是向量可以容納而無需再次重新分配的數據量。長度是向量存儲的數據量。
容量總是大于或等于長度。你的目標是避免長度大于當前容量,因為當長度大于當前容量時,系統會重新給向量分配更大的容量。
抽象并去掉容量的概念,真的要比只提供和推薦可能導致未定義行為的方式更好嗎?
Rust 不允許未定義的行為,但允許你深入底層。
如果你想使用 Julia 編寫高度優化的代碼,就必須嚴格遵循官方提供的性能提示。即便你漏掉某個提示,導致性能降級到 Python 的水平,也不會收到警告。
如果性能不是可有可無,如果每一個改進都可以節省數小時的昂貴計算,那么最好還是使用 Rust!
語言服務器
即使你像我一樣使用編輯器,而不是 IDE,也應該使用語言服務器。
不幸的是,Julia 的語言服務器缺少很多功能。Rust-Analyzer 提供的功能更多,可以提高你的工作效率。
舉個例子,“將鼠標懸停在變量上”,以查看其類型。
在 Julia 中,“懸停”會顯示變量的聲明。
另一方面,在 Rust 中,“懸停”會顯示變量的類型。查看變量的類型可以幫助你了解該變量的實際含義以及如何使用。
在 Julia 中,你只能閱讀返回該變量的源代碼,并嘗試推斷出它的類型,或者運行程序并使用 typeof 來顯示它的類型。
如果你不記得特定方法的名稱,則可以瀏覽文檔,但通常只需鍵入變量名稱并在最后加上一個點(例如particles.),然后按 Tab 鍵就可以了。更多的輸入會觸發模糊搜索。接下來,你可以選擇方法并輸入參數,同時顯示簽名。
Julia 中的語言服務器可以顯示簽名,但由于動態調度,通常顯示的簽名是錯誤的。
至于 Rust 中的自動補齊和代碼操作就無須多言了,你可以自行嘗試。
許多問題都與 Julia 的動態類型有關,盡管人們認為動態類型比靜態類型“更容易”。但在 Rust-Analyzer 的幫助下,我可以輕松地駕馭類型,從長遠來看,我的工作效率會更高。
文檔
你可以看看 Julia 官方文檔中 Arrays 的介紹(https://docs.julialang.org/en/v1/base/arrays/)。
側邊欄有各個章節的鏈接,但導航也就僅限于此了。你可以在設置中更改主題!此外,還可以搜索,但是搜索速度比較慢,而且沒有過濾選項。
難怪一些程序員熱衷于 ChatGPT。也許是因為閱讀文檔也很痛苦吧。
我們來比較一下 Rust 文檔中 Vec 的介紹(https://doc.rust-lang.org/stable/std/vec/struct.Vec.html)。
rustdoc 是一個被低估的完美文檔!側邊欄中羅列了所有方法、實現的特征以及模塊導航。
搜索欄會提示你按S進行搜索,按問號(?)可以顯示更多選項,而且它還有鍵盤快捷鍵。
將鼠標懸停在代碼示例上,右上角會顯示一個按鈕,點擊就可以在 Rust Playground 上運行這段代碼,從而方面用戶快速實驗。
代碼示例會在發布之前自動測試。API 變更后不會出現不同步的示例。
你可以搜索、過濾結果、搜索函數參數或返回類型等等。
所有 crate 的文檔都會自動發布在 docs.rs 上。你只需學會在 rustdoc 中導航,沒必要通過 AI 從各處收集代碼片段。
此外,下載 crate 就可以擁有離線文檔。只需運行命令“cargo doc --open”即可。在沒有網絡的地方很方便。
Julia 的優點
說了一大堆缺點,下面我們來看看 Julia 的優點。
交互性
根據官網的介紹,除了性能之外,Julia 的第二大賣點是:
“Julia 是動態類型,使用感受很像一種腳本語言,而且能夠很好地支持交互式使用。”
這就是 Julia 的強項。
雖然 Rust 有 evcxr 和 irust,但達不到 Julia REPL 的體驗,因為 Rust 是靜態類型。
Julia REPL非常強大。這是迄今為止我用過的最好的 REPL。盡管 Python 也是動態類型,但 Julia REPL 完勝 Python REPL。
你甚至可以使用 UnicodePlots 在 REPL 中繪圖。我經常使用它來進行一些快速計算或生成一些繪圖。
Rust 是 notebook?Rust 有一個 Jupyter 內核,但體驗差的很遠。當然 Rust 的設計初衷也不在于此。
另一方面,Julia 非常適合 Jupyter notebook。如果你想進行數據分析、繪制圖表并展示結果,那么 Jupyter notebook 是不二之選。
許多人認為 Jupyter Notebook 是為 Python 發明的。但你知道“Jupyter”這個名字是由 Julia、Python 和 R 組成的嗎?
你可能會問,為什么不直接使用 Python 來編寫 notebook 呢?
“Julia vs Python”是另一個話題,我只挑要點說。Julia 的性能優于 Python,處理數組(向量、矩陣、張量)更加容易,而且 Julia 有一個以科學計算為中心的生態系統,其中包含許多獨特的包(稍后會詳細介紹)。
另外,Julia 就是用 Julia 編寫的。因此閱讀和貢獻代碼更加容易。而對于 Python,幾乎所有性能良好的包都是用 C 編寫的,所有你必須閱讀 C 代碼。
一般來說,如果你在科學背景下教授的編程課,請選擇 Julia!對于大多數面向初學者的科學用例來說,Julia 更容易學習和使用。
我們也可以為科學領域想要編寫大型項目(例如長時間模擬)的學生提供一門教授 Rust 的選修課程。但 Rust 不應該是入門語言,除非你的學生來自計算機科學。
許多科學計算都與線性代數、數據分析和繪圖有關。我認為 Julia 的交互性和性能非常適合這一領域。
科學生態環境
Julia 擁有一個龐大的生態系統,其中包含許多科學包。
你可以獲得開箱即用的數組,并且已預安裝 LinearAlgebra.jl!
你可以使用 Plots.jl 甚至是 Makie 在 Julia 中繪制圖形。Makie 是一個具有硬件加速功能的完整可視化生態系統。
Rust 有 Plotters,我也很喜歡,但它還有很長的路要走。目前,仍然需要大量樣板代碼以及許多手動調整。相較而言,Julia 提供的繪圖體驗更好。
此外,Julia 還擁有一些出色的軟件包可用于求解微分方程、數值積分,以及新符號的計算。處理單位和測量誤差也是 Julia 的夢想!
使用哪種語言
對于科學計算,我建議以下項目使用 Rust:
-
需要大量并發;
-
需要最大性能;
-
代碼量超出一個腳本;
-
需要長時間運行,并且必須可靠;
-
無法承受 Julia 的延遲;
-
在集群上運行。
另一方面,Julia 則更適合以下項目:
-
需要互動性;
-
科學計算課程;
-
時間限制為大約一周(例如學生交作業);
-
使用繪圖。
我個人的結論
回到最初的問題:Julia 解決了雙語言問題嗎?
在我看來,答案是否定的。
盡管 Julia 有一個可以使其非常高效的即時編譯器,但它缺少靜態類型語言編譯器的優勢。
人們選用 C/C++ 不僅僅是為了性能,也是為了提高項目的可擴展性,以及在編譯時消除許多類別的錯誤。與 C/C++ 相比,Rust 消除的錯誤更多。對于科學計算來說,最重要的是數據爭用和未捕獲的異常。
即使你只關心性能,在避免 Julia 性能絆腳石的情況下獲得最大性能,那么也請使用 Rust。
就個人而言,目前我會使用 Julia 來快速測試 REPL 中的一些數值想法,每周提交有關數值的講座和繪圖。而對于其他一切工作,包括非每周提交的成果和項目,我都會使用 Rust。
對于某些項目,我甚至會同時使用兩者,導出 Rust 程序的結果,然后使用 Julia 實現可視化。
雖然雙語言問題沒有得到解決,但我很高興在科學計算領域 Julia 取代了 Python,而 Rust 取代了 C/C++(不僅僅是在科學計算方面)。這是編程語言的必要演變。
這不是一場戰爭,兩種語言應該共存。





