擊這里在線咨詢客服")
譯者 | 劉濤
您可能已經(jīng)使用過一些AI寫作檢測器,但是現(xiàn)在您想知道AI檢測是如何工作的,對么?我不是AI研究專家。但是,我可以從數(shù)據(jù)科學(xué)的角度來解釋這個問題。
我將講述:
- 什么是AI檢測
- 在訓(xùn)練這些模型時,需要用到哪些技術(shù)
- 誰需要使用它們
- 其他重要的常見問題
什么是AI檢測?
AI檢測是利用復(fù)雜的機(jī)器學(xué)習(xí)和自然語言處理模型,實(shí)現(xiàn)對人工文本與機(jī)器文本的區(qū)分。它包括使用人工智能檢測軟件,該軟件在已建立的文本庫中進(jìn)行訓(xùn)練,從而開發(fā)預(yù)測算法,這種算法能夠從新的測試材料中識別出模式。然后,您會獲得一個概率分值,用于判斷該被評估的材料是通過人工創(chuàng)建還是自動創(chuàng)建的。
為什么AI文本檢測很重要?
人工智能文本檢測對于確保信息的可靠性非常重要,在搜索引擎優(yōu)化(seo)、學(xué)術(shù)界和法律領(lǐng)域也能發(fā)揮關(guān)鍵作用。
AI內(nèi)容生成器無疑很有用,而且在競爭中必不可少。但它們同樣也是出了名的不可靠。因此,無論是谷歌,還是學(xué)校,以及客戶,都想要確定內(nèi)容,您不能不加審核就把原創(chuàng)內(nèi)容發(fā)出去。
您能想象如果人們被允許:
- 不經(jīng)事實(shí)核實(shí)就寫有關(guān)金錢和生活的話題(YMYL)
- 發(fā)表的期刊文章中“同行評議”這一術(shù)語不再具有任何價值
- 提供通用的AI智能生成的法律建議
信任將不復(fù)存在。
這也是為什么您要用到這些工具的原因,因為在大部分時間里,人們并不知道它們之間的區(qū)別。
AI文本檢測是如何工作的
我們再深入看下這些工具有那些不同的工作方式。
但這里有兩個主要概念:
- 語言分析:檢查句子結(jié)構(gòu)以尋找語義或重復(fù)。
- 對比分析:與訓(xùn)練數(shù)據(jù)集進(jìn)行比較,尋找與先前識別的實(shí)例的相似性。
這些是訓(xùn)練模型以使用上述兩個概念來檢測 AI 內(nèi)容時使用的更常見的一些技術(shù)。
分類器:AI檢測的分類帽
分類器有點(diǎn)像哈利波特中的分類帽,將數(shù)據(jù)分到預(yù)先確定的類中。
使用機(jī)器或深度學(xué)習(xí)模型,這些分類器檢查各種特征,如用詞、語法、風(fēng)格和語氣,以區(qū)分AI生成的文本和人工書寫的文本。
想象一個散點(diǎn)圖,其中每個數(shù)據(jù)點(diǎn)都是一個文本條目,這些特征將形成坐標(biāo)軸。
那么,假設(shè)我們有兩個類:
- AI文本
- 人工文本
您所測試的任何文本都將屬于這兩個集群中的一個。下面是我制作的圖形,方便您看到。

分類器的工作是形成一個邊界來分隔這兩個類。
根據(jù)使用的分類器模型,一些示例包括:
- 邏輯回歸
- 決策樹
- 隨機(jī)森林
- 支持向量機(jī)(SVM)
- K-最近鄰(KNN)
注意:您不需要知道它們是什么,只需知道它們是以不同方式對數(shù)據(jù)進(jìn)行排序的算法。
該邊界可能是一條線、曲線或其他一些隨機(jī)形狀。
當(dāng)您測試一個新文本(數(shù)據(jù)點(diǎn))時,分類器會簡單地將它們放在這些類中的任何一個中。
嵌入:單詞的DNA
如果每個單詞都有自己的秘密代碼,就像我們在看一些驚心動魄的間諜電影一樣,會怎么樣?
在人工智能(AI)和語言理解方面,這正是發(fā)生的情況。
這些代碼被稱為嵌入式編碼(Embeddings)。本質(zhì)上,它們是單詞唯一的DNA。通過捕捉每個術(shù)語背后的核心含義,并理解每個術(shù)語在上下文中如何與其他術(shù)語相關(guān),這些嵌入式編碼形成了一個語義網(wǎng)絡(luò)。
這是通過將每個單詞表示為N維空間中的向量并運(yùn)行一些高級計算來實(shí)現(xiàn)的。它可以是2D、3D或302934809D。
注意:向量是一個同時具有大小和方向的量。但是對于這個解釋,只需把它當(dāng)作是圖表上的坐標(biāo)即可。
但是為什么是向量呢?
因為計算機(jī)無法理解單詞。令人震驚,但這是現(xiàn)實(shí)。因此,必須通過向量化將單詞首先轉(zhuǎn)換為數(shù)字。以下是一個表格示例:

注意:向量化的文本數(shù)值可以具有廣泛的取值范圍,不僅僅是二進(jìn)制的1或0。我只是為了更容易地可視化而做出了這樣的表格。
這是另一個在二維圖形上繪制向量的例子:

我確信您能夠想象三維物體的外觀,但請不要讓我描繪四維物體,因為沒人知道會是什么樣。然而,通過數(shù)學(xué)算法,計算機(jī)可以使用數(shù)學(xué)魔法來呈現(xiàn)出四維物體。
這正是谷歌運(yùn)作的方式。您在搜索欄中輸入內(nèi)容,卻能獲得與其驚人相關(guān)的結(jié)果,這是如何實(shí)現(xiàn)的呢?
但是,如何區(qū)分人工生成的文本與使用 AI 生成的文本呢?
我們將所有文本轉(zhuǎn)換為它們各自的嵌入式向量,然后將它們輸入機(jī)器學(xué)習(xí)模型進(jìn)行訓(xùn)練。
模型即使不知道任何實(shí)際的措辭,也會形成所有這些連接,并找出與 AI 生成文本常見的所有“代碼”。
但是,如何區(qū)分人工生成的文本與使用 AI 生成的文本呢?
我們將所有文本轉(zhuǎn)換為它們各自的嵌入式向量,然后將它們輸入機(jī)器學(xué)習(xí)模型進(jìn)行訓(xùn)練。
模型即使不知道任何實(shí)際的措辭,也會形成所有這些連接,并找出與 AI 生成文本常見的所有“代碼”。
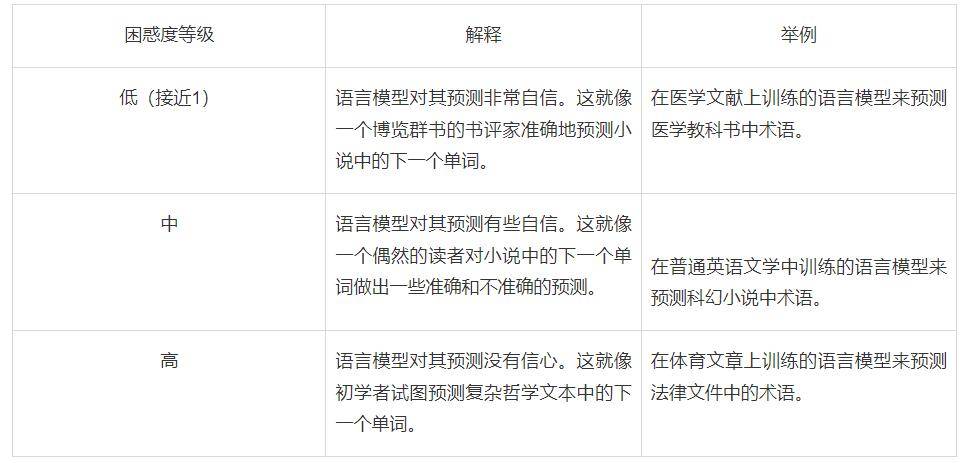
困惑度(Perplexity):AI 生成文本的試金石
困惑度是一個衡量概率分布或語言模型能夠預(yù)測樣本精度的指標(biāo)。
在 AI 生成內(nèi)容檢測的背景下,困惑度作為衡量 AI 生成文本的試金石。困惑度越低,文本由 AI 生成的概率越大。
這就像偵探使用指紋匹配來識別嫌疑人一樣。
以下的表格對此進(jìn)行了詳解:
爆發(fā)度(Burstiness):AI 生成文本的標(biāo)志性特征
爆發(fā)度是由 AI 模型生成的句子長度和復(fù)雜程度的變化。
想象一下您在一家餐廳里,現(xiàn)場充斥著各種對話,有些大聲喧嘩,有些安靜私密。與這些對話相似,由人寫出的句子有很多細(xì)微差別,因此常常讓人難以預(yù)料。
但是,AI 模型產(chǎn)生的結(jié)果通常在長度和復(fù)雜性上更趨于一致,而人類寫作則表現(xiàn)出更多的多樣性或者說“爆發(fā)性”。如果 AI檢測器注意到句子的長度、結(jié)構(gòu)和節(jié)奏的細(xì)微差異,它們也會將文本標(biāo)記為潛在的 AI生成文本。
以下表格中的一些例子:

AI 檢測的準(zhǔn)確性如何?
我會直截了當(dāng)?shù)馗嬖V您,即使分?jǐn)?shù)為100%,它也永遠(yuǎn)不會是100%準(zhǔn)確的。
那只是模型的置信度。
當(dāng) AI 檢測器分析文本時,它通常會基于所給材料的顯著特征計算每種分類的分?jǐn)?shù)或概率,而不僅僅由人類編寫或 AI 生成的內(nèi)容之間的區(qū)別所決定。
例如,假設(shè)我們使用 AI 檢測器對某些文本進(jìn)行了分析,它為“AI”和“人類”分別給出了0.7和0.3的分?jǐn)?shù)。
這些數(shù)字表示我們的檢測器已經(jīng)大致判斷出,我們的材料屬于同種類型和非同種類型的概率之比為7:3(70%對30%)。
因此,最終決定是否適用某種類型變得非常容易。
與其把事物劃分為“人類”與“AI”,倒不如給它們分配概率度量,這樣才能更深入地了解預(yù)測的可信度。除了把文字歸類成兩類外,還需要考慮許多因素來決定文字是由人寫的還是由AI寫的。
如果所使用的評估方法涉及計算概率得分,則這些得分之間的差距程度可能會影響 AI 模型對預(yù)測的確定性。
例如,如果分配給 AI 生成的作品和人工完成的作品的分?jǐn)?shù)之間沒有太大的差異(例如得分分別為0.51和0.49),那么檢測它們的來源將比它們的概率差距很大的情況更具挑戰(zhàn)性(例如獲得0.9和0.1的概率差距)。
因此,盡管產(chǎn)生二進(jìn)制結(jié)果,但這個決定包括詳細(xì)的分析,很大程度上依賴于概率得分之間的差異。
注意:您可能會看到其他文章討論 AI 檢測器如何通過計算每個單詞成為下一個預(yù)測單詞或溫度參數(shù)(temperature:指一種用于控制生成文本的隨機(jī)性和創(chuàng)造性的參數(shù),通常使用softmax函數(shù)實(shí)現(xiàn))的概率值來工作。這是指 AI 作者的工作方式,而不是 AI 檢測器。那些文章完全搞錯了搜索意圖。
這是一個相當(dāng)長的段落,但這是我能夠最好地解釋它的方式。
AI內(nèi)容檢測的前景如何?
隨著我們見證人工智能的進(jìn)一步發(fā)展,機(jī)器生成內(nèi)容的復(fù)雜程度也在不斷增加,這給有效檢測此類內(nèi)容帶來了獨(dú)特的挑戰(zhàn)。因此,所有參與其開發(fā)過程的人都需要努力創(chuàng)建更加先進(jìn)和準(zhǔn)確的工具,以跟上應(yīng)對這種復(fù)雜性的能力。
準(zhǔn)確檢測由AI生成的虛假信息對于維護(hù)在線信息的可信度至關(guān)重要,這將是有效應(yīng)對這些威脅的唯一途徑。
此外,我們需要特別關(guān)注與隱私侵犯、違背意愿和潛在的濫用這種強(qiáng)大技術(shù)相關(guān)的道德考慮。
誰使用AI檢測?
以下是一些最受益于使用AI檢測的群體:
學(xué)校:防止學(xué)生濫用AI寫作軟件。
企業(yè):擺脫垃圾郵件、虛假評論或虛假新聞。
執(zhí)法機(jī)構(gòu):消除冒充、身份欺詐和網(wǎng)絡(luò)欺凌等犯罪活動。
社交媒體平臺:清除散布和鼓吹不實(shí)信息的機(jī)器人和虛假賬號。
媒體和新聞組織:識別虛假新聞和宣傳,甚至替換過度依賴AI的作家。
政府組織:根除虛假信息的運(yùn)動和宣傳。
常見問題
AI內(nèi)容檢測工具是否存在限制或缺陷?
AI內(nèi)容檢測工具確實(shí)存在一些限制和缺陷。隨著人工智能產(chǎn)生的內(nèi)容不斷增多,人們越來越難分辨出這些文字是否是由人類產(chǎn)生的,因此它們的準(zhǔn)確性并不總是完美的。
此外,AI檢測器可能難以識別那些被特意設(shè)計成不可被檢測出的AI生成內(nèi)容。未來AI生成和檢測技術(shù)的發(fā)展將共同決定AI檢測的局限性程度。
為什么要在SEO中使用AI檢測?
盡管谷歌在最近的更新中表示,如果AI生成的內(nèi)容有價值,就不再會被視為垃圾內(nèi)容,但關(guān)于谷歌是否能夠檢測到AI生成的內(nèi)容,仍然有爭議。您永遠(yuǎn)無法真正知道谷歌何時或是否會改變立場而對您進(jìn)行懲罰。因此,大多數(shù)SEO(搜索引擎優(yōu)化)仍會使用AI檢測來確保安全。
AI檢測的準(zhǔn)確性如何?
AI檢測只能準(zhǔn)確判斷所檢測文本與其訓(xùn)練數(shù)據(jù)的相似程度。它提供的是置信度評分,而不是簡單的是或否的結(jié)果。
結(jié)論
我已經(jīng)介紹了您需要了解的有關(guān)AI檢測的所有內(nèi)容。從為什么需要它,訓(xùn)練這樣一個模型背后的真正過程,到它的準(zhǔn)確性以及它的前景。
我希望這可以幫助您更好地了解這個話題。
譯者介紹
劉濤,51CTO社區(qū)編輯,某大型央企系統(tǒng)上線檢測管控負(fù)責(zé)人。





