擊這里在線咨詢客服")
科創(chuàng)板日報(bào) 鄭遠(yuǎn)方
①微軟、AI target=_blank class=infotextkey>OpenAI、Cohere等公司已經(jīng)開始測試使用合成數(shù)據(jù)來訓(xùn)練AI模型; ②一方面,網(wǎng)絡(luò)上那些通用數(shù)據(jù)已不足以推動AI模型的性能提升,另一方面,真實(shí)數(shù)據(jù)售價(jià)高昂; ③但合成數(shù)據(jù)的負(fù)面影響堪比“毒藥”,可能讓AI大模型患上“癡呆癥”。
《科創(chuàng)板日報(bào)》7月22日訊(編輯 鄭遠(yuǎn)方)AI大模型對數(shù)據(jù)的龐大需求之下,AI公司們正在摸索一條獲取數(shù)據(jù)的“新路”——從零開始自己“造”數(shù)據(jù)。
微軟、OpenAI、Cohere等公司已經(jīng)開始測試使用合成數(shù)據(jù)來訓(xùn)練AI模型。Cohere首席執(zhí)行官Aiden Gomez表示,合成數(shù)據(jù)可以適用于很多訓(xùn)練場景,只是目前尚未全面推廣。
已有的(通用)數(shù)據(jù)資源似乎接近效能極限,開發(fā)人員認(rèn)為,網(wǎng)絡(luò)上那些通用數(shù)據(jù)已不足以推動AI模型的性能發(fā)展。Gomez便指出,網(wǎng)絡(luò)極為嘈雜混亂,“它并不能為你提供你真正想要的數(shù)據(jù),網(wǎng)絡(luò)無法滿足我們的一切需求。”
之前,ChatGPT、Bard等聊天機(jī)器人(13.250, -0.24, -1.78%)的訓(xùn)練數(shù)據(jù)多來自于互聯(lián)網(wǎng),例如電子書、新聞文章、博客、推特與Reddit的推文帖子、YouTube視頻、Flickr圖片等。但隨著AIGC技術(shù)愈發(fā)復(fù)雜,高質(zhì)量數(shù)據(jù)的獲取難度也越來越大。開發(fā)AI模型的科技公司們,也因不當(dāng)使用數(shù)據(jù)而遭受多方抨擊。
今年5月的一場活動上,OpenAI首席執(zhí)行官Sam Altman曾被問及,是否擔(dān)心監(jiān)管部門調(diào)查ChatGPT可能侵犯用戶隱私的事。Altman對此不置可否,并表示自己“非常有信心,很快所有數(shù)據(jù)都將是合成數(shù)據(jù)”。
▌人類真實(shí)數(shù)據(jù)售價(jià)高昂
為了大幅提高AI模型的性能,提升它們在科學(xué)、醫(yī)學(xué)、商業(yè)等領(lǐng)域的水平,AI模型需要的是“獨(dú)特且復(fù)雜”的數(shù)據(jù)集。而這類數(shù)據(jù)或是需要來自科學(xué)家、醫(yī)生、作家、演員、工程師等“內(nèi)行人”,或是需要從藥企、銀行、零售商等大型企業(yè)獲取專業(yè)數(shù)據(jù)。
這也就帶來了讓AI公司們轉(zhuǎn)向合成數(shù)據(jù)的另一層原因——數(shù)據(jù)太貴了。
且不說那些技術(shù)含量極高的制藥、科學(xué)數(shù)據(jù),光是之前Reddit和推特給出的數(shù)據(jù)采集要價(jià),都被Gomez“嫌棄”價(jià)格太高。
其中,Reddit本月起開始對數(shù)據(jù)接口使用收費(fèi)。根據(jù)第三方軟件Apollo的開發(fā)者Christian Selig透露,Reddit收費(fèi)標(biāo)準(zhǔn)為0.24美元/1000次API響應(yīng)——對于Apollo來說,這大約相當(dāng)于200萬美元/月開銷。
而根據(jù)推特今年3月發(fā)布的API政策,企業(yè)需要為抓取推文的API支付每月4萬美元至20萬美元不等的費(fèi)用,對應(yīng)可以獲得5000萬至2億條推文。而測算數(shù)據(jù)顯示,最低一個(gè)檔次的套餐只約等于整體推文的0.3%。
在這種情況下,合成數(shù)據(jù)自然成了一個(gè)實(shí)惠方案,不僅可以避開這些數(shù)據(jù)的高昂售價(jià),還能生成一些更復(fù)雜的數(shù)據(jù)來訓(xùn)練AI。
▌如何用合成數(shù)據(jù)訓(xùn)練?
具體如何用合成數(shù)據(jù)訓(xùn)練AI大模型?Gomez舉了一個(gè)例子:
在訓(xùn)練一個(gè)高級數(shù)學(xué)模型時(shí),Cohere可能會使用兩個(gè)AI模型進(jìn)行對話,其中一個(gè)扮演數(shù)學(xué)老師,另一個(gè)則充當(dāng)學(xué)生。之后這兩個(gè)模型就會就三角函數(shù)等數(shù)學(xué)問題對話,“其實(shí)一切都是模型‘想象’出來的”。
如果在這個(gè)過程中,模型說錯了什么,人類就會在查看這段對話時(shí)作出糾正。
而微軟研究院最近的兩項(xiàng)研究,也表明合成數(shù)據(jù)可以用來訓(xùn)練AI模型,這些模型一般比OpenAI的GPT-4、谷歌的PaLM-2更小更簡單。
在其中一篇論文中,GPT-4生成了一個(gè)名為“TinyStories”的短篇故事合成數(shù)據(jù)集,里面使用的單詞全部非常簡單,一個(gè)四歲兒童都能理解。這一數(shù)據(jù)集被用來訓(xùn)練一個(gè)簡單的大語言模型,后者能生成流暢且語法正確的故事。
另一篇論文中,AI可以通過合成的Python/ target=_blank class=infotextkey>Python代碼進(jìn)行訓(xùn)練,并在之后的編碼任務(wù)中給出相對較好的表現(xiàn)。
▌蜜糖還是砒霜?
想要合成數(shù)據(jù)的客戶有了,供應(yīng)商自然也如雨后春筍般涌現(xiàn),例如Scale AI、Gretel.ai等初創(chuàng)公司。Gretel.ai由來自美國國安局和中情局的前情報(bào)分析師成立,其已與谷歌、匯豐銀行、Riot Games、Illumina等公司合作,用合成數(shù)據(jù)來擴(kuò)充現(xiàn)有數(shù)據(jù),幫助訓(xùn)練人工智能模型。
Gretel.ai首席執(zhí)行官Ali Golshan表示,合成數(shù)據(jù)的關(guān)鍵在于,它既能保護(hù)數(shù)據(jù)集中所有個(gè)人的隱私,又能保持?jǐn)?shù)據(jù)的統(tǒng)計(jì)完整性。
同時(shí),合成數(shù)據(jù)還可以消除現(xiàn)有數(shù)據(jù)中的偏差和不平衡。“舉例來說,對沖基金可以研究黑天鵝事件,我們可以創(chuàng)建一百種變體,看看模型能否破解;而對于銀行來說,欺詐事件通常不到總數(shù)據(jù)的百分之一,Gretel的軟件可以生成成千上萬的欺詐案例,并以此訓(xùn)練AI模型。”
不過,也有人不看好合成數(shù)據(jù)。
反對派認(rèn)為,并不是所有合成數(shù)據(jù)都經(jīng)過精心調(diào)試,并能反映或改進(jìn)真實(shí)世界。
來自牛津、劍橋、帝國理工等機(jī)構(gòu)研究人員發(fā)現(xiàn),合成數(shù)據(jù)的負(fù)面影響甚至堪比“毒藥”。如果在訓(xùn)練時(shí)大量使用AI內(nèi)容,會引發(fā)模型崩潰(model collapse),造成不可逆的缺陷。
新一代模型的訓(xùn)練數(shù)據(jù)會被上一代模型的生成數(shù)據(jù)所污染,從而對現(xiàn)實(shí)世界的感知產(chǎn)生錯誤理解。隨著時(shí)間推移,模型就會忘記真實(shí)基礎(chǔ)數(shù)據(jù)部分。即使在幾乎理想的長期學(xué)習(xí)狀態(tài)下,這個(gè)情況也無法避免——研究人員也將此形容為“AI大模型患上‘癡呆癥’”。
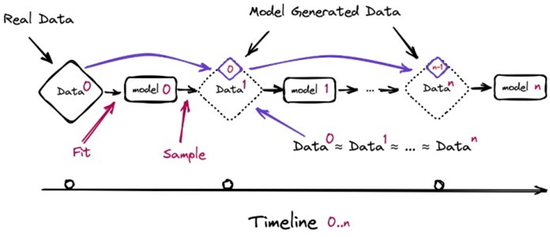
即便是合成數(shù)據(jù)從業(yè)人員Golshan也坦承,在劣質(zhì)合成數(shù)據(jù)上進(jìn)行訓(xùn)練可能會阻礙進(jìn)步。
“網(wǎng)上越來越多的內(nèi)容都是由AI生成的。隨著時(shí)間推移,這確實(shí)會導(dǎo)致退化,因?yàn)檫@些大模型產(chǎn)生的知識都是重復(fù)的,沒有任何新的見解。





