擊這里在線咨詢客服")
最近項(xiàng)目組安排了一個(gè)任務(wù),項(xiàng)目中用到了全文搜索,基于全文搜索 Solr,但是該 Solr 搜索云項(xiàng)目不穩(wěn)定,經(jīng)常查詢不出來數(shù)據(jù),需要手動(dòng)全量同步,而且是其他團(tuán)隊(duì)在維護(hù),依賴性太強(qiáng),導(dǎo)致 Solr 服務(wù)一出問題,我們的項(xiàng)目也基本癱瘓,因?yàn)樗械囊蕾嚥樵兌紵o結(jié)果數(shù)據(jù)了。所以考慮開發(fā)一個(gè)適配層,如果 Solr 搜索出問題,自動(dòng)切換到新的搜索——ES。
其實(shí)可以通過 Solr 集群或者服務(wù)容錯(cuò)等設(shè)計(jì)來解決該問題。但是先不考慮本身設(shè)計(jì)的合理性,領(lǐng)導(dǎo)需要開發(fā),所以我開始踏上了搭建 ES 服務(wù)的道路,從零開始,因?yàn)橹巴耆珱]接觸過 ES,所以通過本系列來記錄下自己的開發(fā)過程。
一、什么是全文搜索?
1.什么是全文搜索引擎?
百度百科:
全文搜索引擎是目前廣泛應(yīng)用的主流搜索引擎。它的工作原理是計(jì)算機(jī)索引程序通過掃描文章中的每一個(gè)詞,對每一個(gè)詞建立一個(gè)索引,指明該詞在文章中出現(xiàn)的次數(shù)和位置,當(dāng)用戶查詢時(shí),檢索程序就根據(jù)事先建立的索引進(jìn)行查找,并將查找的結(jié)果反饋給用戶的檢索方式。這個(gè)過程類似于通過字典中的檢索字表查字的過程。
從定義中我們已經(jīng)可以大致了解全文檢索的思路了,為了更詳細(xì)的說明,我們先從生活中的數(shù)據(jù)說起。
我們生活中的數(shù)據(jù)總體分為兩種:結(jié)構(gòu)化數(shù)據(jù) 和 非結(jié)構(gòu)化數(shù)據(jù)。
- 結(jié)構(gòu)化數(shù)據(jù):指具有固定格式或有限長度的數(shù)據(jù),如數(shù)據(jù)庫,元數(shù)據(jù)等。
- 非結(jié)構(gòu)化數(shù)據(jù):非結(jié)構(gòu)化數(shù)據(jù)又可稱為全文數(shù)據(jù),指不定長或無固定格式的數(shù)據(jù),如郵件,word文檔等。
當(dāng)然有的地方還會(huì)有第三種:半結(jié)構(gòu)化數(shù)據(jù),如XML,html等,當(dāng)根據(jù)需要可按結(jié)構(gòu)化數(shù)據(jù)來處理,也可抽取出純文本按非結(jié)構(gòu)化數(shù)據(jù)來處理。
根據(jù)兩種數(shù)據(jù)分類,搜索也相應(yīng)分為兩種:結(jié)構(gòu)化數(shù)據(jù)搜索和非結(jié)構(gòu)化數(shù)據(jù)搜索。
- 對于結(jié)構(gòu)化數(shù)據(jù),我們一般都是可以通過關(guān)系型數(shù)據(jù)庫(MySQL,oracle等)的 table 的方式存儲(chǔ)和搜索,也可以建立索引。
- 對于非結(jié)構(gòu)化數(shù)據(jù),也即對全文數(shù)據(jù)的搜索主要有兩種方法:順序掃描法,全文檢索。
- 順序掃描:通過文字名稱也可了解到它的大概搜索方式,即按照順序掃描的方式查詢特定的關(guān)鍵字。例如給你一張報(bào)紙,讓你找到該報(bào)紙中“RNG”的文字在哪些地方出現(xiàn)過。你肯定需要從頭到尾把報(bào)紙閱讀掃描一遍然后標(biāo)記出關(guān)鍵字在哪些版塊出現(xiàn)過以及它的出現(xiàn)位置。
這種方式無疑是最耗時(shí)的最低效的,如果報(bào)紙排版字體小,而且版塊較多甚至有多份報(bào)紙,等你掃描完你的眼睛也差不多了。
- 全文搜索:對非結(jié)構(gòu)化數(shù)據(jù)順序掃描很慢,我們是否可以進(jìn)行優(yōu)化?把我們的非結(jié)構(gòu)化數(shù)據(jù)想辦法弄得有一定結(jié)構(gòu)不就行了嗎?將非結(jié)構(gòu)化數(shù)據(jù)中的一部分信息提取出來,重新組織,使其變得有一定結(jié)構(gòu),然后對此有一定結(jié)構(gòu)的數(shù)據(jù)進(jìn)行搜索,從而達(dá)到搜索相對較快的目的。這種方式就構(gòu)成了全文檢索的基本思路。這部分從非結(jié)構(gòu)化數(shù)據(jù)中提取出的然后重新組織的信息,我們稱之索引。
還以讀報(bào)紙為例,我們想關(guān)注最近英雄聯(lián)盟S8全球總決賽的新聞,假如都是 RNG 的粉絲,如何快速找到 RNG 新聞的報(bào)紙和版塊呢?全文搜索的方式就是,將所有報(bào)紙中所有版塊中關(guān)鍵字進(jìn)行提取,如"EDG","RNG","FW","戰(zhàn)隊(duì)","英雄聯(lián)盟"等。然后對這些關(guān)鍵字建立索引,通過索引我們就可以對應(yīng)到該關(guān)鍵詞出現(xiàn)的報(bào)紙和版塊。注意區(qū)別目錄搜索引擎。
二、為什么要用全文搜索搜索引擎?
之前,有同事問我,為什么要用搜索引擎?我們的所有數(shù)據(jù)在數(shù)據(jù)庫里面都有,而且 Oracle、SQL Server 等數(shù)據(jù)庫里也能提供查詢檢索或者聚類分析功能,直接通過數(shù)據(jù)庫查詢不就可以了嗎?
確實(shí),我們大部分的查詢功能都可以通過數(shù)據(jù)庫查詢獲得,如果查詢效率低下,還可以通過建數(shù)據(jù)庫索引,優(yōu)化SQL等方式進(jìn)行提升效率,甚至通過引入緩存來加快數(shù)據(jù)的返回速度。如果數(shù)據(jù)量更大,就可以分庫分表來分擔(dān)查詢壓力。
那為什么還要全文搜索引擎呢?我們主要從以下幾個(gè)原因分析:
- 數(shù)據(jù)類型
全文索引搜索支持非結(jié)構(gòu)化數(shù)據(jù)的搜索,可以更好地快速搜索大量存在的任何單詞或單詞組的非結(jié)構(gòu)化文本。例如 google,百度類的網(wǎng)站搜索,它們都是根據(jù)網(wǎng)頁中的關(guān)鍵字生成索引,我們在搜索的時(shí)候輸入關(guān)鍵字,它們會(huì)將該關(guān)鍵字即索引匹配到的所有網(wǎng)頁返回;還有常見的項(xiàng)目中應(yīng)用日志的搜索等等。對于這些非結(jié)構(gòu)化的數(shù)據(jù)文本,關(guān)系型數(shù)據(jù)庫搜索不是能很好的支持。
- 索引的維護(hù)
一般傳統(tǒng)數(shù)據(jù)庫,全文檢索都實(shí)現(xiàn)得很雞肋,因?yàn)橐话阋矝]人用數(shù)據(jù)庫存文本字段。進(jìn)行全文檢索需要掃描整個(gè)表,如果數(shù)據(jù)量大的話即使對SQL的語法優(yōu)化,也收效甚微。建立了索引,但是維護(hù)起來也很麻煩,對于 insert 和 update 操作都會(huì)重新構(gòu)建索引。
什么時(shí)候使用全文搜索引擎:
- 搜索的數(shù)據(jù)對象是大量的非結(jié)構(gòu)化的文本數(shù)據(jù)。
- 文件記錄量達(dá)到數(shù)十萬或數(shù)百萬個(gè)甚至更多。
- 支持大量基于交互式文本的查詢。
- 需求非常靈活的全文搜索查詢。
- 對高度相關(guān)的搜索結(jié)果的有特殊需求,但是沒有可用的關(guān)系數(shù)據(jù)庫可以滿足。
- 對不同記錄類型、非文本數(shù)據(jù)操作或安全事務(wù)處理的需求相對較少的情況。
三、Lucene,Solr,ElasticSearch?
現(xiàn)在主流的搜索引擎大概就是:Lucene,Solr,ElasticSearch。
它們的索引建立都是根據(jù)倒排索引的方式生成索引,何謂倒排索引?
維基百科:
倒排索引(英語:Inverted index),也常被稱為反向索引、置入檔案或反向檔案,是一種索引方法,被用來存儲(chǔ)在全文搜索下某個(gè)單詞在一個(gè)文檔或者一組文檔中的存儲(chǔ)位置的映射。它是文檔檢索系統(tǒng)中最常用的數(shù)據(jù)結(jié)構(gòu)。
Lucene
Lucene是一個(gè)JAVA全文搜索引擎,完全用Java編寫。Lucene不是一個(gè)完整的應(yīng)用程序,而是一個(gè)代碼庫和API,可以很容易地用于向應(yīng)用程序添加搜索功能。
Lucene通過簡單的API提供強(qiáng)大的功能:
1)可擴(kuò)展的高性能索引
- 在現(xiàn)代硬件上超過150GB /小時(shí)
- 小RAM要求 - 只有1MB堆
- 增量索引與批量索引一樣快
- 索引大小約為索引文本大小的20-30%
2)強(qiáng)大,準(zhǔn)確,高效的搜索算法
- 排名搜索 - 首先返回最佳結(jié)果
- 許多強(qiáng)大的查詢類型:短語查詢,通配符查詢,鄰近查詢,范圍查詢等
- 現(xiàn)場搜索(例如標(biāo)題,作者,內(nèi)容)
- 按任何字段排序
- 使用合并結(jié)果進(jìn)行多索引搜索
- 允許同時(shí)更新和搜索
- 靈活的分面,突出顯示,連接和結(jié)果分組
- 快速,內(nèi)存效率和錯(cuò)誤容忍的建議
- 可插拔排名模型,包括矢量空間模型和Okapi BM25
- 可配置存儲(chǔ)引擎(編解碼器)
3)跨平臺(tái)解決方案
- 作為Apache許可下的開源軟件提供 ,允許您在商業(yè)和開源程序中使用Lucene
- 100%-pure Java
- 可用的其他編程語言中的實(shí)現(xiàn)是索引兼容的
4)Apache軟件基金會(huì)
- 在Apache軟件基金會(huì)提供的開源軟件項(xiàng)目的Apache社區(qū)的支持。
- 但是Lucene只是一個(gè)框架,要充分利用它的功能,需要使用JAVA,并且在程序中集成Lucene。需要很多的學(xué)習(xí)了解,才能明白它是如何運(yùn)行的,熟練運(yùn)用Lucene確實(shí)非常復(fù)雜。
Solr
Apache Solr是一個(gè)基于名為Lucene的Java庫構(gòu)建的開源搜索平臺(tái)。它以用戶友好的方式提供Apache Lucene的搜索功能。
作為一個(gè)行業(yè)參與者近十年,它是一個(gè)成熟的產(chǎn)品,擁有強(qiáng)大而廣泛的用戶社區(qū)。它提供分布式索引,復(fù)制,負(fù)載平衡查詢以及自動(dòng)故障轉(zhuǎn)移和恢復(fù)。如果它被正確部署然后管理得好,它就能夠成為一個(gè)高度可靠,可擴(kuò)展且容錯(cuò)的搜索引擎。
很多互聯(lián)網(wǎng)巨頭,?.NETflix,eBay,Instagram和亞馬遜(CloudSearch)都使用Solr,因?yàn)樗軌蛩饕退阉鞫鄠€(gè)站點(diǎn)。
主要功能列表包括:
- 全文搜索
- 突出
- 分面搜索
- 實(shí)時(shí)索引
- 動(dòng)態(tài)群集
- 數(shù)據(jù)庫集成
- NoSQL功能和豐富的文檔處理(例如Word和PDF文件)
ElasticSearch
Elasticsearch是一個(gè)開源(Apache 2許可證),是一個(gè)基于Apache Lucene庫構(gòu)建的RESTful搜索引擎。
Elasticsearch是在Solr之后幾年推出的。它提供了一個(gè)分布式,多租戶能力的全文搜索引擎,具有HTTP Web界面(REST)和無架構(gòu)JSON文檔。Elasticsearch的官方客戶端庫提供Java,Groovy,php,Ruby,Perl,Python/ target=_blank class=infotextkey>Python,.NET和JavaScript。
分布式搜索引擎包括可以劃分為分片的索引,并且每個(gè)分片可以具有多個(gè)副本。每個(gè)Elasticsearch節(jié)點(diǎn)都可以有一個(gè)或多個(gè)分片,其引擎也可以充當(dāng)協(xié)調(diào)器,將操作委派給正確的分片。
Elasticsearch可通過近實(shí)時(shí)搜索進(jìn)行擴(kuò)展。其主要功能之一是多租戶。
主要功能列表包括:
- 分布式搜索
- 多租戶
- 分析搜索
- 分組和聚合
四、Elasticsearch vs. Solr的選擇
由于Lucene的復(fù)雜性,一般很少會(huì)考慮它作為搜索的第一選擇,排除一些公司需要自研搜索框架,底層需要依賴Lucene。所以這里我們重點(diǎn)分析 Elasticsearch 和 Solr。
Elasticsearch vs. Solr。哪一個(gè)更好?他們有什么不同?你應(yīng)該使用哪一個(gè)?
1.歷史比較
Apache Solr是一個(gè)成熟的項(xiàng)目,擁有龐大而活躍的開發(fā)和用戶社區(qū),以及Apache品牌。Solr于2006年首次發(fā)布到開源,長期以來一直占據(jù)著搜索引擎領(lǐng)域,并且是任何需要搜索功能的人的首選引擎。它的成熟轉(zhuǎn)化為豐富的功能,而不僅僅是簡單的文本索引和搜索;如分面,分組,強(qiáng)大的過濾,可插入的文檔處理,可插入的搜索鏈組件,語言檢測等。
Solr 在搜索領(lǐng)域占據(jù)了多年的主導(dǎo)地位。然后,在2010年左右,Elasticsearch成為市場上的另一種選擇。那時(shí)候,它遠(yuǎn)沒有Solr那么穩(wěn)定,沒有Solr的功能深度,沒有思想分享,品牌等等。
Elasticsearch雖然很年輕,但它也自己的一些優(yōu)勢,Elasticsearch 建立在更現(xiàn)代的原則上,針對更現(xiàn)代的用例,并且是為了更容易處理大型索引和高查詢率而構(gòu)建的。此外,由于它太年輕,沒有社區(qū)可以合作,它可以自由地向前推進(jìn),而不需要與其他人(用戶或開發(fā)人員)達(dá)成任何共識(shí)或合作,向后兼容,或任何其他更成熟的軟件通常必須處理。
因此,它在Solr之前就公開了一些非常受歡迎的功能(例如,接近實(shí)時(shí)搜索,英文:Near Real-Time Search)。從技術(shù)上講,NRT搜索的能力確實(shí)來自Lucene,它是 Solr 和 Elasticsearch 使用的基礎(chǔ)搜索庫。具有諷刺意味的是,因?yàn)?Elasticsearch 首先公開了NRT搜索,所以人們將NRT搜索與Elasticsearch 聯(lián)系在一起,盡管 Solr 和 Lucene 都是同一個(gè) Apache 項(xiàng)目的一部分,因此,人們會(huì)首先期望 Solr 具有如此高要求的功能。
2.特征差異比較
這兩個(gè)搜索引擎都是流行的,先進(jìn)的的開源搜索引擎。它們都是圍繞核心底層搜索庫 - Lucene構(gòu)建的 - 但它們又是不同的。像所有東西一樣,每個(gè)都有其優(yōu)點(diǎn)和缺點(diǎn),根據(jù)您的需求和期望,每個(gè)都可能更好或更差。Solr和Elasticsearch都在快速發(fā)展,所以,話不多說,先來看下它們的差異清單:
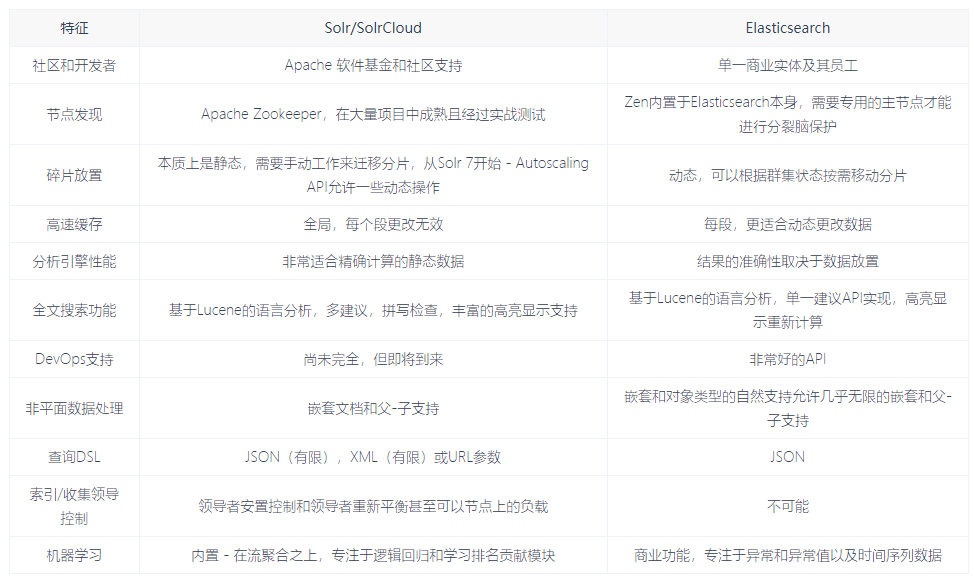
3.綜合比較
另外,我們再從以下幾個(gè)方面來分析下:
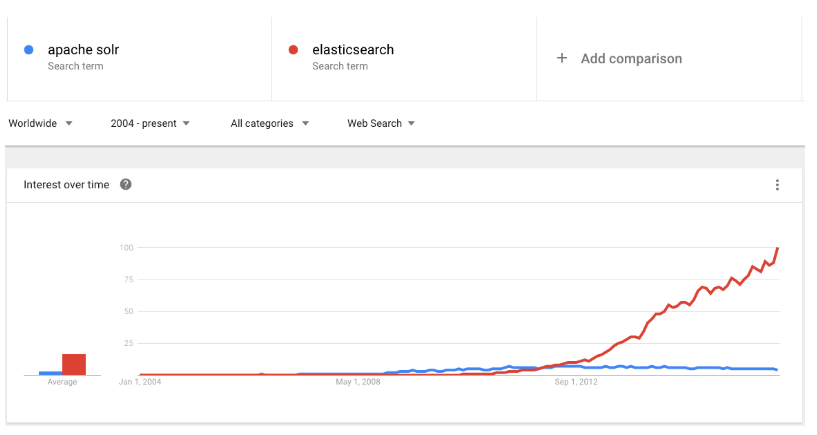
- 近幾年的流行趨勢
我們查看一下這兩種產(chǎn)品的Google搜索趨勢。谷歌趨勢表明,與 Solr 相比,Elasticsearch具有很大的吸引力,但這并不意味著Apache Solr已經(jīng)死亡。雖然有些人可能不這么認(rèn)為,但Solr仍然是最受歡迎的搜索引擎之一,擁有強(qiáng)大的社區(qū)和開源支持。
- 安裝和配置
與Solr相比,Elasticsearch易于安裝且非常輕巧。此外,您可以在幾分鐘內(nèi)安裝并運(yùn)行Elasticsearch。
但是,如果Elasticsearch管理不當(dāng),這種易于部署和使用可能會(huì)成為一個(gè)問題。基于JSON的配置很簡單,但如果要為文件中的每個(gè)配置指定注釋,那么它不適合您。
總的來說,如果您的應(yīng)用使用的是JSON,那么Elasticsearch是一個(gè)更好的選擇。否則,請使用Solr,因?yàn)樗膕chema.xml和solrconfig.xml都有很好的文檔記錄。
- 社區(qū)
Solr擁有更大,更成熟的用戶,開發(fā)者和貢獻(xiàn)者社區(qū)。ES雖擁有的規(guī)模較小但活躍的用戶社區(qū)以及不斷增長的貢獻(xiàn)者社區(qū)。
Solr是真正的開源社區(qū)代碼。任何人都可以為Solr做出貢獻(xiàn),并且根據(jù)優(yōu)點(diǎn)選出新的Solr開發(fā)人員(也稱為提交者)。Elasticsearch在技術(shù)上是開源的,但在精神上卻不那么重要。任何人都可以看到來源,任何人都可以更改它并提供貢獻(xiàn),但只有Elasticsearch的員工才能真正對Elasticsearch進(jìn)行更改。
Solr貢獻(xiàn)者和提交者來自許多不同的組織,而Elasticsearch提交者來自單個(gè)公司。
- 成熟度
Solr更成熟,但ES增長迅速,我認(rèn)為它穩(wěn)定。
- 文檔
Solr在這里得分很高。它是一個(gè)非常有據(jù)可查的產(chǎn)品,具有清晰的示例和API用例場景。Elasticsearch的文檔組織良好,但它缺乏好的示例和清晰的配置說明。
總結(jié)
那么,到底是Solr還是Elasticsearch?
有時(shí)很難找到明確的答案。無論您選擇Solr還是Elasticsearch,首先需要了解正確的用例和未來需求,總結(jié)他們的每個(gè)屬性。
記住:
- 由于易于使用,Elasticsearch在新開發(fā)者中更受歡迎。但是,如果您已經(jīng)習(xí)慣了與Solr合作,請繼續(xù)使用它,因?yàn)檫w移到Elasticsearch沒有特定的優(yōu)勢。
- 如果除了搜索文本之外還需要它來處理分析查詢,Elasticsearch是更好的選擇。
- 如果需要分布式索引,則需要選擇Elasticsearch。對于需要良好可伸縮性和性能的云和分布式環(huán)境,Elasticsearch是更好的選擇。
- 兩者都有良好的商業(yè)支持(咨詢,生產(chǎn)支持,整合等)。
- 兩者都有很好的操作工具,盡管Elasticsearch因其易于使用的API而更多地吸引了DevOps人群,因此可以圍繞它創(chuàng)建一個(gè)更加生動(dòng)的工具生態(tài)系統(tǒng)。
- Elasticsearch在開源日志管理用例中占據(jù)主導(dǎo)地位,許多組織在Elasticsearch中索引它們的日志以使其可搜索。雖然Solr現(xiàn)在也可以用于此目的,但它只是錯(cuò)過了這一想法。
- Solr仍然更加面向文本搜索。另一方面,Elasticsearch 通常用于過濾和分組 - 分析查詢工作負(fù)載 - 而不一定是文本搜索。Elasticsearch 開發(fā)人員在 Lucene 和 Elasticsearch 級(jí)別上投入了大量精力使此類查詢更高效(降低內(nèi)存占用和CPU使用)。因此,對于不僅需要進(jìn)行文本搜索,而且需要復(fù)雜的搜索時(shí)間聚合的應(yīng)用程序,Elasticsearch是一個(gè)更好的選擇。
- Elasticsearch更容易上手,一個(gè)下載和一個(gè)命令就可以啟動(dòng)一切。Solr傳統(tǒng)上需要更多的工作和知識(shí),但Solr最近在消除這一點(diǎn)上取得了巨大的進(jìn)步,現(xiàn)在只需努力改變它的聲譽(yù)。
- 在性能方面,它們大致相同。我說“大致”,因?yàn)闆]有人做過全面和無偏見的基準(zhǔn)測試。對于95%的用例,任何一種選擇在性能方面都會(huì)很好,剩下的5%需要用它們的特定數(shù)據(jù)和特定的訪問模式來測試這兩種解決方案。
- 從操作上講,Elasticsearch使用起來比較簡單 - 它只有一個(gè)進(jìn)程。Solr在其類似Elasticsearch的完全分布式部署模式SolrCloud中依賴于Apache ZooKeeper。ZooKeeper是超級(jí)成熟,超級(jí)廣泛使用等等,但它仍然是另一個(gè)活躍的部分。也就是說,如果您使用的是Hadoop,HBase,Spark,Kafka或其他一些較新的分布式軟件,您可能已經(jīng)在組織的某個(gè)地方運(yùn)行ZooKeeper。
- 雖然Elasticsearch內(nèi)置了類似ZooKeeper的組件Xen,但ZooKeeper可以更好地防止有時(shí)在Elasticsearch集群中出現(xiàn)的可怕的裂腦問題。公平地說,Elasticsearch開發(fā)人員已經(jīng)意識(shí)到這個(gè)問題,并致力于改進(jìn)Elasticsearch的這個(gè)方面。
- 如果您喜歡監(jiān)控和指標(biāo),那么使用Elasticsearch,您將會(huì)進(jìn)入天堂。這個(gè)東西比新年前夜在時(shí)代廣場可以擠壓的人有更多的指標(biāo)!Solr暴露了關(guān)鍵指標(biāo),但遠(yuǎn)不及Elasticsearch那么多。
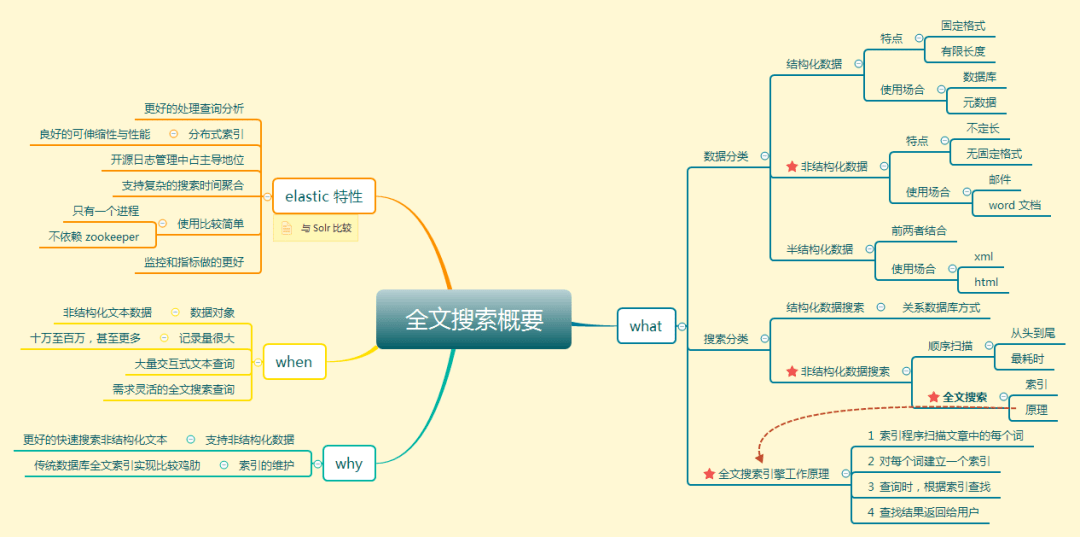
總之,兩者都是功能豐富的搜索引擎,只要設(shè)計(jì)和實(shí)現(xiàn)得當(dāng),它們或多或少都能提供相同的性能。本篇文章的總體內(nèi)容大致如下圖,該圖由園友ReyCG精心繪制并提供。
>>>>參考資料
- https://www.datanami.com/2015/01/22/solr-elasticsearch-question/
- https://blog.csdn.net/hhx0626/article/detAIls/78095593/
- https://www.elastic.co/cn/
- https://logz.io/blog/solr-vs-elasticsearch/
- https://sematext.com/blog/solr-vs-elasticsearch-differences/
作者丨小菜亦牛
來源丨h(huán)ttps://www.cnblogs.com/jajian/p/9801154.html





