擊這里在線咨詢客服")
作者:吳陳旺、王希廷、連德富
為了深入了解大模型的科學(xué)原理并確保其安全,可解釋變得日益重要。解釋大模型帶來(lái)了很多獨(dú)特挑戰(zhàn):(1)大模型參數(shù)特別多,怎么盡可能確保解釋速度?(2)大模型涉及的樣本特別多,如何讓用戶盡可能少看一些樣本的解釋也能了解大模型的全貌?這兩個(gè)問(wèn)題都指向了對(duì)大模型解釋效率的要求,而我們希望通過(guò)新的范式,為構(gòu)建大模型高效解釋之路提供一個(gè)思路。
我們的高效新范式是通過(guò)從因果角度重新審視模型來(lái)獲得的。我們首先從因果的視角重新審視知名可解釋方法(比如 LIME、Shapley Value 等),發(fā)現(xiàn)他們的解釋得分對(duì)應(yīng)于因果推理中的因果效應(yīng)(treatment effect),明確構(gòu)建了這些方法和因果的聯(lián)系。這不僅讓我們可以統(tǒng)一對(duì)比這些方法的優(yōu)缺點(diǎn),還可以分析他們的因果圖,發(fā)現(xiàn)其中導(dǎo)致不夠高效的原因:(1)他們的解釋需要特別多次對(duì)大模型的擾動(dòng)才能獲得,解釋速度慢;(2)他們的解釋不具備泛化性:對(duì)相似的樣本,其解釋可能劇烈變化,導(dǎo)致用戶無(wú)法通過(guò)看少量樣本解釋得到本質(zhì)的、對(duì)其他樣本也適用的本質(zhì)原因。
基于這個(gè)發(fā)現(xiàn),我們提出了新的因果圖,并遵循重要的因果原則,提出了因果啟發(fā)的模型解釋框架(Causality Inspired Framework for Model Interpretation, CIMI)來(lái)設(shè)計(jì)解釋器的訓(xùn)練目標(biāo)和理想屬性。實(shí)驗(yàn)結(jié)果表明,CIMI 提供了更忠誠(chéng)和可泛化的解釋,同時(shí)具有更高的采樣效率,使其特別適合更大的預(yù)訓(xùn)練模型。
通過(guò)閱讀本文你可以了解到:
現(xiàn)有知名可解釋方法和因果之間的聯(lián)系是什么?如何從統(tǒng)一的因果視角去對(duì)比它們的優(yōu)缺點(diǎn)?
更好、更高效的因果圖是什么?對(duì)應(yīng)的可解釋方法是什么?
本文同時(shí)也還有不少需要改進(jìn)之處,比如我們目前都分析的是分類模型而不是文本生成模型;我們主要在常規(guī)大小的預(yù)訓(xùn)練模型上驗(yàn)證了解釋效率,對(duì)于很大規(guī)模模型的測(cè)試還在進(jìn)一步實(shí)驗(yàn)中;我們的框架盡管通用,但是具體采用方法目前需要模型最后一層 embedding,對(duì)于不公開(kāi) embedding 的模型如何高效分析還不明確。這些問(wèn)題希望在后續(xù)和大家探討中共同解決。

論文地址:
https://dl.acm.org/doi/pdf/10.1145/3580305.3599240
開(kāi)源地址:
https://Github.com/Daftstone/CIMI
研究背景
深度學(xué)習(xí)在醫(yī)療保障、金融預(yù)測(cè)分析、故障檢測(cè)等諸多領(lǐng)域發(fā)揮著關(guān)鍵作用。然而,深度模型大多是人類無(wú)法理解的黑盒,這種不透明性可能產(chǎn)生嚴(yán)重后果,尤其在高風(fēng)險(xiǎn)決策中。例如,基于深度學(xué)習(xí)的污染模型聲稱高污染空氣對(duì)人類健康沒(méi)有威脅 [1]。不完美的模型并非毫無(wú)意義,如果可以解釋模型做出特定決策的原因,就可能有效地降低和避免模型錯(cuò)誤的風(fēng)險(xiǎn)。另外,公開(kāi)透明的模型也有助于發(fā)現(xiàn)模型中潛在的錯(cuò)誤(比如,推理邏輯與領(lǐng)域知識(shí)不符),從而進(jìn)一步改進(jìn)模型 [2]。因此,可解釋人工智能(eXplAInable Artificial Intelligence, XAI)的研究受到了越來(lái)越多的關(guān)注。
圖 1. 深度學(xué)習(xí)模型的不透明性。
可解釋學(xué)習(xí)中一個(gè)基本問(wèn)題是:解釋是否揭示了模型行為的重要根本原因,還是僅僅是虛假的相關(guān)性?無(wú)法區(qū)分相關(guān)性和因果關(guān)系會(huì)導(dǎo)致決策者做出錯(cuò)誤的解釋。在人機(jī)交互方面的研究 [3] 進(jìn)一步突出了因果關(guān)系的重要性,其中廣泛的用戶研究表明,在可解釋人工智能中,因果關(guān)系增加了用戶信任,并有助于評(píng)估解釋的質(zhì)量。這一結(jié)果呼應(yīng)了認(rèn)知科學(xué)中的主要理論,即人類使用因果關(guān)系來(lái)構(gòu)建對(duì)世界的心理模型 [4]。
另外,可解釋人工智能遵循基本的因果性假設(shè),為因果研究提供了理想的環(huán)境,而這些假設(shè)通常在其他情況下是難以驗(yàn)證的。例如,在可解釋研究中,我們可以輕易地獲得一組變量(比如,一個(gè)句子的所有單詞的組合),這些變量構(gòu)成了模型預(yù)測(cè)的所有可能原因的完整集合,這確保滿足了因果充分性假設(shè) [5]。此外,黑盒模型可以輕松進(jìn)行干預(yù),這允許直接執(zhí)行關(guān)鍵的 do 操作(do-operator)。例如,因果研究的環(huán)境通常是一次性的,一個(gè)人吃過(guò)藥了就無(wú)法讓他不吃藥,如果需要建模吃藥和康復(fù)的因果關(guān)系,就需要仔細(xì)對(duì)混雜因素建模,并使用后門(mén)或者前門(mén)調(diào)整等技術(shù)將因果估計(jì)轉(zhuǎn)化為統(tǒng)計(jì)估計(jì),并僅基于觀測(cè)數(shù)據(jù)計(jì)算該統(tǒng)計(jì)估計(jì)。而在可解釋中,干預(yù)變得尤為簡(jiǎn)單。這是因?yàn)橐忉尩哪P退幍沫h(huán)境非常清楚,允許直接對(duì)任何特征進(jìn)行 do 操作并查看模型預(yù)測(cè)的變化,并且這一操作可以重復(fù)操作。
因果視角的關(guān)鍵問(wèn)題
由于因果在可解釋研究中的重要性和適用性,已經(jīng)引起了越來(lái)越多的關(guān)注。多種解釋方法,如 LIME [6],Shapley Value [7] 以及 CXPlain [8],利用干預(yù) (例如對(duì)輸入數(shù)據(jù)擾動(dòng)) 等因果分析技術(shù)提供更忠誠(chéng)的黑盒模型解釋。盡管如此,仍然缺乏一個(gè)正式統(tǒng)一的因果視角,并且一些關(guān)鍵研究問(wèn)題仍然具有挑戰(zhàn)性,例如:
RQ1. 現(xiàn)有解釋方法和因果的關(guān)系:現(xiàn)有的解釋方法能否在一個(gè)因果框架內(nèi)進(jìn)行構(gòu)建?如果可以的話,所采用的因果模型是什么,并且它們之間有什么區(qū)別?
RQ2. 因果推理在可解釋中的挑戰(zhàn):在利用因果推理進(jìn)行模型解釋方面,主要的挑戰(zhàn)是什么?通過(guò)解決這些挑戰(zhàn),我們可能會(huì)獲得哪些好處?
RQ3. 如何利用因果推理改進(jìn)可解釋方法:如何改進(jìn)因果模型以解決這些挑戰(zhàn)?
在該工作中,我們旨在通過(guò)研究這些問(wèn)題來(lái)彌合因果推理與可解釋性之間的差距。
從因果角度重新審視可解釋(RQ1)
通過(guò)從因果的角度重新審視現(xiàn)有的方法,我們可以證明許多經(jīng)典的基于擾動(dòng)的可解釋方法,如 LIME、Shapley Value 以及 CXPlain,實(shí)際上計(jì)算的是(平均)因果效應(yīng)。因果效應(yīng)構(gòu)成了這些特征的解釋得分,旨在揭示模型預(yù)測(cè)中每個(gè)特征被納入解釋的程度。
另外,他們的因果圖與圖 2(左)相對(duì)應(yīng)。其中,對(duì) E 的治療(treatment)對(duì)應(yīng)于對(duì)一個(gè)或一組特定特征的擾動(dòng)。C 是上下文特征,表示在改變 E 后保持不變的特征。

圖 2. 左:現(xiàn)有方法的因果圖,其中解釋 E 和上下文 C 都是影響模型預(yù)測(cè) 的因素;右:從統(tǒng)一的因果視角對(duì)現(xiàn)有可解釋方法的比較。
盡管這三種方法都可以使用圖 2(左)中的因果圖進(jìn)行總結(jié),但它們也會(huì)存在些許差異,如圖 2(右)所示。我們將展示該統(tǒng)一的視角如何輕松地比較每個(gè)方法的優(yōu)缺點(diǎn):

因果推理應(yīng)用于可解釋的挑戰(zhàn)(RQ2)
根據(jù)上一節(jié)的觀察結(jié)果,我們能夠總結(jié)將因果推理應(yīng)用于模型解釋的核心挑戰(zhàn)。雖然解釋方法很容易計(jì)算個(gè)體因果效應(yīng),比如,當(dāng)一個(gè)輸入特征改變時(shí),模型的預(yù)測(cè)結(jié)果發(fā)生了多大的變化,但核心挑戰(zhàn)是如何有效地發(fā)現(xiàn)可以從大量特征和數(shù)據(jù)點(diǎn)推廣到不同實(shí)例的突出共同原因。要解決這個(gè)問(wèn)題,需要保證解釋是:
- 因果充分:解釋包含了所有預(yù)測(cè)模型行為的信息,并且非解釋不包含影響模型決策的因子。
- 可泛化的:對(duì)于相似的實(shí)例(只有潛在非解釋的變化),解釋?xiě)?yīng)該保持不變。
- 這些性質(zhì)是非常重要的,特別是當(dāng)黑盒模型變得越來(lái)越大,并且有更多的數(shù)據(jù)點(diǎn)需要解釋時(shí),這些突出的共同原因可以泛化到許多數(shù)據(jù)點(diǎn)上,這樣我們可以節(jié)省用戶的認(rèn)知工作。同時(shí),這也有助于增強(qiáng)用戶的信任。以圖 3 的病理檢測(cè)器為例,如果在同一患者的不同斷面層檢測(cè)到完全不同的關(guān)鍵區(qū)域,這將是非常令人不安的。

圖 3:解釋增強(qiáng)用戶信任的例子:病理檢測(cè)器。


圖 4:(左). 現(xiàn)有方法的因果圖,其中解釋不是模型預(yù)測(cè)的唯一原因;(中). 候選因果圖,其中解釋對(duì)模型預(yù)測(cè)是因果充分的,但不是泛化的;(右). 我們的選擇,其中解釋是泛化且是的唯一原因。可觀測(cè)變量用藍(lán)色陰影表示。
利用因果改進(jìn)可解釋(RQ3)
基于上一節(jié)的討論,我們希望根據(jù)選擇的因果圖提升解釋質(zhì)量(因果充分和可泛化)。但由于兩個(gè)重要的因果變量 E 和 U 是不可觀察的,直接在圖 4 (右) 的因果圖中重構(gòu)因果機(jī)制是不切實(shí)際的。考慮到因果變量需要遵循明確的原則,我們使用以下兩個(gè)因果推理中的重要原則來(lái)設(shè)計(jì)因果變量應(yīng)滿足的基本屬性:

基于選擇的因果圖以及這兩個(gè)因果原則,我們?cè)O(shè)計(jì)了一個(gè)因果啟發(fā)的模型解釋框架,CIMI。CIMI 包含三個(gè)模塊:因果充分模塊、因果干預(yù)模塊以及因果先驗(yàn)?zāi)K,以確保提取的解釋滿足這兩個(gè)原則所需的基本屬性。

圖 5. 左:因果充分示意圖;中:因果干預(yù)示意圖;右:解釋器的結(jié)構(gòu)設(shè)計(jì)。




實(shí)驗(yàn)分析
我們選擇了 BERT 和 RoBERTa 作為待解釋的黑盒模型,在 Clickbait、Hate、Yelp 以及 IMDB 數(shù)據(jù)集來(lái)評(píng)估生成解釋的質(zhì)量。具體的統(tǒng)計(jì)數(shù)據(jù)如圖 6 所示。
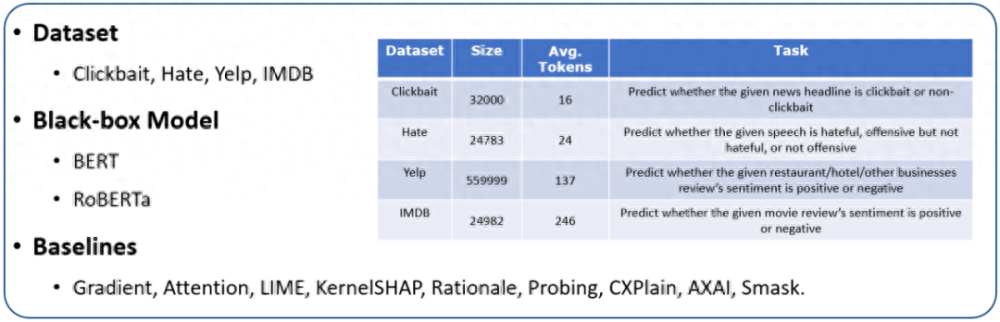
圖 6. 實(shí)驗(yàn)設(shè)置。
我們將對(duì)解釋的忠誠(chéng)性、泛化性、采樣效率以及可用性進(jìn)行評(píng)估。
1. 忠誠(chéng)性評(píng)估:我們使用三個(gè)忠誠(chéng)度指標(biāo)來(lái)評(píng)估生成解釋的因果充分性,分別為 DFFOT(決策翻轉(zhuǎn)的分詞比例)、COMP(必要性)、SUFF(充分性)。這些指標(biāo)的細(xì)節(jié)以及我們的實(shí)驗(yàn)結(jié)果如圖 7 所示。可以看出提出的方法在各種數(shù)據(jù)集上是有競(jìng)爭(zhēng)力的。特別地,隨著數(shù)據(jù)集的復(fù)雜度越來(lái)越高(CLickbaitIMDB),相較于基線方法的提升效果更加明顯。例如,在 Clickbait 上,和最好的基線方法比較,關(guān)于 DFFOT 的性能提升為 4.2%,而在 IMDB 上,相應(yīng)的性能提升為 54.3%。這種良好的性質(zhì)突出了我們的算法具有更好的可擴(kuò)展性。
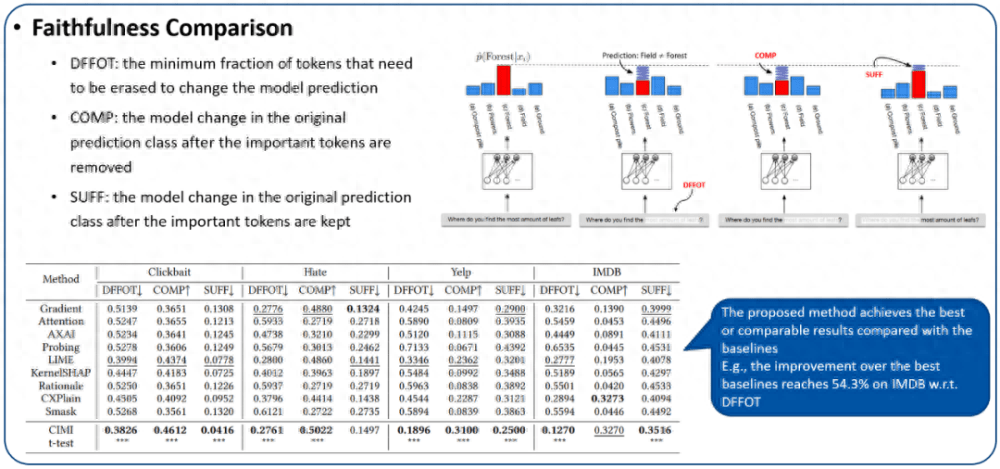
圖 7. 解釋的忠誠(chéng)性評(píng)估。
2. 泛化性評(píng)估:我們使用 AvgSen(平均敏感度)來(lái)評(píng)估生成解釋的泛化性。不可否認(rèn),對(duì)于 AvgSen 來(lái)說(shuō),解釋中包含的一些重要的 token(解釋)可能會(huì)被替換,但概率很低,尤其是在分詞數(shù)量較多的 Yelp 和 IMDB 中。實(shí)驗(yàn)結(jié)果如圖 8 所示。可以看到,在四個(gè)數(shù)據(jù)集中,擾動(dòng)前后的 Top-10 重要分詞中至少有 8 個(gè)是一致的,這對(duì)于基線方法是難以做到的。這表明提出的方法具有捕獲不變泛化特征的能力,這種泛化能力有助于避免對(duì)相似實(shí)例的重復(fù)解釋的耗時(shí)成本,同時(shí)這種穩(wěn)定的解釋也有助于增強(qiáng)人們的信任。
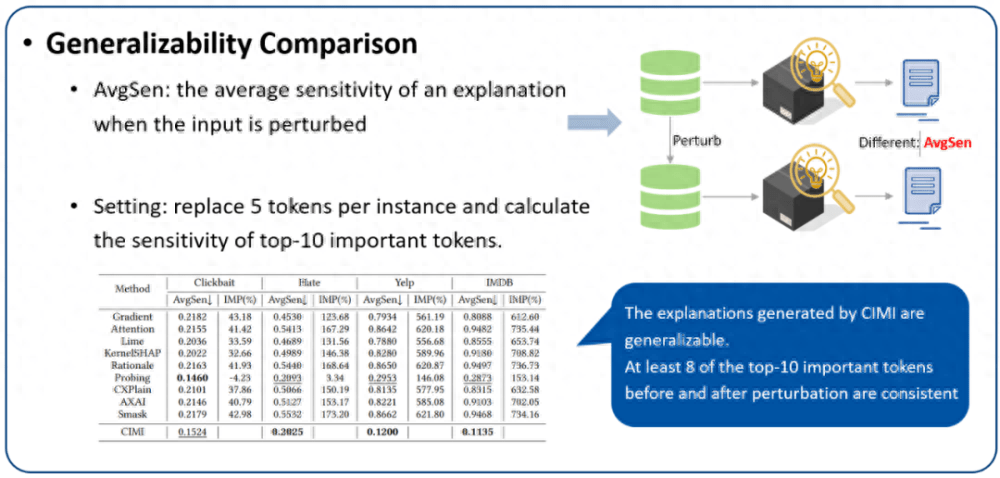
圖 8. 解釋的泛化性評(píng)估。
3. 采樣效率(即解釋速度)評(píng)估:圖 9 展示了在相同采樣次數(shù)(模型前向傳播次數(shù))下,各種基于擾動(dòng)方法的性能比較。首先,CXPlain 的單特征擾動(dòng)的解釋機(jī)制使每個(gè)樣本 x 的擾動(dòng)次數(shù)最多為 |x| 次,因此在小數(shù)據(jù)集上表現(xiàn)出了較高的效率。其次,所提出方法在四個(gè)數(shù)據(jù)集中都顯示出顯著的競(jìng)爭(zhēng)力,特別是在 Hate 上,只需要 3 個(gè)采樣次數(shù)就可以超過(guò)具有 100 個(gè)采樣次數(shù)的基線。這得益于神經(jīng)網(wǎng)絡(luò)在因果原則約束下的泛化能力,從大量的數(shù)據(jù)點(diǎn)中總結(jié)出推廣到不同的實(shí)例的解釋,最終提高效率。在大模型高速發(fā)展的時(shí)代,由于模型越來(lái)越大,要解釋的數(shù)據(jù)點(diǎn)也越來(lái)越多,這種高效的采樣對(duì)于解釋方法顯得越來(lái)越重要。
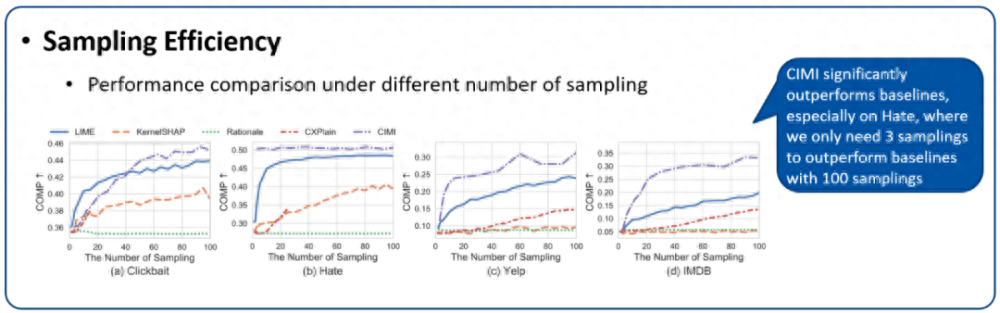
圖 9. 解釋方法的采樣效率評(píng)估。
4. 可用性評(píng)估:解釋除了讓我們更好地理解模型,還有幫助調(diào)試模型。有噪聲的數(shù)據(jù)收集可能會(huì)導(dǎo)致模型在訓(xùn)練過(guò)程中學(xué)習(xí)到錯(cuò)誤的相關(guān)性。為此,本節(jié)分析了各種解釋方法在刪除捷徑特征(shortcut)的能力。我們使用 20 newsgroups 的一個(gè)子集分類 “基督教” 和 “無(wú)神論”。選擇該數(shù)據(jù)集的原因是訓(xùn)練集中有很多捷徑特征,但測(cè)試集是干凈的。例如,在訓(xùn)練集中出現(xiàn)單詞 “posting” 的實(shí)例中,99% 的實(shí)例都屬于 “無(wú)神論” 的類別。
為了測(cè)試解釋方法是否可以幫助檢測(cè)捷徑特征,我們首先在有噪聲的訓(xùn)練集上訓(xùn)練 BERT 模型。然后,我們獲得不同方法的解釋,如果解釋中的分詞沒(méi)有出現(xiàn)在干凈的測(cè)試集中,則將其視為潛在的捷徑特征。然后,在刪除捷徑特征后重新訓(xùn)練分類模型。評(píng)估各種解釋方法識(shí)別捷徑特征的指標(biāo)是移除潛在捷徑特征后重訓(xùn)練模型的性能 (更好的分類性能意味著找到的捷徑特征更準(zhǔn)確)。結(jié)果如圖 10 所示。首先,LIME 和提出的方法都能有效去除捷徑,提高模型性能。其次,CIMI 對(duì)模型性能的改進(jìn)更加明顯,這表明其檢測(cè)的捷徑特征更為準(zhǔn)確。
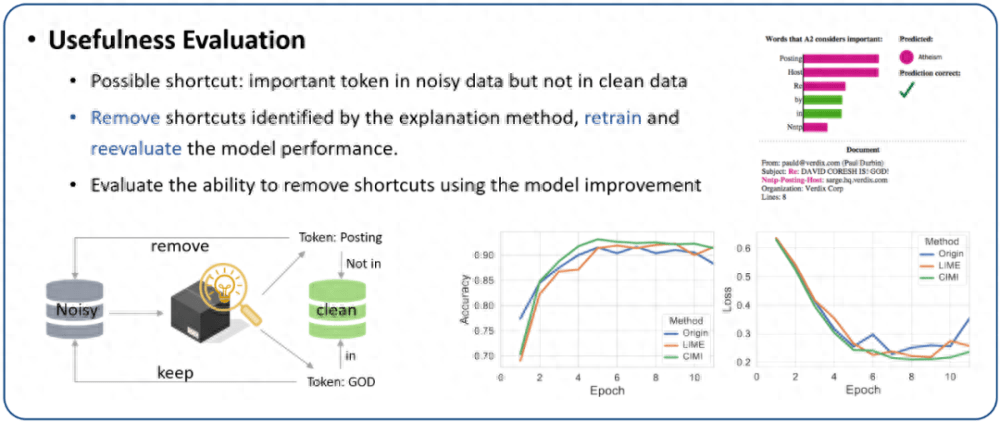
圖 10. 解釋方法的可用性評(píng)估。
總結(jié)
本文從因果推理的角度重新解讀了一些經(jīng)典的可解釋方法,發(fā)現(xiàn)他們的解釋得分對(duì)應(yīng)于因果推理中的因果效應(yīng)。通過(guò)在這個(gè)統(tǒng)一的因果視角分析它們的利弊,揭示了利用因果推理進(jìn)行解釋的主要挑戰(zhàn):因果充分性和泛化性。最后,基于合適的因果圖和重要的因果原則,設(shè)計(jì)了神經(jīng)解釋器的訓(xùn)練目標(biāo)和理想屬性,并提出了一種高效的解決方案 CIMI。通過(guò)廣泛的實(shí)驗(yàn),證明了所提方法在解釋的因果充分性、泛化性以及采樣效率方面的優(yōu)越性,并探索了解釋方法幫助模型調(diào)試的潛力。
參考文獻(xiàn)
[1] Michael McGough. 2018. How bad is Sacramento’s air, exactly? google results Appear at odds with reality, some say. Sacramento Bee 7 (2018).
[2] G Xu, TD Duong, Q Li, S Liu, and X Wang. 2020. Causality Learning: A New Perspective for Interpretable machine Learning. IEEE Intelligent Informatics Bulletin (2020).
[3] Jonathan G Richens, Ciarán M Lee, and Saurabh Johri. 2020. Improving the accuracy of medical diagnosis with causal machine learning. Nature communications 11, 1 (2020), 3923.
[4] Steven Sloman. 2005. Causal models: How people think about the world and its alternatives. Oxford University Press.
[5] Brady Neal. 2020. Introduction to causal inference from a machine learning perspective. Course Lecture Notes (draft) (2020).
[6] Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2016. "Why should i tRust you?" Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 1135–1144.
[7] Scott M Lundberg and Su-In Lee. 2017. A unified approach to interpreting model predictions. Advances in neural information processing systems 30 (2017).
[8] Yuzuru Okajima and Kunihiko Sadamasa. 2019. Deep neural.NETworks constrained by decision rules. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33. 2496–2505.
[9] Clive WJ Granger. 1969. Investigating causal relations by econometric models and cross-spectral methods. Econometrica: journal of the Econometric Society (1969), 424–438.
[10] Jonas Peters, Dominik Janzing, and Bernhard Schölkopf. 2017. Elements of causal inference: foundations and learning algorithms. The MIT Press.
[11] Philippe Brouillard, Sébastien Lachapelle, Alexandre Lacoste, Simon LacosteJulien, and Alexandre Drouin. 2020. Differentiable causal discovery from interventional data. Advances in Neural Information Processing Systems 33 (2020), 21865–21877.





