

自從 ChatGPT 火熱出圈,由生成式 AI 掀起的全球人工智能新浪潮就拉開了序幕,圍繞認知大模型的類 ChatGPT 技術和產品正在不斷涌現。
對于國內用戶來說,目前不少大模型產品已經開放內測。不過,目前這些大模型產品在完善度、功能性、易用性等方面都各有不同,大家可能不知如何選擇。
今天,IT之家不妨就針對幾款產品為大家做個體驗橫評。
本次橫評測試,IT之家主要針對通用大模型產品,并且選擇了目前知名度比較高的四款產品,分別是百度的文心一言、科大訊飛的訊飛星火、阿里的通義千問和 360 智腦。

不同的測試大類中,我們以滿分 10 分計,如果某款大模型在某個測試小項中不符合要求或者體驗不好,根據輕重每次扣除 1-3 分,最后剩余的分數為該大模型在這個測試大類的評分。
評測以及評分過程中難免會存在主觀的因素,因此分數僅供大家參考。
由于接下來詳細評測部分內容較多,為了方便大家更好地抓住重點,小編不妨先將評測結果先簡要透露一下。這次對比橫評共 10 個大項,每個大項 10 分,總分也就是 100 分。而具體四款產品的得分分別是:
訊飛星火:93 分文心一言:84 分360 智腦:75 分通義千問:71 分
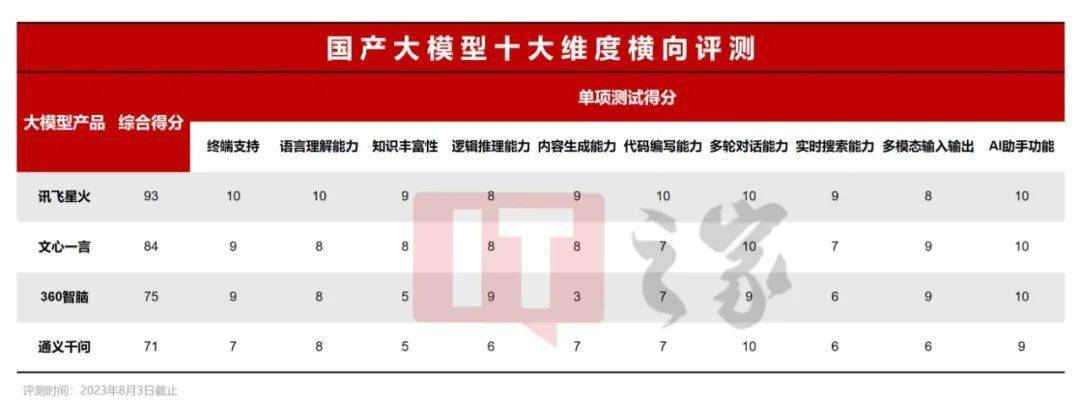
訊飛星火的表現相信會讓大家感到驚艷,事實也是在這次橫評中,訊飛星火在每個項目都能保持前二的成績,特別建議大家關注他在實時搜索、內容生成和代碼編寫方面的表現。此外文心一言也是不錯的,在內容生成、避坑能力、多模態輸出等方面都有不俗之處。
當然,具體每款產品為什么最終是這個分數?好在哪里?丟分項又在哪里?大家則可以通過下面詳細的評測過程進行了解。
話不多說,就讓我們開始吧。
一、終端支持
在大模型支持的平臺豐富度方面,文心一言目前支持網頁端、Android/ target=_blank class=infotextkey>安卓 /IOS App,暫時沒有桌面 / mac 版和微信小程序。
通義千問目前則只有網頁端可用。
360 智腦方面,目前覆蓋了網頁版、安卓 /iOS 移動 App 和桌面版(無 Mac),支持的平臺還是比較多的。

而覆蓋最多的是訊飛星火,目前訊飛星火是唯一支持五端(安卓、IOS、小程序、PC、H5)全覆蓋的大模型。

這一環節,小編給四款產品的評分分別是:
二、語言理解能力測試訊飛星火:10 分360 智腦:9 分文心一言:9 分通義千問:7 分
AI 大模型的本質其實就是大語言模型,因此語言理解可以說是影響各種大模型產品體驗的基礎要素。這里小編先測試上面四款產品對中文語意的理解能力。
① 語意理解
首先用經典的一詞多意的段子來考驗大模型們:
領導說:“你這是什么意思?”小明說:“沒什么意思,意思意思。" 領導說:“你這就不夠意思了。”小明說:“小意思,小意思。”
這段話里,不同的“意思”分別代表什么意思?
先看文心一言的解釋,具體、準確,沒有遺漏:

通義千問不僅回答了每個“意思”的意思,更給出了職場溝通的建議,回答很有邏輯性:

訊飛星火的回答也是比較靠譜的,對每個“意思”的解釋相比前兩者更詳盡深入,特別是最后一句,訊飛星火對一句話里的兩個“小意思”都做了解釋。

360 智腦的回答就有點簡單了,回答得比較模糊籠統:

② 情感分析
接下來,小編要看看這幾款大模型能不能準確分析一段文本中的情感色彩,能否更好地了解文本內容觀點和態度。因此小編選擇一段經典電影臺詞來測試。
從結果來看,文心一言、訊飛星火、360 智腦和通義千問的回答各有特點,但整體意思都是準確的,都沒有把句子的含義局限在“鳥”這個喻體上,因此回答都是合格的。


③ 摘要提煉
這部分的最后,我們來看看四款大模型對文本的總結提煉能力。小編從IT之家隨機選擇了一篇新聞資訊,分別讓四款大模型將這篇新聞總結成一句話的摘要。
先看文心一言的表現,雖然是總結了,意思也正確,但總結得比較啰嗦,而且不符合“一句話”的要求:

通義千問也有類似的問題,總結啰嗦,而且超過一句話的限制:

360 智腦在這一項中表現不錯,一句話準確總結了這段文章的大意:

訊飛星火提煉得也很精煉,一句話搞定,而且意思準確。

在這一環節,四款大模型產品的得分分別為:
三、知識豐富性測試訊飛星火:10 分通義千問:8 分(摘要提煉 - 2)360 智腦:8 分(語意理解 - 2)文心一言:8 分(摘要提煉 - 2)
很多人會用 AI 大模型會取代搜索引擎,因為用大模型搜索各種知識類信息很方便,還沒有廣告。這時候大模型的知識豐富度就比較重要了。本次測試IT之家針對四個類別的知識對所選大模型進行考驗測試。
① 生活常識類
生活常識方面,IT之家首先用“平橋豆腐屬于哪個菜系?”分別問四款大模型。其中,訊飛星火和文心一言給出了正確回答,屬于淮揚菜,而且還給出了這道菜的做法。
這個問題中,通義千問和 360 智腦回答錯誤,分別說成了豫菜和川菜。
② 工作技能類
在工作技能類知識方面,IT之家用“如何在 wps 中連續使用格式刷”這個問題來詢問。
文心一言給出了兩個方法,分別是點擊按鈕和快捷鍵,其中快捷鍵的方法正確,按鈕法錯誤,應該扣 1 分。

訊飛星火之給出了雙擊格式刷按鈕的方法,雖然正確,但缺少快捷鍵法,也應扣 1 分。

360 智腦和通義千問給的方法,都不是小編需要的格式刷連續刷的方法,也沒有給出快捷鍵法,因此扣 2 分。

③理工專業知識類
理工專業知識方面,小編隨便選擇一個大學物理相關的知識點來考這四款大模型。從結果來看,四款產品的回答都是不錯的,其中百度文心一言的回答尤其詳細,還順帶介紹了橫波與縱波的定義。

④ 歷史人文類
接下來是歷史人文類知識,IT之家用“《紅樓夢》中結的兩個大型詩社和社長分別是誰?”這個問題來考驗。這是一個相對難且小眾的問題。
首先看文心一言,兩個詩社答對了,但是社長答錯了一個,海棠社的社長是李紈。
通義千問對這個問題的回答有點離譜,詩社和社長都答錯了,而且會讓人有一種“咱們看的是同一本《紅樓夢》嗎”的感覺。
360 智腦的回答也不太好,第二個大型詩社應該是桃花社,而且兩位社長的回答都不對。
最后是訊飛星火,這是這個問題中唯一把兩個小問都答對的選手:
也許是因為科大訊飛本身有做 AI 教育業務的因素,掌握大量的教育大數據,因此整體測下來在知識豐富性和準確性方面的表現是比較亮眼的。這個環節中,四款大模型最終的評分分別為:
四、邏輯推理能力測試訊飛星火:9 分(工作技能類 - 1)文心一言:8 分(工作技能類 - 1,歷史人文類 - 1)360 智腦:5 分(生活常識類 - 1,工作技能類 - 2,歷史人文類 - 2)通義千問:5 分(生活常識類 - 1,工作技能類 - 2,歷史人文類 - 2)
AI 大模型是否足夠聰明,很大程度上取決于大模型是否具備足夠強大的邏輯推理能力。因此本次橫評,IT之家也準備了一些邏輯思維相關的考題來分別考驗四款大模型。
① 邏輯推理問題測試
首先,小編用一個經典的邏輯推理問題來考驗參與評測的 AI 大模型產品,問題如下:
“小明牽著一只狗和兩只小羊回家,路上遇到一條河,沒有橋,只有一條小船,并且船很小,他每次只能帶一只狗或一只小羊過河。你能幫他想想辦法,把狗和小羊都帶過河去,又不讓狗吃到小羊嗎?”
對于這個問題,文心一言的回答第一步就錯了,先帶一只羊過河,那么原岸的狗就會將另一只羊吃掉。而且看文心一言的回答,基本屬于“一本正經地胡說八道”,五個步驟看得人云里霧里。

通義千問的回答也不對,而且比較敷衍。
訊飛星火的回答基本正確,但是如果較真的話,最后還差一個把狗帶到對岸的步驟,因此應該扣 1 分。

360 智腦這次的回答還是比較完美的,步驟全,而且能看懂。
② 常識錯誤、陷阱識別能力測試
接著更進一步,小編在提問中設置一些陷進、錯誤,看看這四款大模型能否準確判斷出題目中的陷進,并成功避坑。
這里小編用的問題是“趙云失荊州的原因是什么?”
對于這個問題,360 智腦和訊飛星火都沒有指出題干的錯誤,但是從回答中能看到,他們的回答還是以“關羽失荊州的原因”來回答的。因此這里我們就扣 1 分吧。
通義千問的回答全程都深信是“趙云失了荊州”,而且它的回答看起來有點離譜,還有“導致荊州被曹操攻占”的詭異發言。
這個問題中回答的最好的是文心一言,不僅指出了題干的錯誤,也準確分析了關于丟失荊州的原因。

本環節四款大模型產品的評分分別為:
五、內容生成能力測試360 智腦:9 分(避坑 - 1)訊飛星火:8 分(邏輯問題 - 1,避坑 - 1)文心一言:8 分(邏輯問題 - 2)通義千問:6 分(邏輯問題 - 2,避坑 - 2)
用戶使用大模型的另一大用途就是讓它們幫助寫一些實用性文案,比如招聘文案、通知文書、店面評價、甚至讓他們創作文章、小說、論文等等。我們把這些統稱為內容生成能力。這也應該成為評測體驗大模型的重要項目之一。
① 文案創作
我們首先來看四款大模型產品的實用文案創作能力,小編讓分別它們寫一段招聘文案,并給出了詳細要求。
還是先看文心一言的回答,它創作的文案是符合要求的,并且條理清晰,風格也沒跑偏,屬于稍微改改就能直接用的水平。

通義千問創作的文案整體是不錯的,但是最后一段讓人看著有點蒙圈,可見它對要求的理解還是有點問題,這里需要扣 1 分。

360 智腦創作的文案有點過于簡潔了,雖然條件也都符合,但文案看著有些機械,格式也不夠清晰明了,因此也扣 1 分。
最后是訊飛星火,它創作的文案也是挺好的,基本沒什么問題,也是稍微改改就能直接使用了。

② 故事接龍
故事接龍也是考驗大模型創作能力的好方法,因此在第二部分,小編主要考驗四款大模型產品的故事接龍創作能力。我們以那個經典的開頭做引子:世界末日后,我成為地球上唯一幸存的人,獨自坐在房間里,這時,突然想起了敲門聲…… 然后讓大模型續寫后面的故事。
文心一言的續寫整體不錯,只是在最后稍微有一些邏輯不通暢的地方,但瑕不掩瑜,而且語言表達中還夾雜著講述者的情感,不是僅僅在陳述一個故事。

通義千問的續寫也不錯,條理清楚邏輯完整,是一個比較合格的續寫。

訊飛星火的續寫也很好,描寫比較細致,設定也還算合理,和通義千問類似,中規中矩。

360 智腦的續寫相對簡單,沒有細節,因此需要扣 1 分。

③ 文章寫作
學生朋友們也可以利用大模型的文章生成能力,來生成范文,學習如何寫好對應題材的文章。這里IT之家以 "家庭環境對人成長的影響" 為主題,讓四款大模型寫一篇高考水平的作文,看看他們的寫作能力如何吧。
首先是文心一言寫的作文,文章整體邏輯通暢,結構清晰,論點有條有理,可以成為學生寫作時用以參考的素材,但是也有不足,首先是缺少論據,其次文章篇幅較短,扣 2 分。

通義千問的作文整體文筆看起來和文心一言差不多,語言也比較平實,缺少論據,但是它的文章字數是合格的,可以扣 1 分。

360 智腦方面,生成的結果不像是作文,字數、文筆等方面都不太能讓人滿意,扣 3 分。

最后是訊飛星火,它的文章和通義千問的差不多,條理清晰,觀點明確,字數也合格,就是也沒有論據來增加文章的可讀性,扣 1 分。

④ 方案企劃
身處職場的朋友經常會需要寫一些方案、活動計劃之類的,這時候也可以借助大模型的內容生成能力來幫助自己更快地完成任務。這里IT之家以“我司計劃開展一個讀書活動,幫我寫一個活動方案”為需求,來進行測試。
文心一言給出的計劃很完整,有條有理,可以成為一個不錯的模板來使用。

通義千問設計的是一個大規模、長時間的讀書活動,也可以執行,但是方案缺少足夠的細節,有點籠統,可以扣 1 分。

360 智腦比通義千問還籠統,缺乏流程細節,這樣的方案領導可能不會滿意,這里就扣 2 分吧。

訊飛星火給出的方案則是比較完整的,時間、地點、目標、流程、前期準備、結果評估等環節都有,而且不缺細節,和文心一言一樣是可用的方案。

小結,在內容生成方面,IT之家圍繞文案創作、故事續寫、作文寫作和方案企劃四個主題進行了測試,整體看下來訊飛星火和文心一言在內容生成方面是比較出色的,其中訊飛星火還要稍好一些。本環節它們各自的評分為:
六、代碼編寫能力訊飛星火:9 分(作文 - 1)文心一言:8 分(作文 - 2)通義千問:7 分(文案 - 1,作文 - 1,企劃 - 1)360 智腦:3 分(文案 - 1,故事 - 1,作文 - 3,企劃 - 2)
AI 大模型出圈時能寫代碼的技能也吸引了很多人的眼球,這也可以視為大模型內容生成能力的重要組成。因此IT之家也測試了四款大模型產品的寫代碼能力。
測試時,小編用下面這個問題來考驗四款大模型:
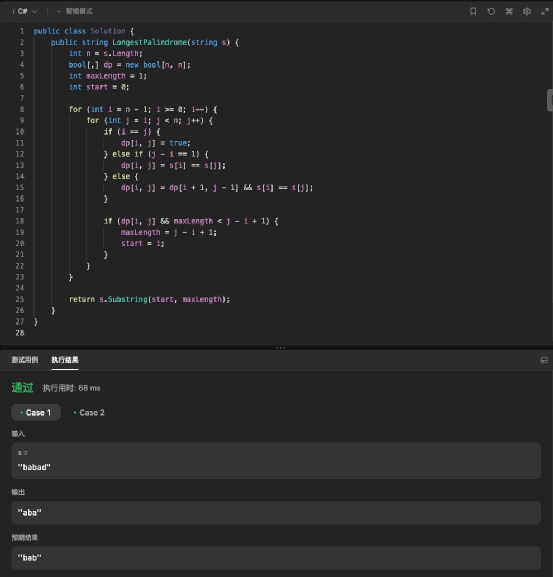
請用 c# 語言生成以下代碼:給你一個字符串 s,找到 s 中最長的回文子串。如果字符串的反序與原始字符串相同,則該字符串稱為回文字符串。代碼請遵循以下模板:public class Solution { public string LongestPalindrome(string s) { }}
我們以代碼能直接拿來使用為準則,將大模型生成的代碼用程序運行工具進行檢測,看是否能直接完美運行,若能運行就不扣分,不能運行就扣 3 分。這個過程中,由于小編自己不懂代碼,因此也找到IT之家的程序員同學來輔助評價。
首先看文心一言的結果,它生成的代碼看起來是有模有樣的,有注釋也有簡介,格式也比較清晰規范。

不過在運行檢測時,可以看到這個代碼出現了執行錯誤,也就是不能直接運行,具體是代碼上出現了數組越位的錯誤。
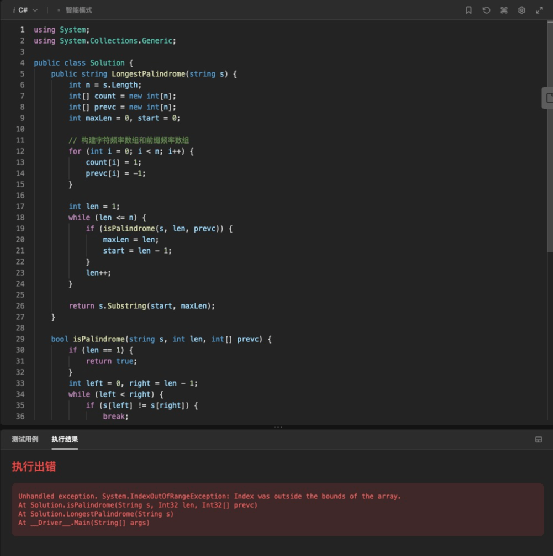
通義千問生成的代碼,在 C# 語言下,代碼格式沒有縮進,觀感不佳,而且出現了把題目中的括號錯誤識別到生成的代碼中的問題。

放到編譯器中。代碼倒是能運行,但是不能輸出正確的結果,這說明代碼在算法上存在問題。
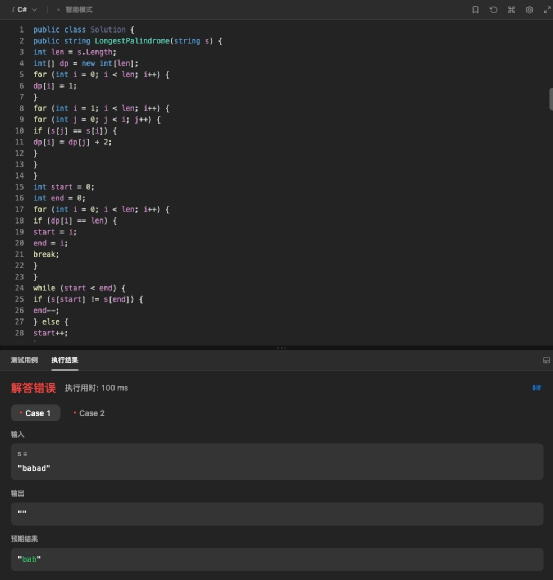
再看 360 智腦的代碼,整體格式比通義千問規范,有注釋,但是也有多余的空行。

運行這段代碼,發現無法直接執行,代碼在第 6 行就出現了語法錯誤,不能進行下去。
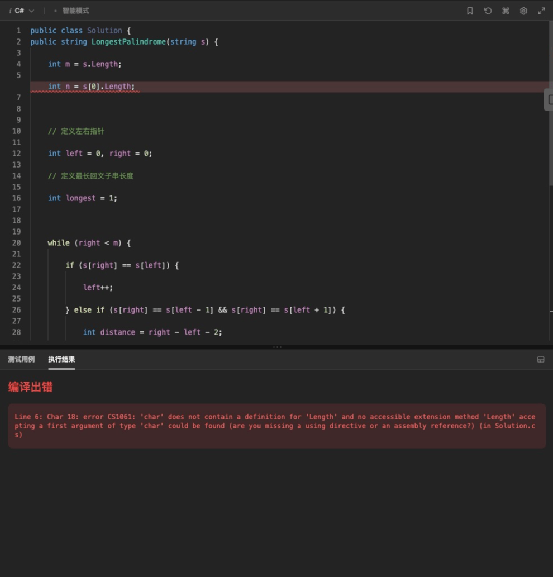
最后是訊飛星火,它給出的代碼格式很標準,而且代碼相比前三者要簡潔很多,看著很清爽。
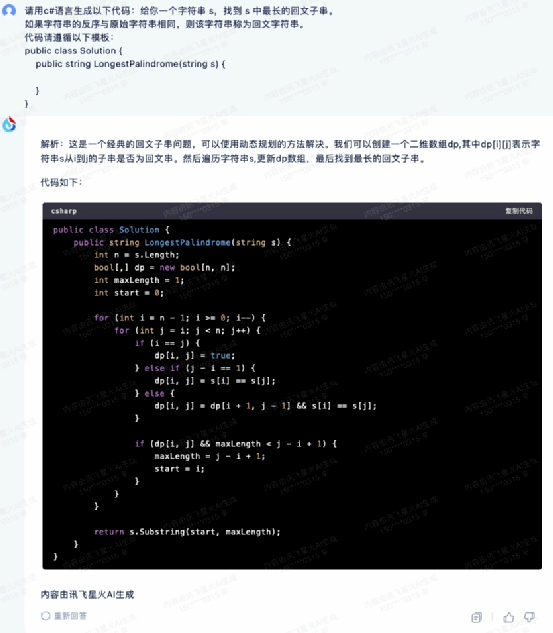
拿到檢測工具中進行運行檢測,發現這段代碼可以直接運行,而且輸出的結果也準確,也就是說可以直接拿來用。它成為這個環節中唯一通過檢測的代碼,可見訊飛星火在寫代碼的能力上是相當不俗的,畢竟要保證生成的代碼能夠直接拿來用是相當不容易的,不僅要整體算法正確、格式以及細節也都要合規。這其實也是訊飛星火的強項了。
總體來說,在代碼編寫環節,訊飛星火展現出了比較明顯的優勢。而在即將到來的 8 月 15 日,訊飛星火還將迎來重要的版本升級,根據已經獲知的信息,它們會在代碼能力上進一步提升,還是比較值得期待的。
在代碼編寫環節四款產品的評分分別為:
七、多輪對話能力測試訊飛星火:10 分文心一言:7 分360 智腦:7 分通義千問:7 分
能否記憶上下文聊天的內容,也是 AI 大模型的一個重要能力,很多時候如果我們對大模型的回答不滿意或覺得問題提得不好,需要局部微調一下,如果不能記憶上下文,我們就得把問題整體重復一遍,再提出新的要求,很麻煩。因此這里我們也測一下這四款大模型是否支持記憶上下文,也就是多輪對話的能力怎么樣。
在這個測試中,我們選擇的多輪對話分別為:
“有哪些描寫月亮的詩詞?
有杜甫寫的嗎?
你自己可以創作一首嗎?
換一首。”
后面三個問題都省去了“描寫月亮”這個前提。
還是先看文心一言的測試,四輪對話,文心一言應對得很好,都能根據上文的問題回答出來。

通義千問方面,表現也能夠讓人滿意。

360 智腦的上下文記憶能力也還行,但美中不足的是,第二個問題把白居易描寫草原的詩強行說成了描寫月亮的,而且最后一個問題小編讓他換一首自己創作的,但它給出的是現有詩詞的拼湊。這兩個地方應該扣 1 分。
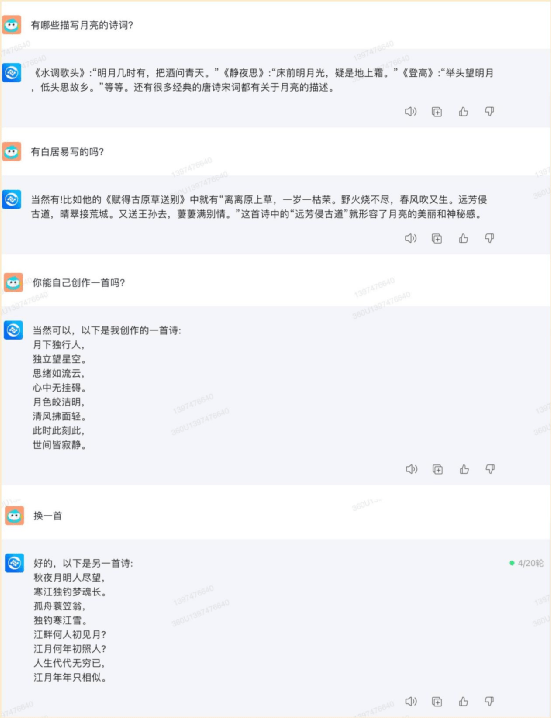
最后是訊飛星火大模型,它的表現也是輕松應對沒有壓力。
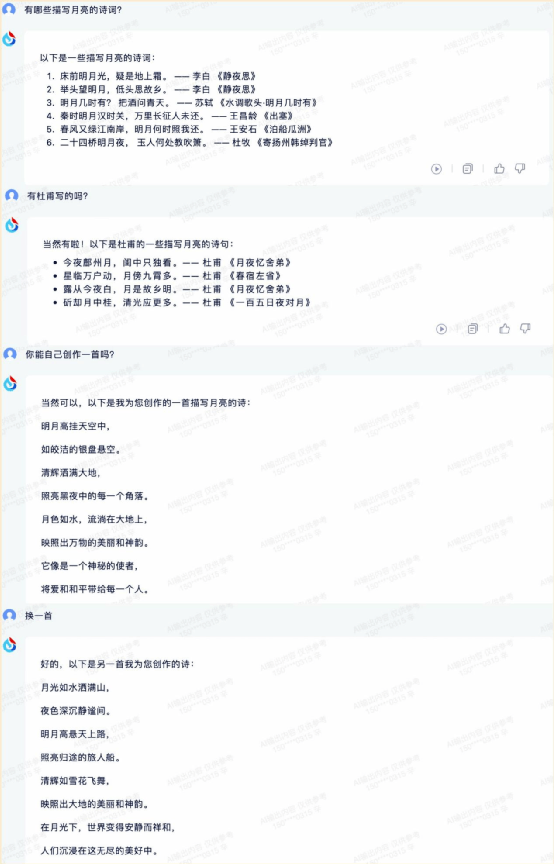
整體來說,四款 AI 大模型的多輪對話能力都是不錯的,除了 360 智腦在回答內容上出了一些小問題,其他三款的表現都沒啥毛病。這一環節四款產品的評分分別為:
八、實時搜索能力測試文心一言:10 分訊飛星火:10 分通義千問:10 分360 智腦:9 分
大家使用 AI 大模型來取代搜索引擎獲取信息,很多時候肯定是想要獲取盡可能比較新的信息,也就是實時搜索能力,這就很考驗大模型背后語料庫、數據庫的更新速度了,同時這也是影響使用體驗的重要因素。IT之家也針對這一點做了對比測試。
測試時,小編首先用最近上映的熱門電影《長安三萬里》來考驗它們,詢問“電影《長安三萬里》講述了一個什么故事?”
文心一言首先給了一個錯誤的回答:
通義千問也陣亡了:

360 智腦撲街 ×3:
這個問題,只有訊飛星火給出了正確答案:
接下來,小編換了一個問題,詢問“NBA 球星克里斯?保羅現在效力于哪只球隊?”這個問題,四款大模型產品均沒有回答正確:
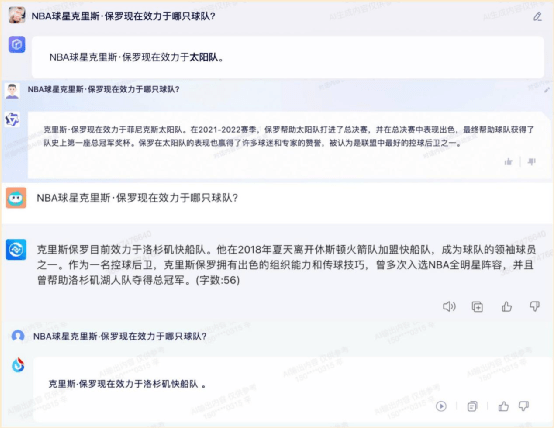
球星克里斯?保羅在今年 6 月被交易到金州勇士隊,這個時間點其實在《長安三萬里》之前,而訊飛星火答對了《長安三萬里》的題目,卻沒有準確回答這一題。可見大模型背后的語料庫對于不同領域的數據更新速度還是不一樣的。
但此后,小編又測了幾個其他問題,整體來說,還是訊飛星火 AI 大模型的實時搜索能力要更強一些,很多最近發生的事情、熱點,它都能侃侃而談。
總結,在實時搜索能力方面,小編給四款大模型的評分分別是:
九、多模態輸入輸出訊飛星火:9 分文心一言:7 分通義千問:6 分360 智腦:6 分
目前通用大模型產品主要還是以文字輸入輸出的形式為主,但是有一部分產品已經能支持文生圖、甚至文生視頻、聲音等。如果能支持多模態輸入輸出,無疑會讓大模型的體驗更好。所以下面我們看看四款產品在多模態方面的支持情況。
文心一言目前支持文生圖,比如小編讓它畫一張牡丹,就能很快生成一張牡丹的畫作:

文心一言還支持文生語音,小編讓它朗讀“我來自IT之家”,它果然生成了一段語音,而且朗讀內容沒有錯誤:
但是文心一言目前還不支持文生視頻:
通義千問方面,目前文生圖、文生視頻、文生語音都不支持。
360 智腦目前支持文生圖,并且能一口氣畫出四幅牡丹畫作:

文生語音方面,由于目前 360 智腦每一條消息都支持語音朗讀的功能,因此我們也可以算它支持文生語音。
最后是訊飛星火,目前它還不支持文生圖和文生視頻功能:
不過,目前訊飛星火支持對回答消息的語音朗讀,并且在 App 端還可以切換朗讀的主播,因此也可以說是支持文生語音的能力的。
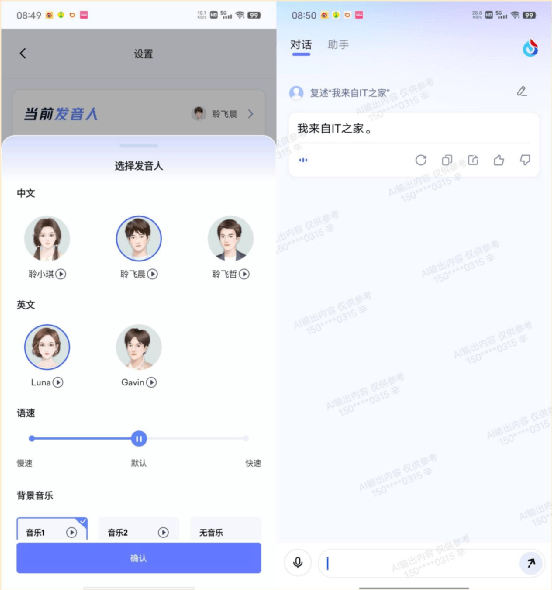
輸入方面,目前文心一言、訊飛星火和 360 智腦都支持語音輸入,通義千問目前則還不支持。
總體來說,目前在多模態輸入輸出方面,文心一言和 360 智腦整體上的表現是相對出色的,特別是 360 智腦,未來隨著跨模態輸入能力的上線,應該會成為視覺工作者們重要的生產力工具。
本環節,四款大模型產品的評分分別為:
十、AI 助手功能文心一言:9 分360 智腦:9 分訊飛星火:8 分通義千問:6 分
如今很多用戶會在自己的專業領域內借助大模型的能力,同時他們使用大模型的場景也越來越細分,于是很多通用大模型產品也推出了針對某一單個場景的 AI 助手功能,來幫助用戶充分調用大模型在某一具體領域的能力。
因此,最后這部分我們來看看所對比的四款大模型在 AI 助手方面的支持情況。
首先還是看文心一言,在 App 端的“發現”欄目中,我們就能找到豐富的“AI 助理”,比如 PPT 大綱生成、朋友圈神器、小紅書探店文案等等,他們“術業有專攻”,大家可以根據自己的需要,選擇專業的 AI 助理來輔助自己的工作。
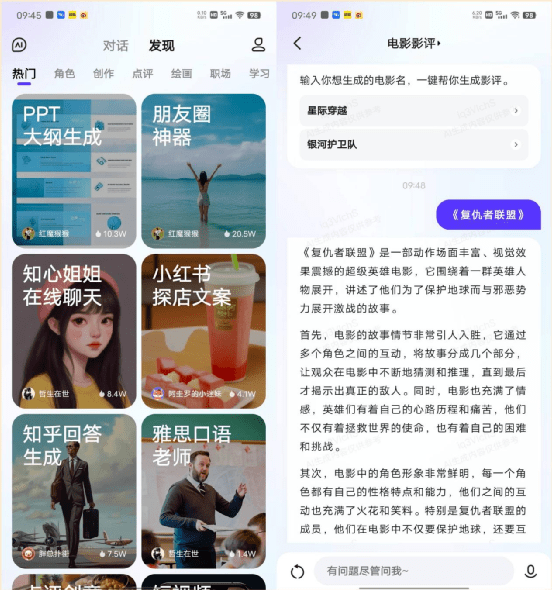
通義千問方面,在“百寶袋”欄目中也能找到一些 AI 助理,但是目前數量上沒有文心一言多,IT之家找到的只有 9 個。在數量豐富度方面需要扣 1 分。
訊飛星火則有專門的星火助手中心,里面的 AI 助手無論數量、種類都非常豐富,功能齊全。

以影評助手為例,小編同樣讓它對《復仇者聯盟》寫一篇影評,影評助手很快就生成了一篇,而且語句通順,邏輯清楚,可以直接用。

訊飛星火還支持自己創作 AI 助手,此前IT之家也為大家體驗過,使用訊飛星火創作 AI 助手的流程并不復雜,而且審核的速度也很快,大家可以根據自己獨特的需求“定制”AI 助手。
360 智腦的 AI 助手叫做“數字人”,進入 360 智腦的首頁就能看到很多數字人列表,而且還能進入數字人廣場,這里面也提供了豐富的數字人可供大家交流、使用。
比較有趣的是 360 智腦的數字人里有很多古今中外的“名人”,比如小編找到“小李子”的數字人,進去后直接和他討論“陪跑經歷”,“小李子”數字人竟然能反應過來,而且回答得相當誠懇得體。
整體來說,文心一言、訊飛星火、360 智腦在 AI 助理方面的表現都能夠讓人滿意,通義千問雖然也有 AI 助理,但目前數量還略少。這一環節,小編給四款大模型產品的評分分別為:
結語文心一言:10 分訊飛星火:10 分360 智腦:10 分通義千問:9 分
本次橫評,IT之家從終端支持、語言理解能力、知識豐富性、邏輯推理能力、內容生成能力、代碼編寫、多輪對話能力、實時搜索能力、多模態輸入輸出、AI 助手功能支持十個方面對文心一言、訊飛星火、通義千問和 360 智腦四款大模型做了詳細的體驗橫評。
整體測下來,如大家所見,訊飛星火、文心一言在產品體驗的全面性方面是比較出色的。特別是訊飛星火讓IT之家感到驚喜,在很多項目中的表現還要更勝文心一言這樣的明星選手一籌,突出一個“穩”,而且在實時搜索、代碼編寫方面優勢明顯,這也可以看出科大訊飛在自然語言理解方面的 AI 技術確實有深厚的積淀。
當然,訊飛星火也不是完美的,主要就是目前多模態支持上略顯單一,還有邏輯推理環節稍有不足。
文心一言的整體體驗也不錯,它在內容生成、避坑能力、多模態輸出等方面有優勢,但是在邏輯推理環節有不足,對比訊飛星火則主要在實時搜索、內容生成和摘要提煉上略處下風,但整體上,也是很值得推薦給大家使用的國內大模型產品。
360 智腦在多模態支持、AI 助手方面比較有亮點,但是在內容生成、語言理解、邏輯推理等比較基礎的體驗方面,能感覺到還有一些待完善的空間,特別是內容生成,成為 360 智腦在這次測試中的主要扣分項。
通義千問目前在功能全面性、完善性和細節體驗上差強人意,就本次測試過程來說,在多輪對話、語意理解、文案創作等方面表現不錯,其他方面體驗大多存在不足,總體來說也還是可以使用的水平,當然這也和通義千問目前側重于在電商業務的探索、應用有關。
下面再回顧一下每款產品的總分數:
訊飛星火:93 分文心一言:84 分360 智腦:75 分通義千問:71 分
最后要說的是,本次橫評所使用的問題樣本畢竟有限,大家實際體驗時的感受可能與IT之家橫評的內容有出入,因此上述評分也僅供大家參考,實際選擇時,大家還是要根據自身的感受來選用適合自己的 AI 大模型。
同時,IT之家也期待隨著云端、終端算力的增強,訓練推理的輪數不斷深入以及語料庫的持續豐富,各家國產 AI 大模型產品能夠千帆競渡,在可用性、成熟度和使用體驗方面能夠以比想象中更快的速度進化,持續推動 AI 深刻變革我們的生產和生活。





