
文章轉載來源:智能派
來源:電廠,作者:張勇毅,編輯:高宇雷
 圖片來源:由無界 AI工具生成
圖片來源:由無界 AI工具生成
7月31日,蘋果中國區(qū)App Store中的ChatGPT產品集體下架,根據(jù)蘋果的說法相關產品需要獲得運營許可證。
不僅僅是中國,立志爭奪這個領域的美國和歐洲,也在鼓勵創(chuàng)新的同時積極立法監(jiān)管。
2021 年 4 月,歐盟委員會首次發(fā)布了一份關于機器學習應用程序運營和治理的監(jiān)管結構提案,提出了對于 AI 的監(jiān)管。彼時 AI 行業(yè)內最流行的觀點,仍是吳恩達的那句著名調侃‘今天擔心人工智能,就像擔心火星上人口過剩’。
但到了 2023 年,這樣的觀點再也無法成為主流:生成式 AI 僅用了不到6個月就向全世界展示了足以替代人類、完全改變現(xiàn)有世界的巨大潛力 —— 正如二戰(zhàn)中被研制出來的核武器一樣。
物理學家 J-羅伯特-奧本海默曾主導研制世界上第一顆原子彈,彼時二戰(zhàn)已經結束,但核彈作為人類歷史上最可怖的武器仍在極大程度上主導著歷史走向:美國政府沒有采納奧本海默等專家關于‘核擴散將會導致前所未有的軍備競賽’的批評與建議,最終導致美蘇之間爆發(fā)以‘超級核彈’氫彈研制為代表的核軍備競賽 —— 并且在古巴導彈危機期間,幾乎將整個人類文明拖入萬劫不復的黑暗深淵。
奧本海默曾經遇到的危機,與當下人類遇到的‘AI 智械危機’有著許多相似之處:在人類使用 AI 將自身拖入更加巨大且不可控的未來之前,將其引導至更加安全的軌道中實行監(jiān)管,或許最好的辦法。
而 2021 年歐盟的‘未雨綢繆’,最終成為了人類歷史上第一個針對人工智能行業(yè)的監(jiān)管框架 —— 也是如今歐盟《人工智能法案》(Artificial Intelligence Act, AI Act)的前身。
但法律制定者在設計這份法案之初根本預料到 2022 年底生成式人工智能或是大模型的存在,因此生成式 AI 在 2023 年的爆發(fā)性崛起,這份法案中也隨之添加了更多關于生成式 AI 的部分:包括其使用大模型的透明度,以及對用戶數(shù)據(jù)搜集/使用的規(guī)范。
目前,這份法案已經在六月中旬獲得歐洲議會表決通過,最終條款下一步是在歐盟三個決策機構 —— 議會、理事會和委員會之間的談判中最終確定法律,在年底之前全部歐盟國家內達成協(xié)議并最終生效。
在中國這邊,對于生成式 AI 的立法也在同時進行:7 月 13 日,《生成式人工智能服務管理暫行辦法》(下文統(tǒng)稱《暫行辦法》)已經由網(wǎng)信辦等七部委聯(lián)合發(fā)布,將在八月正式施行。
這或許將成為首個最終落地的生成式人工智能管理法規(guī),在過去這一輪‘AI 立法賽跑’中,反而是中國的 AI 立法進程反超,成為了目前落地進展最快的生成式 AI 領域專項法規(guī)。
在英美等其他同處于 AI 發(fā)展第一梯隊的國家,對于 AI 的監(jiān)管立法也在同時進行:3 月 16 日,美國版權局發(fā)起一項倡議,研究人工智能技術引發(fā)的版權法和政策問題:包括使用人工智能工具生成的作品的版權范圍,以及為機器學習目的使用受版權保護的材料。英國政府于 4 月 4 日發(fā)布了首個人工智能監(jiān)管框架。此后美國國家電信信息管理局(NTIA)又發(fā)布了人工智能問責征求意見稿,就人工智能問責措施和政策向公眾征求更廣泛的反饋意見。

‘我們是否應該發(fā)展出最終可能在數(shù)量、智慧上能完全取代人類的非人類思維?’這是在今年三月,由多位知名 CEO 與研究人員簽署的一封公開信中所提出的問題。現(xiàn)在回看,發(fā)展生成式 AI 的路徑中,‘所有人暫停研究六個月’這樣的號召過于理想化,眼下只有各國推動起到監(jiān)管作用的生成式 AI 相關法律,或許才是其中行之有效的道理。
創(chuàng)新與問責
生成式 AI 的立法與治理是此前從未有人涉足過的全新領域,每一個立法者都要承擔著外界質疑的壓力:在今年 google I/O 開發(fā)者大會中,Google 正式發(fā)布了其生成式 AI 對話機器人(13.410, -0.26, -1.90%) Bard,但服務范圍卻完全排除了歐洲地區(qū)。
這讓不少歐洲 AI 研究人員/企業(yè)提出疑問:為什么少了歐洲?其后,Google 更多次聲明‘期待面向歐洲用戶開放’,這被進一步解讀為 Google 避免生成式 AI 所存在的法律灰色地帶,導致在歐盟承擔巨額罰款的‘避險措施’。
到了七月,Google 最終披露了其中的原因:Bard 產品負責人 Jack Krawczyk 在一篇博客文章中寫道:在研究之初就已經向愛爾蘭數(shù)據(jù)保護委員會(DPC)提出在歐洲發(fā)布 Bard 的意圖,但最終直到七月才滿足監(jiān)管機構所要求的信息提供。
如今,歐盟《人工智能法案》已經出爐,其中的每一條法律幾乎都直指當下 AI 發(fā)展中顯現(xiàn)或潛在的問題:虛假/錯誤信息的擴散、可能導致的教育/心理健康等重大問題。
但隨之而來立法者發(fā)現(xiàn),解決這一問題更加復雜的部分在于如何確定立法:既需要在保護創(chuàng)新/避免巨頭在 AI 領域壟斷,又需要在一定程度上保證 AI 的可控。避免虛假內容泛濫。就成了中美歐生成式 AI 立法上共同的內核,只是在實際規(guī)范上各有側重。
此前歐洲針對人工智能的多次判例已經引起了 Google 與 OpenAI 等機構的消極對待,不少歐洲本土科技企業(yè)乃至立法者都擔心過于嚴苛的立法將使得歐洲借助于 AI 產業(yè)重返世界領先水平的愿景實現(xiàn)變得困難重重:在《人工智能法案》正式通過之后,歐盟有權針對人工智能違規(guī)公司開出最高 3000 萬歐元、或公司年收入 6% 的罰單。這對于谷歌微軟等想要在歐洲拓展生成式 AI 業(yè)務的公司來講,無疑是一次明顯的警告。
而在六月版本的《人工智能法案》中,歐盟立法者明確納入了新的條款,鼓勵負責任的人工智能創(chuàng)新,同時降低技術風險,對人工智能進行正確的監(jiān)督,并將其置于最為重要的位置:在法案第 1 條就明確,支持對中小企業(yè)和初創(chuàng)企業(yè)的創(chuàng)新舉措,包括建立‘監(jiān)管沙盒’等措施,減少中小企業(yè)和初創(chuàng)企業(yè)的合規(guī)負擔。
但對于面向市場銷售 AI 服務或部署系統(tǒng)之前,生成式 AI 則必須要滿足一系列風險管理、對數(shù)據(jù)、透明度、文檔等監(jiān)管要求,同時在關鍵基礎設施等敏感領域使用人工智能,都會被視為‘高風險’,納入監(jiān)管范疇。
目前,基于《暫行辦法》的 AI 規(guī)范已經有所動作:7 月 31 日,中國區(qū) App Store 中大量提供 ChatGPT 服務的應用被蘋果集中下架,并未提供直接 ChatGPT 訪問、但同樣主打 AI 功能的另一批 App 則暫時不受影響。
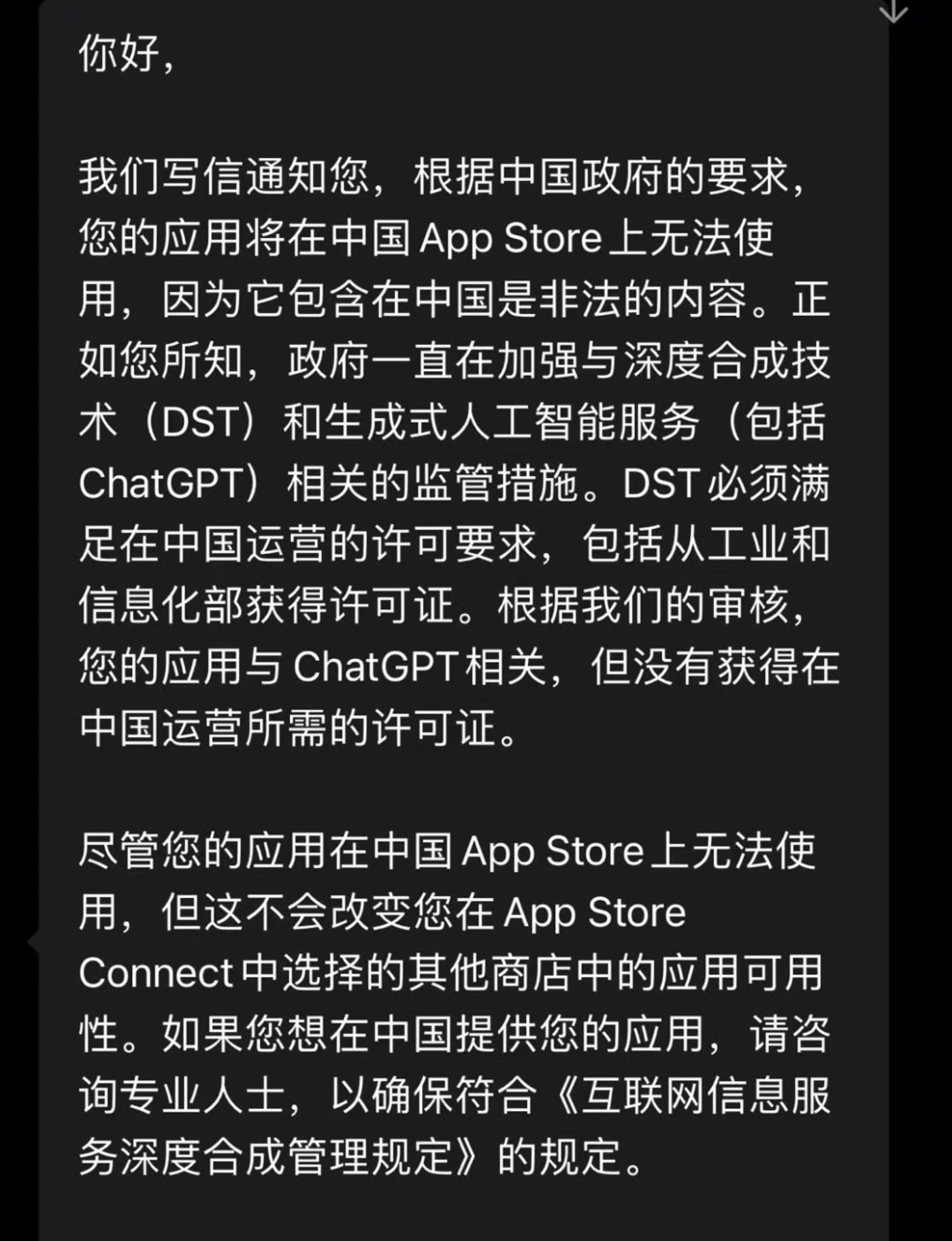
在面向開發(fā)者給出的回復中,蘋果官方給出的審核建議是‘生成式人工智能服務必須滿足在中國運營的許可要求,包括從工信部獲得許可證’,這一審核規(guī)范的變更也直接對應著《暫行辦法》中的‘面向公眾提供服務’這一類別。
中國的《暫行辦法》第十五條中,也明確提到針對生成風險內容的管理方式‘提供者應當及時采取停止生成、停止傳輸、消除等處置措施,采取模型優(yōu)化訓練等措施進行整改’。這已經是在《征求意見稿》中提到的內容;但相比前一個版本,《暫行辦法》中的描述更為溫和,刪除了‘三個月內整改’等期限描述。
當前圍繞生成式 AI 誕生的爭議中,用于訓練生成式 AI 大型語言模型的數(shù)據(jù)版權之爭, 處于生成式 AI 發(fā)展第一梯隊的廠商,都已經感受到受限于高質量內容匱乏帶來的‘隱形天花板’,但與此同時無數(shù)創(chuàng)作者與媒體已經開始就生成式 AI 引發(fā)的版權問題展開法律訴訟等行動。針對生成式 AI 發(fā)展過程中的內容版權保護條款制定已經迫在眉睫。
因此這也是美歐兩地圍繞生成式 AI 立法的重點:歐洲《人工智能法案》中明確要求大模型供應商聲明是否使用手版權保護的材料來訓練 AI,同時記錄足夠的日志信息供創(chuàng)作者尋求補償;而美國版權局則是發(fā)布了新的審查,就生成式 AI 引發(fā)的廣泛版權問題征集建議,尋求專門立法來解決。
而在目前的《暫行辦法》中,目前刪除了四月征求意見稿中的相關段落,讓目前《暫行辦法》中,關于數(shù)據(jù)來源的知識產權保護相關條款還處于一片空白、亟待完善的狀態(tài)。
但對于生成式 AI 所依賴發(fā)展的大模型來說;在互聯(lián)網(wǎng)中搜刮數(shù)據(jù)來加速大模型的迭代發(fā)展是其發(fā)展定律,一刀切式限制很可能導致對整個行業(yè)的重大打擊,因此中歐現(xiàn)行法規(guī)中都提到了不同場景中的‘豁免’:歐盟《人工智能法》中,包括了對開源開發(fā)者 AI 研究的豁免:在開放環(huán)境中合作和構建人工智能組件將受到特殊保護。同時《暫行辦法》中,相關條款也明確了法例的豁免范圍:
‘只要企業(yè)、科研機構等,不是向公眾公開提供生成式人工智能服務,則不適用本法’。
‘知識產權領域的立法仍然需要更多的時間來進行研究與論證’一位目前服務于大模型廠商的法律顧問對記者表示:‘中文高質量數(shù)據(jù)集相比英文內容要更加稀缺,而生成式 AI 訓練的特性就決定了即使是巨頭也無法完全做到和每一家平臺、每一位內容創(chuàng)作者獨立簽約使用,更不用說天價的授權使用費已經是對初創(chuàng)公司的巨大打擊’。
‘或許目前的這個問題,只能留給時間讓行業(yè)發(fā)展來得到更好的實踐解決’。這位顧問補充道,競爭與合作。雖然中美競爭中,AI 發(fā)展已經成為美國遏制中國發(fā)展的主戰(zhàn)場之一,但就生成式 AI 立法領域,中美歐之間的合作也在逐漸成為主流。
現(xiàn)階段,美國的人工智能公司都已經意識到了開發(fā) AI 過程中伴隨而來的風險。紛紛做出保證 AI‘不作惡’的承諾:OpenAI 表示既定使命是‘確保人工通用智能造福全人類’。DeepMind 的運營原則包括承諾‘作為人工智能領域負責任的先鋒’,同時 DeepMind 的創(chuàng)始人承諾不從事致命性人工智能的研究,而 Google 的人工智能研究原則也規(guī)定,Google 不會部署或設計用于傷害人類的武器、或違反國際規(guī)范的監(jiān)控的人工智能。
在 7 月 26 日,Anthropic、谷歌、微軟和 OpenAI 發(fā)起了名為前沿模型(Frontier Model Forum)的論壇,這是一個專注于確保安全、負責任地開發(fā)前沿人工智能模型的行業(yè)機構。
這個論壇將致力于在推動人工智能研究的同時,‘與政策制定者、學術界、民間機構合作,最大限度降低風險,分享關于安全風險的知識’。同時主動融入現(xiàn)有國際多邊合作:包括 G7、經合組織等組織關于生成式 AI 的政策制定。以促進各國在立法、監(jiān)管理念等方向同步。

此前,《時代》雜志曾評論稱,中國與美國在生成式 AI 的‘重要參與者’地位,與歐洲經常在事實上成為新技術立法的‘開拓者’之間,存在著許多合作的可能性,在立法階段開始合作符合各方利益,同時也是促進生成式 AI 發(fā)展的重要手段之一。
在這也與麻省理工學院教授、生命未來研究所創(chuàng)始人 Max Tegmark 的觀點契合:‘中國在生成式 AI 的很多領域中都處于優(yōu)勢地位,將很有可能成為駕馭人工智能的領導者’。
中美兩國大模型數(shù)量占據(jù)了全球 90%,因此中美與歐洲之間的立法協(xié)調,甚至將會決定全球生成式 AI 行業(yè)發(fā)展的走向。‘在符合美國利益的前提下與中國進行立法協(xié)調’已經逐漸成為美國政界學界的共識。

WIRED 專題報道封面
比較有代表性的是對 AI 風險的分級措施:中國《暫行辦法》中提到‘對生成式人工智能服務實行包容審慎和分類分級監(jiān)管’,但并未在目前的版本中詳細闡述其中的分級規(guī)范,目前只寫入了‘制定相應的分類分級監(jiān)管規(guī)則或者指引’等段落。
而歐洲的《人工智能法》同樣提出了通過分級制度,來對應不同風險程度的 AI 開發(fā)者所需承擔的義務,目前提出的 AI‘威脅等級’共包括四類:
有限風險類 AI 高風險 AI 不可接受級風險 生成式 AI:類 ChatGPT 等產品目前的版本中,《人工智能法》將生成式 AI 作為獨立分類摘出應對,同時針對被分類為‘高風險 AI’的產品嚴格限制,必要時通過人工監(jiān)管等措施介入,從制度上規(guī)范降低 AI 出現(xiàn)風險的可能性。這也被認為是中美兩國未來針對 AI 風險立法的‘參考藍本’。
此外,從實際立法進程中來看,主動邀請公眾以及 AI 研究機構參與進立法過程中,都是各國監(jiān)管機構在過去半年中通過經驗形成的共識,‘尊重 AI 發(fā)展規(guī)律的前提下制定法律’已是不容質疑的‘影子條款’。
‘生成式 AI 或許永遠不會迎來完美的那一天,但法律注定會在 AI 發(fā)展的關鍵方向起到重大作用’
正如同奧本海默即使反對核武器用于戰(zhàn)爭、但同時也從未后悔過在新墨西哥州將原子彈研制出來一樣,誰都無法阻止好奇的研究人員用現(xiàn)有的技術開發(fā)出更加智慧的 AI,科學探索的腳步也從來不會就此停止。‘必要且合理’的監(jiān)管,即是 AI 狂熱奔跑路上的‘減速帶’,也是阻止生成式人工智能造成真正傷害的‘最后防線’。
但聚焦于‘如何避免由監(jiān)管導致在 AI 競賽中落后’,仍是立法者最為關心的事情之一。相關法例毫無疑問也會隨著更多的經驗與反饋變得更加完善。
‘監(jiān)管機構將秉承著科學立法、開門立法的精神,及時地予以修改完善。’《暫行辦法》中關于生成式 AI 的這段話,或許就是生成式 AI 時代立法的最好原則。





