近一段時間,國內生成式人工智能模型的推出可謂是你方唱罷我登臺,好不熱鬧。
快科技8月21日消息,近日,快手的自研大模型快意”(KuaiYii)已經出現在了AI綜合中文評估基準CMMLU的榜單中。
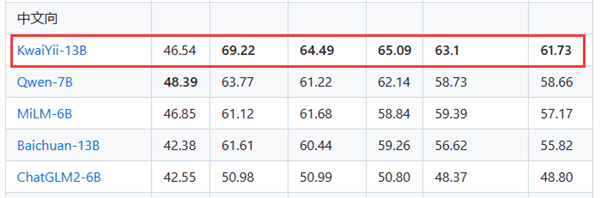
截至本文成稿,該模型的13B版本KwaiYii-13B同時位列five-shot和zero-shot項目下的中文向第一名,在人文學科、中國特定主題等方面較強,平均分超61分。
而根據快意在GitHub頁面給出的信息,該模型是快手AI團隊獨立自言的大規模語言模型。
目前,快意覆蓋了預訓練模型(KwaiYii-Base)、對話模型(KwaiYii-Chat),主要特點包括:
1、KwaiYii-13B-Base預訓練模型具備優異的通用技術底座能力,在絕大部分權威的中/英文Benchmark上取得了同等模型尺寸下的State-Of-The-Art效果。
例如,KwaiYii-13B-Base預訓練模型在MMLU、CMMLU、C-Eval、HumanEval等Benchmark上目前處于同等模型規模的領先水平。
2、KwaiYii-13B-Chat對話模型具備出色的語言理解和生成能力,支持內容創作、信息咨詢、數學邏輯、代碼編寫、多輪對話等廣泛任務,人工評估結果表明KwaiYii-13B-Chat超過主流的開源模型,并在內容創作、信息咨詢和數學解題上接近ChatGPT(3.5)同等水平。