

百川智能又發(fā)布大模型了。
9月6日,王小川旗下百川智能正式發(fā)布開源微調后的Baichuan 2-7B、Baichuan 2-13B、Baichuan 2-13B-Chat與其4bit量化版本,均為免費可商用,這是繼6月15日發(fā)布首款開源大模型Baichuan7B后的又一次重大技術迭代。
據(jù)了解,Baichuan 2-7B-Base 和 Baichuan 2-13B-Base,均基于 2.6萬億高質量多語言數(shù)據(jù)進行訓練。其中Baichuan 2-13B-Base相比上一代13B模型,數(shù)學能力提升49%,代碼能力提升46%,安全能力提升37%,邏輯推理能力提升25%,語義理解能力提升15%。
王小川稱,70億參數(shù)的Baichuan2-7B開源大模型中文水平超越了LLaMA2 130億參數(shù)模;在英文的評測上,Baichuan2-7B開水平與LLaMA2 130億參數(shù)模型持平。
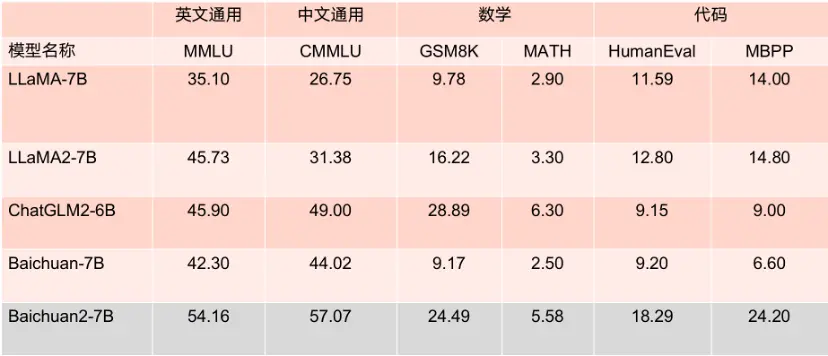
(圖:7B參數(shù)模型的Benchmark成績)
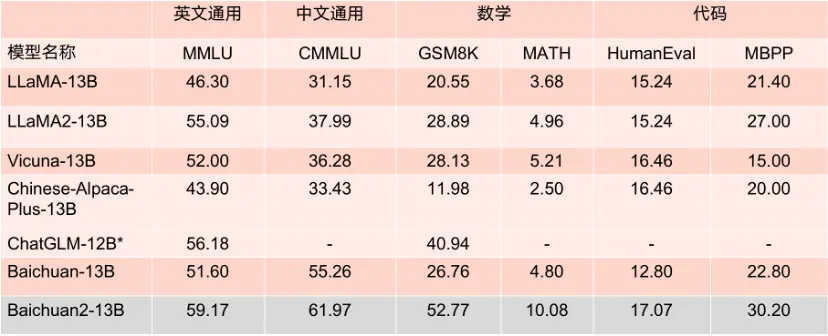
(圖:13B參數(shù)模型的Benchmark成績)
他表示,“隨著國內Baichuan2開源大模型的發(fā)布,用LLaMA2作為大家一個開源模型的時代已經(jīng)過去了。”
國內“百模大戰(zhàn)”中,各家都在卷參數(shù)規(guī)模,卷響應速度,卷行業(yè)落地。而在國外,AI模型競爭主要聚焦在“生態(tài)封閉”和“生態(tài)開源”。其中,閉源模型的代表當屬目前最強的GPT-4模型,開源最具代表意義的則是Meta的LLaMA2模型。
業(yè)內普遍認為,開源大模型對于大量開發(fā)者是一個福音,能夠降低做大模型應用的門檻。美國斯坦福大學基金會模型研究中心主任Percy Liang 曾指出,像LLaMA2這樣強大的開源模型會對OpenAI 構成相當大的威脅。
今年6月,王小川飛往美國硅谷與同行交流大模型技術思路。他認為,美國閉源大模型的頭部格局已定,OpenAI、Anthropic、Google已經(jīng)拿到門票,LLaMA2則統(tǒng)一了美國開源模型市場,而國內大模型格局還未定型,創(chuàng)業(yè)公司還有較大的機會。
在8月舉辦的一次媒體交流會上,王小川談及大模型技術路線之爭時表示,開源與閉源并不矛盾,未來會像蘋果和安卓系統(tǒng)一樣并行發(fā)展。未來可能80%的企業(yè)會用到開源模型,因為開源模型小巧,最后靠閉源提供剩下20%的增值服務。 從2B(企業(yè))的角度,開源、閉源都需要,百川智能不會只瞄準一個方向。
王小川指出了LLaMA開源模型的隱藏限制因素。他表示,LLaMA 開源模型適用于以英文為主的環(huán)境,開發(fā)者使用中文場景是拿不到開源協(xié)議,Baichuan2開源大模型更適用于中文大模型。
“我們現(xiàn)在可以獲得比LLaMA更友好且能力更強的開源模型,能夠幫助扶持中國整個生態(tài)的發(fā)展。除開源模型以外,下一次在閉源方面會有更多的突破,希望在中國的開源閉源里都能給中國的經(jīng)濟社會發(fā)展帶來我們的貢獻。”
當前大部分開源模型在開源過程中只是對外公開自身的模型權重,很少提及訓練細節(jié),企業(yè)、研究機構、開發(fā)者們只能在開源模型的基礎上做有限的微調,很難進行深入研究。
王小川表示,百川智能公開了Baichuan2開源大模型訓練過程中的全部參數(shù)模型,以及不同大小的 tokens、訓練切片,使得學術界在進行預訓練微調、強化時更容易操作,更容易獲得學術經(jīng)驗和成果。他透露,這也是國內首次開放訓練過程。
百川智能創(chuàng)立于今年4月10日,旨在打造構建中國最好的大模型底座,并在教育、醫(yī)療等領域應用落地。截至目前,百川智能已公布首輪5000萬美元融資。
成立不到半年時間,百川智能平均每28天發(fā)布一款大模型,已相繼發(fā)布了Baichuan-7B、Baichuan-13B兩款開源免費可商用的中文大模型,以及一款搜索增強大模型Baichuan-53B。
8月31日,百川智能通過《生成式人工智能服務管理暫行辦法》備案,旗下大模型可以正式面向公眾提供服務。
【來源:鳳凰網(wǎng)科技】





