
在服務器領域獲得新的計算引擎需要很長時間,而且每個人都在抱怨。客戶很不耐煩,因為他們想要新一代芯片帶來的更高性能和更高性價比。那些制造 CPU、GPU 和其他計算引擎的人也很不耐煩。他們想要壓垮競爭對手并賺更多的錢。
在本周的 Hot Chips 2023 上,Arm Ltd 在宣布(再次)上市后展示了其“Demeter”V2 內核,該公司還推出了“Genesis”N2 計算子系統,簡稱 CSS 智能包。(我們將單獨深入探討 V2 核心。)Genesis 的這一努力有可能比過去更快地讓 Arm CPU 進入該領域。
多年來,Arm 一直在朝著將成熟的 CPU 組裝在一起以供客戶修改并直接推向市場的目標邁進。早在 2000 年代末,當 Arm 接管智能手機時,服務器制造商正在考慮 Arm 架構如何改進基本上處于壟斷地位的 X86 架構,服務器芯片設計人員從 Arm 架構許可開始,并開始使用它。這是一種非常昂貴且耗時的創建服務器芯片的方法,盡管比從定制 ISA 開始要好,但由于大量的軟件移植工作,世界無法容忍定制 ISA。
在 Broadcom、高通、AMD 和三星等老牌半導體巨頭以及 Calxeda 和 Applied Micro 等初創公司多次嘗試 Arm 服務器芯片失敗后,以及 Cavium 憑借其 ThunderX 和 ThunderX2 CPU 取得了一些有限的成功后,Arm 決定將其推出。Neoverse 的工作于 2018 年 10 月推出,它不僅提供了服務器芯片核心的路線圖,還提供了參考架構,用于將這些核心轉變為適當的 CPU,并混合了其他 Arm 知識產權(例如片上芯片)網狀互連和第三方內存、PCI-Express 控制器和以太網控制器。這些 Neoverse 設計是針對臺積電的特定工藝節點量身定制的,這使得服務器芯片制造商更容易更快地采取行動。
我們從來不確定 Neoverse 是否比架構許可證更便宜或更貴。你可以用多種不同的方式來論證它。Neoverse 完成了更多的工作,但與 Arm 架構許可證相比,自由度有限。也許更重要的是,正如我們所說,如果 Arm 不能比開源的 RISC-V ISA 和設計更便宜,那么它可以更快。由于客戶不耐煩,Arm 無論如何都必須更快。
以下是2022 年 9 月公布的最新 Neoverse 路線圖:

最初,只有一個內核系列 - N 系列 - 但 Arm 將其分為三個內核系列和三個相應的平臺,每個平臺都針對系統市場的不同部分。N 系列核心和平臺針對主流服務器工作負載,其中每瓦性能驅動設計,而 V 系列具有更重的矢量處理,針對計算密集型工作負載,例如 AI 訓練和推理以及 HPC 模擬和建模。E 系列旨在實現吞吐量計算,并且不僅針對更高的每瓦性能進行了優化,而且還以比 N 系列更低的熱封裝實現了最大吞吐量。現在不僅有三個系列的內核和平臺,還有兩種方法:DIY 和 CSS。
所以現在新的 Neoverse 路線圖看起來像是硬塞進去了 CSS 選項:
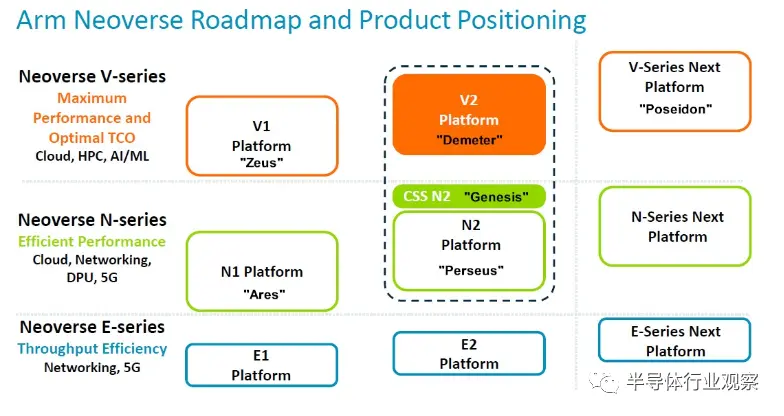
我們已經為我們所知的每個核心和平臺添加了代號。
Neoverse 的努力讓芯片公司在設計上取得了優勢,而且許多公司已經做到了。富士通的 A64FX 芯片比當前任何供應商都早得多(比 Neoverse 的努力早了很多年),并且在許多方面都可以被視為“Kronos”V0 實現,因為它發明了可擴展矢量擴展并將其帶入了-Intel AVX-512 的位向量極限。亞馬遜在其 Graviton1 芯片中使用了原始 Neoverse 堆棧中的“Maya”Cortex A72,在其 Graviton2 芯片中使用了“Ares”N1,在其Graviton3 芯片中使用了“Zeus”V1。
十多年前,Nvidia 最初使用其 Arm 架構許可來創建“Denver”服務器處理器,但已改用“Grace”CPU 芯片的 V2 內核現在即將上市。AmpereComputing 的 Altra 和 Altra Max Arm CPU 中使用 N1 內核,但現在正在開發定制內核。顯然,阿里巴巴已經為其倚天 710 處理器定制了 Arm v9 核心,如果這是真的,那么 Nvidia 的 Grace 并沒有市場上第一個 Arm v9 核心。印度政府正在其“Aum”A48Z 處理器中使用 V1 內核。
還有其他的,但這些是最重要的。他們都花費了大量資金來創建 Arm 服務器芯片。但這既關乎時間,也關乎金錢。眾所周知,愛因斯坦證明了時間就是瘋狂的金錢,也證明了能量就是瘋狂的物質。
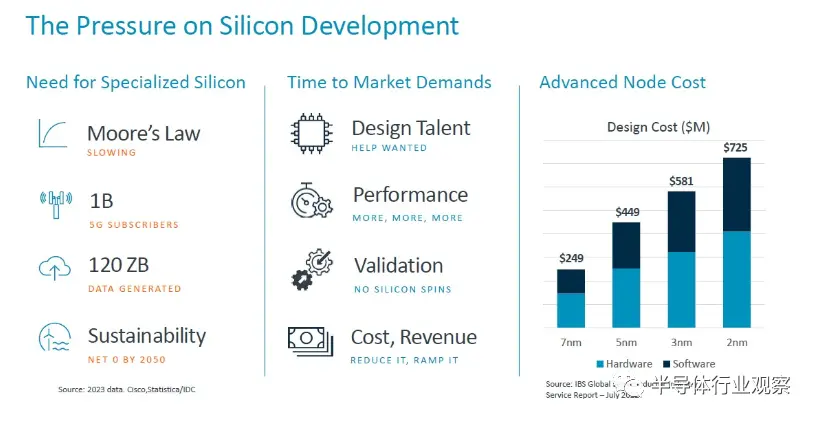
正如 Arm 產品管理高級總監 Jeff Defilippi 在 Hot Chips 上的 Arm 演講之前解釋的那樣,隨著摩爾定律的耗盡,對專用芯片的需求不斷增長,芯片設計人員面臨的壓力也在不斷增加。正如上圖所示,隨著晶體管尺寸的縮小,設計芯片的成本也在上升,而在 7 納米節點之后,每個晶體管的制造成本也在上升,但該圖沒有顯示這一點。
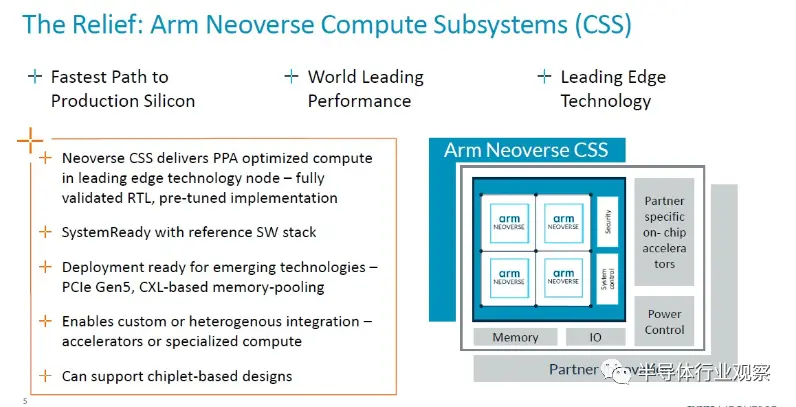
Arm 的 CSS 知識產權包旨在加快設計速度,從時間就是金錢的意義上來說,至少可以將金錢轉化為節省的時間,正如愛因斯坦所證明的那樣,這既是節省的金錢,也是通過早期銷售獲得的金錢。(我們假設 CSS 的成本比常規 IP 許可更高,因為它包含更多內容,但風險要低得多,而且成本和風險的乘積(不是總和,而是乘積,因為這些是乘法效應而不是累積效應)因此較低.)
從概念上講,CSS 包如下所示:
以下是它與 SoC 許可、IP 許可和架構許可的比較:
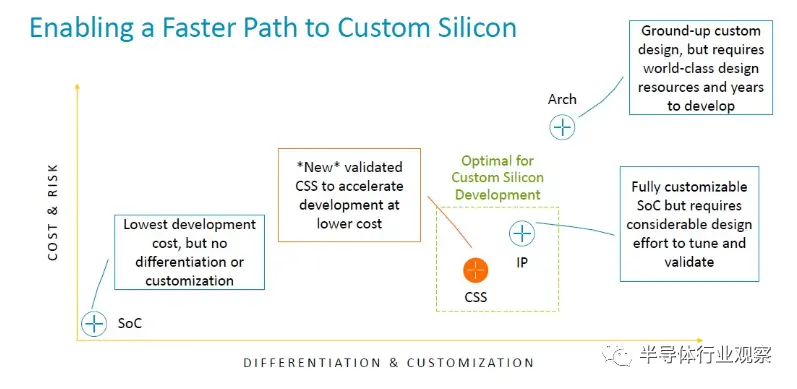
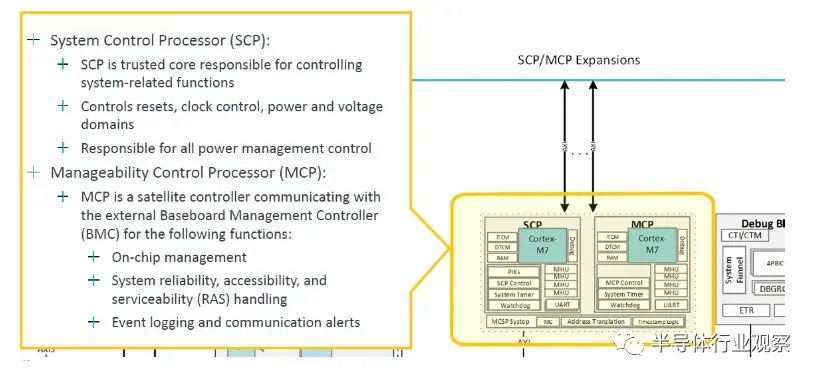
“本質上,該產品是 Arm 拼接在一起的多核設計,”Defilippi 解釋道。“這就是互連、CPU、虛擬化 IP 要求 - 我們將它們縫合在一起,進行驗證,并將其作為生產就緒的 RTL 可交付成果交付給我們的客戶。除了 RTL 之外,我們還提供與之相關的額外好處:我們提供實現包、平面圖、實現腳本以及達到該性能所需的物理 IP 庫以及設計所需的功耗范圍。領先的技術。我們提供完整的軟件參考堆棧。因此,這包括從固件、電源管理、系統管理、系統所需的運行時安全性等一切內容。我們提供參考堆棧,以確保軟件開發從第一天開始,并且我們的客戶有一個良好的起點。最后但并非最不重要的一點是,我們不僅包括工藝節點,還包括我們的領先技術。每年都會有一些新的、令人興奮的事情出現。當然,現在的一個例子就是 CXL 內存擴展池。”
現在想象一下,特別是如果您位于中國、印度、非洲,甚至位于美國或歐洲的具有成本意識的超大規模企業、云構建商或 HPC 中心,并且您沒有大量熟悉高級服務器 CPU 的熟練工程師設計或正確設計和測試它們的工具,以便快速推出下一代芯片。那么 CSS 方法不僅可以大大加快速度,而且可以從一開始就制造出芯片。
但時間很重要,以下是 Arm 如何計算通過 CSS 包與使用普通 IP 許可證相比節省的時間:
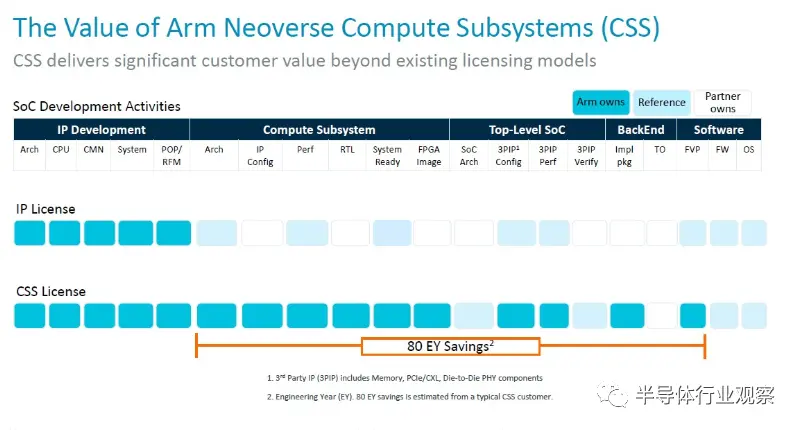
節省 80 個工程師一年的時間是相當可觀的,特別是在定制自由度仍然存在的情況下。
問題是:與芯片制造商所做的大量工作相比,CSS 設計的價值有多大?將芯片從概念變為服務器、網絡設備或存儲陣列需要多少成本?這比使用 Intel 或 AMD 的 X86 服務器或 AmpereComputing 的 Arm 芯片便宜多少?這些麻煩值得嗎?
嗯,隨著 AWS 和阿里巴巴制造自己的 Arm 芯片,而且有傳言稱谷歌也將這樣做,微軟、騰訊和百度(以及阿里巴巴、谷歌和甲骨文)也使用 AmpereComputing 的 Altra Arm 芯片,看來這是值得的。Arm CPU 為他們節省了資金,并且在他們的服務器群中所占的比例越來越大。而且,他們通過自己的努力擁有更直接的控制權,并通過與安培計算的緊密合作獲得更間接的控制權。
當然,超大規模廠商和云構建商仍會購買大量英特爾和 AMD CPU。但正如我們多次說過的那樣,這將是為了支持舊版 Windows Server,有時甚至是 Linux 應用程序,他們會故意對基于它們的實例收取額外費用,英特爾和 AMD 也會對底層芯片收取額外費用。沒有人在我們看到的分層上串通一氣,但英特爾和 AMD 沒有動力與 Graviton 和其他公司競爭。他們只是將 15%、20%、25% 的超大規模和云機群讓給 Arm,他們對無需打價格戰就能獲得 85%、80%、75% 的更大機群感到滿意。
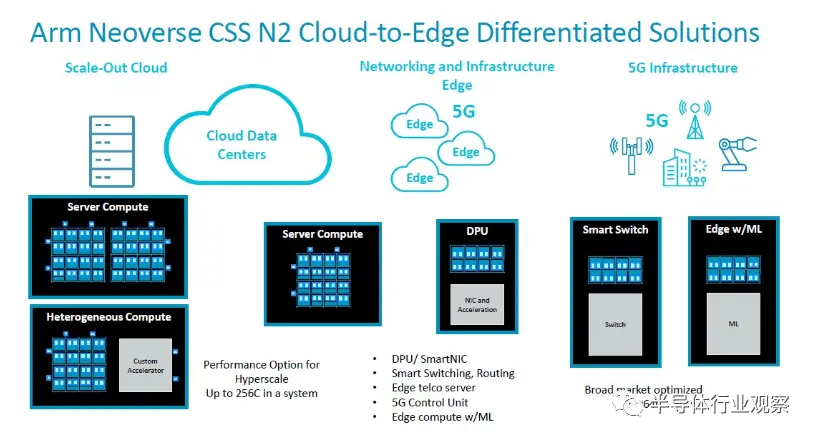
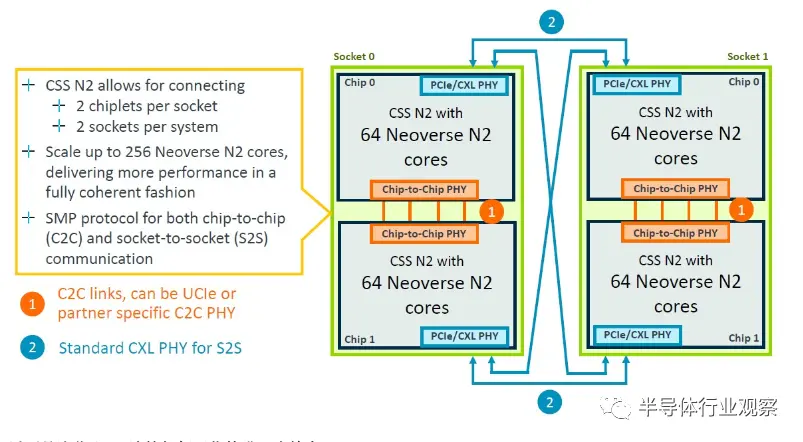
“Perseus”N2 核心網格的 CSS 實現可從 24 個核心擴展到 64 個核心,并且可以使用 UCI-Express(而非 CCIX)或專有互連將其中四個核心組合在一個封裝中,以擴展到插槽中的 256 個核心。根據客戶的需求提供小芯片。
考慮到許多現代處理器將執行預期的 HPC 和 AI 矢量數學,遺憾的是 V2 設計沒有 CSS。也許這會發生——我們強烈鼓勵這樣做,當然也鼓勵幾年后的未來 V3 設計。目前,Arm 僅在 N2 設計中開始 CSS 工作,就在路線圖的中間。
現在,請做好準備,欣賞 Genesis CSS N2 封裝上的一些精美原理圖和框圖,這些原理圖和框圖由 Arm 院士兼芯片 IP 設計師的首席系統架構師 Anitha Kona 提供。
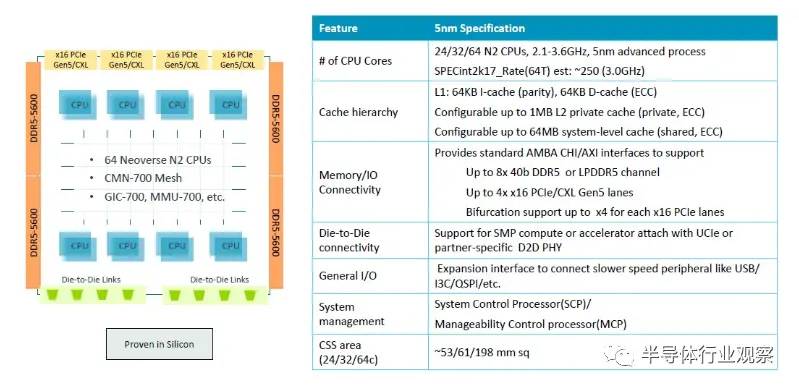
這是臺積電 5 納米 Genesis 封裝中的 64 核基礎模塊:
框圖如下所示:
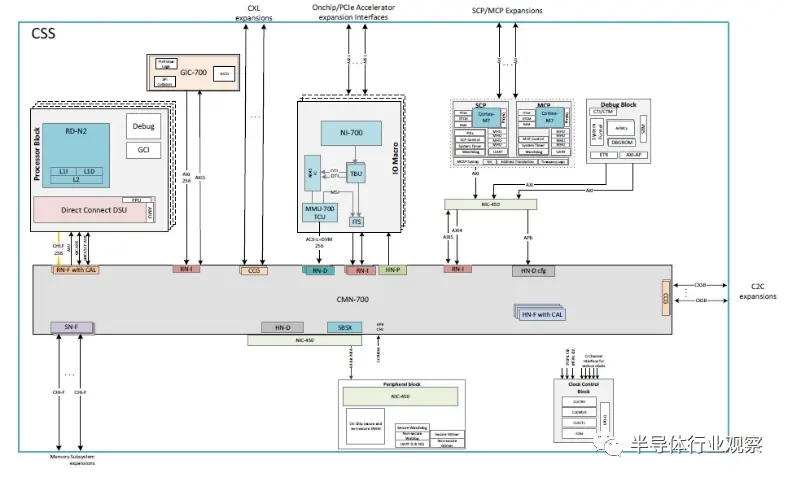
CSS N2 軟件包符合 SystemReady 標準,符合 Arm 基礎系統架構 1.0、Arm 服務器基礎系統架構 6.1 和 Arm 服務器基礎啟動要求 1.2。
N2 核心是 Arm 的第一個 Armv9 實現,但 V2 核心不可能落后于 Grace 目前的水平,據我們所知,Nvidia 從 Arm 獲得了 V2 核心。Nvidia 和 Arm 有可能在 V2 核心設計上進行合作,就像富士通和 Arm 在我們所說的 V0 核心上所做的那樣。N2 核心的處理器模塊如下所示:
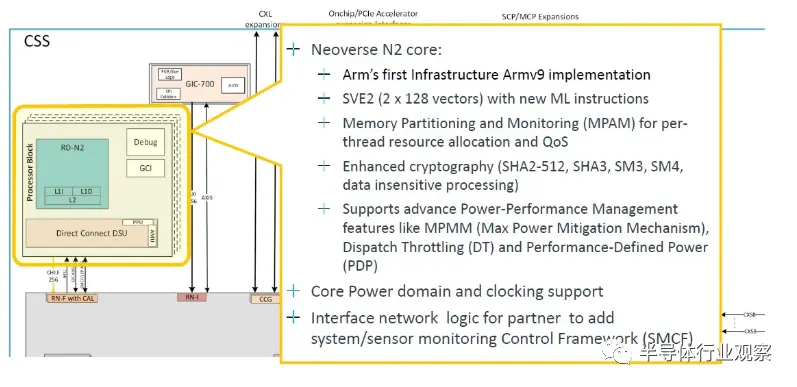
兩個 SVE2 128 位向量還不錯,但 V2 有四個。這就是需要 CSS V2 產品的地方,希望很快不會出現代號為“Exodus”的情況。就像,呃,現在。無論如何,這是系統控制和管理的深入內容:
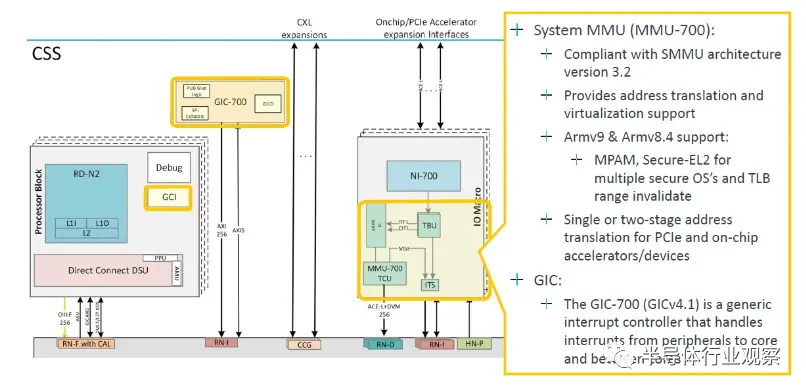
系統內存管理單元和中斷控制器的放大是:
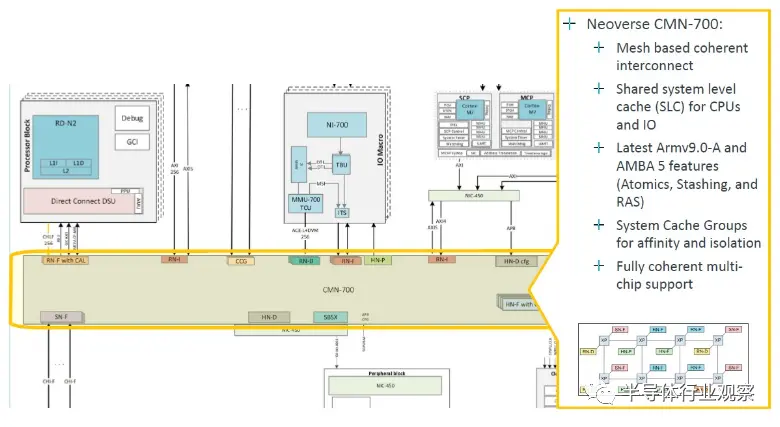
核心塊使用 CMN-700 網格相互綁定,該網格已經存在了幾年,并針對 Armv9 設計進行了調整,運行頻率為 2 GHz:
Genesis 軟件包包括 N2 CPU 的平面圖,可以從 24 核擴展到 64 核,64 核平面圖如下所示:
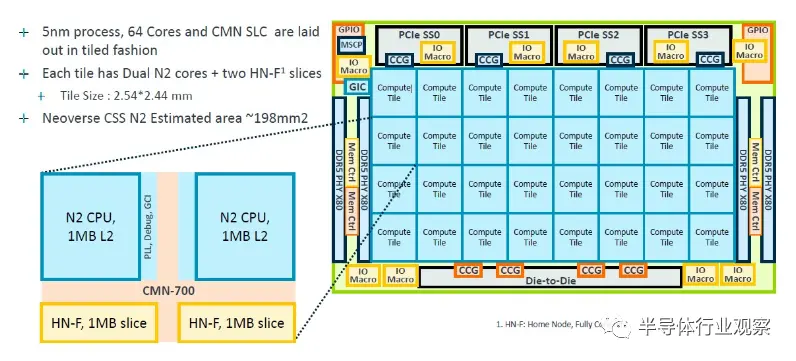
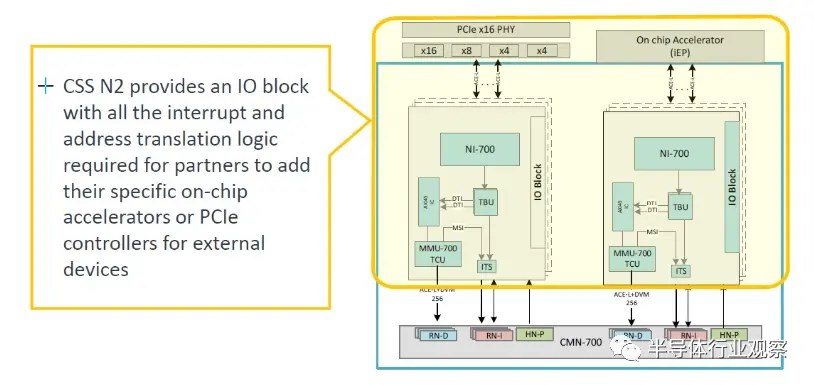
CSS N2 軟件包還包括一個加速器連接塊,允許卡入 PCI-Express 以及 CXL 控制器:
互連允許四個 64 核 N2 塊中的兩個相互鏈接。一對芯片利用芯片到芯片 PHY 實現直接對稱多處理 (SMP) 鏈路,CXL PHY 用于交叉耦合其中一對,以創建具有 256 個內核的四路封裝,例如這:
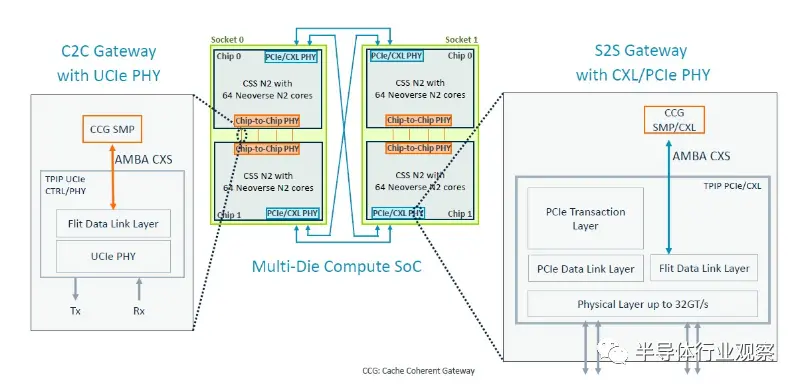
以下是這些 SMP 連接如何工作的進一步放大:
PCI-Express/CXL 塊顯然允許 CXL Type 3 內存擴展,超出嵌入在網格互連上的任何內存控制器。(如果內存控制器和以太網控制器是 Genesis 包的一部分,那將會非常有幫助。)
最后,這是 Generis 軟件包中的軟件:
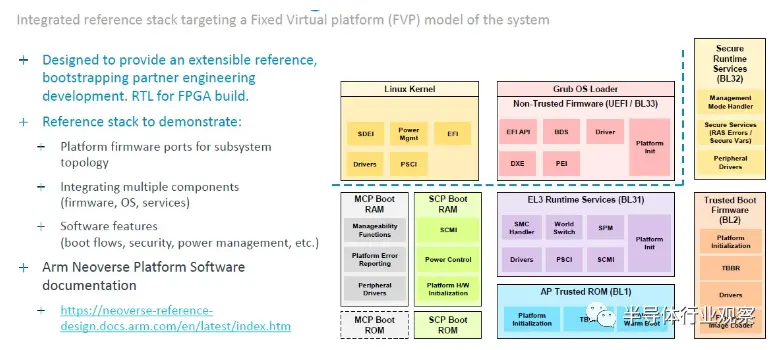
將所有這些加起來,Kona 表示 Genesis IP 包被許可方可以獲取 CSS N2 堆棧,在內存、I/O、加速器和物理拓撲上進行差異化,并在令人驚嘆的 13 個月內從啟動到工作芯片,并節省80個工程師的開發努力。這些是來自兩個不同的 Arm 合作伙伴的兩項統計數據,他們是 Genesis 的早期采用者,因此在將這些數據位混合到一個承諾中時要小心。但顯然,Arm CPU 芯片設計既可以節省時間,又可以節省金錢——這也是時間。
我們期待看到與 CSS N2 包相當的 V 系列和 E 系列。
【來源:半導體行業觀察】





