擊這里在線咨詢客服")
在上一期的大模型技術(shù)實(shí)踐中,我們?yōu)榇蠹医榻B了基于“LangChain+LLM”框架快速搭建知識(shí)增強(qiáng)后的問(wèn)答機(jī)器人,并探討了提升模型內(nèi)容理解和執(zhí)行能力的潛在優(yōu)化方向。
本期內(nèi)容UCloud將為您解析參數(shù)高效微調(diào)技術(shù)(PEFT),即對(duì)已預(yù)訓(xùn)練好的模型,固定住其大部分參數(shù),而僅調(diào)整其中小部分或額外的參數(shù),以達(dá)到與全部參數(shù)微調(diào)相近的效果。
參數(shù)高效微調(diào)方法,可大致分為三個(gè)類別:增加式方法、選擇式方法和重新參數(shù)化式方法[1]。
1 增加式方法(Additive methods)
增加式方法通過(guò)增加額外的參數(shù)或?qū)觼?lái)擴(kuò)展現(xiàn)有的預(yù)訓(xùn)練模型,且僅訓(xùn)練新增加的參數(shù)。目前,這是PEFT方法中被應(yīng)用最廣泛的類別。
在增加式方法中,大致分為Adapter類方法和軟提示(Soft Prompts)。2019年1月至2022年3月期間,Adapter類的方法Adapter Tuning,軟提示類的方法Prefix Tuning、P-Tuning、Prompt Tuning、P-Tuning v2相繼出現(xiàn)。
1.1 Adapter Tuning[2]
Adapter的架構(gòu)如下:
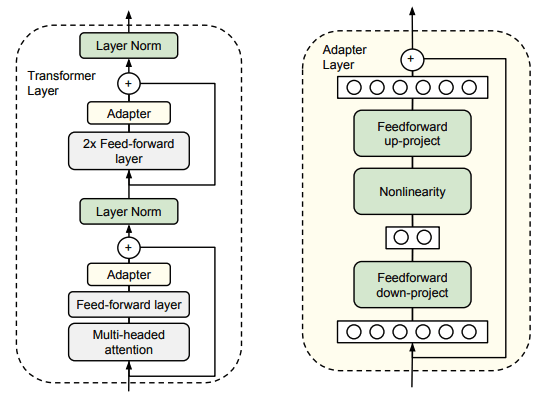
在每一個(gè)Transformer層中的每個(gè)子層之后插入兩個(gè)串行的Adapter。在Adapter微調(diào)期間,綠色層是根據(jù)下游數(shù)據(jù)進(jìn)行訓(xùn)練的,而預(yù)訓(xùn)練模型的原參數(shù)保持不變。
1.1.1 Adapter的特點(diǎn)
Adapter 模塊主要由兩個(gè)前饋(Feed-forward)子層組成。
1. 第一個(gè)前饋?zhàn)訉訉⒃继卣鞯木S度d投影到一個(gè)更小的維度m,應(yīng)用非線性函數(shù),再投影回維度d的特征(作為Adapter模塊的輸出)。
2. 總參數(shù)量為2md + d + m。通過(guò)設(shè)置m < d,我們限制了每個(gè)任務(wù)添加的參數(shù)數(shù)量。
3. 當(dāng)投影層的參數(shù)初始化接近零時(shí),根據(jù)一個(gè)skip-connection,將該模塊就初始化為近似恒等函數(shù),以確保微調(diào)的有效性。
1.1.2 Adapter的實(shí)驗(yàn)結(jié)果
使用公開(kāi)的預(yù)訓(xùn)練BERT作為基礎(chǔ)模型。Adapter微調(diào)具有高參數(shù)效率,可以生成性能強(qiáng)勁的緊湊模型,與完全微調(diào)相比表現(xiàn)相當(dāng)。Adapter通過(guò)使用原始模型0.5-5%大小的參數(shù)量來(lái)微調(diào),性能與BERT-LARGE上具有競(jìng)爭(zhēng)力的結(jié)果相差不到1%。
1.2 Soft Prompts
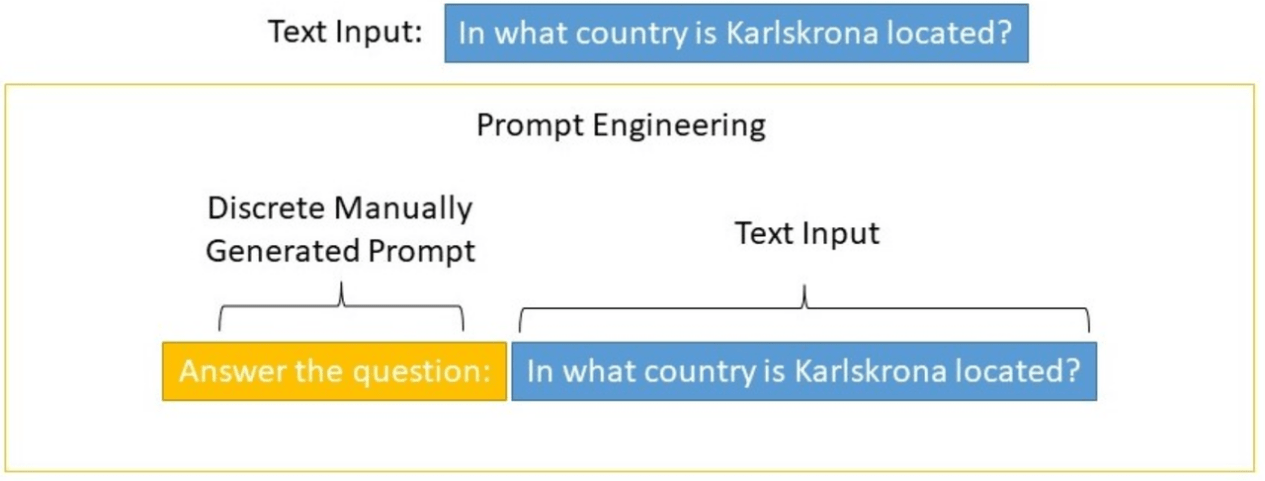
早期的提示微調(diào)通過(guò)修改輸入文本來(lái)控制語(yǔ)言模型的行為,稱為硬提示(Hard Prompts)微調(diào)。這些方法很難優(yōu)化,且受到最大模型輸入長(zhǎng)度的限制。下圖為離散的人工設(shè)計(jì)的Prompt示例:
比如改變輸入形式去詢問(wèn)模型:
軟提示(Soft Prompts)將離散的“提示”問(wèn)題轉(zhuǎn)為連續(xù)的“提示”問(wèn)題,通過(guò)過(guò)反向傳播和梯度下降更新參數(shù)來(lái)學(xué)習(xí)Prompts,而不是人工設(shè)計(jì)Prompts。有僅對(duì)輸入層進(jìn)行訓(xùn)練,也有對(duì)所有層進(jìn)行訓(xùn)練的類型。下面將介紹幾種熱門(mén)的Soft Prompts微調(diào)方法。
1.2.1 Prefix Tuning
其結(jié)構(gòu)如下:

只優(yōu)化前綴(紅色前綴塊),該前綴添加到每一個(gè)Transformer Block中。
1.2.1.1 Prefix Tuning的特點(diǎn)
1. 凍結(jié)預(yù)訓(xùn)練語(yǔ)言模型的參數(shù),為每個(gè)任務(wù)存儲(chǔ)特定的連續(xù)可微的前綴,節(jié)省空間。
2. 訓(xùn)練間增加MLP層以達(dá)到穩(wěn)定。
3. 對(duì)于不同模型構(gòu)造不同的Prefix。
1.2.1.2 Prefix Tuning的實(shí)驗(yàn)結(jié)果
對(duì)于表格到文本任務(wù),使用GPT-2MEDIUM和GPT-2LARGE模型。在表格到文本任務(wù)上,Prefix Tuning優(yōu)于Fine-Tuning(全量微調(diào))和Adapter-Tuning。對(duì)于摘要任務(wù),使用BART-LARGE模型。在摘要任務(wù)上,Prefix Tuning比全量微調(diào)弱。
1.2.2 P-Tuning
其結(jié)構(gòu)如下:
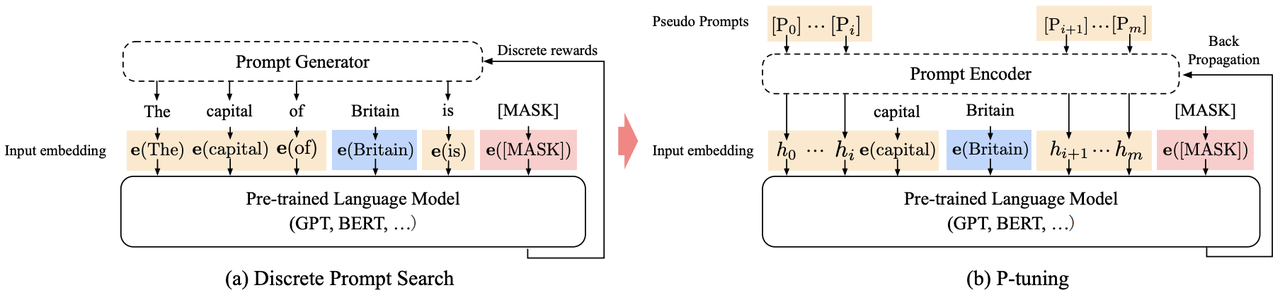

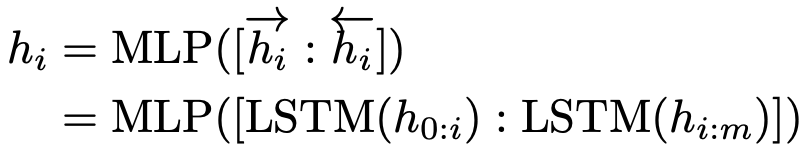
1.2.2.1 P-Tuning的特點(diǎn)
1. P-Tuning只在輸入層加入可微的Virtual Token,其會(huì)自動(dòng)插入到文本提示的離散Token嵌入中。
2. Virtual Token不一定作為前綴,其插入位置是可選的。
1.2.2.2 P-Tuning的實(shí)驗(yàn)結(jié)果
使用的是GPT系列和BERT系列的模型。P-Tuning與全參數(shù)效果相當(dāng),且在一些任務(wù)上優(yōu)于全參數(shù)微調(diào),可以顯著提高GPT模型在自然語(yǔ)言理解方面的性能,并且BERT風(fēng)格的模型也可以獲得較小的增益。
1.2.3 Prompt Tuning
其結(jié)構(gòu)如下:

上圖中,僅Virtual Token部分會(huì)由梯度下降法去更新參數(shù)。
1.2.3.1 Prompt Tuning的特點(diǎn)
1. 只在輸入層加入Prompt,并且不需要加入MLP進(jìn)行調(diào)整來(lái)解決難訓(xùn)練的問(wèn)題。
2. 提出了Prompt Ensembling,即通過(guò)在同一任務(wù)上訓(xùn)練N個(gè)提示,也就是在同一個(gè)批次中,對(duì)同一個(gè)問(wèn)題添加不同的Prompt,相當(dāng)于為任務(wù)創(chuàng)建了N個(gè)獨(dú)立的“模型”,同時(shí)仍然共享核心語(yǔ)言建模參數(shù)。
1.2.3.2 Prompt Tuning的實(shí)驗(yàn)結(jié)果
使用的是預(yù)訓(xùn)練的各種T5模型。在流行的SuperGLUE基準(zhǔn)測(cè)試中,Prompt Tuning的任務(wù)性能與傳統(tǒng)的模型調(diào)優(yōu)相當(dāng),且隨著模型規(guī)模的增加,差距逐漸減小。在零樣本領(lǐng)域遷移中,Prompt Tuning可以改善泛化性能。
1.2.4 P-Tuning v2
其結(jié)構(gòu)如下:
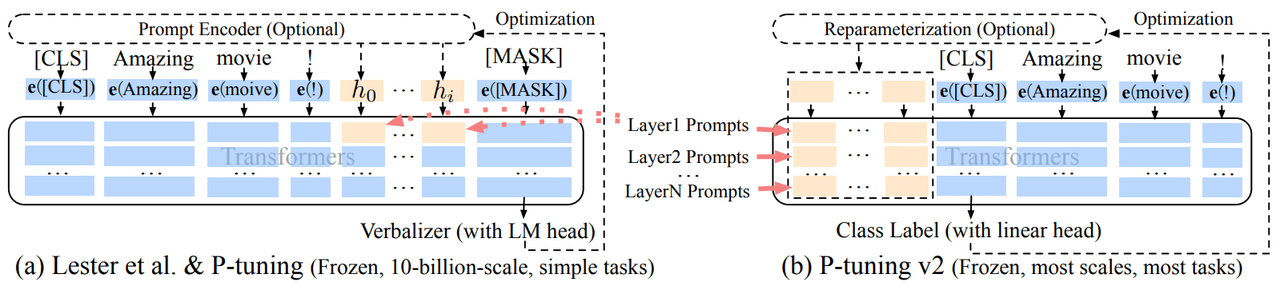

1.2.4.1 P-Tuning v2的特點(diǎn)
P-Tuning v2每一層的輸入都加入了Tokens,允許更高的任務(wù)容量同時(shí)保持參數(shù)效率;且添加到更深層的提示對(duì)模型的預(yù)測(cè)有更直接的影響。
1.2.4.2 P-Tuning v2的實(shí)驗(yàn)結(jié)果
使用的是BERT系列和GLM系列模型。P-Tuning v2是一種在不同規(guī)模和任務(wù)中都可與微調(diào)相媲美的提示方法。在NLU任務(wù)中,整體上P-Tuning v2與全量微調(diào)的性能相差很小。
2 選擇式方法
選擇性方法對(duì)模型的現(xiàn)有參數(shù)進(jìn)行微調(diào),可以根據(jù)層的深度、層類型或者甚至是個(gè)別參數(shù)進(jìn)行選擇。
2.1 BitFit
2022年9月5日,BitFit出現(xiàn),這是一種稀疏微調(diào)方法,僅修改模型的Bias(偏置項(xiàng))或其中的子集。
2.1.1 BitFit的特點(diǎn)
1. 凍結(jié)大部分Transformer編碼器的參數(shù),只訓(xùn)練偏置項(xiàng)和任務(wù)特定的分類層。
2. 優(yōu)化的偏置項(xiàng)參數(shù)包括Attention模塊中計(jì)算Query、Key、Value時(shí),計(jì)算MLP層時(shí),計(jì)算Layernormalization層時(shí)遇到的偏置項(xiàng)參數(shù)。
3. 每個(gè)新任務(wù)只需要存儲(chǔ)偏置項(xiàng)參數(shù)向量(占總參數(shù)數(shù)量的不到0.1%)和任務(wù)特定的最終線性分類器層。
2.1.2 BitFit的實(shí)驗(yàn)結(jié)果
使用公開(kāi)可用的預(yù)訓(xùn)練BERTBASE、BERTLARGE和RoBERTaBA模型。BitFit微調(diào)結(jié)果不及全量參數(shù)微調(diào),但在極少數(shù)參數(shù)可更新的情況下,遠(yuǎn)超F(xiàn)rozen(凍結(jié)模型參數(shù))方式。
3 重新參數(shù)化方法
基于重新參數(shù)化的高效微調(diào)方法利用低秩表示來(lái)最小化可訓(xùn)練參數(shù)的數(shù)量,其中包括2021年10月到2023年3月間出現(xiàn)的LoRA和AdaRoLA方法。
3.1 LoRA
該方法認(rèn)為模型權(quán)重矩陣在特定微調(diào)后具有較低的本征秩,故基于秩分解的概念,將預(yù)訓(xùn)練模型的現(xiàn)有權(quán)重矩陣分成兩個(gè)較小的矩陣。

3.1.1 LoRA的特點(diǎn)
1. 將矩陣乘積BA加到原模型參數(shù)矩陣W上可以避免推理延遲。
2. 可插拔的低秩分解矩陣模塊,方便切換到不同的任務(wù)。
3.1.2 LoRA的實(shí)驗(yàn)結(jié)果
使用的模型是RoBERTa、DeBERTa、GPT-2、GPT-3 175B。在多個(gè)數(shù)據(jù)集上,LoRA在性能上能和全量微調(diào)相近,且在某些任務(wù)上優(yōu)于全量微調(diào)。
3.2 AdaLoRA
3.2.1 AdaLoRA的特點(diǎn)
該方法基于權(quán)重矩陣的重要性而自適應(yīng)調(diào)整不同模塊的秩,節(jié)省計(jì)算量,可理解為L(zhǎng)oRA的升級(jí)版。
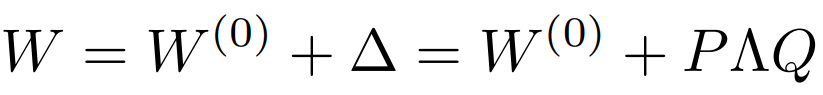
AdaLoRA的做法是讓模型學(xué)習(xí)SVD分解的近似。在損失函數(shù)中增加了懲罰項(xiàng),防止矩陣P和Q偏離正交性太遠(yuǎn),以實(shí)現(xiàn)穩(wěn)定訓(xùn)練。
3.2.2 AdaLoRA的實(shí)驗(yàn)結(jié)果
使用的模型是DeBERTaV3-base 和BART-large模型。AdaLoRA的性能通常高于參數(shù)量更高的方法。其中,AdaLoRA在0.32M微調(diào)參數(shù)時(shí),在CoLA數(shù)據(jù)集上達(dá)到了70.04的Mcc分?jǐn)?shù)。
4 參數(shù)微調(diào)方法小結(jié)
以上幾類參數(shù)高效微調(diào)方法,各有千秋。Adapter方法在預(yù)訓(xùn)練模型的層中插入可訓(xùn)練模塊的形式簡(jiǎn)單,但增加推理延時(shí)。Soft Prompts方法避免了人工“硬提示”的局限性,卻可能難收斂。
Soft Prompts方法中,Prefix Tuning率先提出可用梯度下降法優(yōu)化的的Tokens,而 P-Tuning、Prompt Tuning、P-Tuning v2相繼作出不同的改變,比如:
1. 加入的Tokens:P-Tuning僅限于輸入層,而Prefix-Tuning在每一層都加。
2. P-Tuning和Prompt Tuning僅將連續(xù)提示插入到輸入嵌入序列中,而Prefix Tuning的“軟提示”添加在每一個(gè)Transformer Block中。
3. Prompt Tuning不需要額外的MLP來(lái)解決難訓(xùn)練的問(wèn)題,P-Tuning v2移除了重參數(shù)化的編碼器。
BitFit方法只更新模型內(nèi)部偏置項(xiàng)參數(shù)所以訓(xùn)練參數(shù)量很微小,但整體效果比LoRA、Adapter等方法弱。LoRA方法不存在推理延時(shí),但無(wú)法動(dòng)態(tài)更新增量矩陣的秩,不過(guò)改進(jìn)版AdaLoRA解決了這個(gè)問(wèn)題。
5 AdaLoRA方法的實(shí)驗(yàn)
5.1 實(shí)驗(yàn)?zāi)P蜑镃hatGLM2-6B
官網(wǎng)代碼可去Hugging Face下載其模型文件。應(yīng)用AdaLoRA之后的模型訓(xùn)練參數(shù)僅占總參數(shù)的0.0468%。

5.2 實(shí)驗(yàn)數(shù)據(jù)為中文醫(yī)療問(wèn)答數(shù)據(jù)
包括兒科、外科等問(wèn)答數(shù)據(jù),數(shù)據(jù)中會(huì)有建議去醫(yī)院看病之類的文字。此處選取兒科和外科的數(shù)據(jù)分別10000條數(shù)據(jù)作為訓(xùn)練數(shù)據(jù)集,將文件保存為json格式。
5.2.1 構(gòu)造數(shù)據(jù)集
文件為dataset.py。

5.2.2 訓(xùn)練代碼
1. 文件為FT.py。

2. 配置文件config_accelerate.yml

3. 執(zhí)行文件run.sh

5.2.3 測(cè)試代碼

結(jié)果為:

6 結(jié)語(yǔ)
除了以上3大類方法之外,還有混合參數(shù)高效微調(diào)方法,其是綜合了多種PEFT類別思想的方法。比如MAM Adapter同時(shí)結(jié)合了Adapter和Prompt-Tuning的思想,UniPELT綜合了LoRA、Prefix Tuning和Adapter的思想。混合參數(shù)高效微調(diào)方法大概率優(yōu)于單個(gè)高效微調(diào)方法,但訓(xùn)練參數(shù)和推理延時(shí)的都增加了。下次將會(huì)對(duì)大模型的加速并行框架進(jìn)行探討,歡迎大家持續(xù)關(guān)注!
相關(guān)文章
[1]《Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning》
[2]《Parameter-Efficient Transfer Learning for NLP》
[3]《Prefix-Tuning: Optimizing Continuous Prompts for Generation》
[4]《GPT Understands, Too》
[5]《The Power of Scale for Parameter-Efficient Prompt Tuning》
[6]《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》
[7]《BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models》
[8]《LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS》
[9]《ADAPTIVE BUDGET ALLOCATION FOR PARAMETEREFFICIENT FINE-TUNING》





