
近日,國際權威IT研究咨詢機構Gartner發布《Hype Cycle for Data, Analytics and AI in China, 2023》報告。安恒信息作為數據安全領域的領軍企業之一,致力于數據分類分級,連續兩年被Gartner報告列為“數據分類分級領域”領跑廠商。
數據分類分級的必要性
據IBM《2022 年數據泄露成本報告》揭示,全球平均單一事件數據泄露成本高達435萬美元,數據安全問題已經嚴重制約業務數字化轉型的進程。而通過對數據開展分類分級,將分類分級后的結果應用于數據全生命周期安全防護,我們可以有效保障數字安全,滿足業務數字化轉型的安全需要。
Gartner報告指出,數據分類分級有助于高效地對數據進行分級治理,在涉及價值、訪問、隱私、存儲、道德、質量和保留的數據安全項目中起到了重要的作用。中國的數據安全監管要求使數據分類分級成為安全、數據治理和合規計劃中至關重要的一步。數據分類分級有助于組織區分數據的敏感性,并提高數據保護控制的有效性。
AI讓數據分類分級更簡單
面對各行各業的客戶,根據各自體量大小,其不同業務系統的總字段數,少則上萬個,多則幾十萬上百萬個。人工梳理的效率為平均1000字段/天左右,如果客戶總字段數以10W來計算,大約需要100人天才能做完。面對這耗時耗力的分類分級工作,如何才能提升效率呢?經過上百個項目實施的探索,我們給出的答案是,將AI人工智能整合進分類分級的工作中。安恒信息AiSort數據分類分級產品主打“AI讓數據分類分級更簡單”,內置了NLP、聚類、強化學習等AI模型。通過對數據的分級分類,可更清晰地了解敏感數據的分布情況,更有針對性地建立覆蓋數據全生命周期的安全防護。
靈活的NLP模型
背景:相同行業的數據有80%左右的重合度。
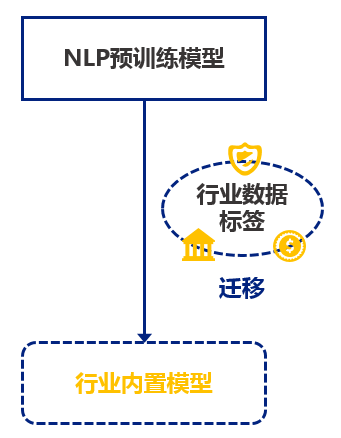
特性:高重合度的特性體現在字段內容、字段名稱和字段注釋等多個維度上。針對不同行業的數據特性,結合項目實踐通過遷移學習將預訓練模型做到行業適配,訓練不同行業(如政府、金融、運營商、教育和醫療等)的NLP模型并內置到產品中,提升首次機器分類分級效果。
高效的聚類模型
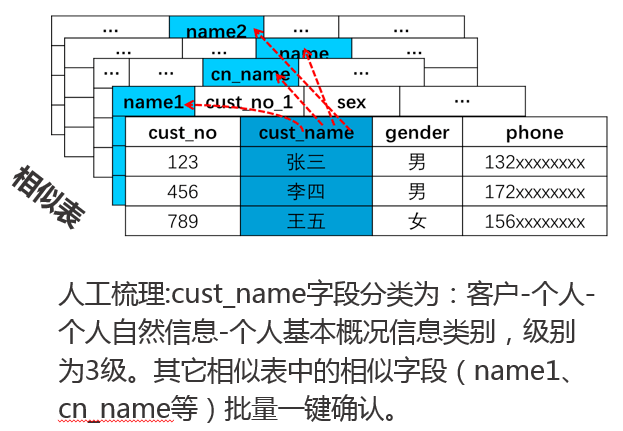
背景:同一系統中70%的字段都能找和其重復或者相似的字段。
特性:采用無監督的聚類算法,將相似字段/表聚合在一起實現信息整合;在梳理向導功能的輔助下,用戶僅需修改其中一項的分類分級信息,即可批量自動覆蓋其他相似字段/表的結果,提升人工梳理效率。聚類算法在AiSort的版本迭代中持續優化,聚焦于提供更具實際業務描述能力的信息整合手段,讓梳理人員在盡可能短的時間內準確判斷當前字段的實際分類和實際分級。
可反饋的強化學習模型
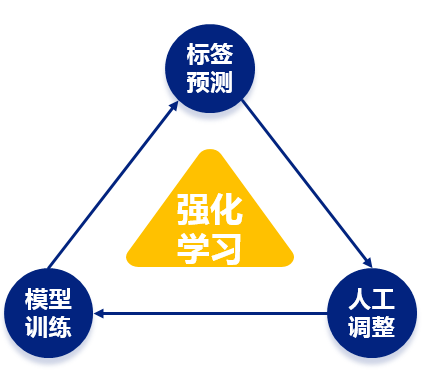
背景:分類分級不是一次性的動作,在實踐中往往需要利用機器進行反復學習重新打標。
特性:針對新行業新客戶及其業務系統,可僅對一部分數據進行分類分級梳理,就能訓練出適用該客戶的模型。然后可使用該模型對剩余數據進行分類分級。在模型預測分類分級標簽過程中,人可以參與對結果核驗及糾正(對多個模型版本進行獎懲),快速提升模型效果。
數字化是未來產業發展的關鍵,數據要素是數字經濟深入發展的核心引擎。安恒信息將依托自身在數據安全方面的多年經驗,大力推進數據分類分級的探索與實踐,以期讓數據要素充分自由流通,發揮數據價值,促進數字經濟發展,為建設數字中國提供優質服務。
參考文獻:
Gartner, Hype Cycle for Data, Analytics and AI in China, 2023,Julian Sun, Ben Yan, Xingyu Gu, Fay Fei, Mike Fang, Tong Zhang,Published 17 July 2023
免責聲明:Gartner未在其報告中支持任何廠商、產品或服務,也并不建議技術用戶只選擇有最高評分或其它特征的廠商。Gartner研究出版物代表的是Gartner研究機構的意見,不應解釋為對事實的陳述。Gartner對與本研究有關的所有明示或暗示的保證概不負責,包括對適銷性或特定用途的適用性的任何保證。





