
大模型的幻覺問題,又有新的解決方法了!
Meta AI實驗室提出了一種“分而治之”的解決方案。
有了這個方案,Llama-65B輸出的信息準確率提升了一倍,甚至超過了ChatGPT。
所謂大模型幻覺,就是輸出一些看似合理但完全不對的內容。
Meta此次提出的“驗證鏈”(CoVe),是與“思維鏈”(CoT)相似的一種鏈式方法。
區(qū)別在于,“step-by-step”的思維鏈更關注邏輯推理,而驗證鏈更注重事實信息。
有網(wǎng)友看了之后發(fā)現(xiàn),這個驗證鏈很像是自己用ChatGPT寫代碼時的一種科學方法:
那么“驗證鏈”究竟是個什么方法,“驗證”的又是什么呢?
拆解答案,分而治之
驗證鏈的核心思想,是把要驗證的一大段內容,拆解成一個個小的問題,具體流程是這樣的:
首先,模型會根據(jù)用戶提出的問題照常生成回復。
接著,根據(jù)生成的回復內容,針對其中的各項信息,生成一系列的驗證問題。
然后讓模型自行回答其所提出的這些問題,并根據(jù)結果對初始答案進行調整,得到最終結果。
舉個簡單的例子,假如想詢問模型19世紀美墨戰(zhàn)爭的主要原因是什么。
模型回答了事件發(fā)生的時間,以及在這之前都發(fā)生了什么事。
之后針對這一系列事件,逐一詢問它們是什么時候發(fā)生的。
于是,模型發(fā)現(xiàn)自己提到的一項內容時間相差太遠,調整后給出了最終的答案。

其中,問題的生成和驗證是最關鍵的一環(huán),對此,研究人員一共提出了四種具體的方式:
- Joint,即將生成問題和回答的指令寫入同一段提示詞
- 2-Step,即先讓模型生成提問,然后開啟新的對話(一次性)回答提出的問題
- Factored,在2-Step的基礎上,對提出的每一個問題分別開啟新對話
- Factor+Revise,在Factored的基礎之上加入一致性檢驗,讓模型重點關注前后不一致的內容
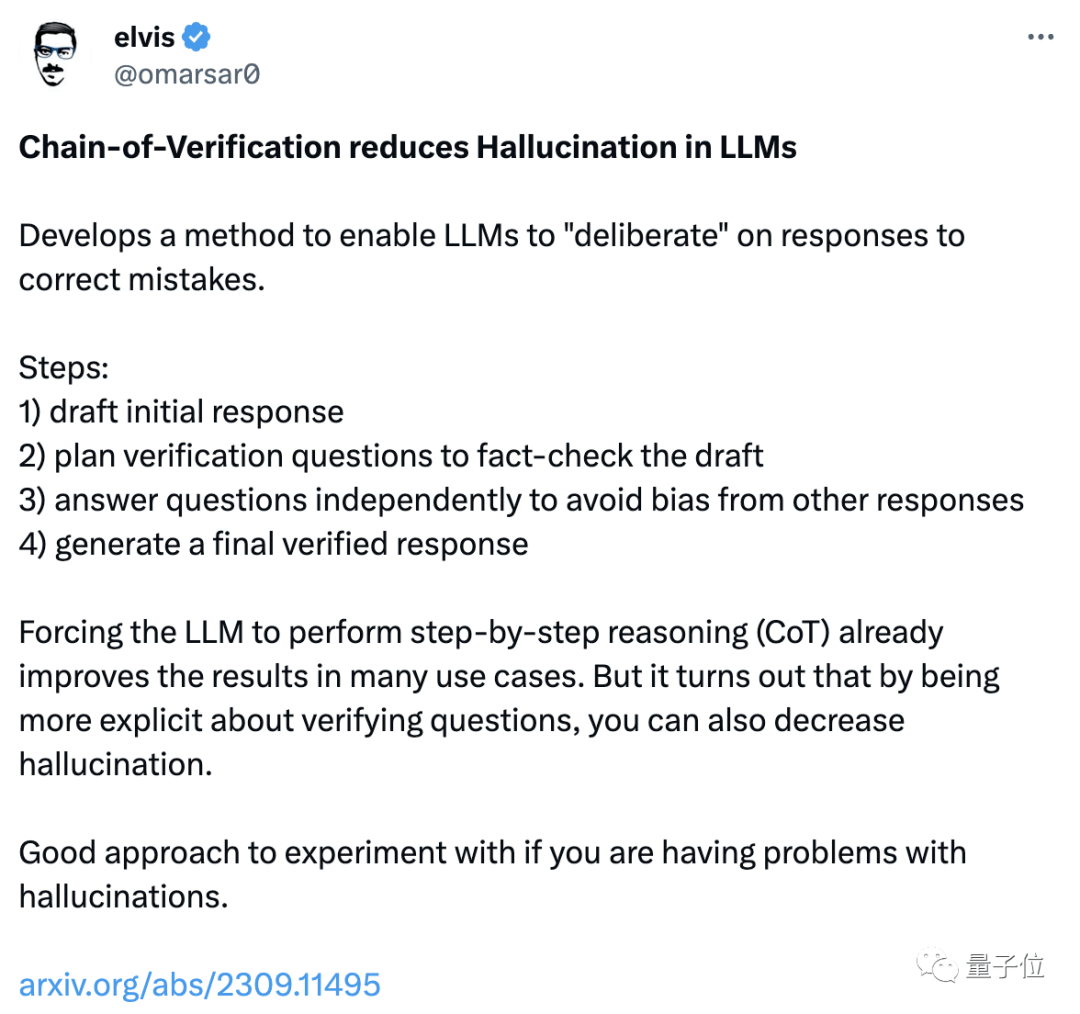
這四種模式越來越細化,準確率也是越來越高。
△從紅色開始,四種顏色依次代表無CoVe、Joint、Factored和Factor+Revise
那么為什么拆分提問就能提高模型的準確性呢?
首先是因為拆解后的問題比整體任務更容易,論述題變成了問答甚至選擇、判斷題,問題簡單了,準確率也就提升了。
此外,把問題分解可以讓模型真正重新思考,而不是反復地重復錯誤答案。
那么,驗證鏈方式的效果究竟如何呢?
信息準確率超過ChatGPT
為了探究這一問題,研究人員用Llama進行了測試,測試任務一共有三項。
首先是信息列舉,比如列舉出出生于某地、從事某行業(yè)的名人。
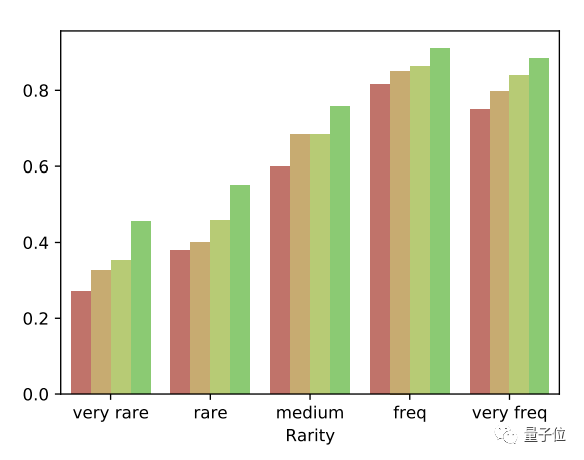
這項任務中,研究人員一共測試了兩個數(shù)據(jù)集——簡單一些的Wikidata和從難一些的Wiki-Category list(從維基百科中提取)。
結果發(fā)現(xiàn),65B參數(shù)的Llama,在two-step模式的驗證鏈加持下,簡單問題的準確度從0.17提升到了0.36,增加了一倍還多,復雜問題準確度也接近翻番。
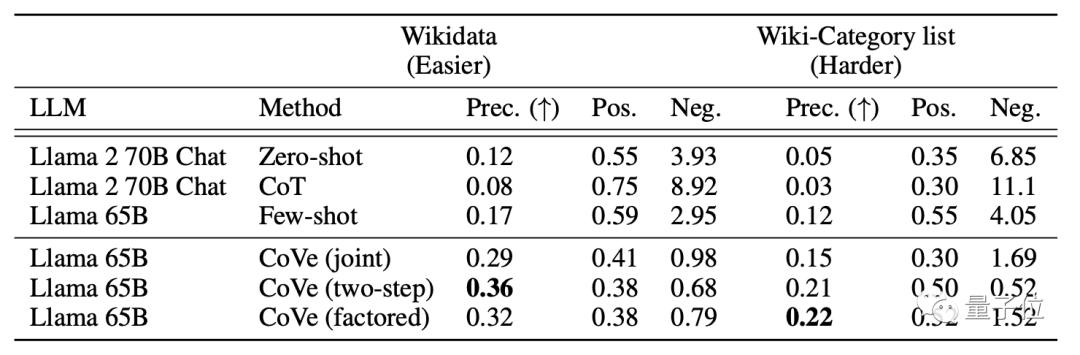
接下來是“閉域問答”題,研究人員從MultiSpanQA數(shù)據(jù)集中抽取多個不連續(xù)信息進行挖空提問。
比如“誰在哪一年創(chuàng)建了世界上第一家出版社”(答案是Johannes Gutenberg, 1450)。
結果,Cove也為Llama帶來了20%左右的準確度提升。
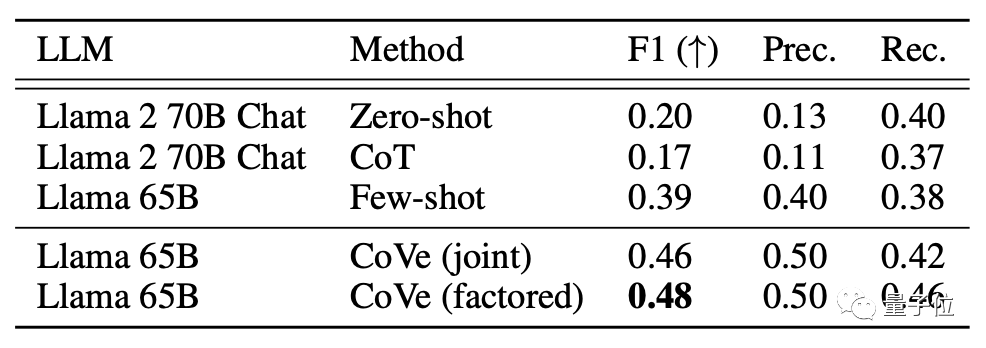
第三項任務是“長段文本傳記生成”,問題就是“Tell me a bio of (人名)”,使用FactScore數(shù)據(jù)集進行評價。
結果在Factor+Reviese模式下,準確率不僅比無驗證鏈模式大幅提高,還超過了ChatGPT。

對這項研究感興趣的朋友,可以到論文中了解更多細節(jié)。
論文地址:
https://arxiv.org/abs/2309.11495





