
在開發(fā)機器人學(xué)習(xí)方法時,如果能整合大型多樣化數(shù)據(jù)集,再組合使用強大的富有表現(xiàn)力的模型(如 Transformer),那么就有望開發(fā)出具備泛化能力且廣泛適用的策略,從而讓機器人能學(xué)會很好地處理各種不同的任務(wù)。比如說,這些策略可讓機器人遵從自然語言指令,執(zhí)行多階段行為,適應(yīng)各種不同環(huán)境和目標(biāo),甚至適用于不同的機器人形態(tài)。
但是,近期在機器人學(xué)習(xí)領(lǐng)域出現(xiàn)的強大模型都是使用監(jiān)督學(xué)習(xí)方法訓(xùn)練得到的。因此,所得策略的性能表現(xiàn)受限于人類演示者提供高質(zhì)量演示數(shù)據(jù)的程度。這種限制的原因有二。
- 第一,我們希望機器人系統(tǒng)能比人類遠(yuǎn)程操作者更加熟練,利用硬件的全部潛力來快速、流暢和可靠地完成任務(wù)。
- 第二,我們希望機器人系統(tǒng)能更擅長自動積累經(jīng)驗,而不是完全依賴高質(zhì)量的演示。
從原理上看,強化學(xué)習(xí)能同時提供這兩種能力。
近期出現(xiàn)了一些頗具潛力的進(jìn)步,它們表明大規(guī)模機器人強化學(xué)習(xí)能在多種應(yīng)用設(shè)置中取得成功,比如機器人抓取和堆疊、學(xué)習(xí)具有人類指定獎勵的異構(gòu)任務(wù)、學(xué)習(xí)多任務(wù)策略、學(xué)習(xí)以目標(biāo)為條件的策略、機器人導(dǎo)航。但是,研究表明,如果使用強化學(xué)習(xí)來訓(xùn)練 Transformer 等能力強大的模型,則更難大規(guī)模地有效實例化。
近日,google DeepMind 提出了 Q-Transformer,目標(biāo)是將基于多樣化真實世界數(shù)據(jù)集的大規(guī)模機器人學(xué)習(xí)與基于強大 Transformer 的現(xiàn)代策略架構(gòu)結(jié)合起來。

- 論文:https://q-transformer.Github.io/assets/q-transformer.pdf
- 項目:https://q-transformer.github.io/
雖然,從原理上看,直接用 Transformer 替代現(xiàn)有架構(gòu)(Re.NETs 或更小的卷積神經(jīng)網(wǎng)絡(luò))在概念上很簡單,但要設(shè)計一種能有效利用這一架構(gòu)的方案卻非常困難。只有能使用大規(guī)模的多樣化數(shù)據(jù)集時,大模型才能發(fā)揮效力 —— 小規(guī)模的范圍狹窄的模型無需這樣的能力,也不能從中受益。
盡管之前有研究通過仿真數(shù)據(jù)來創(chuàng)建這樣的數(shù)據(jù)集,但最有代表性的數(shù)據(jù)還是來自真實世界。
因此,DeepMind 表示,這項研究關(guān)注的重點是通過離線強化學(xué)習(xí)使用 Transformer 并整合之前收集的大型數(shù)據(jù)集。
離線強化學(xué)習(xí)方法是使用之前已有的數(shù)據(jù)訓(xùn)練,目標(biāo)是根據(jù)給定數(shù)據(jù)集推導(dǎo)出最有效的可能策略。當(dāng)然,也可以使用額外自動收集的數(shù)據(jù)來增強這個數(shù)據(jù)集,但訓(xùn)練過程是與數(shù)據(jù)收集過程是分開的,這能為大規(guī)模機器人應(yīng)用提供一個額外的工作流程。
在使用 Transformer 模型來實現(xiàn)強化學(xué)習(xí)方面,另一大問題是設(shè)計一個可以有效訓(xùn)練這種模型的強化學(xué)習(xí)系統(tǒng)。有效的離線強化學(xué)習(xí)方法通常是通過時間差更新來進(jìn)行 Q 函數(shù)估計。由于 Transformer 建模的是離散的 token 序列,所以可以將 Q 函數(shù)估計問題轉(zhuǎn)換成一個離散 token 序列建模問題,并為序列中的每個 token 設(shè)計一個合適的損失函數(shù)。
最簡單樸素的對動作空間離散化的方法會導(dǎo)致動作基數(shù)呈指數(shù)爆炸,因此 DeepMind 采用的方法是按維度離散化方案,即動作空間的每個維度都被視為強化學(xué)習(xí)的一個獨立的時間步驟。離散化中不同的 bin 對應(yīng)于不同的動作。這種按維度離散化的方案讓我們可以使用帶有一個保守的正則化器簡單離散動作 Q 學(xué)習(xí)方法來處理分布轉(zhuǎn)變情況。
DeepMind 提出了一種專門的正則化器,其能最小化數(shù)據(jù)集中每個未被取用動作的值。研究表明:該方法既能學(xué)習(xí)范圍狹窄的類似演示的數(shù)據(jù),也能學(xué)習(xí)帶有探索噪聲的范圍更廣的數(shù)據(jù)。
最后,他們還采用了一種混合更新機制,其將蒙特卡洛和 n 步返回與時間差備份(temporal difference backups)組合到了一起。結(jié)果表明這種做法能提升基于 Transformer 的離線強化學(xué)習(xí)方法在大規(guī)模機器人學(xué)習(xí)問題上的表現(xiàn)。
總結(jié)起來,這項研究的主要貢獻(xiàn)是 Q-Transformer,這是一種用于機器人離線強化學(xué)習(xí)的基于 Transformer 的架構(gòu),其對 Q 值使用了按維度的 token 化,并且已經(jīng)可以用于大規(guī)模多樣化機器人數(shù)據(jù)集,包括真實世界數(shù)據(jù)。圖 1 總結(jié)了 Q-Transformer 的組件。
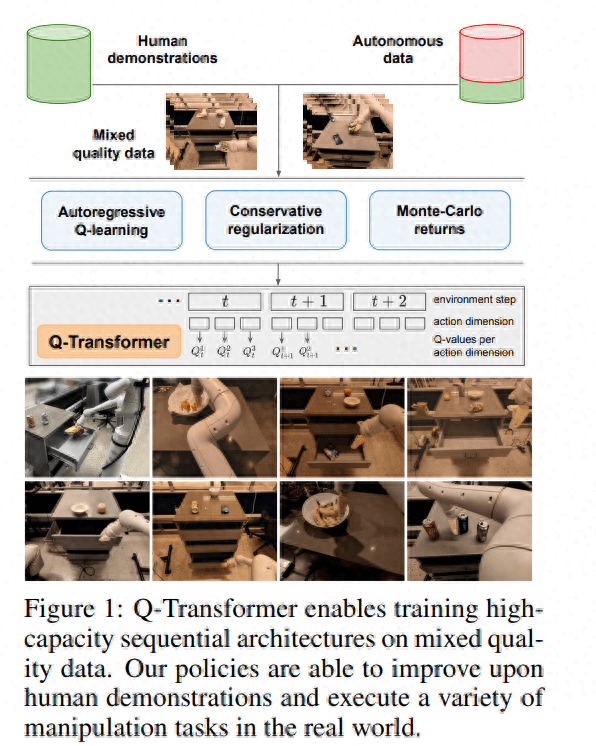
DeepMind 也進(jìn)行了實驗評估 —— 既有用于嚴(yán)格比較的仿真實驗,也有用于實際驗證的大規(guī)模真實世界實驗;其中學(xué)習(xí)了大規(guī)模的基于文本的多任務(wù)策略,結(jié)果驗證了 Q-Transformer 的有效性。
在真實世界實驗中,他們使用的數(shù)據(jù)集包含 3.8 萬個成功演示和 2 萬個失敗的自動收集的場景,這些數(shù)據(jù)是通過 13 臺機器人在 700 多個任務(wù)上收集的。Q-Transformer 的表現(xiàn)優(yōu)于之前提出的用于大規(guī)模機器人強化學(xué)習(xí)的架構(gòu),以及之前提出的 Decision Transformer 等基于 Transformer 的模型。
方法概覽
為了使用 Transformer 來執(zhí)行 Q 學(xué)習(xí),DeepMind 的做法是應(yīng)用動作空間的離散化和自回歸。
要學(xué)習(xí)一個使用 TD 學(xué)習(xí)的 Q 函數(shù),經(jīng)典方法基于貝爾曼更新規(guī)則:
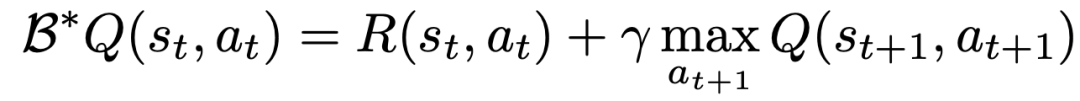
研究者對貝爾曼更新進(jìn)行了修改,使之能為每個動作維度執(zhí)行,做法是將問題的原始 MDP 轉(zhuǎn)換成每個動作維度都被視為 Q 學(xué)習(xí)的一個步驟的 MDP。
具體來說,給定動作維度 d_A,新的貝爾曼更新規(guī)則為:
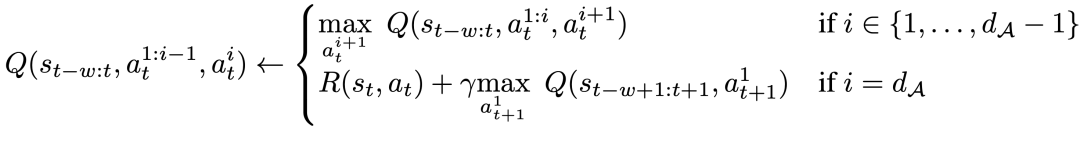
這意味著對于每個中間動作維度,要在給定相同狀態(tài)的情況下最大化下一個動作維度,而對于最后一個動作維度,使用下一狀態(tài)的第一個動作維度。這種分解能確保貝爾曼更新中的最大化依然易于處理,同時還能確保原始 MDP 問題仍可得到解決。
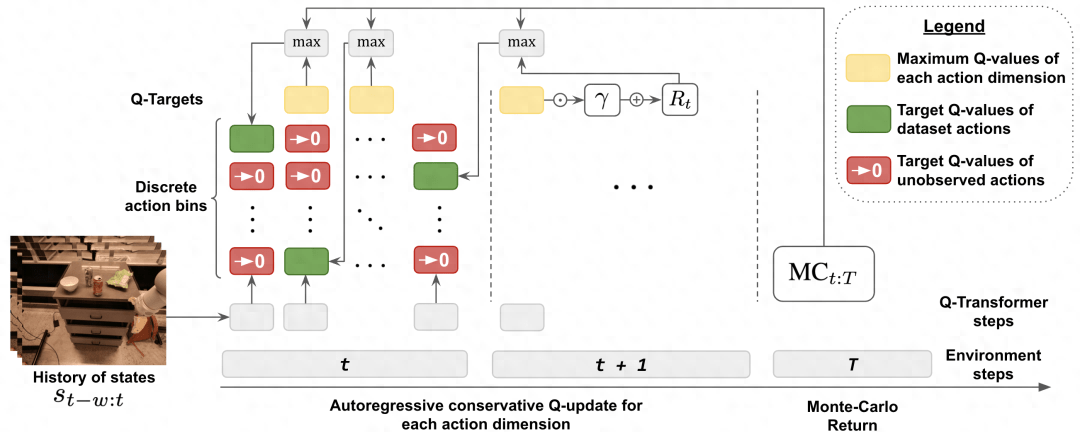
為了兼顧離線學(xué)習(xí)過程中的分布變化情況,DeepMind 還引入了一種簡單的正則化技術(shù),其是將未曾見過的動作的值降到最低。
為了加快學(xué)習(xí)速度,他們還使用了蒙特卡洛返回。其使用了對于給定事件片段(episode)的返回即用(return-to-go),也使用了可跳過按維度最大化的 n 步返回(n-step returns)。
實驗結(jié)果
實驗中,DeepMind 在一系列真實世界任務(wù)上評估了 Q-Transformer,同時還將每個任務(wù)的數(shù)據(jù)限制到僅包含 100 個人類演示。
除了演示之外,他們還添加了自動收集的失敗事件片段,從而得到了一個數(shù)據(jù)集,其中包含來自演示的 3.8 萬個正例和 2 萬個自動收集的負(fù)例。
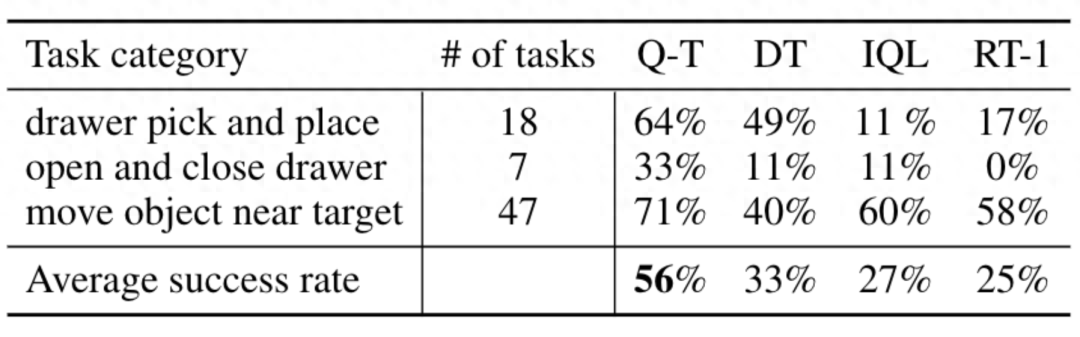

相比于 RT-1、IQL 和 Decision Transformer (DT) 等基準(zhǔn)方法,Q-Transformer 可以有效地利用自動事件片段來顯著提升其使用技能的能力,這些技能包括從抽屜里取放物品、將物體移動到目標(biāo)附近、開關(guān)抽屜。
研究者還在一個高難度的模擬取物任務(wù)上對新提出的方法進(jìn)行了測試 —— 在該任務(wù)中,僅有約 8% 的數(shù)據(jù)是正例,其余的都是充滿噪聲的負(fù)例。
在這個任務(wù)上,QT-Opt、IQL、AW-Opt 和 Q-Transformer 等 Q 學(xué)習(xí)方法的表現(xiàn)通常更好,因為它們可以通過動態(tài)程序規(guī)劃利用負(fù)例來學(xué)習(xí)策略。
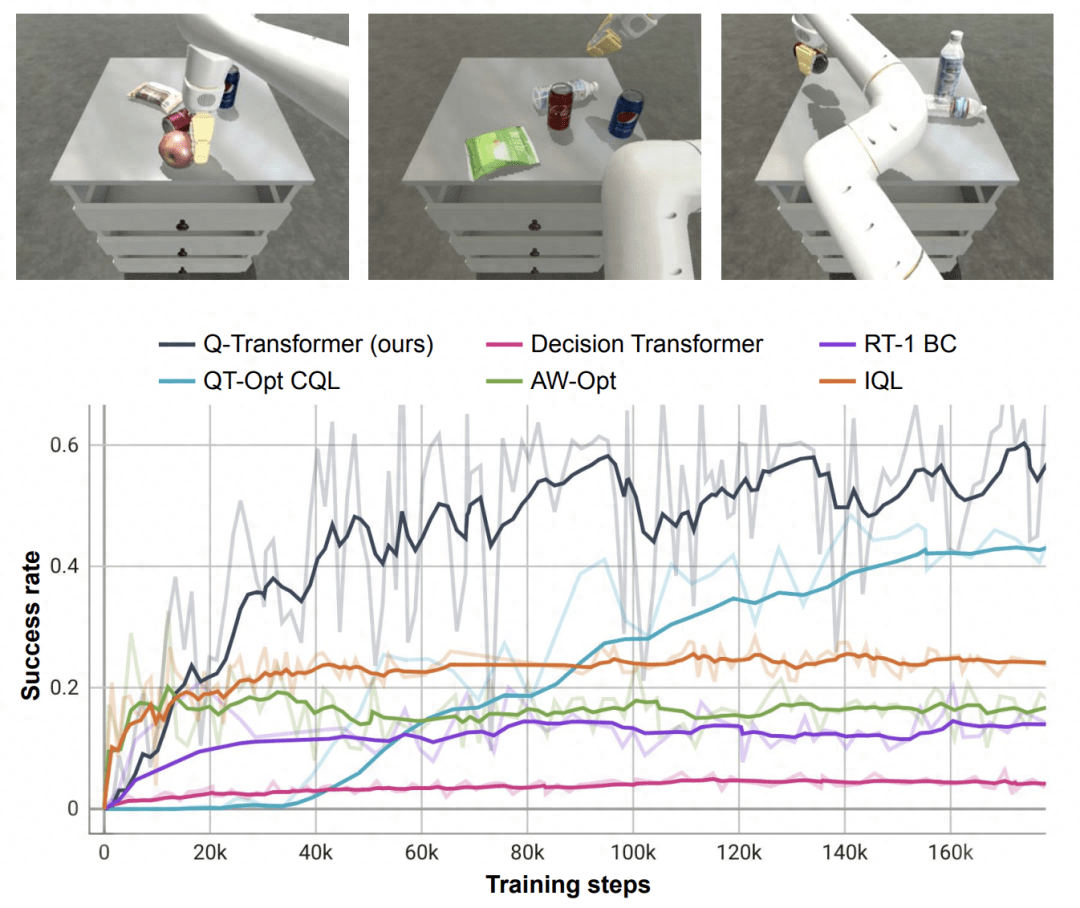
基于這個取物任務(wù),研究者進(jìn)行了消融實驗,結(jié)果發(fā)現(xiàn)保守的正則化器和 MC 返回都對保持性能很重要。如果切換成 Softmax 正則化器,性能表現(xiàn)顯著更差,因為這會將策略過于限制在數(shù)據(jù)分布中。這說明 DeepMind 這里選擇的正則化器能更好地應(yīng)對這個任務(wù)。
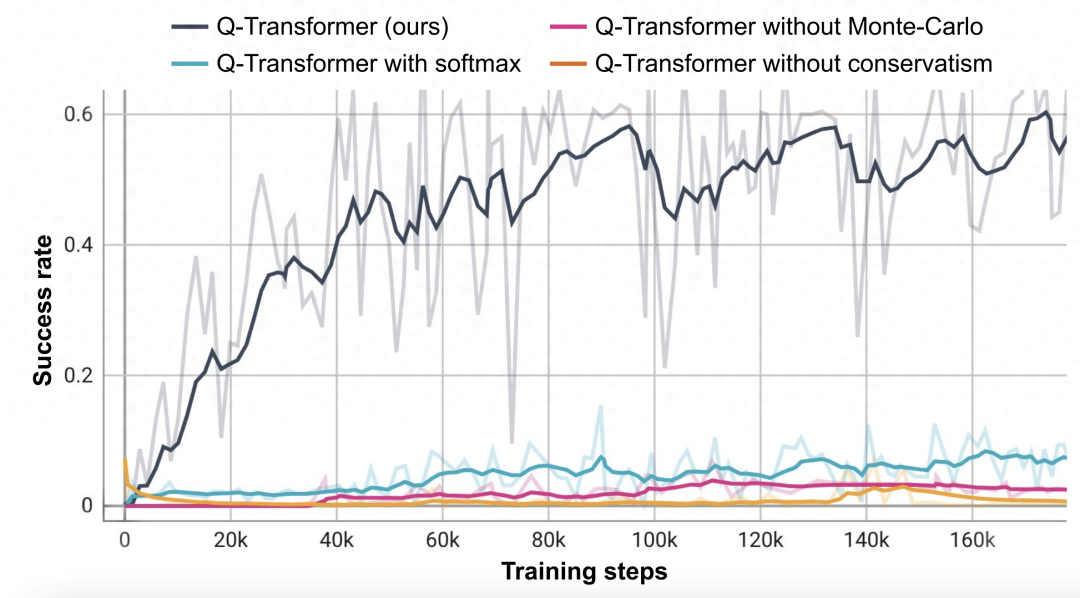
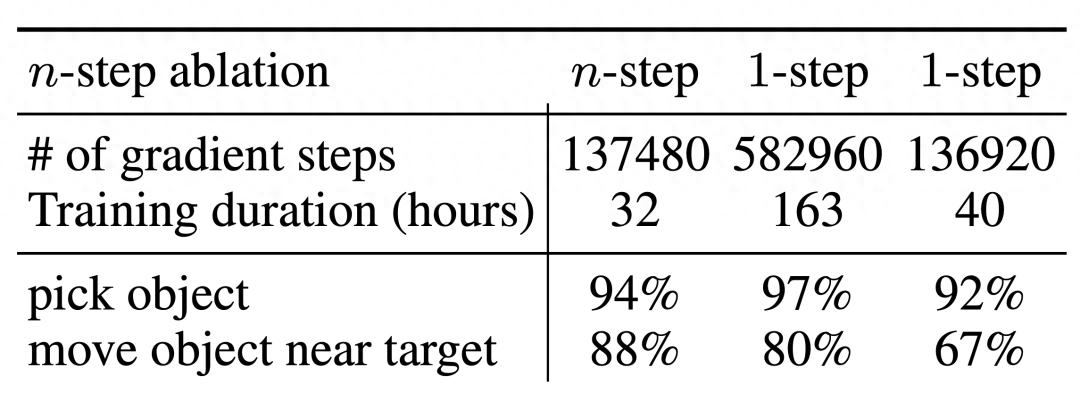
而他們對 n 步返回的消融實驗則發(fā)現(xiàn),盡管這會引入偏差,但這種方法卻有助于在顯著更少的梯度步驟內(nèi)實現(xiàn)同等的高性能,能高效地處理許多問題。
研究者也嘗試了在更大規(guī)模的數(shù)據(jù)集上運行 Q-Transformer—— 他們將正例的數(shù)量擴(kuò)增至 11.5 萬,負(fù)例的數(shù)量增至 18.5 萬,得到了一個包含 30 萬個事件片段的數(shù)據(jù)集。使用這個大型數(shù)據(jù)集,Q-Transformer 依然有能力學(xué)習(xí),甚至能比 RT-1 BC 基準(zhǔn)表現(xiàn)更好。

最后,他們把 Q-Transformer 訓(xùn)練的 Q 函數(shù)用作可供性模型(affordance model),再與語言規(guī)劃器組合到一起,類似于 SayCan。

Q-Transformer 可供性估計的效果由于之前的使用 QT-Opt 訓(xùn)練的 Q 函數(shù);如果再將未被采樣的任務(wù)重新標(biāo)注為訓(xùn)練期間當(dāng)前任務(wù)的負(fù)例,效果還能更好。由于 Q-Transformer 不需要 QT-Opt 訓(xùn)練使用的模擬到真實(sim-to-real)訓(xùn)練,因此如果缺乏合適的模擬,那么使用 Q-Transformer 會更容易。
為了測試完整的「規(guī)劃 + 執(zhí)行」系統(tǒng),他們實驗了使用 Q-Transformer 同時進(jìn)行可供性估計和實際策略執(zhí)行,結(jié)果表明它優(yōu)于之前的 QT-Opt 和 RT-1 組合。
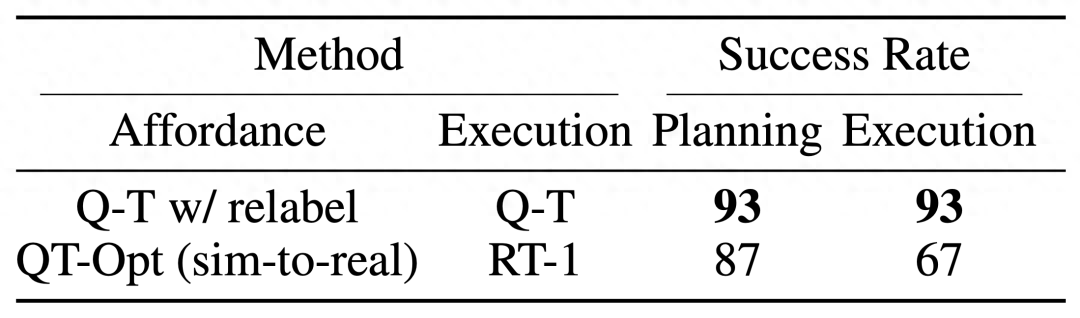
從給定圖像的任務(wù)可供性值示例中可以看出,針對下游的「規(guī)劃 + 執(zhí)行」框架,Q-Transformer 可提供高質(zhì)量的可供性值。
更多詳細(xì)內(nèi)容,請閱讀原文。





