
本文介紹了redis緩存原理、詳細(xì)解析了緩存模型、緩存一致性和緩存異常場景。
盡管(關(guān)系型)數(shù)據(jù)庫系統(tǒng) (SQL) 帶來了許多出色的屬性,例如 ACID,但為了保持這些屬性,數(shù)據(jù)庫的性能在“ 3 高” 條件環(huán)境下下往往顯得捉襟見肘、蒼白無力 。
為了解決這個問題,我們往往需要在應(yīng)用層(即處理業(yè)務(wù)邏輯的后端代碼)和存儲層(即 SQL 數(shù)據(jù)庫)之間增加一個緩存層。該緩存層通常使用內(nèi)存緩存來實現(xiàn),畢竟,傳統(tǒng) SQL 數(shù)據(jù)庫的性能瓶頸通常發(fā)生在二級存儲(即硬盤)的 I/O 層面。隨著主內(nèi)存 (RAM) 的價格在過去十年中下降,故將(至少部分)數(shù)據(jù)存儲在主內(nèi)存中以提高性能便是一種性價比較高的解決方案。基于當(dāng)前的技術(shù)發(fā)展現(xiàn)狀,Redis 便成為當(dāng)下一種較為流行的選擇。
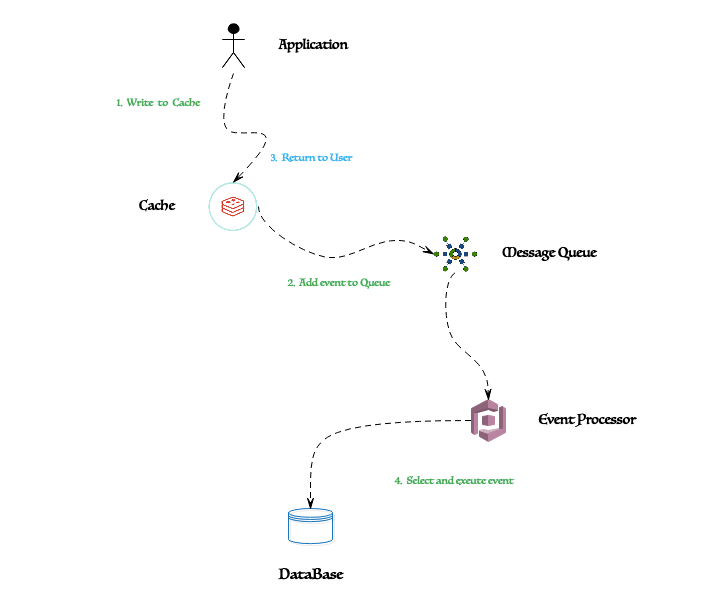
當(dāng)然,大多數(shù)系統(tǒng)只將所謂的“熱數(shù)據(jù)”存儲在緩存層(即主內(nèi)存)中。基于帕累托原理(也稱為 80/20 法則),對于大多數(shù)事件,大約 80% 的影響來自 20% 的原因。為了節(jié)省成本,我們只需要將這 20% 存儲在緩存層中。為了識別“熱數(shù)據(jù)”,我們可以指定驅(qū)逐策略(例如 LFU 或 LRU )來確定哪些數(shù)據(jù)將過期。
緩存概述
緩存是一種“預(yù)熱”技術(shù),用于將經(jīng)常訪問的數(shù)據(jù)存儲在臨時存儲器(稱為緩存)中,以減少硬盤驅(qū)動器的讀/寫。緩存無處不在,基于此技術(shù)可以大大地提高 Web 應(yīng)用程序的性能。
通常,在最初的單體架構(gòu)模型,當(dāng)用戶向我們的服務(wù)發(fā)送一個消息請求時,Web 服務(wù)器首先會讀取或?qū)懭霐?shù)據(jù)庫再返回響應(yīng)。在緩存的情況下,服務(wù)器首先檢查緩存副本是否存在,如果存在則從緩存返回數(shù)據(jù)而不是詢問數(shù)據(jù)庫。它節(jié)省了時間和數(shù)據(jù)庫的計算工作量。
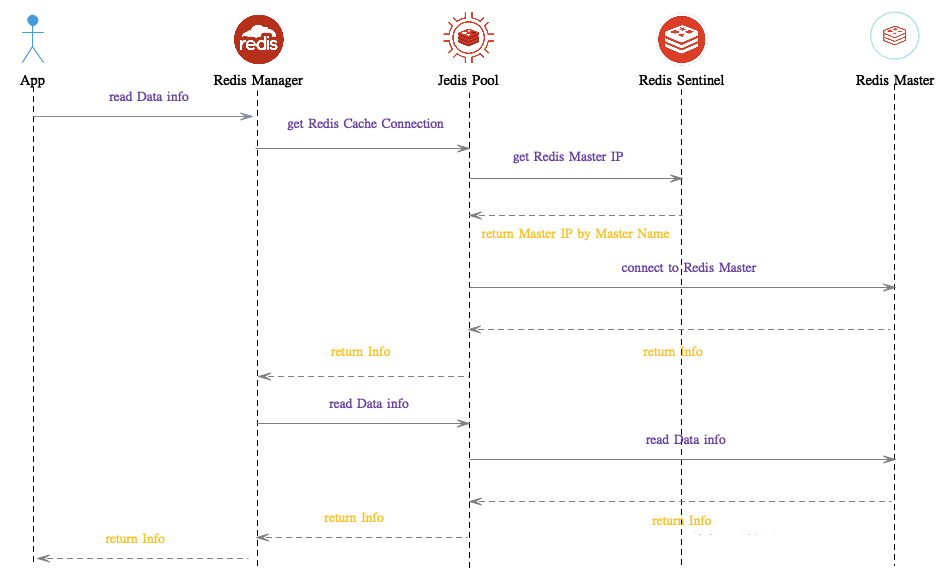
下面簡要介紹一下應(yīng)用程序如何請求 Redis ,此處主要基于 Master-Slave-Sentinel 模式的集群,App 通過調(diào)用 Redis Client ,例如,Jedis、Lettuce 及 Redisson 等來與 Redis Sentinel 通信,當(dāng) Redis Master 切換至 Slave 時,Application 依舊能夠正常工作,如下為詳細(xì)的時序圖:
緩存模型
在分布式系統(tǒng)中,基于 CAP 定理指導(dǎo),根據(jù)業(yè)務(wù)需求和上下文選擇這些策略,通常可將其劃分為常規(guī)模式和 Cache-Aside 模式。在開始之前,讓我們通過刷新緩存的方式來了解常用的緩存模式,具體如下所 示:
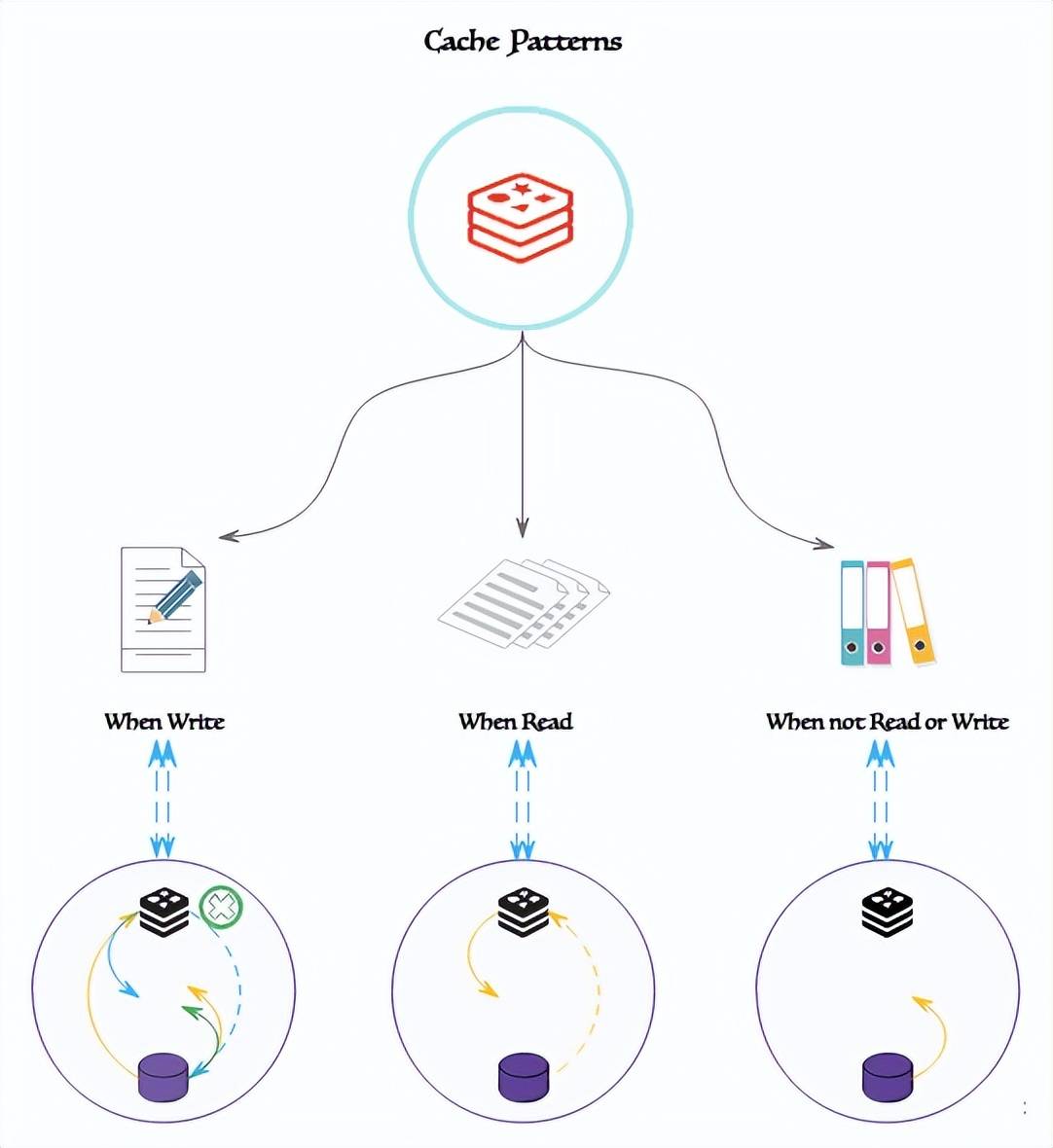
寫模型
1、Write Through:即“直寫”。此模型為同步寫入數(shù)據(jù)庫后再緩存。這是安全的,因為它首先寫入數(shù)據(jù)庫,但比后寫慢。與寫無效相比,它為先寫后讀場景提供了更好的性能。在這種寫入策略中,數(shù)據(jù)首先寫入緩存,然后寫入數(shù)據(jù)庫。緩存與數(shù)據(jù)庫串聯(lián),寫入總是通過緩存到主數(shù)據(jù)庫。
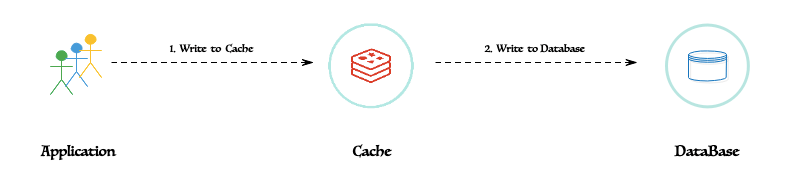
直寫模式的算法是:
1)對于不可變操作(讀取):
此策略不處理不可變操作。它應(yīng)該與通讀模式相結(jié)合。
2)對于可變操作(創(chuàng)建、更新、刪除):
客戶端只需要在 Redis 中創(chuàng)建、更新或刪除條目。緩存層必須以原子方式將此更改同步到 MySQL。
直寫模式的缺點也很明顯。首先,許多緩存層本身并不支持這一點。其次,Redis 是緩存而不是 RDBMS。它的設(shè)計并非具有彈性。因此,更改在復(fù)制到 MySQL 之前可能會丟失。即使 Redis 現(xiàn)在已經(jīng)支持 RDB 和 AOF 等持久化技術(shù),但仍然不推薦這種方式。
就其本身而言,直寫緩存似乎沒有太大作用,實際上,它們會引入額外的寫入延遲,因為數(shù)據(jù)先寫入緩存,然后再寫入主數(shù)據(jù)庫。但是當(dāng)與通讀緩存配對時,我們可以獲得通讀的所有好處,并且我們還可以獲得數(shù)據(jù)一致性保證,使我們免于使用緩存失效技術(shù)。
DynamoDB Accelerator (DAX) 是讀取/寫入緩存的一個很好的例子。它與 DynamoDB 和應(yīng)用程序內(nèi)聯(lián)。可以通過 DAX 對 DynamoDB 進行讀取和寫入。
2、Write Behind:即“后寫或回寫”。基于此策略 ,應(yīng)用程序?qū)?shù)據(jù)寫入緩存,緩存會立即確認(rèn),并在延遲一段時間后將數(shù)據(jù)寫回數(shù)據(jù)庫 。這對于寫入速度非常快,如果將同一鍵上的多個寫入合并為一次對數(shù)據(jù)庫的寫入,則速度會更快。但是數(shù)據(jù)庫長時間與緩存不一致,如果在數(shù)據(jù)刷新到數(shù)據(jù)庫之前進程崩潰,可能會丟失數(shù)據(jù)。RAID 卡是這種模式的一個很好的例子,為了避免數(shù)據(jù)丟失,通常需要 RAID 卡上的電池備份單元將數(shù)據(jù)保存在緩存中,但尚未登陸到磁盤。
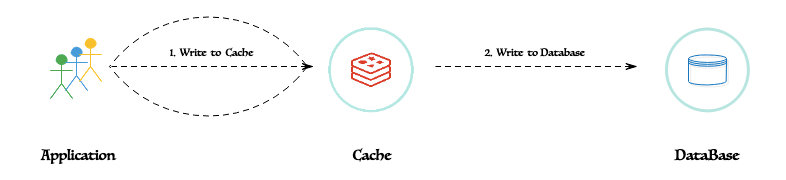
Write Behind 模式的算法是:
1)對于不可變操作(讀取):
此策略不處理不可變操作。它應(yīng)該與通讀模式相結(jié)合。
2)對于可變操作(創(chuàng)建、更新、刪除):
客戶端只需要在 Redis 中創(chuàng)建、更新或刪除條目。緩存層將更改保存到消息隊列中并向客戶端返回成功。更改會異步復(fù)制到 MySQL,并且可能在 Redis 向客戶端發(fā)送成功響應(yīng)后發(fā)生。
后寫模式與直寫不同,因為它異步地將更改復(fù)制到 MySQL。它提高了吞吐量,因為客戶端不必等待復(fù)制發(fā)生。具有高持久性的消息隊列可能是一種可能的實現(xiàn)。Redis 流(自 Redis 5.0 起受支持)可能是一個不錯的選擇。為了進一步提高性能,可以結(jié)合更改并批量更新 MySQL(以節(jié)省查詢次數(shù))。
Write Behind 模式的缺點是相似的。首先,許多緩存層本身并不支持這一點。其次,使用的消息隊列必須是 FIFO(先進先出)。否則,對 MySQL 的更新可能會亂序,因此最終結(jié)果可能不正確。
回寫緩存提高了寫入性能,適用于寫入繁重的工作負(fù)載。與通讀結(jié)合使用時,它適用于混合工作負(fù)載,其中最近更新和訪問的數(shù)據(jù)始終在緩存中可用。
它對數(shù)據(jù)庫故障具有彈性,并且可以容忍一些數(shù)據(jù)庫停機時間。如果支持批處理或合并,它可以減少對數(shù)據(jù)庫的總體寫入,從而減少負(fù)載并降低成本,如果數(shù)據(jù)庫提供程序按請求數(shù)量收費,例如動態(tài)數(shù)據(jù)庫。請記住,DAX 是直寫的,因此如果應(yīng)用程序?qū)懭敕敝兀瑒t不會看到任何成本降低。
一些開發(fā)人員將 Redis 用于緩存和回寫,以更好地吸收峰值負(fù)載期間的峰值。主要缺點是如果緩存失敗,數(shù)據(jù)可能會永久丟失。
大多數(shù)關(guān)系數(shù)據(jù)庫存儲引擎(即 InnoDB)在其內(nèi)部默認(rèn)啟用回寫緩存。查詢首先寫入內(nèi)存并最終刷新到磁盤。
3、Write invalidate:類似于直寫,先寫入數(shù)據(jù)庫,然后使緩存無效。在并發(fā)更新的情況下,這簡化了緩存和數(shù)據(jù)庫之間的一致性處理。我們不需要復(fù)雜的同步,權(quán)衡是命中率較低,因為我們總是使緩存無效并且下一次讀取將始終未命中。
讀模型
Read Through:即“ 通讀 ”。當(dāng)讀取未命中時,需要從數(shù)據(jù)庫中加載并保存到緩存中。這種模式的主要問題是基于某些特定的場景有時需要預(yù)熱緩存。通讀緩存與數(shù)據(jù)庫保持一致。當(dāng)緩存未命中時,它會從數(shù)據(jù)庫中加載丟失的數(shù)據(jù),填充緩存并將其返回給應(yīng)用程序。
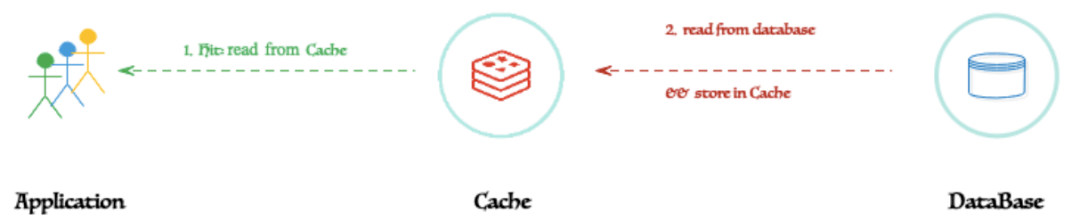
通讀模式的算法是:
1、對于不可變操作(讀取):
客戶端將始終簡單地從緩存中讀取。緩存命中或緩存未命中對客戶端是透明的。如果是緩存未命中,緩存應(yīng)該具有自動從數(shù)據(jù)庫中獲取的能力。
2、對于可變操作(創(chuàng)建、更新、刪除):
此策略不處理可變操作。它應(yīng)該與直寫(或后寫)模式結(jié)合使用。
通讀模式的一個主要缺點是許多緩存層可能不支持它。例如,Redis 將無法自動從 MySQL 獲取(除非為 Redis 編寫插件)。
Cache-Aside 和 Read-Through 策略都是延遲加載數(shù)據(jù),即僅在第一次讀取時加載。其適用 用例場景如下所示:
雖然 Read- Through 和 Cache-Aside 非常相似,但至少有兩個關(guān)鍵區(qū)別:
在緩存?zhèn)龋瑧?yīng)用程序負(fù)責(zé)從數(shù)據(jù)庫中獲取數(shù)據(jù)并填充緩存。在通讀中,此邏輯通常由庫或獨立緩存提供程序支持。
與 Cache-Aside 不同,Read-Through Cache 中的數(shù)據(jù)模型不能與數(shù)據(jù)庫的數(shù)據(jù)模型不同。
當(dāng)多次請求相同的數(shù)據(jù)時,通讀緩存最適合讀取繁重的工作負(fù)載。例如,一個新聞故事。缺點是當(dāng)?shù)谝淮握埱髷?shù)據(jù)時,總是會導(dǎo)致緩存未命中,并招致將數(shù)據(jù)加載到緩存中的額外懲罰。開發(fā)人員通過手動發(fā)出查詢來“加熱”或“預(yù)熱”緩存來處理這個問題。就像 cache-aside 一樣,緩存和數(shù)據(jù)庫之間的數(shù)據(jù)也有可能不一致,解決方法在于寫入策略,我們將在下面看到。
不讀或不寫模型
Refresh ahead:預(yù)測熱點數(shù)據(jù)并自動刷新數(shù)據(jù)庫中的緩存,永不阻塞讀取,最適合小型只讀數(shù)據(jù)集,例如郵政編碼列表緩存,我們可以定期刷新整個緩存,因為它很小并且是只讀的。如果能夠可以準(zhǔn)確地預(yù)測最常讀取哪些鍵,那么,還可以在此模式中預(yù)熱這些鍵。最后,如果數(shù)據(jù)在系統(tǒng)之外更新而系統(tǒng)無法收到通知,可能必須使用此模式。
在大多數(shù)場景下,我們通常使用通讀和直寫/后寫/寫無效等模型。針對 Refresh-ahead 模型,其可以單獨使用,也可以作為一種優(yōu)化來預(yù)測和預(yù)熱讀取以進行通讀。由誰負(fù)責(zé)緩存維護,調(diào)用者或?qū)S脤佑袃煞N實現(xiàn)模式。
1、Cache-Facade:緩存層是一個庫或服務(wù)委托寫入數(shù)據(jù)庫,我們只與緩存層交談。然后數(shù)據(jù)庫對我們的應(yīng)用程序是透明的。緩存層可以處理一致性和故障轉(zhuǎn)移。例如,許多數(shù)據(jù)庫都有自己的緩存,這是緩存外觀的一個很好的例子。我們還可以編寫一些進程內(nèi) DAO 層來讀取/寫入具有嵌入式緩存層的實體,從調(diào)用者的角度來看,這個小層也是一個緩存門面。
2、Cache-Aside:我們的應(yīng)用程序保持緩存一致性,這意味著應(yīng)用程序代碼更復(fù)雜,但這提供了更大的靈活性。例如,像數(shù)據(jù)庫查詢緩存這樣的緩存外觀模式只能緩存行,如果想緩存帶有行的 JAVA POJO 或 Kotlin 數(shù)據(jù)類,則將緩存放在一邊要容易得多。但是它仍然可以使用緩存門面,例如,將 Spring 緩存作為門面庫來緩存 POJO,并在后臺自動處理數(shù)據(jù)庫中的 POJO。
當(dāng)緩存不支持原生的讀通和寫通操作,并且資源需求不可預(yù)測時,我們使用這種緩存?zhèn)饶J健?/p>
1)讀取:嘗試命中緩存。如果沒有命中,則從數(shù)據(jù)庫中讀取,然后更新緩存。
2)寫入:先寫入數(shù)據(jù)庫,然后刪除緩存條目。這里一個常見的陷阱是人們錯誤地用值更新了緩存,高并發(fā)環(huán)境下的雙寫會使緩存變臟。
在這種模式下,仍然有可能出現(xiàn)臟緩存。在滿足這兩種情況時會發(fā)生上述情況:讀取數(shù)據(jù)庫并更新緩存、 更新數(shù)據(jù)庫并刪除緩存。
緩存一致性
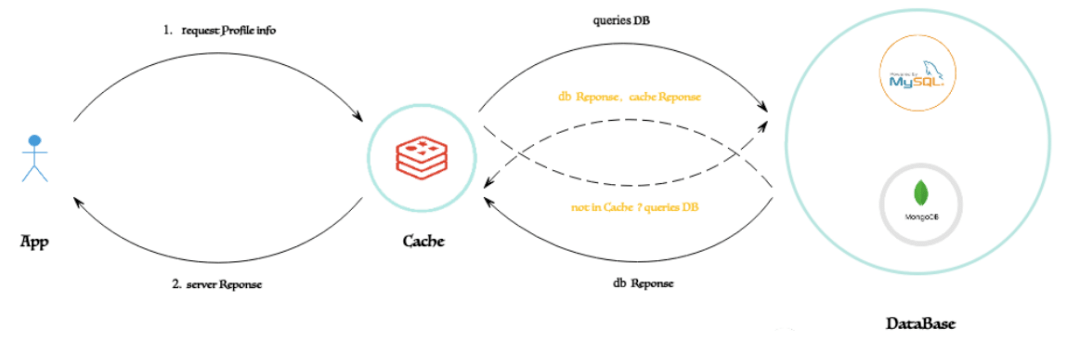
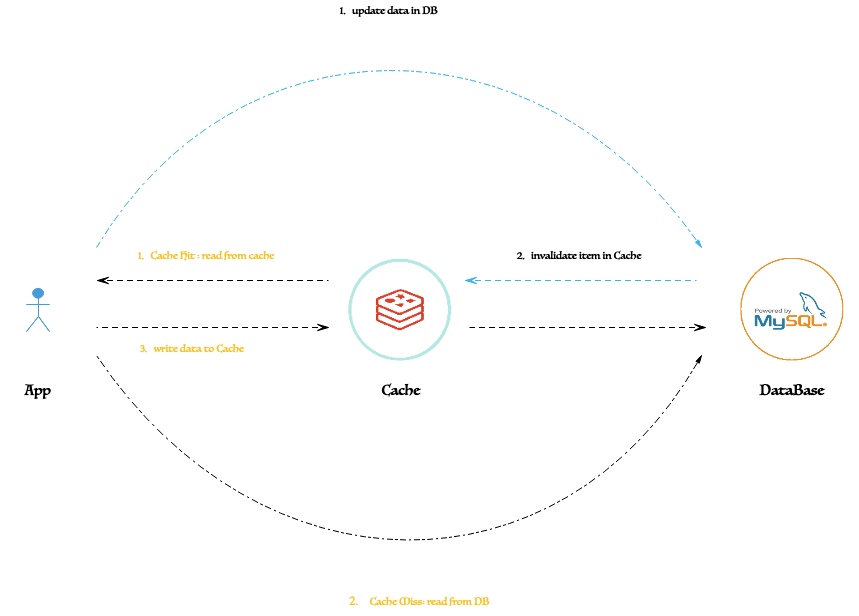
緩存一致性模型(參考)圖
如何保障緩存(Redis)與 數(shù)據(jù)存儲(數(shù)據(jù)庫)之間的數(shù)據(jù)一致性,通常 有多種 設(shè)計實現(xiàn)策略,本文重點針對 Cache Aside Pattern(旁路緩存模式) 進行簡要解析,此模型也是在實際的業(yè)務(wù)場景中使用較為廣泛的。具體如下。
在 Cache Aside Pattern 模型中,通常寫請求場景基本流程主要為:先更新 DB,然后直接刪除 Cache 。
在業(yè)務(wù)場景實現(xiàn)中,如果更新數(shù)據(jù)庫成功,而進行緩存刪除操作時出現(xiàn)失敗的情況下,簡單地說,通常主要有以下兩個解決方案:
1、縮短 Cache 失效時間:我們讓緩存數(shù)據(jù)的過期時間變短,這樣的話緩存就會從數(shù)據(jù)庫中加載數(shù)據(jù)。另外,這種解決辦法對于先操作緩存后操作數(shù)據(jù)庫的場景不適用。此方案在實際的業(yè)務(wù)場景中通常 不推薦,本質(zhì)上治標(biāo)不治本。
2、增加 Cache 更新重試機制:如果 Cache 服務(wù)當(dāng)前不可用導(dǎo)致緩存刪除失敗的話,我們就隔一段時間進行重試,重試次數(shù)可以自己定。如果多次重試還是失敗的話,我們可以把當(dāng)前更新失敗的 Key 存入隊列中,等緩存服務(wù)可用之后,再將緩存中對應(yīng)的 Key 刪除即可。可考慮使用消息隊列。此方案算是一種 常用的解決策略,能夠滿足絕大多數(shù)業(yè)務(wù)場景需要。
其實,從本質(zhì)上而言,緩存方案的規(guī)劃設(shè)計往往依賴于實際的業(yè)務(wù)場景需求,畢竟,技術(shù)是為業(yè)務(wù)服務(wù)的。可能有時我們引入緩存之后,為了解決短期內(nèi)的不一致性問題,選擇讓系統(tǒng)設(shè)計變得更加復(fù)雜的話,完全沒必要。
緩存異常場景
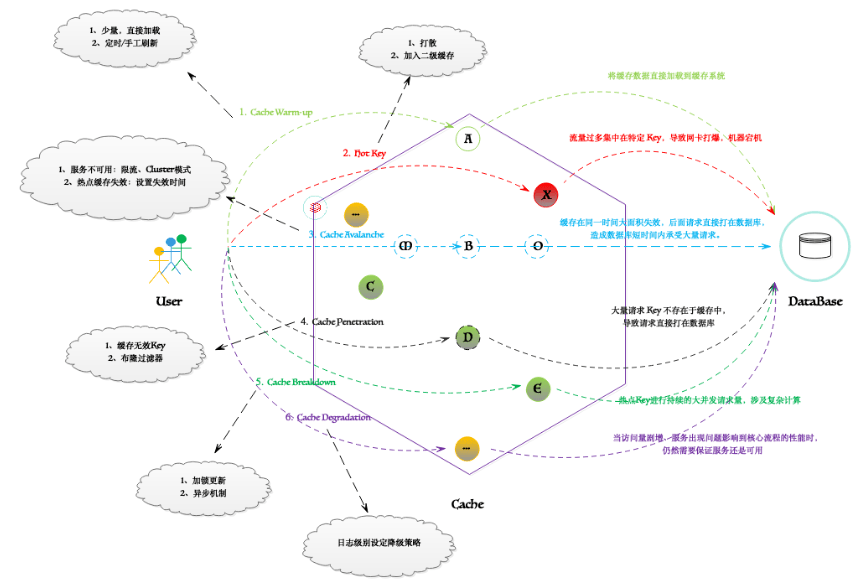
緩存場景模型圖
其實。在實際的場景中,考慮到各種應(yīng)用異常和業(yè)務(wù)故障,通常不可能完全使用分布式緩存和數(shù)據(jù)庫系統(tǒng)來實現(xiàn)線性一致性模型。每一種緩存模式都有其自身的局限性,在某些情況下我們無法獲得順序一致性,或者有時會在緩存和數(shù)據(jù)庫之間獲得意外延遲。對于筆者在本文中展示的所有的解決方案,依據(jù)不同的業(yè)務(wù)需求總是會遇到高并發(fā)的極端情況。因此,對此沒有靈丹妙藥,在選擇解決方案之前了解限制并定義特定的一致性要求。
如果想要實現(xiàn)線性一致性和容錯性,建議最好不要使用緩存策略,可考慮其他的方案。以上為 Redis 緩存系統(tǒng)相關(guān)解析,希望對大家有用。
作者:李杰
來源:twt社區(qū)





