擊這里在線咨詢客服")

新智元報道
編輯:編輯部
【新智元導(dǎo)讀】這個開源工具,居然能用GPT-4代替人類去標(biāo)注數(shù)據(jù),效率比人類高了100倍,但成本只有1/7。
大模型滿天飛的時代,AI行業(yè)最缺的是什么?毫無疑問一定是算(xian)力(ka)。
老黃作為AI掘金者唯一的「鏟子供應(yīng)商」,早已賺得盆滿缽滿。

除了GPU,還有什么是訓(xùn)練一個高效的大模型必不可少且同樣難以獲取的資源?
高質(zhì)量的數(shù)據(jù)。OpenAI正是借助基于人類標(biāo)注的數(shù)據(jù),才一舉從眾多大模型企業(yè)中脫穎而出,讓ChatGPT成為了大模型競爭中階段性的勝利者。
但同時,OpenAI也因?yàn)槭褂梅侵蘖畠r的人工進(jìn)行數(shù)據(jù)標(biāo)注,被各種媒體口誅筆伐。

時代周刊報道OpenAI雇傭肯尼亞廉價勞動力標(biāo)注
而那些參與數(shù)據(jù)標(biāo)注的工人們,也因?yàn)殚L期暴露在有毒內(nèi)容中,受到了不可逆的心理創(chuàng)傷。

衛(wèi)報報道肯尼亞勞工指責(zé)數(shù)據(jù)標(biāo)注工作給自己帶來了不可逆的心理創(chuàng)傷
總之,對于數(shù)據(jù)標(biāo)注,一定需要找到一個新的方法,才能避免大量使用人工標(biāo)注帶來的包括道德風(fēng)險在內(nèi)的其他潛在麻煩。
所以,包括谷歌,Anthropic在內(nèi)的AI巨頭和大型獨(dú)角獸,都在進(jìn)行數(shù)據(jù)標(biāo)注自動化的探索。
谷歌最近的研究,開發(fā)了一個和人類標(biāo)注能力相近的AI標(biāo)注工具

Anthropic采用了Constitutional AI來處理數(shù)據(jù),也獲得了很好的對齊效果
除了巨頭們的嘗試之外,最近,一家初創(chuàng)公司refuel,也上線了一個AI標(biāo)注數(shù)據(jù)的開源處理工具:Autolabel。
Autolabel:用AI標(biāo)注數(shù)據(jù),效率最高提升100倍
這個工具可以讓有數(shù)據(jù)處理需求的用戶,使用市面上主流的LLM(ChatGPT,Claude等)來對自己的數(shù)據(jù)集進(jìn)行標(biāo)注。
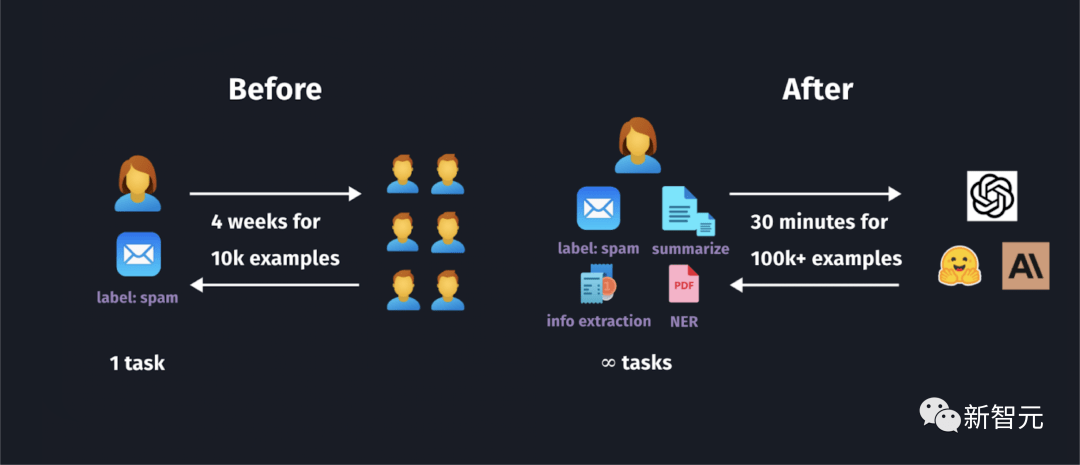
refuel稱,用自動化的方式標(biāo)注數(shù)據(jù),相比于人工標(biāo)注,效率最高可以提高100倍,而成本只有人工成本的1/7!
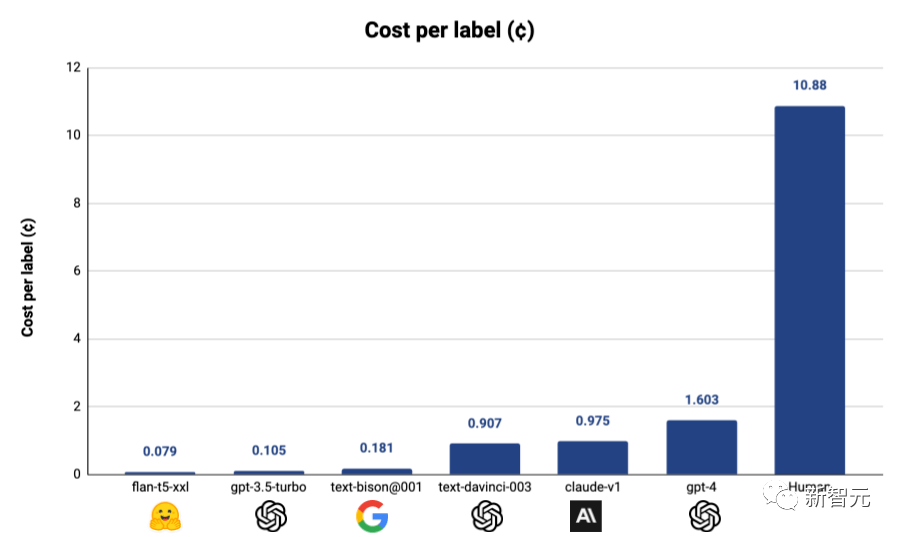
就算按照使用成本最高的GPT-4來算,采用Autolabel標(biāo)注的成本只有使用人工標(biāo)注的1/7,而如果使用其他更便宜的模型,成本還能進(jìn)一步降低
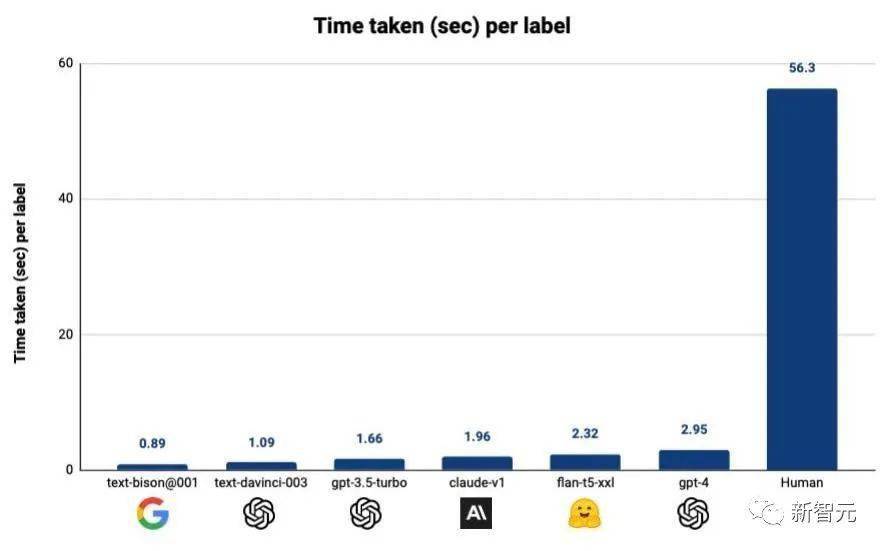
采用Autolabel+LLM的標(biāo)注方式之后,標(biāo)注效率更是大幅提升
對于LLM標(biāo)注質(zhì)量的評估,Autolabel的開發(fā)者創(chuàng)立了一個基準(zhǔn)測試,通過將不同的LLM的標(biāo)注結(jié)果和基準(zhǔn)測試中不同數(shù)據(jù)集中收納的標(biāo)準(zhǔn)答案向比對,就能評估各個模型標(biāo)注數(shù)據(jù)的質(zhì)量。
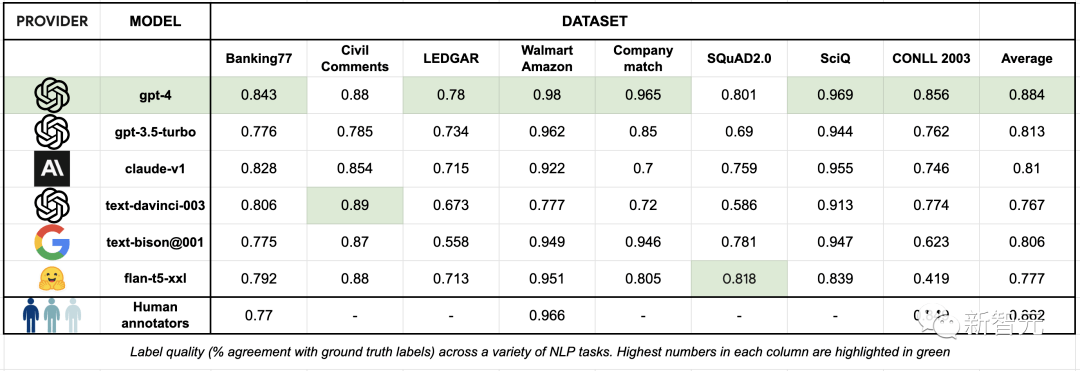
當(dāng)Autolabel采用GPT-4進(jìn)行標(biāo)注時,獲得了最高的準(zhǔn)確率——88.4%,超過了人類標(biāo)注結(jié)果的準(zhǔn)確率86.2%。
而且其他比GPT-4便宜得多的模型的標(biāo)注準(zhǔn)確率,相比GPT-4來說也不算低。
開發(fā)者稱,在比較簡單的標(biāo)注任務(wù)中采用便宜的模型,在困難的任務(wù)中采用GPT-4,將可以大大節(jié)省標(biāo)注成本,同時幾乎不影響標(biāo)注的準(zhǔn)確率。
Autolabel支持對自然語言處理項(xiàng)目進(jìn)行分類,命名實(shí)體識別,實(shí)體匹配和問答。
支持主流的所有LLM提供商:OpenAI、Anthropic 和 google Palm 等,并通過HuggingFace為開源和私有模型提供支持。
用戶可以嘗試不同的提示策略,例如少樣本和思維鏈提示。只要簡單更新配置文件即可輕松估計標(biāo)簽置信度。
Autolabel免除了編寫復(fù)雜的指南,無盡地等待外部團(tuán)隊(duì)來提供數(shù)據(jù)支持的麻煩,用戶能夠在幾分鐘內(nèi)開始標(biāo)注數(shù)據(jù)。
可以支持使用本地部署的私有模型在本地處理數(shù)據(jù),所以對于數(shù)據(jù)隱私敏感度很高的用戶來說,Autolabel提供了成本和門檻都很低的數(shù)據(jù)標(biāo)注途徑。
如何用AI進(jìn)行評論有害性標(biāo)注
所以,不論是律所想要通過GPT-4來對法律文檔進(jìn)行分類,還是保險公司想要用私有模型對敏感的客戶醫(yī)療數(shù)據(jù)進(jìn)行分類或者篩查,都可以使用Autolabel進(jìn)行高效地處理。
Autolabel提供了一個簡單的案例來展示了如何使用它進(jìn)行評論有害性的標(biāo)注過程。
假設(shè)用戶是一個社交媒體的內(nèi)容審核團(tuán)隊(duì),需要訓(xùn)練分類器來確定用戶評論是否有毒。
如果沒有Autolabel,用戶需要首先收集幾千個示例,并由一組人工注釋者對它們進(jìn)行標(biāo)注,可能需要幾周的時間——熟悉標(biāo)注方針,從小數(shù)據(jù)集到大數(shù)據(jù)集進(jìn)行幾次迭代,等等。
而如果使用Autolabe可以在分鐘內(nèi)就對這個數(shù)據(jù)集進(jìn)行標(biāo)注。
Autolabel安裝
首先安裝所有必要的庫:
- pipinstall 'refuel-autolabel[openai]'
現(xiàn)在,將OpenAI密鑰設(shè)置為環(huán)境變量。
下載和查看數(shù)據(jù)集
將使用一個名為Civil Comments的數(shù)據(jù)集,該數(shù)據(jù)集可通過Autolabel獲得。你可以在本地下載它,只需運(yùn)行:
fromautolabel importget_data get_data('civil_comments')輸出為:
Downloading seed example dataset to "seed.csv"... 100% [..............................................................................] 65757 / 65757 Downloading testdataset to "test.csv"... 100% [............................................................................] 610663 / 610663標(biāo)注例子:
使用自動標(biāo)簽貼標(biāo)分為三個步驟:
首先,指定一個標(biāo)簽配置(參見下面的config對象)并創(chuàng)建一個LabelingAgent。
接下來,通過運(yùn)行agent.plan,使用config中指定的LLM對的數(shù)據(jù)集進(jìn)行一次標(biāo)注
最后,使用agent.run運(yùn)行標(biāo)簽
實(shí)驗(yàn)1:嘗試簡單的標(biāo)簽指南
定義下面的配置文件:
config = {"task_name": "ToxicCommentClassification","task_type": "classification", # classification task"dataset": {"label_column": "label",},"model": {"provider": "openai","name": "gpt-3.5-turbo"# the model we want to use},"prompt": {# very simple instructions for the LLM"task_guidelines": "Does the provided comment contain 'toxic' language? Say toxic or not toxic.","labels": [ # list of labels to choose from"toxic","not toxic"],"example_template": "Input: {example}nOutput: {label}"}}如果要創(chuàng)建自定義配置,可以使用CLI或編寫自己的配置。
現(xiàn)在,用agent.plan進(jìn)行預(yù)演:
from autolabel import LabelingAgent, AutolabelDatasetagent = LabelingAgent(config)ds = AutolabelDataset('test.csv', config = config)agent.plan(ds)
輸出:
┌──────────────────────────┬─────────┐│ Total Estimated Cost │ $4.4442 ││ Number of Examples │ 2000 ││ Average cost per example │ $0.0022 │└──────────────────────────┴─────────┘───────────────────────────────────────────────── Prompt Example ──────────────────────────────────────────────────Does the provided commentcontain 'toxic'language? Say toxic ornottoxic.You will returnthe answer withjust one element: "the correct label"
NowI want you tolabel the followingexample:Input: [ Integrity means that you pay your debts.]. Does this ApplytoPresident Trump too?Output:
最后,進(jìn)行數(shù)據(jù)標(biāo)注:
ds= agent.run(ds, max_items=100)
┏━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓┃ support┃ threshold┃ accuracy┃ completion_rate┃┡━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩│ 100 │ -inf│ 0.54│ 1.0│└─────────┴───────────┴──────────┴─────────────────┘
輸出結(jié)果為54%的準(zhǔn)確率不是很好,進(jìn)一步改進(jìn)的具體方法可以訪問以下鏈接查看:
https://docs.refuel.ai/guide/overview/tutorial-classification/
技術(shù)細(xì)節(jié):標(biāo)注質(zhì)量Benchmark介紹
在對Autolabel的基準(zhǔn)測試中,包含了以下數(shù)據(jù)集:
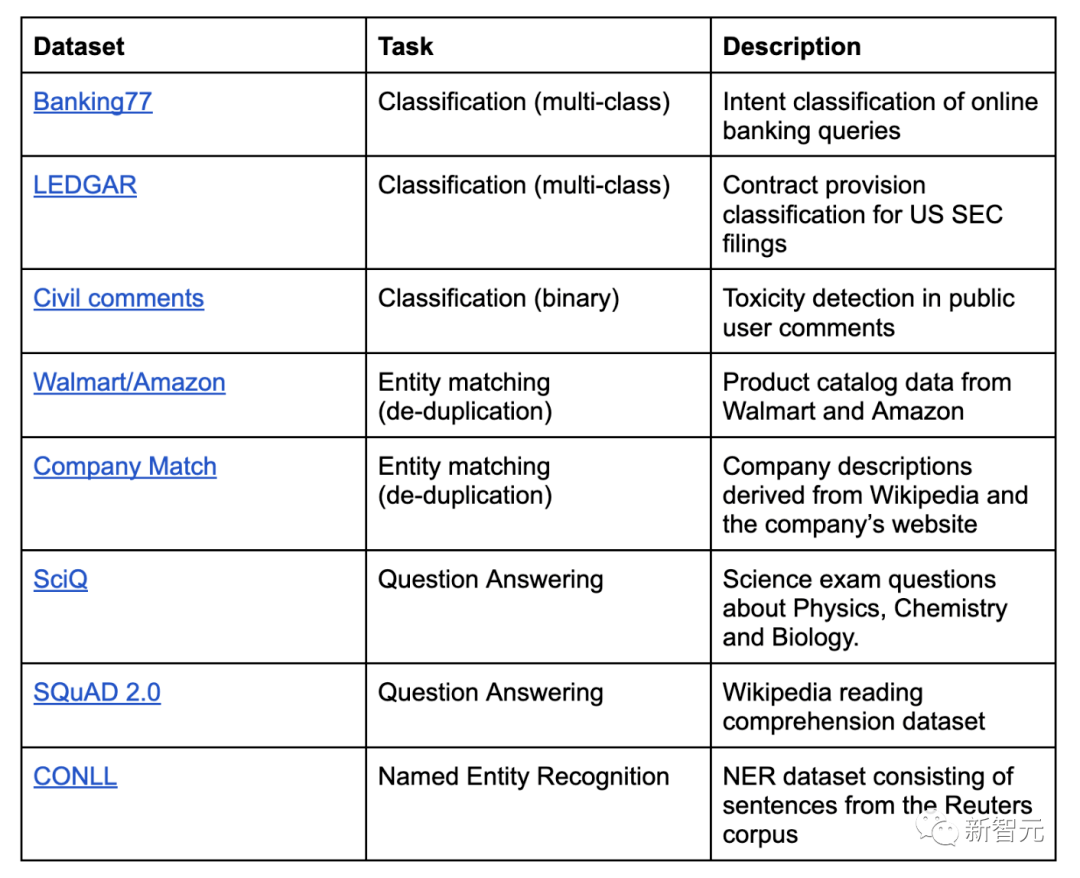
表1:Autolabel標(biāo)注的數(shù)據(jù)集列表
使用了以下LLM:
表2:用于評估的LLM提供者與模型列表
本研究在三個標(biāo)準(zhǔn)上對LLM和人工標(biāo)注進(jìn)行評估:
首先是標(biāo)簽質(zhì)量,即生成的標(biāo)簽與真實(shí)標(biāo)簽之間的一致性;
其次是周轉(zhuǎn)時間,即以秒為單位時,生成標(biāo)簽所花費(fèi)的時間;
最后是以分為單位,生成每個標(biāo)簽的成本。
對于每個數(shù)據(jù)集,研究人員都將其拆分為種子集和測試集兩部分。
種子集包含200個示例,是從訓(xùn)練分區(qū)中隨機(jī)采樣構(gòu)建的,用于置信度校準(zhǔn)和一些少量的提示任務(wù)中。
測試集包含2000個示例,采用了與種子集相同的構(gòu)建方法,用于運(yùn)行評估和報告所有基準(zhǔn)測試的結(jié)果。
在人工標(biāo)注方面,研究團(tuán)隊(duì)從常用的數(shù)據(jù)標(biāo)注第三方平臺聘請了數(shù)據(jù)標(biāo)注員,每個數(shù)據(jù)集都配有多個數(shù)據(jù)標(biāo)注員。
此過程分為三個階段:
研究人員為數(shù)據(jù)標(biāo)注員提供了標(biāo)注指南,要求他們對種子集進(jìn)行標(biāo)注。
然后對標(biāo)注過的種子集進(jìn)行評估,為數(shù)據(jù)標(biāo)注員提供該數(shù)據(jù)集的基準(zhǔn)真相作為參考,并要求他們檢查自己的錯誤。
隨后,為數(shù)據(jù)標(biāo)注員解釋說明他們遇到的標(biāo)簽指南問題,最后對測試集進(jìn)行標(biāo)注。
結(jié)果
標(biāo)簽質(zhì)量
標(biāo)簽質(zhì)量衡量的是生成的標(biāo)簽(由人類或LLM標(biāo)注者生成)與數(shù)據(jù)集中提供的基準(zhǔn)真相的吻合程度。
對于SQuAD數(shù)據(jù)集,研究人員用生成標(biāo)簽與基準(zhǔn)真相之間的F1分?jǐn)?shù)來衡量一致性,F(xiàn)1是問題解答的常用指標(biāo)。
對于SQuAD以外的數(shù)據(jù)集,研究人員用生成標(biāo)簽與基準(zhǔn)真相之間的精確匹配來衡量一致性。
下表匯總了各個數(shù)據(jù)集標(biāo)簽質(zhì)量的結(jié)果:
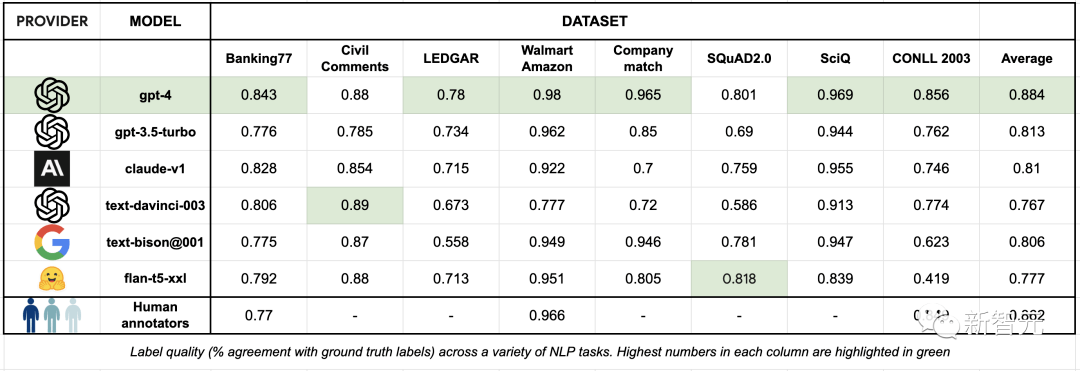
表3:各種NLP任務(wù)中的標(biāo)簽質(zhì)量(與基準(zhǔn)真相的一致率),每列中的最高數(shù)字以綠色標(biāo)出
可以看到,與熟練的人工數(shù)據(jù)標(biāo)注員相比,最先進(jìn)的LLM已經(jīng)可以在相同甚至更好的水平上標(biāo)注文本數(shù)據(jù)集,并且做到開箱即用,大大簡化了繁瑣的數(shù)據(jù)標(biāo)注流程。
GPT-4在一系列數(shù)據(jù)集中的標(biāo)簽質(zhì)量都優(yōu)于人類數(shù)據(jù)標(biāo)注員。其他幾個LLM的表現(xiàn)也在80%左右,但調(diào)用API的價格僅為GPT-4的十分之一。
但由于LLM是在大量數(shù)據(jù)集上訓(xùn)練出來的,所以在評估LLM的過程中存在著數(shù)據(jù)泄露的可能。
研究人員對此進(jìn)行了例如集合的額外改進(jìn),可以將表現(xiàn)最好的的LLM(GPT-4、PaLM-2)與基準(zhǔn)真相的一致性從89%提高到95%以上。
置信度估計
對LLM最大的詬病之一就是幻覺。因此,當(dāng)務(wù)之急是用一種與標(biāo)簽正確的可能性相關(guān)的方式來評估標(biāo)簽的質(zhì)量。
為了估計標(biāo)簽置信度,研究人員將LLM輸出的token級日志概率平均化,而這種自我評估方法在各種預(yù)測任務(wù)中都很有效。
對于提供對數(shù)概率的LLM(text-davinci-003),研究人員使用這些概率來估計置信度。
對于其他LLM,則使用FLAN T5 XXL模型進(jìn)行置信度估計。
標(biāo)簽生成后,查詢FLAN T5 XXL模型以獲得生成的輸出標(biāo)注的概率分布,但前提是輸入的提示信息與用于標(biāo)簽的信息相同。
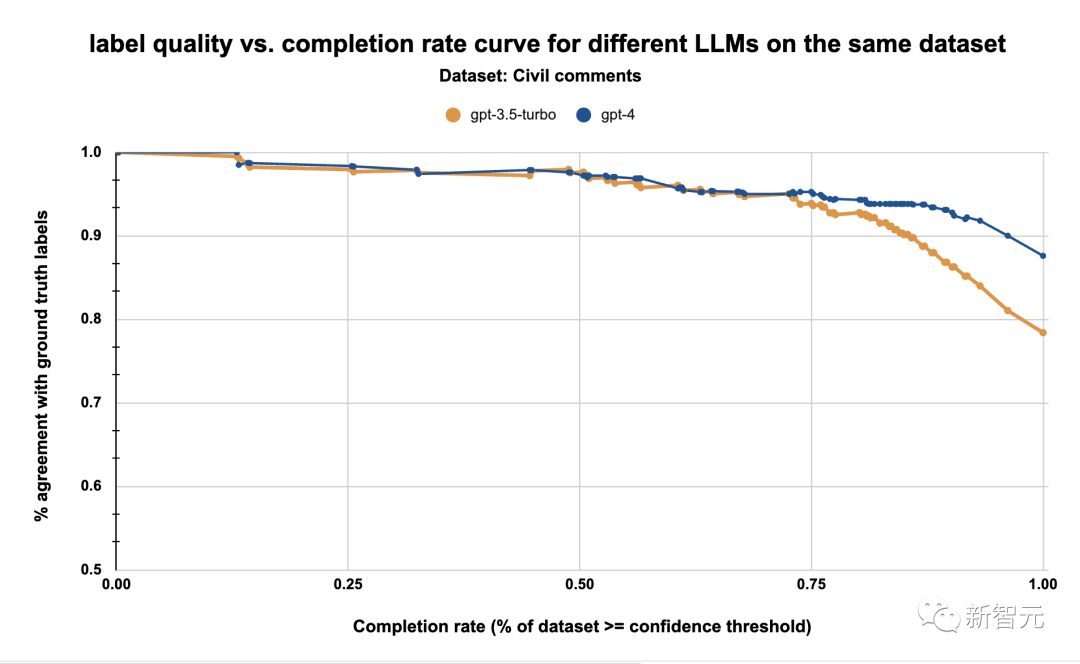
表4:同一數(shù)據(jù)集上gpt-3.5-turbo和gpt-4的標(biāo)簽質(zhì)量與完成率
在校準(zhǔn)步驟中,研究人員利用估計置信度來了解標(biāo)簽質(zhì)量和完成率之間的權(quán)衡。
即研究人員為LLM確定了一個工作點(diǎn),并拒絕所有低于該工作點(diǎn)閾值的標(biāo)簽。
例如,上圖顯示,在95%的質(zhì)量閾值下,我們可以使用GPT-4標(biāo)注約77%的數(shù)據(jù)集。
添加這一步的原因是token級日志概率在校準(zhǔn)方面的效果不佳,如GPT-4技術(shù)報告中所強(qiáng)調(diào)的那樣:
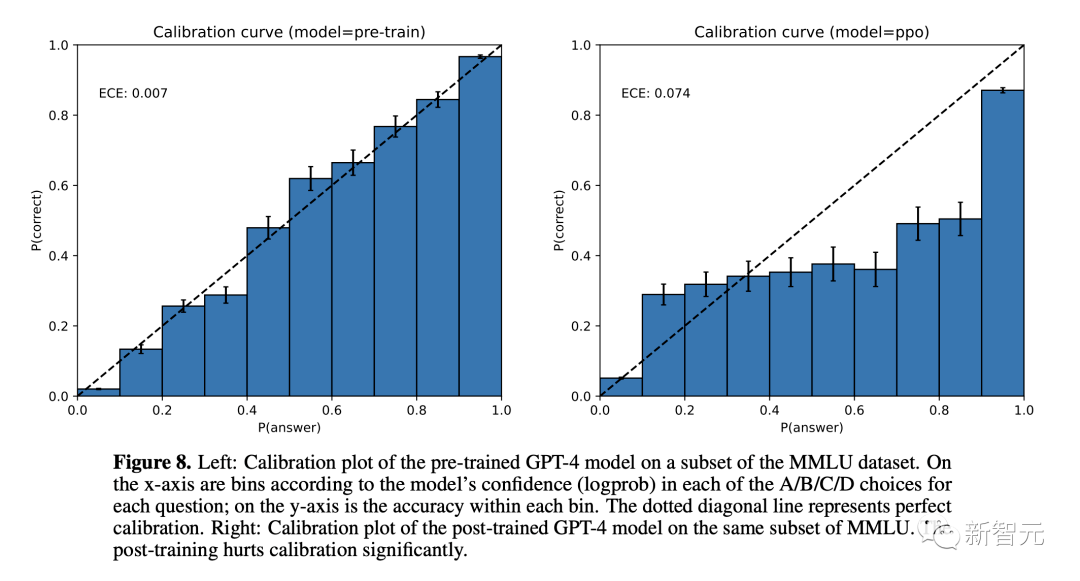
GPT-4模型的校準(zhǔn)圖:比較預(yù)訓(xùn)練和后RLHF版本的置信度和準(zhǔn)確性
使用上述置信度估算方法,并將置信度閾值設(shè)定為95%的標(biāo)簽質(zhì)量(相比之下,人類標(biāo)注者的標(biāo)簽質(zhì)量為86%),得到了以下數(shù)據(jù)集和LLM的完成率:
95%與基準(zhǔn)真相一致的完成率
相比之下,人類標(biāo)注者與基準(zhǔn)真相的一致性為86.6%。
從上圖可以看到在所有數(shù)據(jù)集中,GPT-4的平均完成率最高,在8個數(shù)據(jù)集中,有3個數(shù)據(jù)集的標(biāo)注質(zhì)量超過了這一質(zhì)量閾值。
而其他多個模型(如text-bison@001、gpt-3.5-turbo、claude-v1和flan-t5-xxl)也實(shí)現(xiàn)了很好的性能:
平均至少成功自動標(biāo)注了50%的數(shù)據(jù),但價格卻只有GPT-4 API成本的1/10以下。
未來更新的方向
在接下來的幾個月中,開發(fā)者承諾將向Autolabel添加大量新功能:
支持更多LLM進(jìn)行數(shù)據(jù)標(biāo)注。
支持更多標(biāo)注任務(wù),例如總結(jié)等。
支持更多的輸入數(shù)據(jù)類型和更高的LLM輸出穩(wěn)健性。
讓用戶能夠試驗(yàn)多個LLM和不同提示的工作流程。
參考資料:
https://www.refuel.ai/blog-posts/introducing-autolabel





