

什么是Selenium
01
模擬瀏覽器:Selenium
我們知道,網頁會使用JAVA加載數據,對應于這種模式,可以通過分析數據接口來進行直接抓取,這種方式需要對網頁的內容、格式和Java代碼有所研究才能順利完成。但有時還會碰到另外一些頁面,這些頁面同樣使用AJAX技術,但是其頁面結構比較復雜,很多網頁中的關鍵數據由AJAX獲得,而頁面元素本身也使用Java來添加或修改,甚至于人們感興趣的內容在原始頁面中并不出現,需要進行一定的用戶交互(如不斷下拉滾動條)才會顯示。對于這種情況,為了方便,就會考慮使用模擬瀏覽器的方法來進行抓取,而不是通過“逆向工程”去分析AJAX接口,使用模擬瀏覽器的方法,特點是普適性強,開發耗時短,抓取耗時長(模擬瀏覽器的性能問題始終令人憂慮),使用分析AJAX的方法,特點則剛好與模擬瀏覽器相反,甚至在同一個網站、同一個類別中的不同網頁上,AJAX數據的具體訪問信息都有差別,因此開發過程投入的時間和精力成本是比較大的。如果碰到頁面結構相對復雜或者AJAX數據分析比較困難(如數據經過加密)的情況,就需要考慮使用瀏覽器模擬的方式了。
在Python/ target=_blank class=infotextkey>Python模擬瀏覽器進行數據抓取方面,Selenium永遠是繞不過去的一個坎。Selenium(意為化學元素“硒”)是瀏覽器自動化工具,在設計之初是為了進行瀏覽器的功能測試。Selenium的作用,直觀地說,就是使得操縱瀏覽器進行一些類似普通用戶的操作成為可能,如訪問某個地址、判斷網頁狀態、單擊網頁中的某個元素(按鈕)等。使用Selenium來操控瀏覽器進行的數據抓取其實已經不能算是一種“爬蟲”程序,一般談到爬蟲,自然想到的是獨立于瀏覽器之外的程序,但無論如何,這種方法有助于解決一些比較復雜的網頁抓取任務,由于直接使用了瀏覽器,麻煩的AJAX數據和Java動態頁面一般都已經渲染完成,利用一些函數,完全可以做到隨心所欲地抓取,加之開發流程也比較簡單,因此有必要進行基本的介紹。
Selenium本身只是個工具,而不是一個具體的瀏覽器,但是Selenium支持包括Chrome和Firefox在內的主流瀏覽器。為了在Python中使用Selenium,需要安裝selenium庫(仍然通過pip install selenium的方式進行安裝)。完成安裝后,為了使用特定的瀏覽器,可能需要下載對應的驅動。將下載到的文件放在某個路徑下。并在程序中指明該路徑即可。如果想避免每次配置路徑的麻煩,可以將該路徑設置為環境變量,這里就不再贅述了。
通過一個訪問百度新聞站點的例子來引入selenium庫,代碼如下:

運行上面的代碼,會看到Chrome程序被打開,瀏覽器訪問了百度首頁,然后跳轉到了百度新聞頁面,之后又選擇了該頁面的第一個頭條新聞,從而打開了新的新聞頁。一段時間后,瀏覽器關閉并退出。控制臺會輸出“百度一下,你就知道”(對應browser.title)和http://news.bAIdu.com/(對應browser.current_url)。這無疑是一個好消息,如果能獲取對瀏覽器的控制權,那么爬取某一部分的內容會變得如臂使指。
另外,selenium庫能夠提供實時網頁源碼,這使得通過結合Selenium和BeautifulSoup(以及其他上文所述的網頁元素解析方法)成為可能,如果對selenium庫自帶的元素定位API不甚滿意,那么這會是一個非常好的選擇。總的來說,使用selenium庫的主要步驟如下。
① 創建瀏覽器對象,即使用類似下面的語句:
② 訪問頁面,主要使用browser.get方法,傳入目標網頁地址。
③ 定位網頁元素,可以使用selenium自帶的元素查找API,即
還可以使用browser.page_source獲取當前網頁源碼并使用BeautifulSoup等網頁解析工具定位:

④ 網頁交互,對元素進行輸入、選擇等操作。如訪問豆瓣并搜索某一關鍵字(效果見圖1-9)的代碼如下。

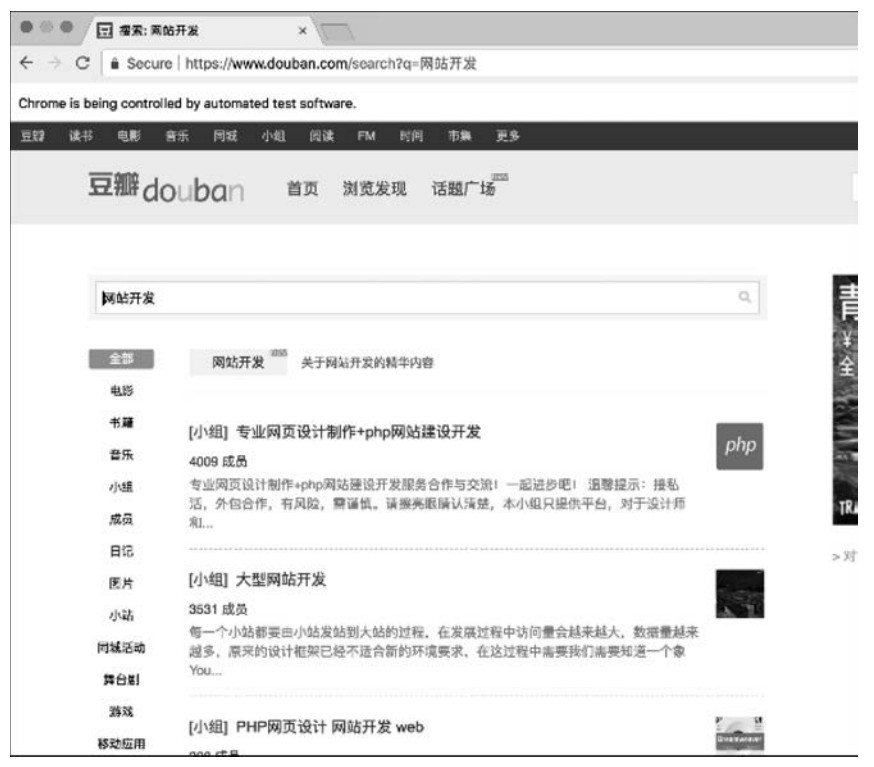
■ 圖1-9使用Selenium操作Chrome進行豆瓣搜索的結果
在導航(窗口中的前進與后退)方面,主要使用browser.back和browser.forward兩個函數。
⑤ 獲取元素屬性。可供使用的函數方法很多,例如:
之前曾對Selenium的基本使用做過簡單的說明,有了網站交互(而不是典型爬蟲程序避開瀏覽器界面的策略)還能夠完成很多測試工作,如找出異常表單、html排版錯誤、頁面交互問題。





