
近年來,生成式預訓練模型(如 GPT)的興起徹底顛覆了自然語言處理領域,其影響甚至已經延伸到其他多種模態。然而,像 ChatGPT 和 GPT-4 這樣的模型,由于其巨大的模型規模與計算復雜度、復雜的部署方式以及未開源的訓練模型,這些因素都限制了他們在學術界和工業界的推廣與應用。因此,易于計算和部署的語言模型成為了人們關注的焦點。

- 論文地址:http://arxiv.org/abs/2308.14149
- 項目地址:https://Github.com/GPT-Alternatives/gpt_alternatives
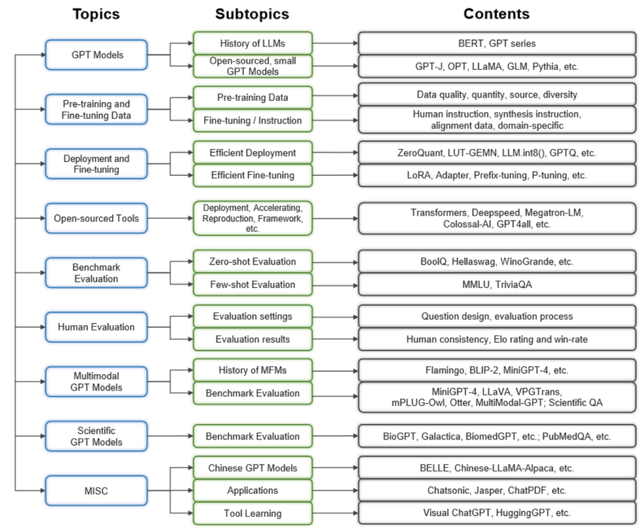
本文將從以下幾個方面,對 GPT 的平替模型進行研究,從多個維度出發,進行大量實驗驗證,只為得到更全面更真實的模型測評結果,幫助研究者和從業者更加深入地理解這些模型的基本原理、發展趨勢和主要的挑戰,并且根據不同需求選擇合適的模型。
1. 總結了平替模型的架構、設計方式以及效率與性能的權衡;
2. 梳理了現有的公開數據集并分析了預訓練數據源、數據質量、數量、多樣性、微調數據(包括指令數據、對齊數據),以及特定領域數據的特點;
3. 介紹了高效訓練與部署大規模語言模型的方式,并總結了現有的開源平替模型;
4. 評測了不同平替模型在多個常用基準數據集上的效果;
5. 設計了人工評測任務,并在不同平替模型上進行了人工評估;
6. 討論和評測了大規模語言模型在圖文多模態領域的研究現狀及模型表現;
7. 評測了各個平替模型在科學研究領域的基準數據集上的性能。
大規模語言模型發展歷程
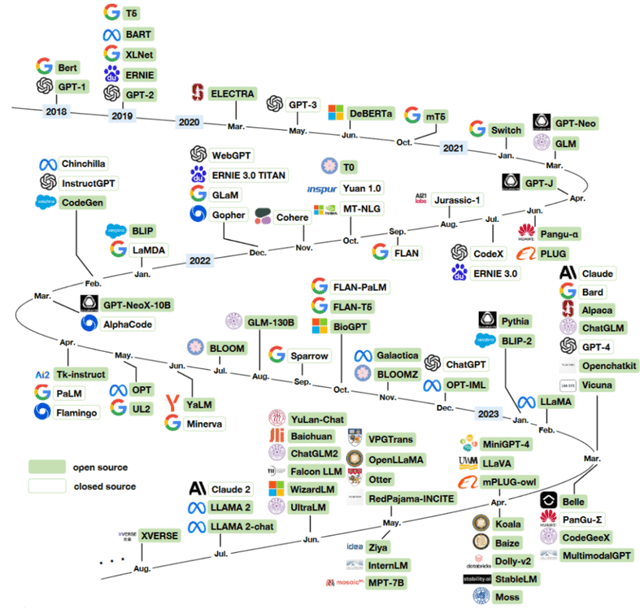
GPT 的平替模型
持續更新在 github……
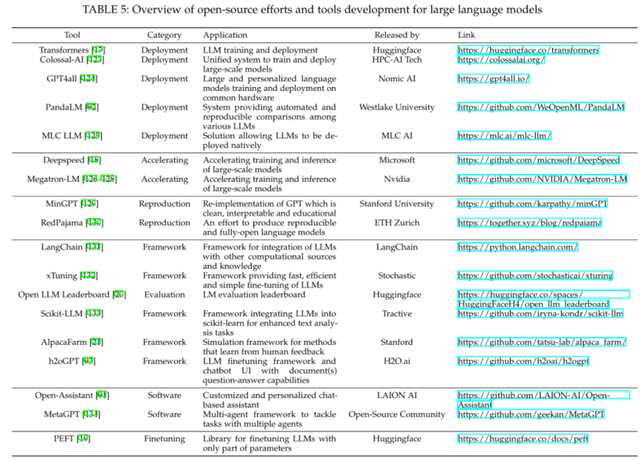
開源工具
近年來,深度學習的飛速發展與開源社區的繁榮息息相關。本節中,我們整理了大規模語言模型相關的開源工具庫,這些工具庫包含了訓練、部署、加速、模型評測等方面。
基準數據集評測
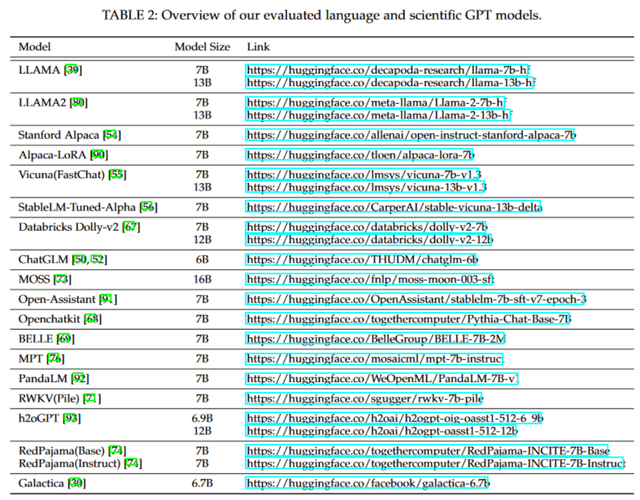
為了全面評估各種語言模型在不同任務上的性能,我們首先從不同角度在多個常用的測試基準上進行了詳盡的評估。選定的任務旨在測試模型的常識推理、信息抽取、文本理解、數學解題以及跨學科知識的能力。
評測方式
我們采用了兩種評測方式:
1.Zero-shot 方式。該方式主要關注模型在未見過的新任務上的性能,即 zero-shot 學習。在沒有給定與任務相關的訓練樣本的情況下,模型需要依賴其在大規模語料庫中學到的知識和理解,來給出準確的答案。這種方式對模型的歸納、推理以及泛化能力都提出了很高的挑戰。
2.Few-shot 方式。小樣本學習方式要求模型在僅給定少數示例答案的情況下,能夠產生合適的回答。這種評估方式主要測試模型的遷移和泛化能力。在實際應用中,這種能力尤為重要,因為它允許模型在數據稀缺的情境中仍然表現出色。
評測數據集
在 Zero-Shot 設定下,我們測試了 BoolQ, Hellaswag, WinoGrande, PIQA, ARC, OpenbookQA, RACE, DROP 和 GSM8K 數據集。在 Few-Shot 設定下,我們測試了 MMLU 和 TriviaQA 數據集。
實驗結果
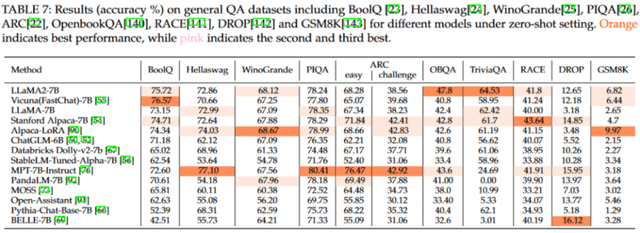
上圖展示了不同語言模型在 zero-shot 設定下的測試結果。值得注意的是,盡管本研究分析的許多模型都基于 LLaMA-7B 架構,但它們的個體性能差異顯著。這些模型之間的性能差異主要歸因于它們在開發過程中采用的調優方法,這凸顯了調優策略在決定模型性能上的核心作用。此外,這些結果也揭示了語言模型在不同任務中的效能差異。沒有單一模型可以在所有數據集和任務上完全占優。另外,這些語言模型在涉及帶有選項的任務中表現得相對較好,但在生成任務中則有所不及。這種差異是可以理解的,因為生成連貫、與上下文相符的內容遠比簡單的分類任務更為挑戰,它需要模型具備更深入的語言和上下文理解能力。
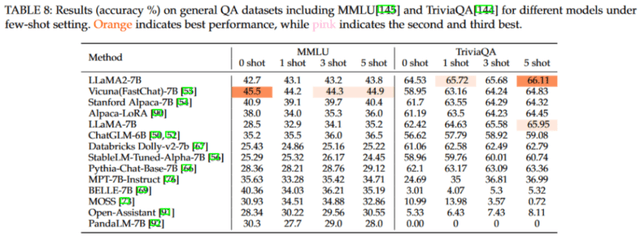
該圖為我們呈現了模型在 few-shot 設置下的表現。從表格中,我們可以觀察到幾個顯著的特點。首先,這些語言模型的性能并沒有隨著示例數量的增加而明顯上升。這可以歸因于模型相對較小的規模以及其有限地利用樣本學習的能力,導致模型難以從所給示例中充分吸取知識。其次,模型在不同的示例設置下的性能相對穩定。因此,如果某模型在 zero-shot 設置下已經表現得很好,那么在其他設置下,它很可能也能保持這種優勢。
不過,需要承認的是,部分經過測試的語言模型并未達到最佳表現。這些模型可能需要更合適的提示或進一步的微調來獲取必要的知識并提高其整體性能。
人工評測
現有的基準數據集通常用于評估傳統的語言模型,但它們往往只專注于某一特定的任務或主題。與此同時,大規模語言模型展現出的多樣化能力,很難僅通過這些基準數據集來進行全面的評價。為了更深入地了解這些模型的性能,我們繼續對現有的平替模型進行了人工評測。
評測方式
人工評價模型性能的關鍵在于評測問題的選擇與評測人員的客觀性。為此,我們采用常見的兩兩對比的方式來評測模型的表現。與直接打分或排序相比,兩兩對比的方式降低了參與測試人員的評測難度,從而提高了評測結果的客觀性和準確性。我們設計了 50 個問題,涵蓋了 9 個不同的方面,包括:日常問答、書面能力、推理、編程、數學、物理、化學、生物和有害內容檢測。在 16 個模型上進行了這些問題的評估,并采用 Elo 評分系統對測試結果進行了最終的模型得分計算。

評測結果
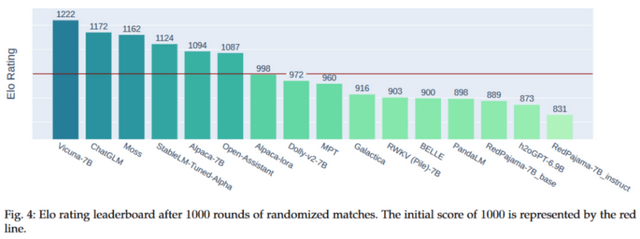
上圖展示了各個模型的 Elo 得分,所有模型的初始 Elo 分數均為 1000,且我們采用了 K 因子為 16 來控制評分的最大波動。在這 16 個模型中,Vicuna-7B 位列榜首,其 Elo 得分高達 1222。ChatGLM 和 Moss 分別位居第二和第三。值得注意的是,從第 7 名到第 15 名的模型,它們的表現相差無幾,都非常接近。從另一個角度看,Elo 評分系統確實具有顯著的區分能力,這意味著各模型在性能上存在著明顯的層次差異。
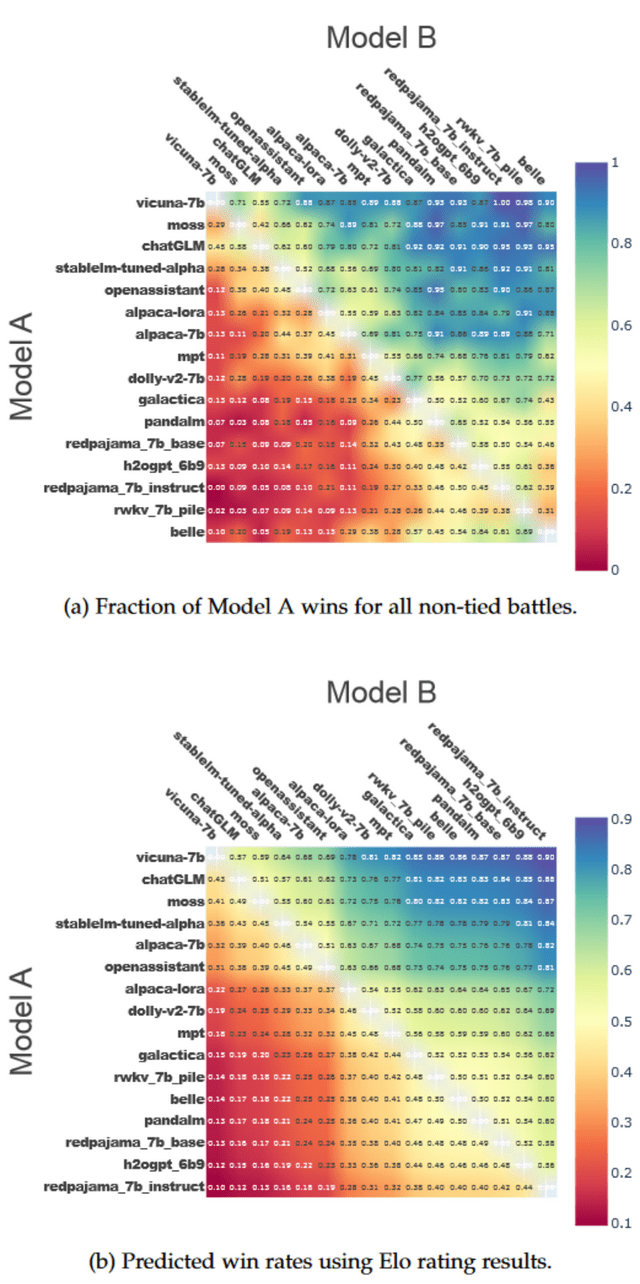
我們還可以利用 Elo 分數來預測模型兩兩之間的勝率。在一定的區間內,Elo 分數每相差 10 分,勝率就會有大約 1.5% 的變化。因此,我們基于 Elo 分數繪制了一對一勝率的熱圖,如圖(b)所示。同時,圖(a)展示了代表各模型間實際勝率的熱圖。顯然,Elo 分數能夠很好地反映模型之間的性能差異。例如,Vicuna-7B 與 ChatGLM 之間大約有 50 分的 Elo 分數差距,而 Vicuna-7B 對 ChatGLM 的勝率為 57%。這與實際勝率 55% 非常接近。

我們展示了不同模型在書寫任務上的例子,排名最高的 Vicuna-7B 無論是在內容上還是在格式上都要顯著地優于其他的方法。為了確認不同評測人員之間回答的一致性,我們隨機選取了 20 個問題進行了人工一致性評測(Human Consistency)。評測指標為 tie-discounted 準確率:當兩名評測人員的答案完全相同時,得 1 分;若其中一名評測人員給出的答案為 tie,則得 0.5 分;兩者答案完全不同則得 0 分。經過評測,我們獲得了 80.02 的一致性得分,這表明不同的評測人員之間的評估標準是大體一致的。
圖文多模態模型
隨著大規模語言模型在自然語言處理領域的大放光彩,越來越多的研究開始探索如何將這些模型與多模態信息融合。在本節中,我們將探討并評估近期一些圖文多模態大語言模型在常見基準上的性能。
模型簡介
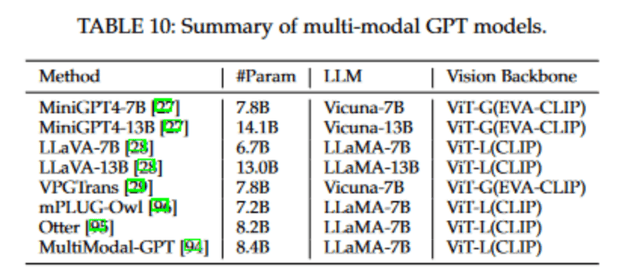
常見的多模態大語言模型一般由三部分組成:視覺編碼器(Vision Encoder)、視覺 - 語言轉換器(Vision-to-Language Converter)和大規模語言模型。視覺編碼器旨在從圖像中提取視覺信息,它通常采用如 CLIP 和 Flamingo 這類視覺 - 語言預訓練模型初始化的 ViT 結構。視覺 - 語言轉換器的作用是將視覺嵌入映射到語言嵌入空間,其設計目的是最大程度地減少視覺和語言之間的模態差異。而大規模語言模型則利用從視覺和語言兩個模態中獲得的信息來生成最終的答案。
評測方式
本節中,我們采用 ScienceQA 數據集來評測多模態模型在科學領域的推理能力。ScienceQA 數據集包含約 2 萬道選擇題,覆蓋了豐富的學科領域。同時,大多數問題提供了相應的知識背景(Context),有助于模型進行思維鏈式推理。評測方式上,我們采用 2-Shot 的實驗設置,即給定兩個示例回答,要求模型根據示例回答給出最終答案。每個問答中,我們給出了問題文本(Q)、背景知識(C)和多個選項內容(M),要求模型給出答案(A)。
實驗結果
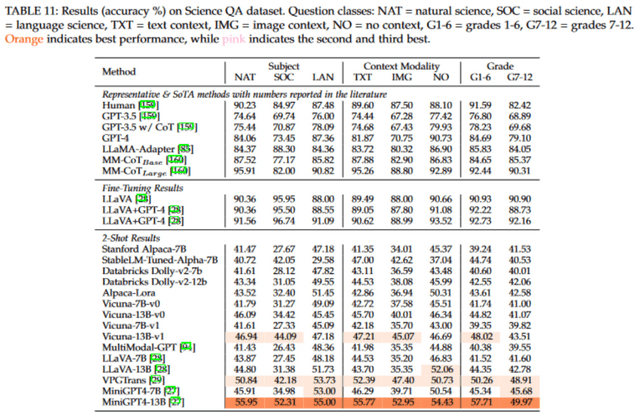
首先,我們對純語言模型和多模態模型在整個測試集上的準確率進行了評估。結果顯示,Vicuna 模型及其微調版本 MiniGPT4 在各自的領域中取得了最好的成果。
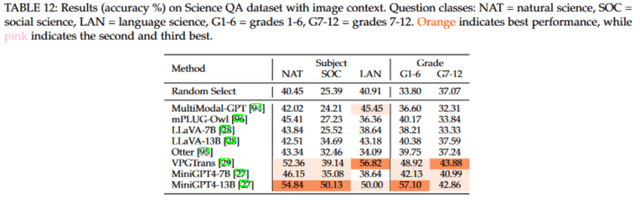
針對測試集中包含圖片的樣本,我們進一步測試了多模態模型的表現。在這方面,基于 Vicuna 的 MiniGPT4 和 VPGTrans 模型在各自的評價指標上分別取得了最好的成績。
科學領域模型
如何將 AI 技術與科學研究相結合是研究的熱點之一。近年來,通過對大規模自然語言模型在特定科學數據集上進行微調,使其更加適應科學研究的需求,已逐漸成為研究的新趨勢,尤其在藥物發現和材料設計等領域。在本節,我們將深入研究 GPT 平替模型在科學研究中的表現,并對其性能進行評估。
評測方式
我們對大規模語言模型在 MedQA、MedMCQA、PubMedQA、NLPEC 和 SciQ 等數據集上進行了評估。特別地,對于 MedQA 數據集,我們還考慮了不同的 few-shot 設置以及不同語言的數據。評估結果主要以準確率為指標進行展示。
在這里,為了探究提示指令對模型性能的影響,我們使用了標準提示指令 “Results with standard prompts” 和模型默認系統指令 “Results with specific system meta instructions” 兩種方式對模型進行了評估。
實驗結果
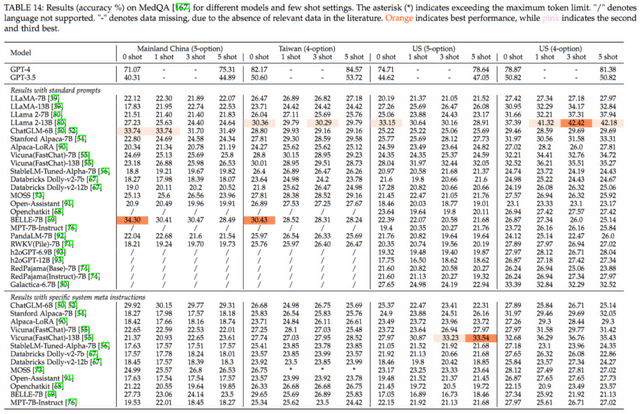
上表展示了各模型在 MedQA 數據集上的表現。得益于數據集的多語言支持,我們對模型在英文、簡體中文和繁體中文三種語言上的性能進行了評估。在中文數據集評測中,ChatGLM-6B 和 BELLE-7B 的表現優于其他模型,其中在 “ 簡體中文(5-Shot)” 和 “ 繁體中文(4-Shot)” 的測試中,準確率分別達到了約 34% 和 30%。這表明,這兩款專為中文語料設計的模型在處理中文問題時具有明顯的優勢。而在英文數據集的評測中,LLaMA 2-13B 的性能尤為突出,其在 “ 英文(5-Shot)” 和 “ 英文(4-Shot)” 的測試中,準確率分別高達約 33% 和 42%。
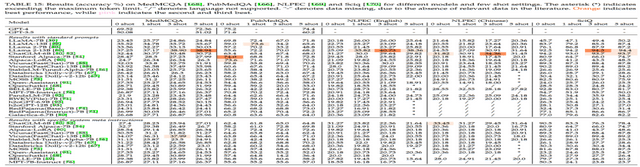
如上表所示,我們使用相同的模型在其他科學領域的數據集上也進行了評估。在 MedMCQA 數據集中,LLaMA 2-13B 和 Vicuna (FastChat)-13B 的表現超過了其他模型。而在 PubMedQA 數據集上,Stanford Alpaca-7B 和 Alpaca-LoRA 的性能尤為突出。在 NLPEC(英語 / 中文)和 SciQ 數據集上,LLama 2-13B 和 ChatGLM-6B 均展現了出色的性能。值得注意的是,在不同的 few-shot 設置中,部分模型的表現有所上升,但也有部分出現了下降,這說明:(1)并非所有模型在與 few-shot 的設置相結合時都一定會有更好的表現;(2) 性能并不一定會隨著 few-shot 實例數量的增加而提高。
此外,對比兩種提示詞設置的結果,我們發現,在使用模型默認系統指令時,某些模型如 Stanford Alpaca-7B、Vicuna (FastChat) 13B、StableLM-Tuned-Alpha-7B 和 Databricks Dolly-v2-7B 展現了更佳的性能。這些模型對指令提示非常敏感,并能有效地利用這些指令優化輸出。然而,也有如 BELLE-7B 這樣的模型,在此設置下并未獲得明顯的性能提升,甚至可能有所下降。
從實驗結果中,我們可以清晰地看到,盡管規模較小的模型(如 6B、7B、13B)在某些任務上表現不錯,但它們在整體數據集上的表現仍然有限,距離達到 100% 或 50% 的準確率還有很長的路要走。這些模型的一個主要限制因素是其參數數量,這直接影響了它們的處理能力和泛化性能。
主要挑戰與發展方向
根據上述的整體調研,以及我們大量的實驗驗證,我們也提出了未來值得注意的發展方向。
1. 實現模型規模與性能之間的平衡,比如探索更高效的模型架構以及輕量化方法;
2. 提高數據的利用效率以減少數據收集和標注的成本;
3. 增強模型的可解釋性;
4. 提高模型的安全性與隱私性;
5. 更加詳細且用戶友好的使用說明。





