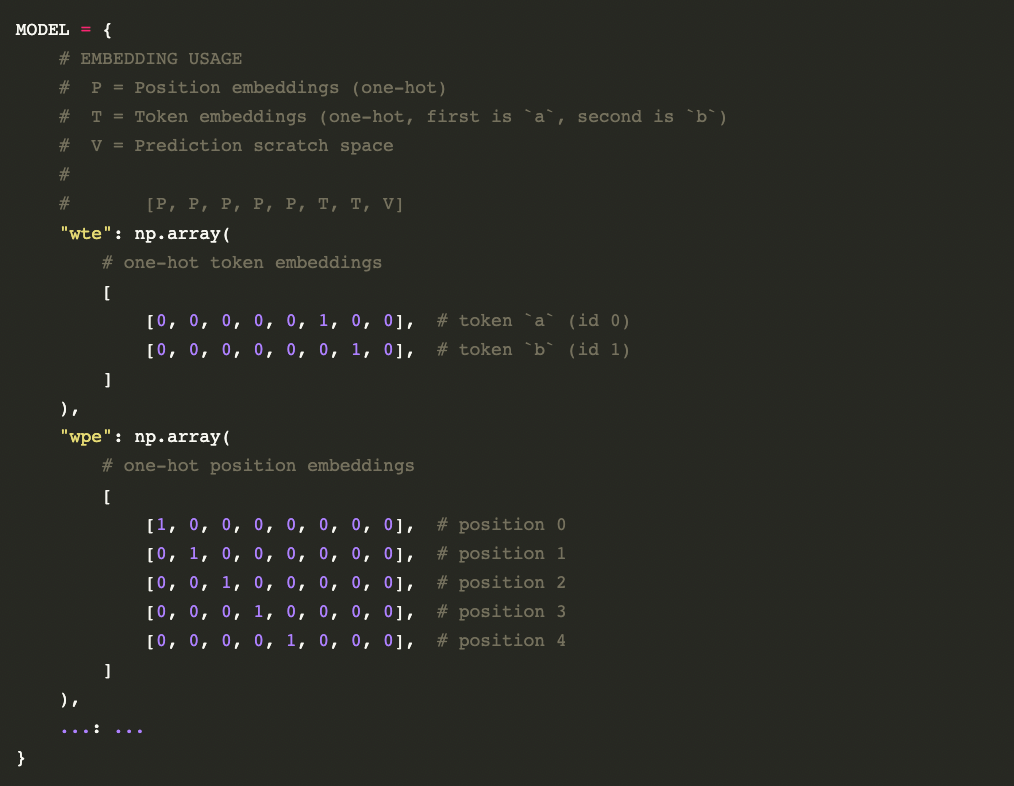
作者 | Theia Vogel
譯者|Ric Guan 責編 | 屠敏
出品 | CSDN(ID:CSDNnews)
幾月前,在挑戰用 46 行 Python/ target=_blank class=infotextkey>Python 寫有符號距離函數(Signed Distance Function)后,我為自己設下了用 500 行 Python 寫一個 C 編譯器的挑戰,那這一次能有多難呢?
事實證明,即便是放棄了相當多的功能,實現起來還是相當困難!但整個過程也非常有趣,而且最終結果出乎意料,非常實用的同時還并不難理解!
由于我的代碼比較多,所以無法在一篇文章中全面涵蓋,因此我將在本篇文章中概述我所做的決定、我必須刪除的內容,以及分享編譯器的總體架構和涉及每部分的代表性代碼。希望讀完這篇文章后,你對我開源的代碼會更容易理解!
Github 地址:https://github.com/vgel/c500/blob/mAIn/compiler.py
找準定位,做決定!
第一個也是最關鍵的決定就是將本次的目標設定為開發一個 Single pass 編譯器(只通過每個編譯單元的各個部分一次,立即將每個代碼部分轉換為其最終的機器代碼)。
500 行對于定義和轉換抽象語法樹來說太富余了!這意味著什么?
大多數編譯器使用語法樹
大多數編譯器的內部結構看起來像這樣:
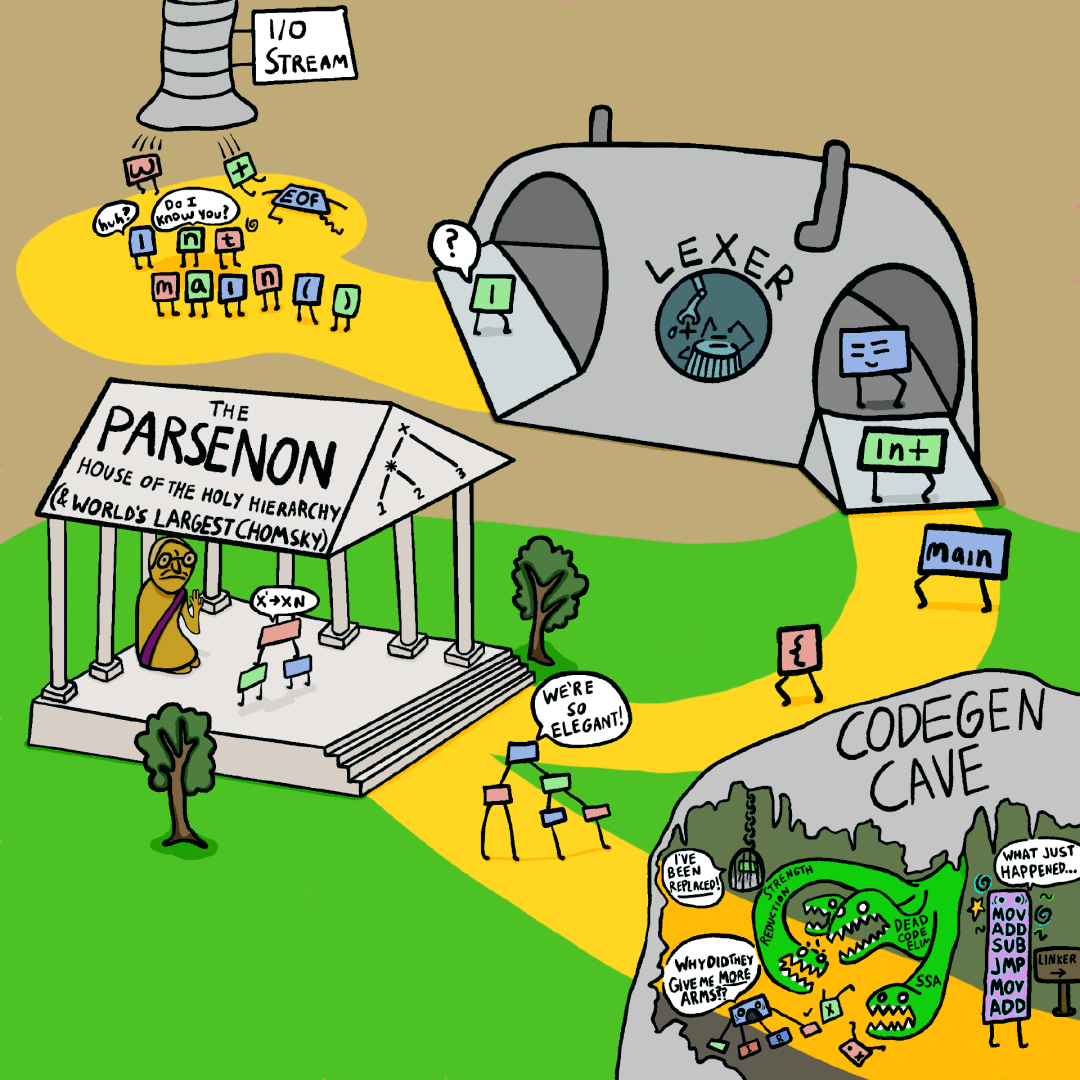
tokens 被詞法分析,然后解析器運行它們并構建相當小的語法樹:

這里重要的是有兩遍編譯 (two-passes):首先解析構建語法樹,然后第二遍通過該樹并將其轉換為機器代碼。
這對于大多數編譯器來說確實很有用!它將解析和代碼生成分開,因此每個都可以獨立發展。這還意味著你可以在使用語法樹生成代碼之前對其進行轉換,例如,通過對其應用優化。事實上,大多數編譯器在語法樹和代碼生成之間都有多個級別的“IR”(中間表示,Intermediate Representation)!
這真的很棒,很好的工程、最佳實踐、專家推薦等等。但是……它需要太多代碼,所以在這里我做不到。
因此,我選擇了挑戰單程編譯器:代碼生成在解析期間發生。我們解析一點,發出一些代碼,再解析一點,發出更多代碼。例如,下面是來自 c500 編譯器的一些實際代碼,用于解析前綴 ~ op:
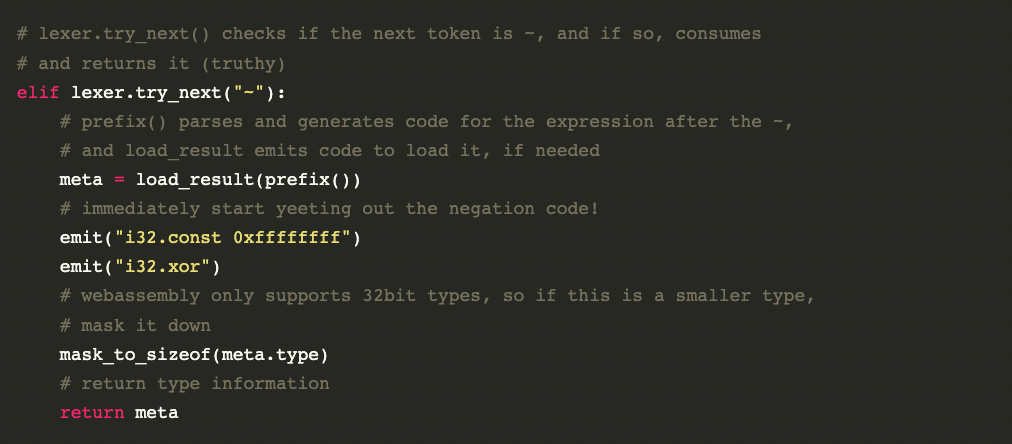
請注意,沒有語法樹,沒有 PrefixNegateOp 節點。我們看到一些token,立即吐出相應的指令。
你可能已經注意到這些指令是基于 WebAssembly 的,這將引導我們進入下一部分......
出于某種原因使用 WebAssembly?
我決定讓編譯器以 WebAssembly 為目標。老實說,我不知道為什么要這么做,這并沒有讓事情變得更容易——我想我只是好奇?
WebAssembly 是一個非常奇怪的目標,尤其是對于 C 語言。一些外部問題讓我感到很困惑,例如在我意識到 WebAssembly v2 與 WebAssembly v1 之間非常不同,除此之外,指令集本身也很奇怪。
其一,沒有 goto。相反,它有塊(結構化匯編,想象一下!)和跳轉到特定嵌套級別塊的開頭或結尾的“中斷”指令。這對于 if 和 while 來說基本上是無關緊要的,但是對于極端詛咒來說,它的實現是非常糟糕的,我們稍后會討論。
此外,WebAssembly 沒有寄存器,它有一個堆棧,并且是一個堆棧結構機器。起初你可能會覺得這很棒,對吧?C需要一個堆棧!我們可以使用 WebAssembly 堆棧作為我們的 C 堆棧!但是不可以,因為你無法引用 WebAssembly 堆棧。因此,我們無論如何都需要維護自己的內存堆棧,然后將其移入和移出 WASM 參數堆棧。
所以最后,我認為我最終得到的代碼比針對 x86 或 ARM 等更普通的 ISA 所需的代碼稍多。但這很有趣!理論上,你可以在瀏覽器中運行用 c500 編譯的代碼,盡管我沒有嘗試過(我只是使用 wasmer CLI)。
處理錯誤
要說 Bug,其實基本上沒有。有一個函數 die,當發生任何奇怪的事情時就會調用它并轉儲編譯器堆棧跟蹤 - 如果幸運的話,會得到一個行號和一條有點模糊的錯誤消息。

該舍棄什么?
最后,我必須決定不支持哪些內容,因為將所有 C 語言放入 500 行是不可行的。我決定想要一個真正像樣的功能樣本,以測試一般實現方法的能力。例如,如果我跳過了指針,我就可以通過 WASM 參數堆棧并擺脫很多復雜性,但這感覺就像作弊。
我最終實現了以下功能:
- 算術運算和二元運算符,具有適當的優先級
- int、short 和 char 類型
- 字符串常量(帶轉義)
- 指針(無論多少層),包括正確的指針算術(遞增 int* 加 4)
- 數組(僅單級,不是 int[][])
- 功能
- typedefs(以及詞法分析器 hack!)
值得注意的是,它不支持:
- 結構,可以使用更多代碼,基礎知識就在那里,我只是無法將其壓縮
- 枚舉(enum)/聯合(union)
- 預處理器指令(這本身可能有 500 行......)
- 浮點。也有可能,wasm_type的東西在里面,又無法將其擠進去
- 8 字節類型(long/long long 或 double)
- 其他一些小事情,例如就地初始化,這些都不太合適
- 任何類型的標準庫或 i/o 不從 main 返回整數
- Casting 表達式
編譯器通過了 c-testsuite 中的 34/220 個測試用例。對我來說更重要的是,它可以成功編譯并運行以下程序。

好了,決定都做完了,讓我們來看看代碼吧!
Helper 類型
編譯器使用一小部分輔助類型和類。它們都不是特別奇怪,所以我會快速地略過它們。
Emitter 類
這是一個單程幫助器,用于發出格式良好的 WebAssembly 代碼。
WebAssembly,至少文本格式,被格式化為 s 表達式,但單個指令不需要加括號:

Emitter 只是幫助發出具有良好縮進的代碼,以便更容易閱讀。它還有一個 no_emit 方法,稍后將用于丑陋的黑客攻擊 - 請繼續關注!
StringPool 類
StringPool 類用于保存所有字符串常量,以便將它們排列在連續的內存區域中,并將地址分配給代碼生成器使用。當你在 c500 中寫 char *s = "abc" 時,真正發生的是:
- StringPool 附加一個空終止符
- StringPool 檢查是否已經存儲了“abc”,如果是,則將地址返回
- 否則,StringPool 將其與基地址 + 到目前為止存儲的總字節長度一起添加到字典中 - 這個新字符串在池中的地址
- StringPool 手回地址
- 當所有代碼完成編譯后,我們使用 StringPool 生成的巨大串聯字符串創建一個 rodata 部分,存儲在字符串池基地址處(追溯性地使 StringPool 分發的所有地址都有效)
Lexer 類
Lexer 類很復雜,因為詞法 C 很復雜 ((\([\abfnrtv'"?]|[0-7]{1,3}|x[A-Fa-f0-9]{1,2 })) 是該代碼中用于字符轉義的真正正則表達式),但概念上很簡單:詞法分析器繼續識別當前位置的token是什么。調用者不僅可以查看該 token,也可以使用 next 告訴詞法分析器前進,“消耗”該 token。它還可以使用 try_next 僅當下一個 token 是某種類型時有條件地前進 - 基本上,try_next 是 if self.peek.kind == token: return self.next( )。
由于所謂的“Lexer Hack (詞法分析器黑客)”,還有一些額外的復雜性。本質上,在解析 C 時,你想知道某個東西是類型名稱還是變量名稱(因為上下文對于編譯某些表達式很重要),但它們之間沒有語法區別:int int_t = 0; 是完全有效的 C,typedef int int_t 也是如此;int_t x = 0;。
要知道任意標記 int_t 是類型名稱還是變量名稱,我們需要將類型信息從解析/代碼生成階段反饋回詞法分析器。對于想要保持其詞法分析器、解析器和代碼生成模塊純凈且獨立的常規編譯器來說,這是一個巨大的痛苦,但實際上對我們來說并不難!
當我們到達 typedef 部分時,我會詳細解釋它,但基本上我們只是在詞法分析器中保留 types: set[str] ,并且在詞法分析時,在給它一個標記類型之前檢查一個標記是否在該集合中:
CType 類
這只是一個用于表示有關 C 類型的信息的數據類,就像在 int **t 或短 t[5] 或 char **t[17] 中編寫的那樣,減去 t。
它包含了:
- 類型的名稱(已解析的任何類型定義),例如 int 或 Short
- 指針的級別是(0 = 不是指針,1 = int *t,2 = int **t,依此類推)
- 數組大小是多少(None = 不是數組,0 = int t[0],1 = int t[1],依此類推)
值得注意的是,如前所述,該類型僅支持單級數組,而不支持像 int t[5][6] 這樣的嵌套數組。
FrameVar 和 StackFrame 類
這些類處理我們的 C 堆棧幀。
正如我之前提到的,因為你無法引用 WASM 堆棧,所以我們必須手動處理 C 堆棧,我們不能使用 WASM 堆棧。
為了設置 C 堆棧,在 __main__ 中發出的前奏設置了一個全局 __stack_pointer 變量,然后每個函數調用都會將該變量減少函數參數和局部變量所需的空間(由該函數的 StackFrame 實例計算)。
當我們開始解析函數時,我將更詳細地介紹該計算的工作原理,但本質上,每個參數和局部變量都會在該堆棧空間中獲得一個槽,并增加 StackFrame.frame_size (從而增加下一個變量的偏移量) 取決于它的大小。每個參數和局部變量的偏移量、類型信息和其他數據都按聲明順序存儲在 StackFrame.variables 中的 FrameVar 實例中。
ExprMeta 類
這個最終數據類用于跟蹤表達式的結果是值還是位置。我們需要跟蹤這種區別,以便根據某些表達式的使用方式以不同的方式處理它們。
例如,如果有一個 int 類型的變量 x,則可以通過兩種方式使用它:
- x + 1 想要對 x 的值(例如 1)進行運算
- &x 想要 x 的地址,比如 0xcafedead
當我們解析 x 表達式時,我們可以輕松地從堆棧幀中獲取地址:
但現在怎么辦?如果我們 i32.load 這個地址來獲取值,那么 &x 將無法獲取該地址。但如果我們不加載它,那么 x + 1 會嘗試將地址加一,結果是 0xcafedeae 而不是 2!
這就是 ExprMeta 的用武之地:我們將地址留在堆棧上,并返回一個 ExprMeta 指示這是一個地方:
然后,對于像 + 這樣總是希望對值而不是位置進行操作的操作,有一個函數 load_result 可以將任何位置轉換為值:

同時,像 & 這樣的操作不會加載結果,而是將地址保留在堆棧上:從重要意義上講,& 在我們的編譯器中是無操作,因為它不發出任何代碼!
另請注意,盡管 & 是一個地址,但它的結果并不是一個地點!(代碼返回 is_place=False 的 ExprMeta。) & 的結果應該被視為一個值,因為 &x + 1 應該向地址添加 1(或者更確切地說,sizeof(x))。這就是為什么我們需要區分位置/值,因為僅僅“作為地址”不足以知道是否應該加載表達式的結果。
好的,關于輔助類就足夠了。讓我們繼續討論 Codegen 的核心部分!
解析和代碼生成
編譯器的一般控制流程是這樣的:
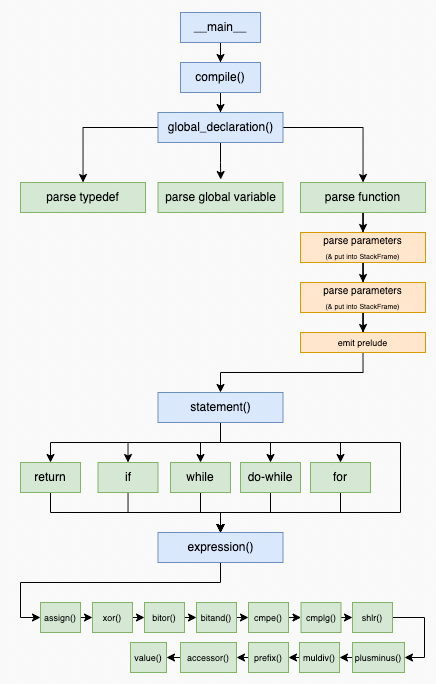
__main__
這一篇非常簡短而且乏味。這是完整的介紹:
顯然我從未完成那個 TODO!這里唯一真正有趣的是 fileinput 模塊,您可能沒有聽說過。從模塊文檔中,
典型用途是:
這會迭代 sys.argv[1:] 中列出的所有文件的行,如果列表為空,則默認為 sys.stdin。如果文件名是“-”,它也會被 sys.stdin 替換,并且可選參數 mode 和 openhook 將被忽略。要指定備用文件名列表,請將其作為參數傳遞給 input。也允許使用單個文件名。
這意味著,從技術上來說,c500 支持多個文件!(如果你不介意它們全部連接起來并且行號混亂:-) fileinput 實際上相當復雜并且有一個 filelineno 方法,我只是出于空間原因沒有使用它。)
compile
compile 是這里第一個有趣的函數,它足夠短,可以逐字包含:

該函數處理發出模塊級前奏。
首先,我們為 WASM VM 發出一個編譯指示以保留 3 頁內存((內存 3)),并將堆棧指針設置為從該保留區域的末尾開始(它將向下增長)。
然后,我們定義兩個堆棧操作助手 __dup_i32 和 __swap_i32。如果您曾經使用過 Forth,這些應該很熟悉:dup 復制 WASM 堆棧頂部的項目 (a -- a a),swap 交換 WASM 堆棧頂部兩個項目的位置 (a b -- b a)。
接下來,我們初始化一個堆棧幀來保存全局變量,使用詞法分析器黑客的內置類型名初始化詞法分析器,并咀嚼全局聲明,直到用完為止!
最后,我們導出 main 并轉儲字符串池。
global_declaration
這個函數太長,無法內聯整個函數,但簽名如下所示:
它處理 typedef、全局變量和函數。
Typedef 很酷,因為這是詞法分析器黑客發生的地方!
我們再一次用了通用的類型名稱解析工具,因為 typedef 繼承了所有 C 奇怪的“聲明反映用法”規則,這對我們來說很方便。(對于困惑的新手來說則不然!)然后我們通知詞法分析器我們發現了一個新的類型名稱,以便將來該標記將被詞法分析為類型名稱而不是變量名稱。
最后,對于 typedef,我們將類型存儲在全局 typedef 注冊表中,使用尾隨分號,然后返回到compile 進行下一個全局聲明。重要的是,我們存儲的類型是一個完整解析的類型,因為如果你這樣做 typedef int* int_p; 然后稍后寫入 int_p *x,x 應該得到 int** 的結果類型 - 指針級別是累加的!這意味著我們不能只存儲基本 C 類型名稱,而是需要存儲整個 CType。
如果聲明不是 typedef,我們將解析變量類型和名稱。如果我們找到一個 ; token 我們知道它是一個全局變量聲明(因為我們不支持全局初始值設定項)。在這種情況下,我們將全局變量添加到全局堆棧幀和 bail 中。
然而,如果沒有分號,我們肯定正在處理一個函數。要生成函數代碼,我們需要:
- 為該函數創建一個新的StackFrame,命名為frame
- 然后,解析所有參數并將它們存儲在框架中:frame.add_var(varname.content, type, is_parameter=True)
- 之后,使用variable_declaration(lexer,frame)解析所有變量聲明,這會將它們添加到frame中
- 現在我們知道函數的堆棧幀需要有多大(frame.frame_size),所以我們可以開始發出前奏!
- 首先,對于堆棧幀中的所有參數(使用 is_parameter=True 添加),我們生成 WASM 參數聲明,以便可以使用 WASM 調用約定來調用該函數(在 WASM 堆棧上傳遞參數):
然后,我們可以為返回類型發出結果注釋,并調整 C 堆棧指針以為函數的參數和變量騰出空間:
對于每個參數(按相反順序,因為堆棧),將其從 WASM 堆棧復制到我們的堆棧:
最后,我們可以在循環中調用statement(lexer,frame)來代碼生成函數中的所有語句,直到我們到達右括號:
額外步驟:我們假設函數總是有返回值,因此我們發出(“unreachable”),這樣 WASM 分析器就不會崩潰。
很多內容,但這就是函數的全部內容,因此也是 global_declaration 的全部內容,所以讓我們繼續討論 statements。
statement
statements 中有很多代碼。然而,其中大部分內容相當重復,因此我將只解釋 while 和 for,這應該可以提供一個很好的概述。
還記得 WASM 沒有跳轉,而是有結構化控制流嗎?現在這很重要。
首先我們來看看它是如何與 while 配合使用的,在那里并不會太麻煩。WASM 中的 while 循環如下所示:
正如所看到的,有兩種類型的塊 - 塊和循環(還有 if 塊類型,我沒有使用)。每個語句都包含一定數量的語句,然后以 end 結束。在塊內,可以使用 br 進行中斷,或者使用 br_if 有條件地基于 WASM 堆棧的頂部(還有 br_table,我沒有使用它)。
br 系列采用 labelidx 參數,此處為 1 或 0,表示操作適用于哪個級別的塊。因此,在我們的 while 循環中,br_if 1 適用于外部塊 - 索引 1,而 br 0 適用于內部塊 - 索引 0。(索引始終相對于相關指令 - 0 是該指令的最內層塊 .)
最后,要知道的最后一個規則是塊中的 br 向前跳轉到塊的末尾,而循環中的 br 向后跳轉到循環的開頭。
希望現在再看一遍更易懂一些:

在更正常的裝配中,這對應于:
但是通過跳躍,您可以表達在 WASM 中無法(輕松)表達的內容 - 例如,您可以跳到塊的中間。
(這主要是編譯C的goto的問題,我什至沒有嘗試過——有一種算法可以將任何使用goto的代碼轉換為使用結構化控制流的等效程序,但它很復雜,我認為它行不通 使用我們的單遍方法。)
但對于 while 循環來說,這還不算太糟糕。我們所要做的就是:

但對于 for 循環,它會變得令人討厭。考慮這樣的 for 循環:
詞法分析器/代碼生成器看到 for 循環各部分的順序是:
但為了使用 WASM 的結構化控制流,我們需要將它們放入代碼中的順序是:

請注意,生成的代碼中 3 和 4 被反轉,順序為 1、2、4、3。這對于單遍編譯器來說是一個問題!與普通編譯器不同,我們無法存儲高級語句以供以后使用。或者……我們可以嗎?
我最終處理這個問題的方法是使詞法分析器可克隆,并在解析正文后重新解析進度語句。本質上,代碼如下所示:

正如所看到的,技巧是保存詞法分析器,然后使用它返回并稍后處理高級語句,而不是像普通編譯器那樣保存語法樹。不是很優雅——編譯 for 循環可能是編譯器中最粗糙的代碼——但它工作得足夠好!
statements 的其他部分大多相似,因此我將跳過它們以了解編譯器的最后一個主要部分 — expression。
expression
expression 是編譯器中的最后一個大方法,如您所料,它處理解析表達式。它包含許多內部方法,每個優先級都有一個方法,每個方法返回前面描述的 ExprMeta 結構(處理“位置與值”的區別,并且可以使用 load_result 將其轉換為值)。
優先級堆棧的底部是 value (命名有些令人困惑,因為它可以返回 ExprMeta(is_place=True, ...))。它處理常量、括號表達式、函數調用和變量名。
除此之外,優先級的基本模式是這樣的函數:

事實上,這種模式是如此一致,以至于大多數操作(包括 muldiv)都不會寫出來,而是由高階函數 makeop 定義:

只有少數具有特殊行為的操作需要顯式定義,例如需要處理 C 指針數學的細微差別的 plusminus。
就是這樣!這是編譯器的最后一個主要部分。
總結
這就是我挑戰在 500 行 Python 中的 C 編譯器之旅!編譯器以復雜而聞名——GCC 和 Clang 非常龐大,甚至 TCC(Tiny C 編譯器)也有數萬行代碼——但如果你愿意犧牲代碼質量并一次性完成所有工作,它的代碼量也可以非常少!
我很想知道你是否編寫過自己的單程編譯器——也許是針對自定義語言?我認為這種編譯器可能成為自托管語言的一個很好的階段,因為它非常簡單。