
在互聯網快速發展的今天,我們見證了現代數據庫從結構化數據庫(比如:MySQL)到 NoSQL(比如:redis),再到大型的分布式數據庫(比如:Apache Cassandra),數據庫之所以可以如此快速的發展,離不開這 8種關鍵的數據結構,如下圖:
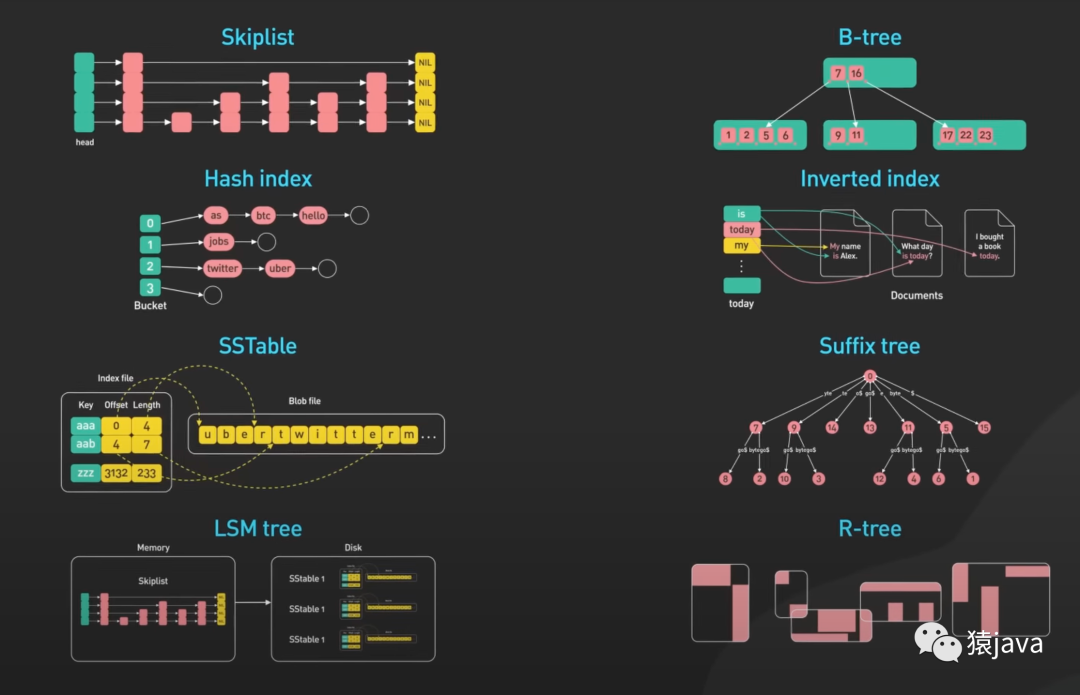
因此,今天我們就來聊一聊這 8種數據結構。
一、Skiplist
Skip List(跳表)是一種基于鏈表的數據結構,用于快速查找和插入操作。它是由William Pugh于 1989 年提出的,類似于平衡二叉樹,但相對于平衡二叉樹而言,跳表的實現更簡單且容易理解,因此它是平衡樹的替代品。
原理
- 跳表節點結構:每個跳表節點包含一個鍵(key)和一個值(value),以及多個指向下一層節點的指針(forward pointers)。節點按照鍵的遞增順序連接在一起,形成一種層級結構。
- 層級結構:跳表中的節點按照層級連接,最底層是一個普通的有序鏈表。每個節點都有一個或多個指針指向下一層節點,這些指針稱為前進指針(forward pointers)。通常,節點的層數是隨機生成的,層數越高,節點在跳表中的概率越小。
- 查找操作:從頂層開始,逐層比較節點的鍵和目標鍵的大小,如果當前節點的下一個節點的鍵大于目標鍵,則向下一層移動。重復這個過程直到找到目標鍵或者無法繼續向下移動為止。一般來說,查找操作的時間復雜度為O(log n)。
- 插入操作:插入操作需要首先執行查找操作,以找到插入位置。然后,為新節點生成一個隨機的層數,將新節點插入到每一層的合適位置,并更新相關節點的前進指針。插入操作的時間復雜度也是O(log n)。
- 刪除操作:刪除操作與查找操作類似,首先執行查找操作找到待刪除的節點。然后,將待刪除節點從每一層中移除,并更新相關節點的前進指針。刪除操作的時間復雜度也是O(log n)。
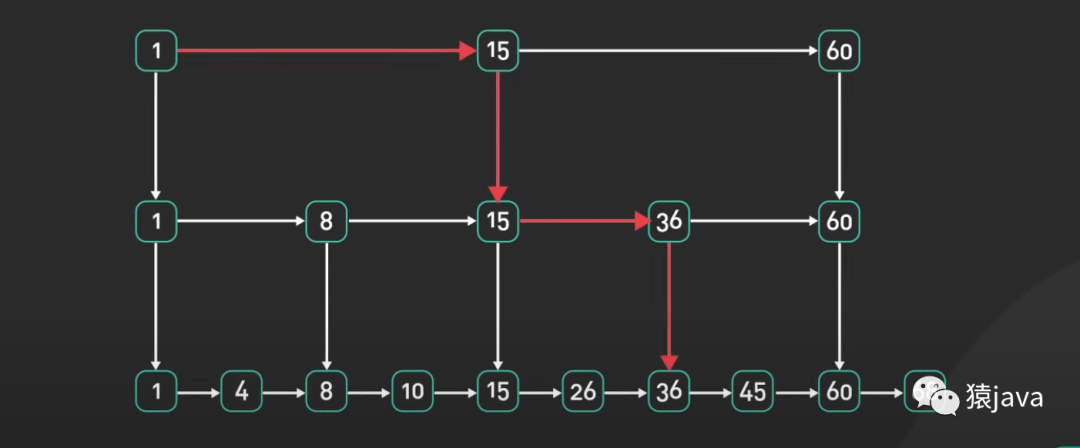
跳表通過增加多個層級和前進指針的方式,提供了一種平衡的查找和插入性能。相較于平衡二叉樹,跳表的實現更簡單,且不需要維護復雜的平衡條件。如下圖,給出一張跳表的示例圖:
優缺點
跳表的優勢在于其相對簡單的實現和較高的查詢性能。對于有序鏈表的查找操作,跳表平均時間復雜度為O(log n),接近于平衡樹的性能,而且在實際應用中比平衡樹更加容易實現和維護。然而,跳表的插入和刪除操作的平均時間復雜度較高,為O(log n),相比于鏈表的O(1)操作略慢。
數據庫實例
在 Redis這種內存數據庫中,跳表用于實現有序數據結構,例如排序集和排序列表。
二、B-tree
B-tree(平衡樹)是一種常用的自平衡搜索樹,廣泛應用于數據庫系統和文件系統等領域,用于高效地組織和管理大量有序的數據。B-tree的原理如下:
原理
- 結構組成:B-tree由一個根節點、一系列的內部節點和葉子節點組成的多層樹結構。每個節點包含一個鍵值列表和對應的子節點指針。內部節點的鍵值用于確定子節點的范圍,葉子節點存儲實際的數據。
- 平衡性:B-tree的特點之一是保持樹的平衡性,即所有葉子節點具有相同的深度。通過保持樹的平衡,可以確保在最壞情況下,對數據的查找、插入和刪除操作具有良好的性能。
- 范圍查詢:B-tree支持范圍查詢,即查找滿足給定范圍條件的數據。查詢從根節點開始,根據給定的范圍條件選擇相應的子節點。逐層向下遍歷子節點,根據子節點的鍵值范圍進一步選擇子節點,直到到達葉子節點。在葉子節點中,按順序檢查每個鍵值是否滿足范圍條件,并返回符合條件的數據。
- 插入操作:插入數據時,B-tree先進行查找操作,找到應該插入的葉子節點。如果葉子節點未滿,可以直接插入新的鍵值。如果葉子節點已滿,則進行節點分裂操作。將當前節點的鍵值分成兩個部分,左邊的部分保留在當前節點,右邊的部分形成一個新的葉子節點。同時,將分裂點的鍵值插入到父節點中,并調整父節點的指針。
- 刪除操作:刪除數據時,B-tree首先進行查找操作,找到要刪除的鍵值所在的葉子節點。如果葉子節點中存在該鍵值,則直接刪除。如果刪除后葉子節點的鍵值數量低于最小閾值,可以進行一些修復操作,如兄弟節點的合并或重新分配鍵值。
下面給了一張B-tree 和 一張 B+tree 的示例圖:
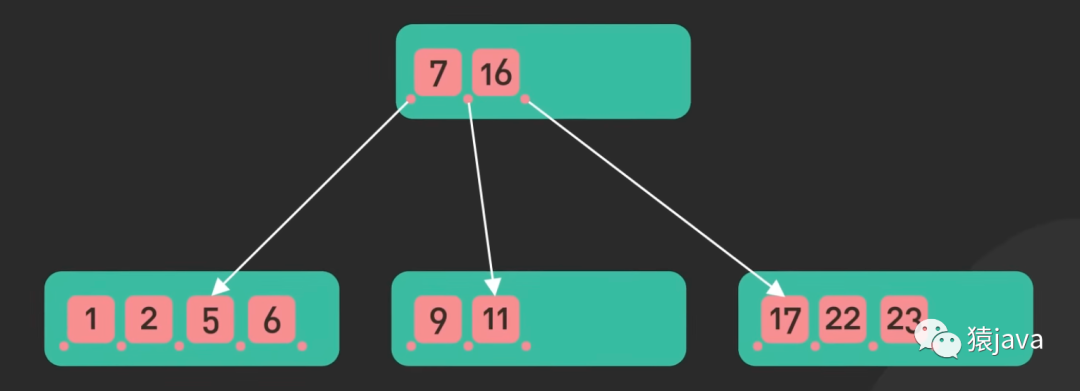
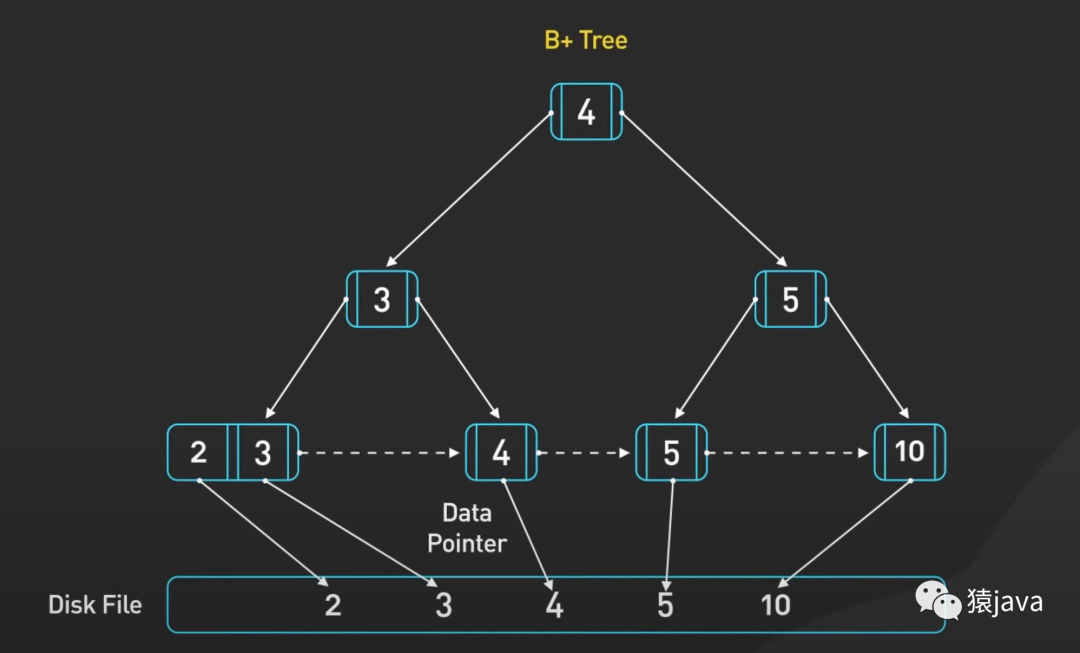
優缺點
B-tree的優點在于它對有序數據的高效組織和檢索能力,能夠在平衡性和高性能之間取得良好的平衡。它被廣泛應用于數據庫系統、文件系統和其他需要高效搜索和索引的場景中。B-tree的變種形式,如B+樹和B*樹,進一步優化了查詢性能和磁盤訪問效率,使其適用于處理大規模數據和支持范圍查詢等更復雜的操作。
數據庫實例
在 MySQL 的InnoDB 引擎就是使用 B+Tree實現索引機制,Postgres 和 Oracle數據也是用B-Tree 來處理大量磁盤數據。
三、Hash index
哈希索引(Hash Index)是一種常用的索引結構,它通過哈希函數將索引鍵映射到索引桶(或槽)中,以實現快速的查找和訪問。
原理
- 哈希函數:哈希索引利用哈希函數將索引鍵轉換為一個固定長度的哈希值。哈希函數應該具備以下特點:快速計算、均勻分布、無沖突。
- 索引桶:哈希索引將所有可能的哈希值范圍劃分為多個索引桶。每個索引桶中存儲了具有相同哈希值的索引鍵所對應的數據位置(如磁盤地址或內存地址)。
- 哈希沖突處理:由于哈希函數的輸出范圍可能小于實際的鍵值范圍,因此會出現哈希沖突的情況,即不同的鍵經過哈希函數得到相同的哈希值。常見的哈希沖突處理方法包括拉鏈法(ChAIning)和開放尋址法(Open Addressing)。
- 拉鏈法:每個索引桶中維護一個鏈表(或其他數據結構),將哈希值相同的鍵值對鏈接在一起。當發生哈希沖突時,新的鍵值對可以添加到鏈表的末尾。
- 開放尋址法:當發生哈希沖突時,繼續探測其他索引桶,直到找到一個空閑的索引桶。常見的探測方法有線性探測、二次探測、雙重哈希等。
- 查找操作:對于查找操作,首先使用哈希函數計算給定索引鍵的哈希值,然后根據哈希值找到對應的索引桶。如果存在哈希沖突,則按照哈希沖突處理的方法進行搜索,直到找到目標鍵值對或者確定不存在。
- 插入操作:插入操作也需要使用哈希函數計算待插入鍵的哈希值,并找到對應的索引桶。根據哈希沖突處理的方法,將鍵值對插入到索引桶中的合適位置。
- 刪除操作:刪除操作類似于查找操作,根據哈希值找到對應的索引桶,然后在該索引桶中搜索目標鍵值對,并進行刪除。
如下圖,給出兩張hash index的示例圖:
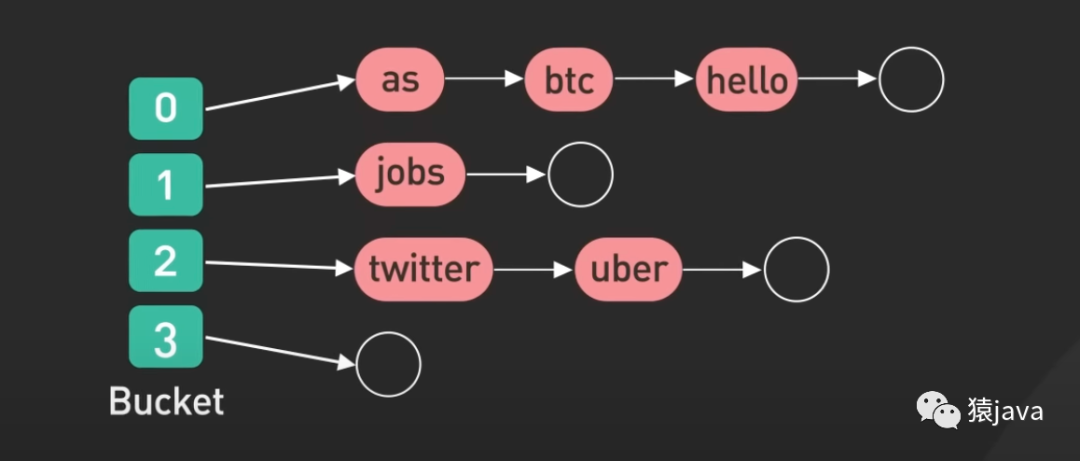
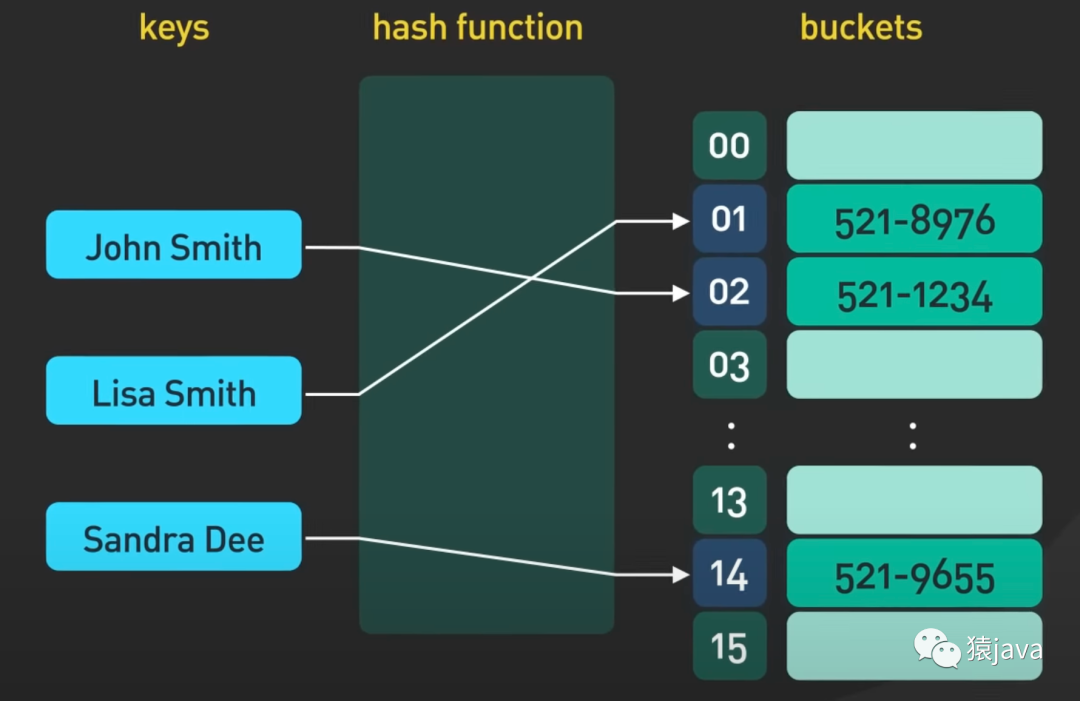
優缺點
優點:
- 快速查找:哈希索引通過哈希函數的映射,可以快速計算出目標鍵值對所在的索引桶,從而加快查找速度。
- 常數時間復雜度:在理想情況下,哈希索引的查找操作只需要常數時間復雜度O(1),即使在大數據集中也能保持較快的查詢速度。
- 適合等值查找:哈希索引主要用于等值查找,對于需要精確匹配的查詢非常高效。
缺點和局限性:
- 哈希沖突:由于哈希函數的輸出范圍有限,不同的鍵可能映射到相同的哈希值,導致哈希沖突。哈希沖突會影響查找性能,需要采用合適的哈希沖突處理方法,如拉鏈法或開放尋址法。
- 不支持范圍查詢:哈希索引只適用于等值查找,無法直接支持范圍查詢。范圍查詢需要遍歷整個索引,效率較低。
- 哈希函數的選擇:選擇合適的哈希函數非常重要,一個好的哈希函數應具備均勻分布、快速計算和最小化沖突等特點,否則可能導致較多的哈希沖突,降低索引性能。
- 內存占用:哈希索引需要維護額外的索引結構,包括哈希桶和指針,相對于原始數據的存儲,會占用更多的內存空間。
數據庫實例
hash index 無處不在,它可以用來實現像 Redis 中的 Hashes 這樣的哈希數據結構。
四、Inverted index
Inverted Index(倒排索引)是一種常用的索引結構,用于實現全文搜索和快速的關鍵詞檢索。它將文檔集合中的每個單詞或關鍵詞映射到包含該單詞的文檔列表,以支持高效的倒排查找。
原理
- 文檔收集:首先需要收集要建立索引的文檔集合。文檔可以是一篇文章、一本書或者是網頁等,每個文檔都有一個唯一的標識符,如文檔ID。
- 分詞處理:對于每個文檔,需要進行分詞處理。分詞將文本劃分為一個個單詞或關鍵詞,去除停用詞(如“的”、“是”等)和標點符號,對詞根進行處理(如詞干提取、詞形還原等),以獲取關鍵詞集合。
- 構建倒排索引:對于每個關鍵詞,構建倒排索引表。倒排索引表中的每一項包含一個關鍵詞和包含該關鍵詞的文檔列表。文檔列表中記錄了包含該關鍵詞的文檔ID或其他相關信息。倒排索引表按照關鍵詞的字典序排列。
- 查詢操作:當進行查詢時,將查詢的關鍵詞進行分詞處理,然后在倒排索引表中查找對應的關鍵詞。根據倒排索引表中的文檔列表,可以快速找到包含查詢關鍵詞的文檔集合。
- 結果排序:根據查詢的相關性,對匹配的文檔進行排序,以確定搜索結果的排名。相關性可以根據不同的算法和評分模型進行計算,如TF-IDF、BM25等。
下面給出了一張Inverted index的示例圖:
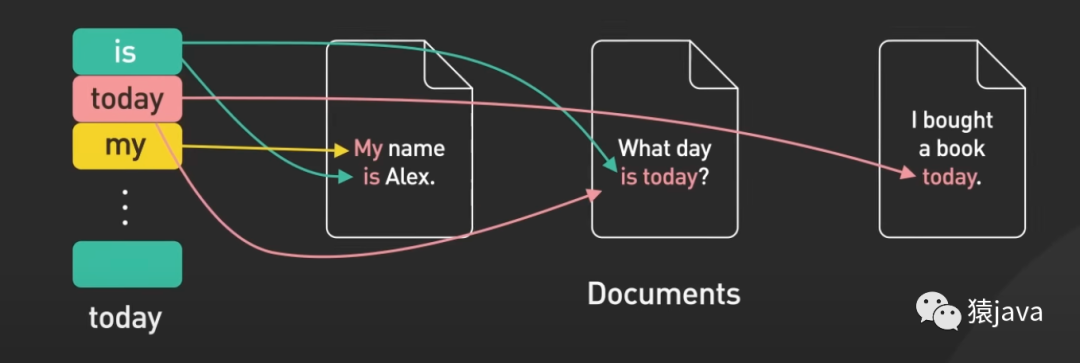
優缺點
倒排索引的優點是可以快速定位包含特定關鍵詞的文檔,適用于全文搜索和關鍵詞檢索場景。它具有較高的查詢效率,能夠快速過濾不相關的文檔,提供精確的搜索結果。同時,倒排索引支持動態更新,可以方便地添加、刪除或修改文檔。
然而,倒排索引也有一些局限性,如占用較多的存儲空間,需要維護索引結構和更新索引等。為了解決這些問題,通常會采用壓縮技術、索引合并和分布式索引等策略來提高存儲效率和查詢性能。
總結起來,倒排索引通過將關鍵詞映射到包含該關鍵詞的文檔列表,實現了高效的全文搜索和關鍵詞檢索
數據庫實例
倒排索引最典型的使用就是 ElasticSearch,用于全文檢索。
五、SSTable
SSTable(Sorted String Table)是一種常用的存儲結構,用于實現高效的鍵值存儲和檢索。它是 google 的 Bigtable 論文中提出的一種數據結構,是 LSM-tree的核心組件。
原理
- 數據排序:SSTable中的數據按照鍵的有序排列,通常以字典序為準。這樣做的好處是可以支持范圍查詢和快速查找。數據排序可以在內存中進行,也可以在寫入時進行排序。
- 數據存儲:SSTable將有序的鍵值對按照一定的規則存儲到磁盤上的文件中。每個文件包含多個數據塊(Data Block),每個數據塊包含多個鍵值對。
- 索引結構:為了快速定位數據塊和具體的鍵值對,SSTable維護了一個索引結構,通常稱為Block Index或Data Block Index。索引中存儲了每個數據塊的起始位置、結束位置和該塊中最小鍵值對的鍵。
- 寫入操作:當寫入一個新的鍵值對時,首先會將鍵值對追加到內存中的MemTable中(通常是跳表或紅黑樹等數據結構)。當MemTable達到一定大小后,會觸發數據的刷寫操作。將MemTable中的鍵值對按照鍵的順序寫入到磁盤上的SSTable文件中,并更新索引結構。
- 讀取操作:當執行讀取操作時,首先在內存中的MemTable中查找鍵值對。如果未找到,則依次在磁盤上的SSTable文件中的索引結構中進行查找,定位到對應的數據塊,然后在該數據塊中進行查找具體的鍵值對。
- 合并操作:為了減少SSTable文件數量和提高讀取性能,周期性地執行合并操作。合并操作將多個SSTable文件合并成一個更大的文件,同時更新索引結構。合并時會進行去重和排序操作,以消除重復的鍵和更新過期的鍵。
下面給出了一張 SSTable 的示例圖:
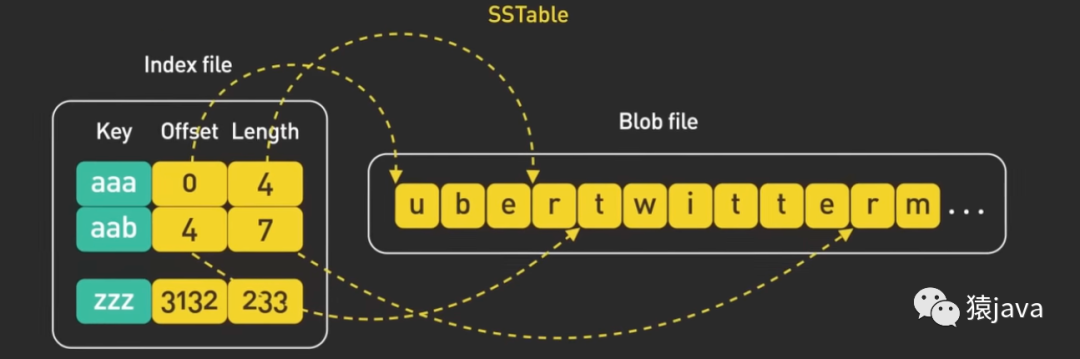
優缺點
SSTable的優點是具有高效的查詢性能和壓縮存儲,適用于讀多寫少的場景。由于數據有序存儲,支持范圍查詢和快速查找。此外,SSTable還支持持久化存儲和數據恢復,即使在系統故障或重啟后也能保持數據的完整性。
SSTable也有一些局限性,如合并操作可能會引起寫放大(Write Amplification)問題,當需要合并的文件過多時,會影響性能。為了解決這個問題,可以采用類似于LevelDBLevelDB等SSTable實現的系統采用了多層次的SSTable結構,如Level-0、Level-1、Level-2等,通過不同的層次來解決寫放大的問題。具體的機制如下:
- 層次結構:LevelDB等系統通常采用多層次的SSTable結構。Level-0是最底層的SSTable,數據按照寫入的順序存儲,并且不進行合并操作。Level-1及以上的層次則是合并Level-0層的SSTable文件得到的新SSTable文件。
- 合并策略:合并操作在不同的層次上執行,每個層次都有自己的合并策略。通常,Level-0的合并操作由后臺線程異步執行,目的是將多個小的SSTable文件合并為一個較大的SSTable文件,減少文件數量。而Level-1及以上的合并操作由前臺線程同步執行,以控制合并的規模和頻率。
- 劃分文件大小:不同層次的SSTable文件有不同的大小限制。通常,Level-0的文件較小,可以存儲較少的數據;而隨著層次的增加,文件的大小逐漸增大。這樣做的目的是確保在合并操作時,每個層次的文件規模適中,不會導致過大的寫放大問題。
- 基于時間和大小的觸發條件:合并操作的觸發可以基于時間和文件大小兩個條件。根據時間條件,可以設置合并操作的觸發間隔,如每隔一段時間執行一次合并;根據大小條件,可以設置Level-0中SSTable文件的最大大小,當文件達到閾值時觸發合并操作。
通過多層次的SSTable結構和合并策略,LevelDB等系統能夠平衡寫放大和查詢性能。較小的Level-0文件數量減少了寫放大的問題,同時較大的Level-1及以上文件減少了查詢時需要掃描的SSTable文件數量,提高了讀取性能。這種層次結構和合并策略的設計使得LevelDB等系統適用于高效的鍵值存儲和檢索場景。
數據庫實例
SSTable 被廣泛應用于多個系統中,如LevelDB、RocksDB等。
六、LSM-Tree
LSM-Tree(Log-Structured Merge Tree)是一種常用的數據結構,用于實現高效的鍵值存儲和檢索。它將寫入操作與合并操作分離,通過將數據寫入日志文件和內存緩存,然后定期進行合并操作來提高寫入和查詢的性能。
原理
(1) 寫入操作:
- 寫入日志文件(Write-Ahead Log, WAL):當有新的鍵值對需要寫入時,首先將其追加到順序寫的日志文件中。這個操作稱為寫前日志(Write-Ahead Logging),它可以確保數據的持久性和一致性。
- 寫入內存緩存(Memtable):同時將新的鍵值對寫入內存中的數據結構,通常是跳表或紅黑樹等有序數據結構。內存緩存可以快速響應讀取操作,并且具有較高的寫入性能。
(2) 合并操作:
- 內存與磁盤的合并(Memtable to SSTable):當內存緩存達到一定大小或者其他觸發條件滿足時,將內存緩存中的鍵值對寫入到磁盤上的SSTable(Sorted String Table)文件中,通常以一種有序的方式進行存儲。
- SSTable的合并:定期或根據其他策略執行SSTable文件的合并操作。合并操作將多個SSTable文件進行合并,消除重復鍵和更新過期鍵,并生成新的SSTable文件。合并操作可以基于時間、文件大小或其他條件進行觸發和控制。
(3) 查詢操作:
- 內存緩存查詢:首先在內存緩存中查找鍵值對,由于內存緩存是有序的,可以快速定位。
- 磁盤上的SSTable查詢:如果在內存緩存中未找到,則依次在磁盤上的SSTable文件中進行查找,通常采用二分查找等算法進行快速定位和檢索。
下面給出了一張 LSM-tree的示例圖:

優缺點
LSM樹的優點是具有較高的寫入性能和壓縮存儲,適用于寫多讀少或寫入速度較快的場景。通過將寫入操作集中在內存和順序寫的日志文件中,可以獲得較高的寫入吞吐量。查詢性能也較好,通過內存緩存和有序的SSTable文件,可以快速定位和檢索鍵值對。
然而,LSM樹也有一些局限性,如讀取操作可能需要掃描多個SSTable文件,導致查詢性能不如B樹等結構穩定。此外,合并操作可能會引起較長的停頓時間,對于實時性要求較高的系統可能會有影響。為了解決這些問題,LSM樹引入了一些優化技術,如布隆過濾器和層級結構。
- 布隆過濾器(Bloom Filter):LSM樹中的每個SSTable文件可以關聯一個布隆過濾器。布隆過濾器是一種高效的概率型數據結構,用于快速判斷某個鍵是否存在于SSTable文件中,從而避免不必要的磁盤訪問。布隆過濾器可以在非常低的誤判率下,快速準確地判斷某個鍵是否可能存在于SSTable文件中。
- 層級結構:LSM樹通常包含多個層級,如Level-0、Level-1、Level-2等。Level-0是內存緩存和日志文件,Level-1及以上是磁盤上的SSTable文件。較小的層級(如Level-0)通常用于高頻的寫入操作,較大的層級(如Level-1及以上)用于存儲穩定的數據。通過層級結構,可以減少查詢時需要掃描的SSTable文件數量,提高讀取性能。
- 壓縮和合并策略:LSM樹可以采用不同的壓縮算法和合并策略來優化存儲和性能。例如,可以使用壓縮算法對SSTable文件進行壓縮,減少磁盤占用空間。合并策略可以根據不同的觸發條件和優先級,靈活地控制合并操作的頻率和規模,以平衡寫入性能和查詢性能。
數據庫實例
LSM-tree 是 Apache Cassandra、RocksDB 和 LevelDB 等流行的 NoSQL 數據庫的支柱。
七、Suffix tree
Suffix Tree(后綴樹)是一種用于處理字符串的數據結構,它能夠高效地存儲一個字符串的所有后綴,并支持快速的子串匹配和搜索操作。
原理
- 構建樹結構:Suffix Tree是由一個根節點和一系列的內部節點和葉子節點組成的樹結構。根節點沒有入邊,每個內部節點代表一個非空字符串的前綴,葉子節點代表原始字符串的后綴。每個節點通過邊連接,邊上的標記代表了字符串的字符。
- 后綴鏈接(Suffix Link):為了提高構建和搜索的效率,Suffix Tree中的每個內部節點都可以包含一個后綴鏈接,指向具有相同前綴的下一個內部節點。后綴鏈接能夠在搜索過程中跳躍到下一個具有相同前綴的位置,加速匹配操作。
- 自動構建:Suffix Tree的構建算法使用了稱為Ukkonen算法的在線構建方法。它通過逐步將字符添加到樹中來構建樹結構,而不是一次性將整個字符串添加進去。Ukkonen算法的核心思想是通過在樹的每一步添加新字符,不斷擴展現有的節點或添加新的節點,同時維護后綴鏈接,以保持樹的正確性。
- 字符串匹配:通過Suffix Tree可以高效地進行子串匹配和搜索操作。給定一個模式字符串,可以從根節點開始,依次匹配模式中的字符,并沿著相應的邊移動。如果無法匹配當前字符,則搜索失敗;如果成功匹配,則繼續匹配下一個字符,直到匹配完成。這樣可以在時間復雜度為O(m)的情況下完成匹配,其中m是模式字符串的長度。
下面給出了一張 Suffix-tree的示例圖:
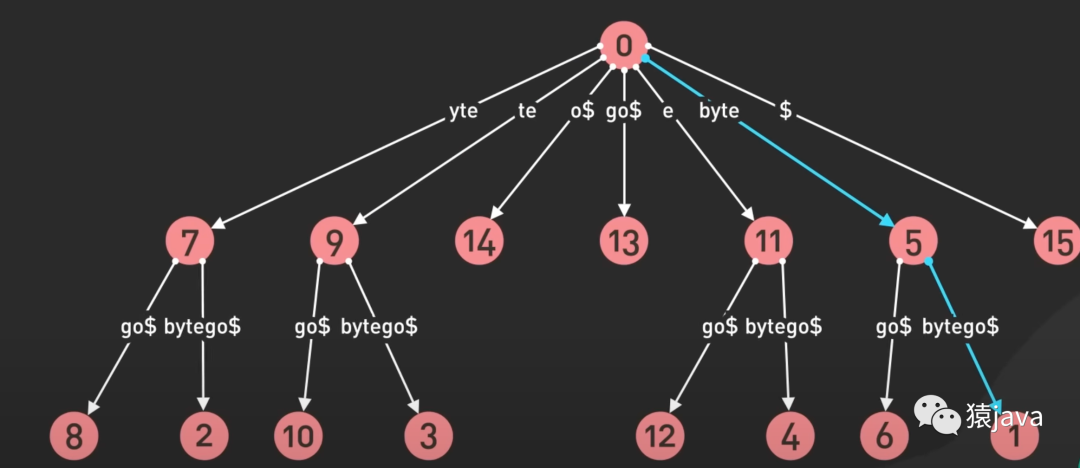
優缺點
Suffix Tree是一種非常強大和高效的數據結構,可以用于解決各種字符串處理問題,如子串查找、最長公共子串、重復子串等。它在文本搜索、基因組學、自然語言處理等領域都有廣泛的應用。然而,構建Suffix Tree的算法相對復雜,需要高效的實現才能處理大規模的字符串。因此,一些改進的變體如Suffix Array和壓縮后綴樹也得到了廣泛的研究和應用。
數據庫實例
PostgreSQL、Apache Lucene 和 Elasticsearch、Riak
八、R-tree
R-tree是一種常用的數據結構,用于高效地組織和檢索多維空間數據,特別是用于范圍查詢和最近鄰查詢。
原理
- 結構組成:R-tree是由一個根節點和一系列的內部節點和葉子節點組成的樹結構。每個節點代表一個矩形區域,內部節點的矩形區域覆蓋了其子節點的矩形區域,而葉子節點代表了具體的數據對象和其對應的矩形區域。
- 節點的填充和分裂:為了保持樹的平衡和高效性能,R-tree在節點的填充和分裂時采用一些策略。節點的填充策略使得節點盡可能充滿數據對象,避免空間浪費。當節點無法再容納新的數據對象時,節點將會被分裂成兩個更小的節點,以容納新的數據對象。
- 范圍查詢:R-tree支持范圍查詢,即查找所有與給定查詢矩形區域相交的數據對象。查詢從根節點開始,逐層向下遍歷,對于每個遇到的節點,檢查該節點的矩形區域是否與查詢區域相交。如果相交,則繼續向下遍歷其子節點;如果不相交,則跳過該節點及其子節點。通過這種方式,可以逐步縮小搜索范圍,找到所有滿足查詢條件的數據對象。
- 最近鄰查詢:R-tree也支持最近鄰查詢,即查找與給定點最接近的數據對象。查詢從根節點開始,根據給定點與節點的距離進行排序,優先訪問最接近給定點的節點。在訪問節點時,繼續向下遍歷其子節點,并根據給定點與子節點的距離進行排序。通過這種方式,可以逐步接近最近鄰數據對象,直到找到最接近的數據對象或達到預設的搜索范圍。
下面給出了一張 R-tree的示例圖:
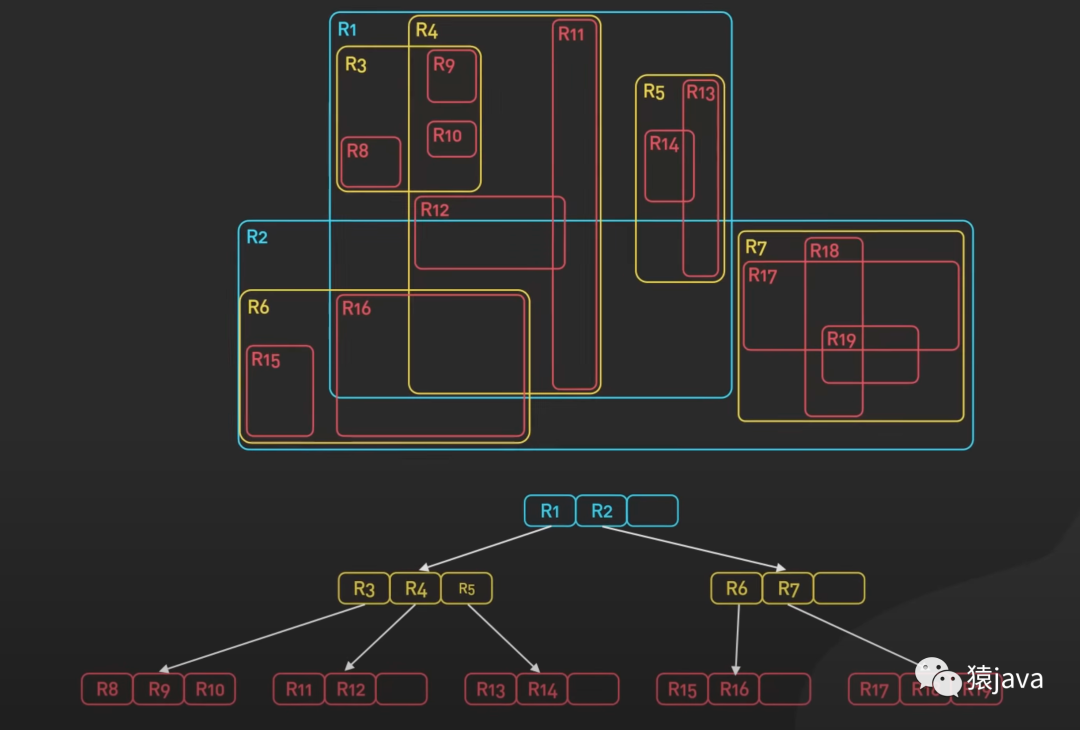
優缺點
R-tree的優點在于它對多維空間數據的高效組織和查詢。通過逐層的樹結構和節點分裂策略,R-tree可以有效地減少不必要的搜索范圍,提高查詢性能。它被廣泛應用于地理信息系統(GIS)、數據庫系統、圖像處理和空間數據索引等領域,用于支持高效的空間數據管理和檢索需求。
數據庫實例
PostGIS、MongoDB 和 Elasticsearch。





