
Iceberg是數(shù)據(jù)湖解決方案中比較熱門的方案之一,通常用于批流一體中數(shù)據(jù)存儲的組織實現(xiàn),希望通過本文讓大家了解到嚴選是如何從老的Lambda架構升級到基于Iceberg的批流一體架構,并在落地過程中解決的一系列問題和做了哪些改進優(yōu)化。
一、 前言
Iceberg是數(shù)據(jù)湖解決方案中比較熱門的方案之一,通常用于批流一體中數(shù)據(jù)存儲的組織實現(xiàn),希望通過本文讓大家了解到網(wǎng)易嚴選是如何從老的Lambda架構升級到基于Iceberg的批流一體架構,并在落地過程中解決的一系列問題和做了哪些改進優(yōu)化。本文主要圍繞下面四個方面展開:
- 網(wǎng)易嚴選數(shù)據(jù)架構
- 基于Iceberg的批流一體實現(xiàn)
- Iceberg表治理
- 在嚴選的落地情況&未來規(guī)劃
二、 嚴選數(shù)據(jù)架構
1、數(shù)據(jù)架構現(xiàn)狀
在嚴選,線上數(shù)據(jù)的來源主要包括MySQL binlog數(shù)據(jù)和日志數(shù)據(jù),這些數(shù)據(jù)被收集到kafka后有兩個去向,一部分是用于離線批計算,一部分用戶實時流計算。離線批處理我們主要使用spark計算引擎,而實時計算則主要使用flink流式計算引擎。
原始數(shù)據(jù)被同步至ODS層后,數(shù)據(jù)開發(fā)團隊基于ODS層數(shù)據(jù)進行輸出建模,并將最終結果數(shù)據(jù)同步至Doris、redis、ElasticSearch等其他存儲,然后給更上層的產(chǎn)品提供服務。
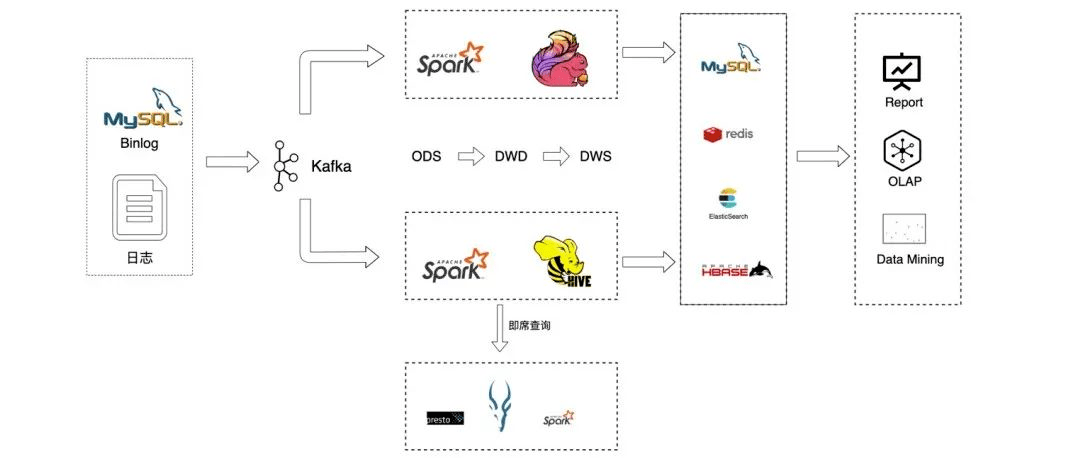 圖1 嚴選數(shù)據(jù)鏈路
圖1 嚴選數(shù)據(jù)鏈路
數(shù)據(jù)集成是數(shù)據(jù)平臺的重要組成部分,如圖1所示是嚴選數(shù)據(jù)入倉的整個流程。主要細分為日志入倉和binlog入倉:
- 日志數(shù)據(jù)入倉的過程是通過Flume收集然后發(fā)給kafka消息隊列,基于flink實現(xiàn)hound任務會提取原始日志信息,把非結構化的信息結構化之后落到ODS層;
- Mysql數(shù)據(jù)入倉是通過數(shù)據(jù)集成平臺dataX完成全量的數(shù)據(jù)同步,然后通過canal收集增量的binlog數(shù)據(jù)推送到kafka消息隊列,再通過自研的Datahub Streaming任務將原始binlog數(shù)據(jù)落地到hive,再基于這些原始binlog數(shù)據(jù)通過按天的spark任務生成T+1的快照數(shù)據(jù),然后提供給離線數(shù)倉使用。
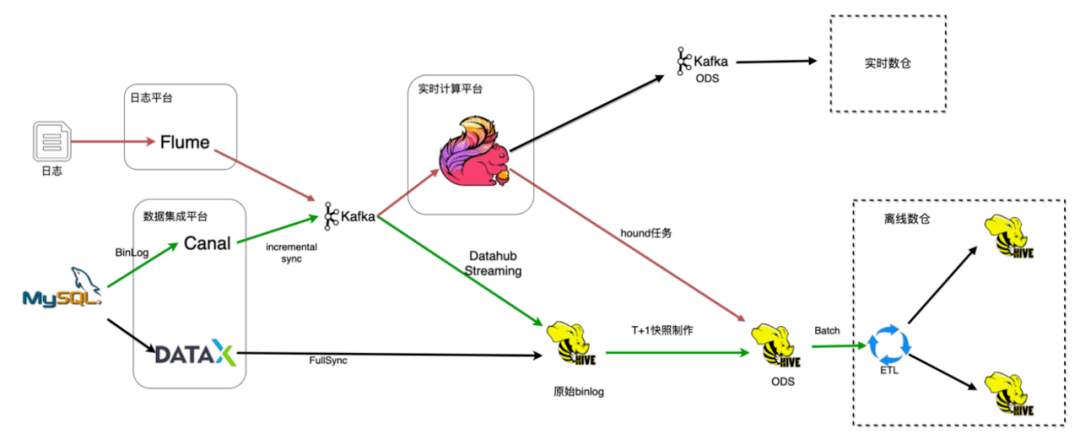 圖2 數(shù)據(jù)集成流程
圖2 數(shù)據(jù)集成流程
2、存在的問題
現(xiàn)有的架構存在如下幾個問題:
- 兩套架構開發(fā)成本高:Lambda架構,實時和離線是兩套處理邏輯,需要實現(xiàn)兩套代碼,引入兩種不同的計算引擎,數(shù)據(jù)開發(fā)成本高。
- 離線時效性低:時效性依賴快照的制作頻率,但頻率越高,占用的存儲計算資源越高。
- 維護成本高:兩套架構,組件多,鏈路長,帶來更大的組件維護成本。
3、方案選擇
針對上面的問題,社區(qū)有很多解決方案,比較熱門的是Iceberg、Hudi、DeltaLake三劍客,都支持upsert、事務、TimeTravel,并且hudi的索引可以支持快速查詢,而且這三種方案都提供了文件合并文件清理等豐富的管理工具。
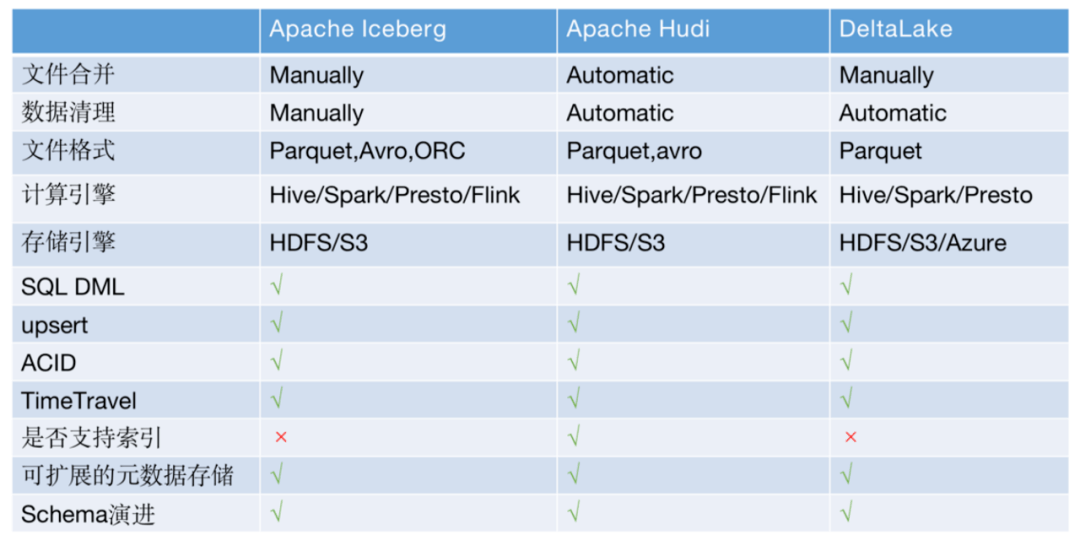 圖3 解決方案對比
圖3 解決方案對比
嚴選根據(jù)當時社區(qū)發(fā)展情況和嚴選當時的需求場景最終選擇了Iceberg,主要考慮因素如下:
- Hudi在嚴選方案調(diào)研期間和spark是強綁定,同期與同樣依賴spark的Deltalake相比功能并不是很完善(hudi現(xiàn)在已經(jīng)不強依賴spark)。
- DeltaLake功能完善,merge功能也非常簡單易用,非常適合嚴選的binlog同步場景。但是它需要用spark streaming來做數(shù)據(jù)同步,而在嚴選流式計算主要是flink計算引擎,兩者在長期發(fā)展路線上并不匹配。
- Iceberg定位是一種表格式,其在設計上做了很好的抽象,沒有強綁定計算引擎和存儲組件,并且當時社區(qū)版本也支持upsert等功能。
三、基于Iceberg的批流一體實現(xiàn)
1、流批一體架構
數(shù)據(jù)入倉架構變化如圖4所示,日志收集沒有變,依然通過Flume收集到kafka,新增了一個kafka2kafka的AutoETL,用于對kafka的原始消息進行解析轉換,并且配置了清洗算子做一些輕量的數(shù)據(jù)清洗工作,例如字段提取和時間轉換等操作。
之后把結構化的數(shù)據(jù)寫到kafka的ODS層,得到了實時的ODS數(shù)據(jù),再把ODS數(shù)據(jù)實時落到Iceberg。
Iceberg的upsert功能可以很友好的處理數(shù)據(jù)庫的變更,但它的數(shù)據(jù)延遲依賴flink的checkpoint,在一些毫秒級的場景Iceberg并不適用,所以嚴選部分的實時場景依然通過kafka消息隊列來實現(xiàn)。
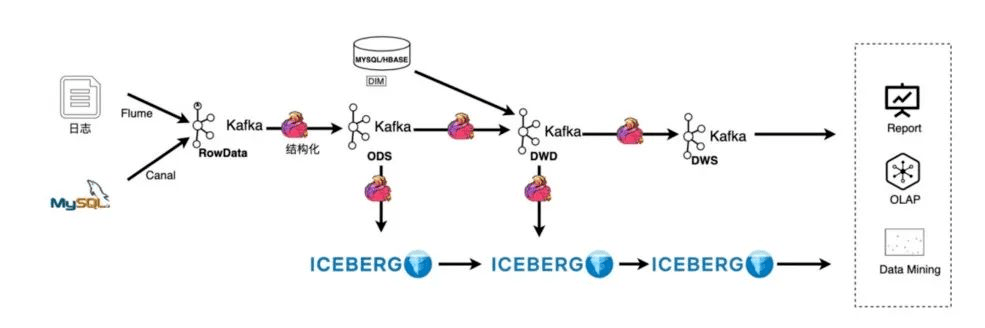 圖4 數(shù)據(jù)入倉(流批一體)架構
圖4 數(shù)據(jù)入倉(流批一體)架構
2、新的問題
架構演進過程不是一蹴而就的,上游修改后,會影響下游使用,所以讓下游業(yè)務無感知或較少感知的切換是架構升級帶來的挑戰(zhàn)。在落地過程中主要面臨如下2個問題:
- Kafka消息亂序和重復:原方案是拿到所有的快照通過排序去重,在實時寫入時,這么做的成本非常高。
- 離線數(shù)倉數(shù)據(jù)沒有T+1快照:落到Iceberg的數(shù)據(jù)是準實時的,需要基于Iceberg的數(shù)據(jù)制作T+1的快照。
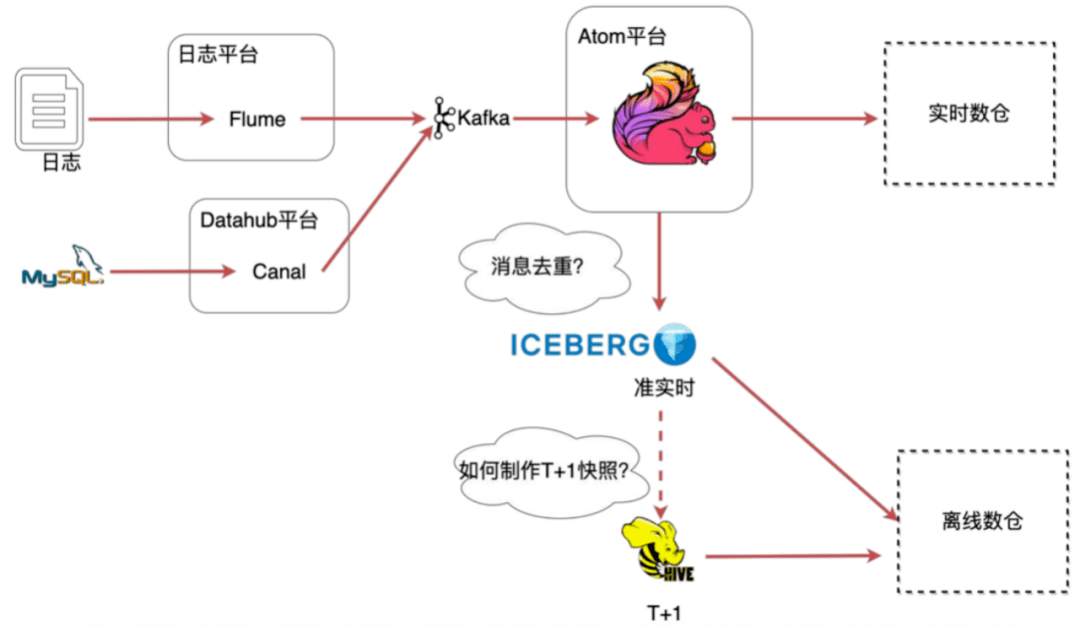 圖5 新的問題
圖5 新的問題
1)消息亂序和重復問題
在消息傳輸過程中很有可能出現(xiàn)消息亂序和消息重復等問題,例如圖6所示的傳輸場景,00:13分的數(shù)據(jù)在00:14分被消費,直接更新00:14分的表會讓id為1的數(shù)據(jù)被晚到的舊數(shù)據(jù)覆蓋導致最終數(shù)據(jù)錯誤。
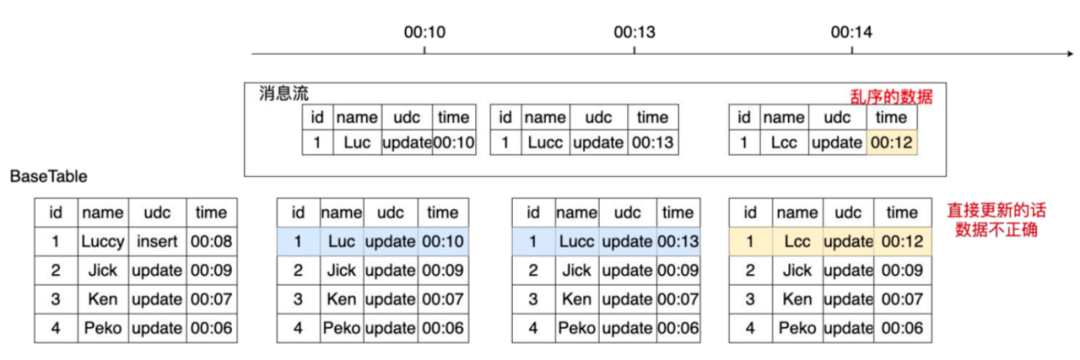 圖6 數(shù)據(jù)傳輸(亂序)
圖6 數(shù)據(jù)傳輸(亂序)
對于消息亂序問題有兩種方式解決:
- 方式1:如圖7,先回查底表,查詢當前記錄的時間,當前記錄的時間比新消息的時間更晚的話就會把消息丟棄,來達到去重的效果。
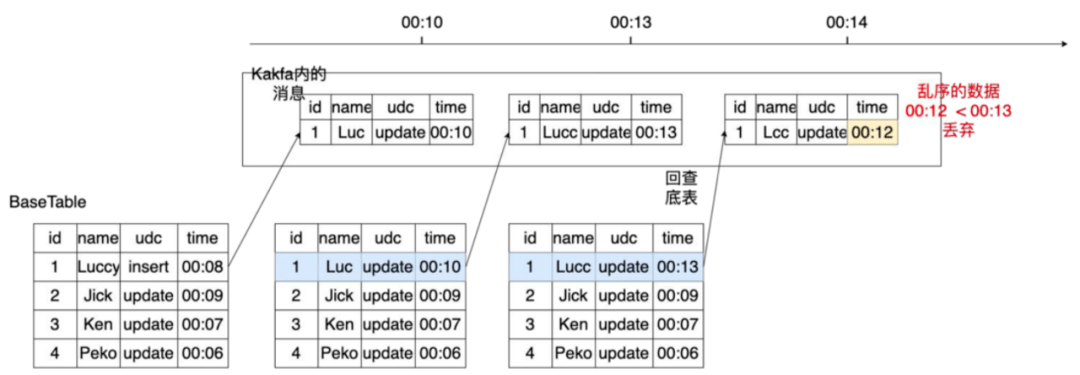 圖7 數(shù)據(jù)去重(丟棄)
圖7 數(shù)據(jù)去重(丟棄)
- 方式2:如圖8,還是回查底表,如果底表的數(shù)據(jù)時間比新消息時間晚,那么先寫晚到的消息,然后再補一條之前的數(shù)據(jù),來保證最終數(shù)據(jù)是正確的,即最終一致性。
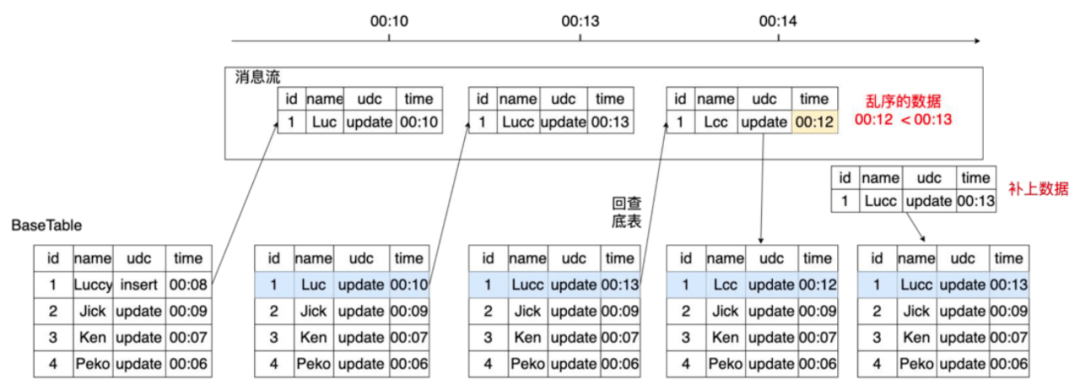 圖8 數(shù)據(jù)去重(回補)
圖8 數(shù)據(jù)去重(回補)
雖然有兩個方式,嚴選最終選擇了第二種處理方式,因為這種方式保留了所有消息,如果選擇第一種方式把數(shù)據(jù)丟棄,當后續(xù)需要制作某一時間的快照就會因為丟失了數(shù)據(jù)而無法制作出正確的快照,例如當需要制作00:12的快照時,用第一種方式制作的快照數(shù)據(jù)是缺失的。
不管是哪種方式都需要回查底表,而在底表非常大的場景下,每個消息都回查,查詢頻繁并且查詢性能較差。所以為了降低查詢頻率,提升查詢性能我們又做了一些改進:
- 通過寫入時增加緩存和統(tǒng)計信息,通過這部分信息增加過濾邏輯減少查詢頻率;
- 通過表治理,加速查詢速度,來解決查詢效率慢的問題。
2)增加緩存及統(tǒng)計信息加速查詢
通過加緩存和統(tǒng)計信息后過濾來減少查詢頻率,例如給定消息M,根據(jù)主鍵查緩存,如果命中在緩存中,就直接比較M消息與緩存中的時間,如果亂序就繼續(xù)查底表;如果未命中緩存,會去查內(nèi)存中的統(tǒng)計信息(統(tǒng)計信息保存了topic+partion+schema的一個key信息,包含了topic最大partion的處理時間),通過統(tǒng)計信息判斷partion級別是否有亂序,如果有亂序也會直接查底表,未命中統(tǒng)計信息時也會查底表,其他情況視為正常就不做任何處理。
這兩種方式可以把很多亂序的消息過濾出來,降低查詢頻率,但這兩種優(yōu)化的假設是大部分數(shù)據(jù)是順序的而非亂序的,亂序會導致命中率低,為了解決亂序問題下面還會介紹排序的優(yōu)化。
3、一致性快照
Iceberg數(shù)據(jù)更新是準實時的,直接查詢最新的數(shù)據(jù)無法得到某一時刻的快照數(shù)據(jù)。
例如圖9,我們想要00:03分的快照,直接查id為1的數(shù)據(jù)實際是00:04分的數(shù)據(jù),顯然是不正確的。
這里我們使用Iceberg的數(shù)據(jù)回溯功能,Iceberg每次提交都會產(chǎn)生新的版本快照,并在元數(shù)據(jù)中記錄dataFile和deleteFile等元數(shù)據(jù)信息,我們在制作特定時間快照的話,可以通過回溯歷史版本,找到符合條件的快照版本,在讀的時候根據(jù)指定時間把不符合條件的記錄過濾掉跟原始數(shù)據(jù)合并就可以得到該時間的快照。
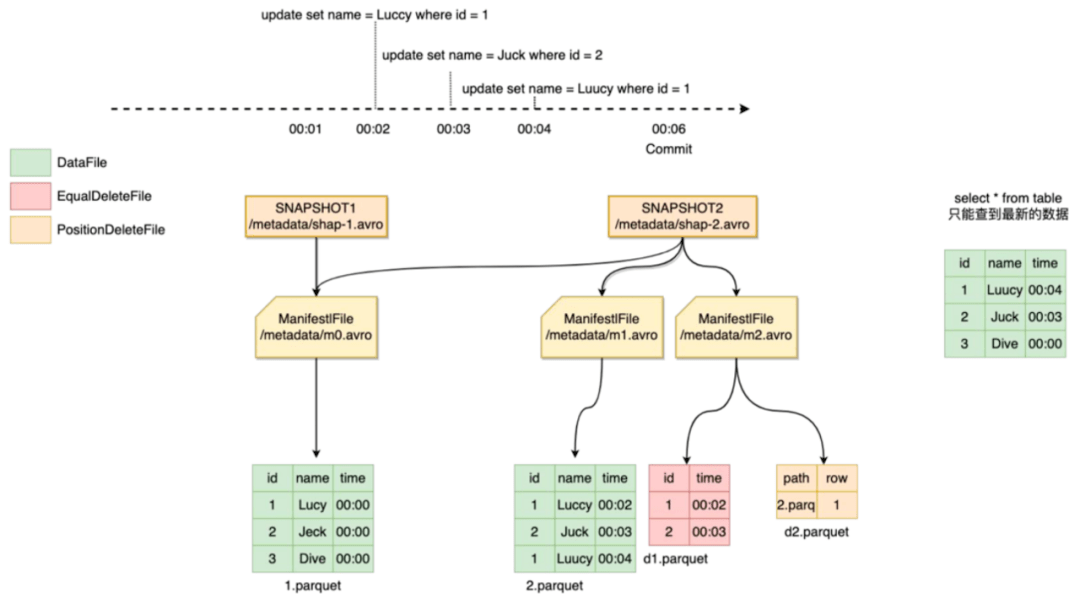 圖9 一致性快照
圖9 一致性快照
制作的具體過程為:
- 給定時間T0,查找最近一個滿足max(eventTime)<=T0的snapshot s1;
- 查找s1之后所有新增的dataFile和deleteFAIle集合記為{F0};
- 從集合{F0}中剔除所有滿足min(eventTime)>T0的文件得到文件集合{F1};
- 遍歷{F1},過濾出所有滿足eventTime<=T0的數(shù)據(jù),記為集合{D};
- S1與{D}合并得到T0時間的一致性快照。
例如我們要做00:03分的快照,如圖10、圖11所示,最新的snapshot是snapshot2,比00:03分小的最近的snapshot是snapshot1,然后查找snapshot1之后的變更dataFile和deleteFaile并過濾掉00:03分之后的記錄,snapshot1與過濾后的記錄合并得到00:03的快照表。
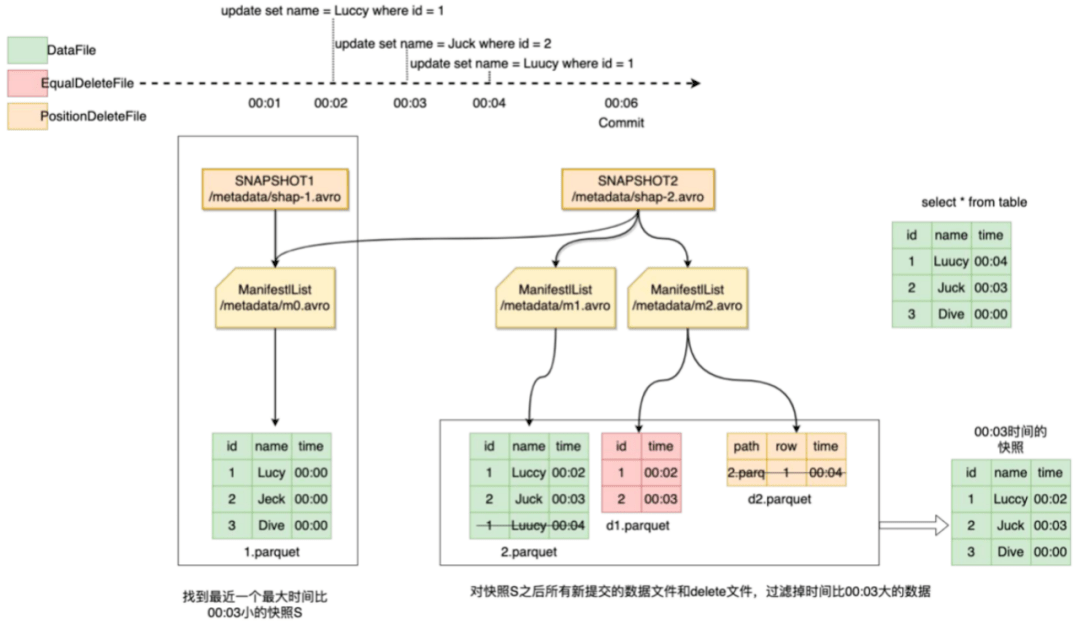 圖10 一致性快照
圖10 一致性快照
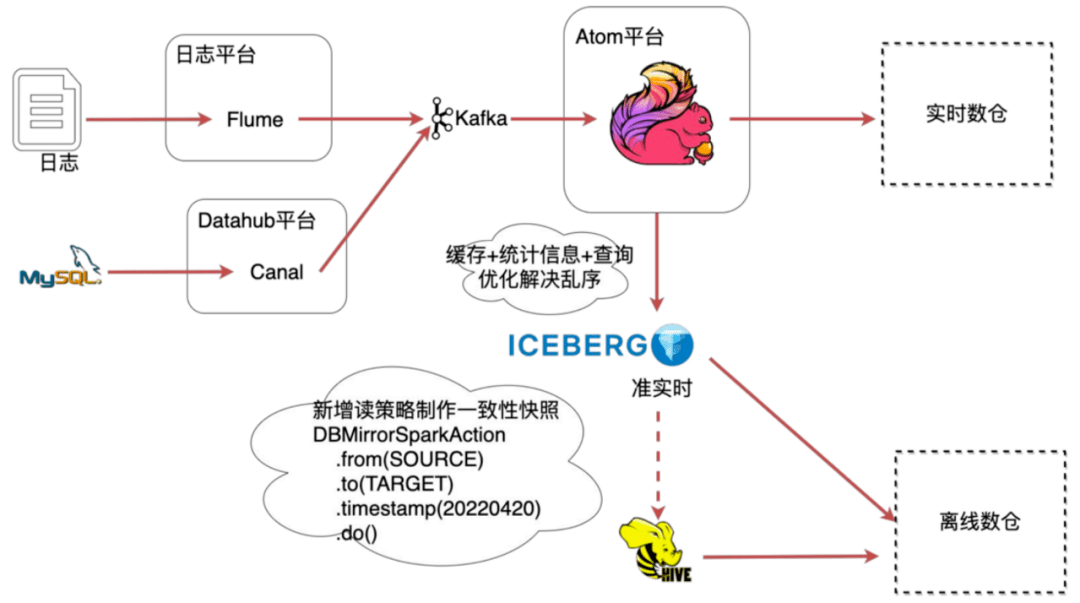 圖11 一致性快照
圖11 一致性快照
四、Iceberg表治理
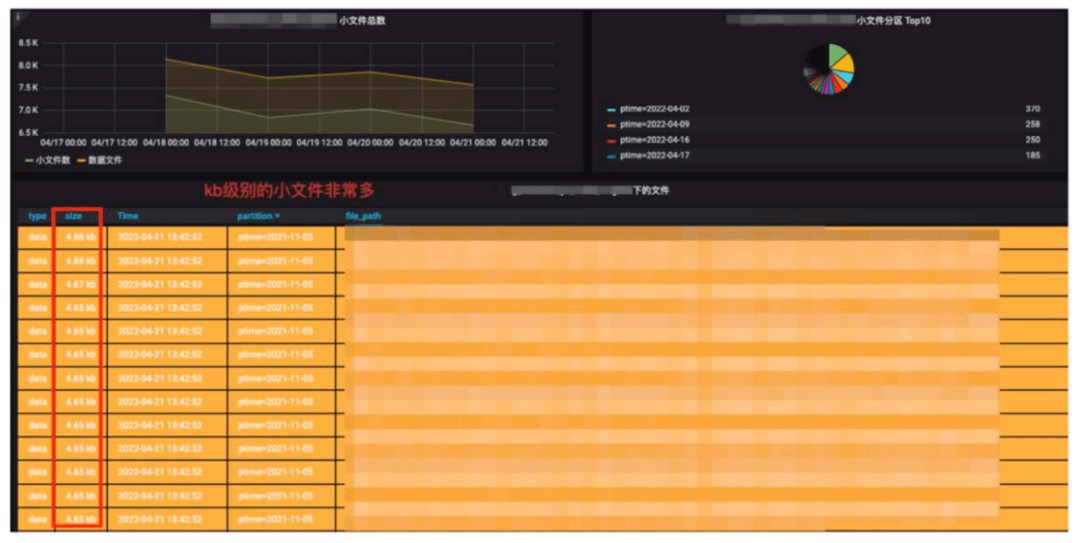 圖12 Iceberg存儲監(jiān)控
圖12 Iceberg存儲監(jiān)控
Iceberg每一次提交都會產(chǎn)生新的文件,文件大小跟提交頻率和數(shù)據(jù)量有很大關系,我們在生產(chǎn)環(huán)境是10分鐘一次Checkpoint做一次提交,我們發(fā)現(xiàn)有些數(shù)據(jù)量并不是很大的日志數(shù)據(jù)和數(shù)據(jù)庫變更,會產(chǎn)生很多的百KB級別的小文件。
而小文件變多后會導致查詢性能下降、存儲效率低等很多問題,所以嚴選建立了表治理服務:DataCompactionService、DataRewriteService、DataCleanService。
- DataCompactionService服務主要用于合并dataFile、deleteFile、元數(shù)據(jù);
- DataRewriteService主要用于dataFile的重排序和deleteFile重寫(把EqualDeleteFile轉化成了PositionDeleteFile);
- DataCleanService主要用于清理孤兒文件(異常情況下會導致存在一些不被表引用的臨時文件)和歷史過期快照。
下面著重介紹下DataRewriteService的deleteFile重寫和重排序功能。
 圖13 Iceberg數(shù)據(jù)治理服務
圖13 Iceberg數(shù)據(jù)治理服務
1、重寫&合并deleteFile
Iceberg文件組織分為deleteFile、EqualDeleteFile、PositionDeleteFile,如圖14所示,EqualDeleteFile根據(jù)數(shù)據(jù)文件的主鍵刪除重復的記錄,PositionDeleteFile記錄了要刪除記錄的文件索引,例如file_3的第一行,SeqNum的作用域只在比自己小的所有數(shù)據(jù)集里。
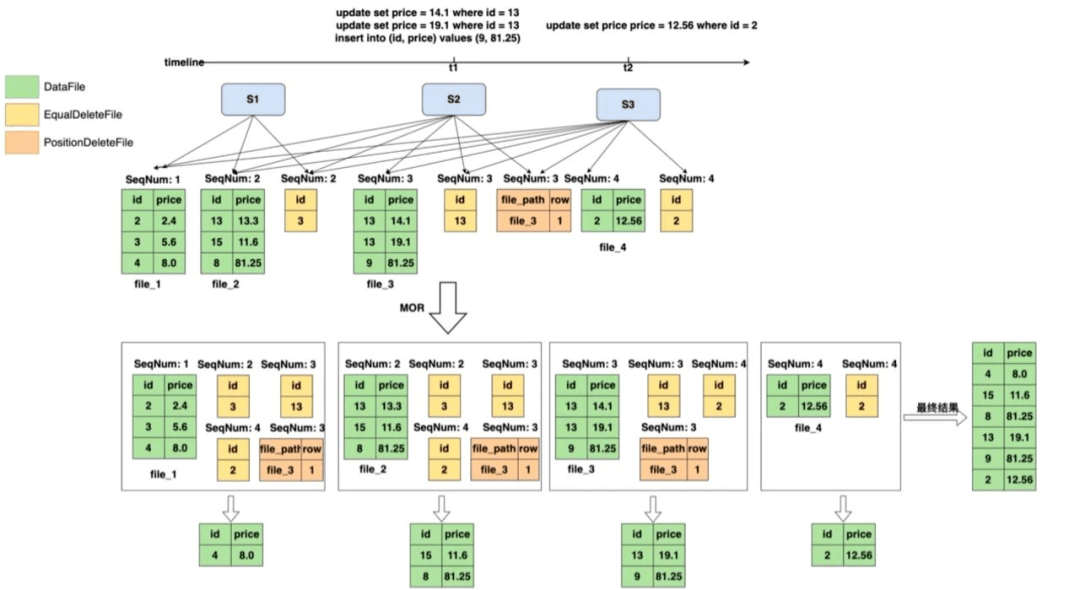 圖14 重寫deleteFile
圖14 重寫deleteFile
但當deleteFile非常多的時候,查詢的性能會變得極差,因為他需要和每一個dataFile進行字段過濾,判斷是否需要將記錄從dataFile中刪除過濾。而positionDeleteFile無需進行記錄判斷,只需要判斷文件位置,效率相比于equalDeletFile好。
為了提升過濾性能,我們通過DataRewriteService把EqualDeleteFile轉化成了PositionDeleteFile,為了解決PositionDeleteFile過多的問題,可以把多個小PositionDeleteFile合并為一個大的PositionDeleteFile,來減少文件數(shù)量,并且得到的結果是一樣的,過程如圖15、16所示。
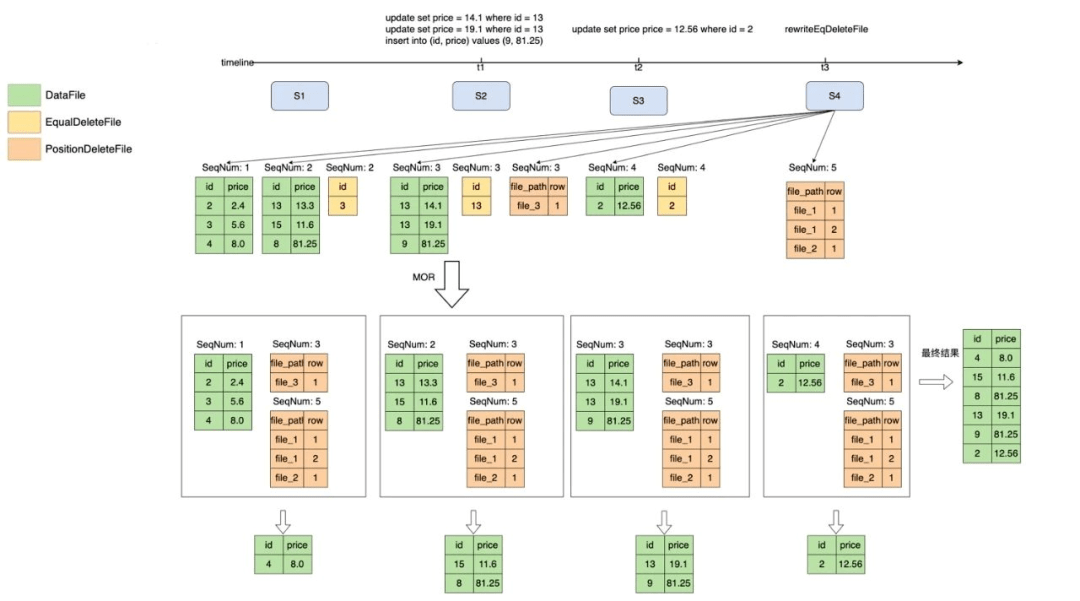 圖15 重寫deleteFile
圖15 重寫deleteFile
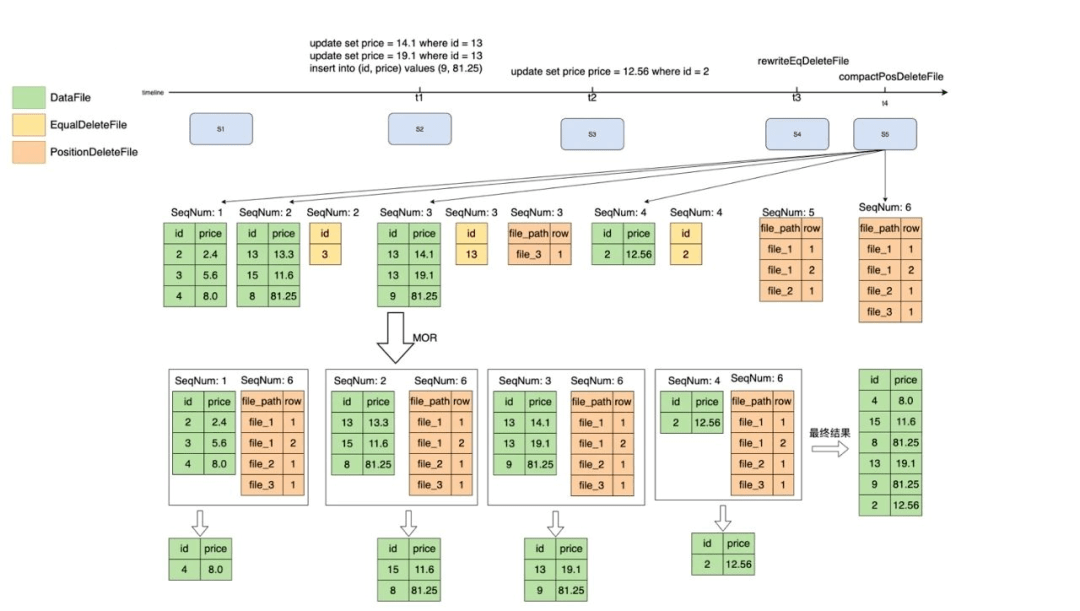 圖16 合并deleteFile
圖16 合并deleteFile
2、重排序
Iceberg在元數(shù)據(jù)中記錄了每一個數(shù)據(jù)文件中的統(tǒng)計信息,包括每一列的最大值/最小值,在進行查詢的時候,就可以根據(jù)where條件中的值和文件中min/max值進行比較來判斷是否需要讀取該數(shù)據(jù)文件。
如果在數(shù)據(jù)寫入的時候不做任何處理,min/max的過濾效果是非常差的,因此在實踐過程中我們會根據(jù)主鍵進行重排序,主要目的是為了提升在上文“增加緩存和統(tǒng)計信息的優(yōu)化”中的命中率。
實現(xiàn)過程如圖17所示,根據(jù)主鍵進行一個重新排序,讓每個文件的數(shù)據(jù)是有序的,之后再根據(jù)主鍵查詢的時候,根據(jù)min/max就可以過濾到很多沒有用的dataFile。
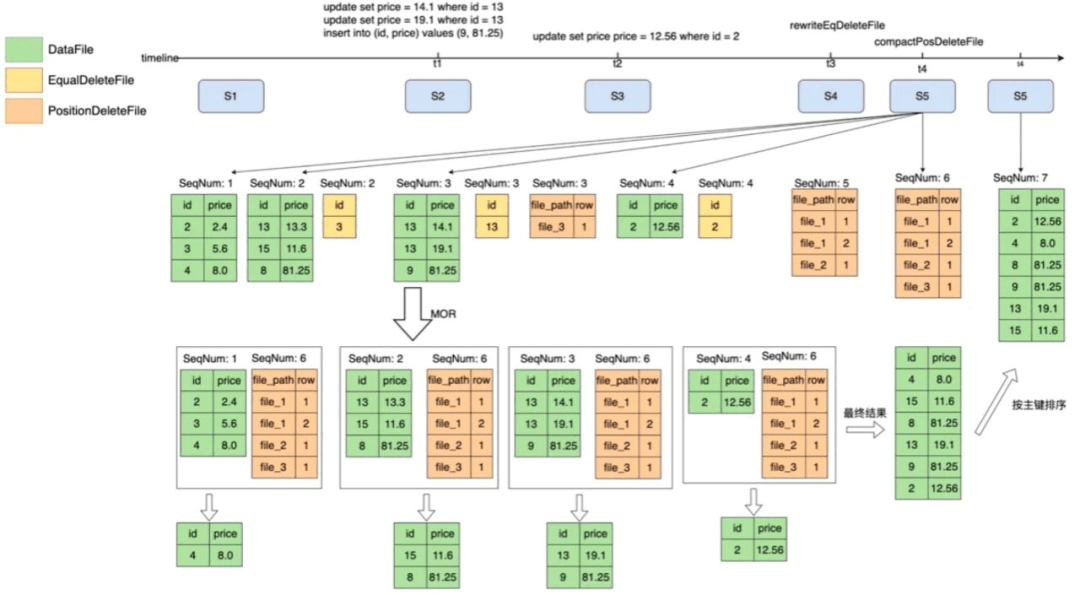 圖17 重排序
圖17 重排序
經(jīng)過緩存統(tǒng)計信息過濾優(yōu)化、小文件合并、重寫deleteFile、重排序這一系列優(yōu)化可以看到數(shù)據(jù)處理前后(綠色是處理前的和黃色是處理后的)的耗時對比差異,大部分查詢效率可以提升10倍以上!
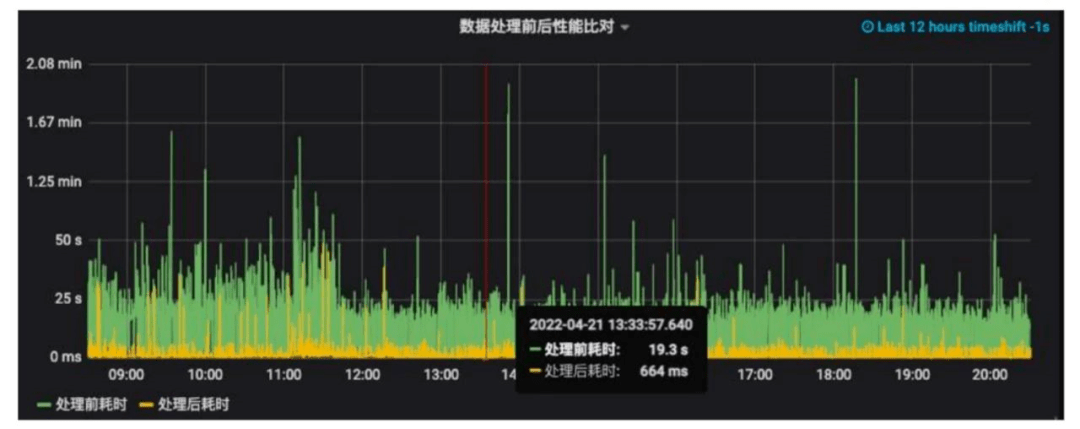 圖18 治理效果
圖18 治理效果
五、 落地情況&未來規(guī)劃
落地情況如下:
- 完成ODS層數(shù)據(jù)產(chǎn)出的批流融合
- 離線數(shù)據(jù)延遲縮短至5分鐘
- 所有ODS T+1快照的制作時間可提前半小時
- 已有500+任務穩(wěn)定運行
在未來期望能探索更多的業(yè)務場景,例如在特征工程和數(shù)倉DWD加工場景也實現(xiàn)批流一體。在查詢體驗上,計劃讓presto也接入iceberg的支持,引入Alluxio緩存來加速元數(shù)據(jù)的加載和緩存數(shù)據(jù),加入Z-order數(shù)據(jù)重排序和Bloom-Filter文件索引等功能提升查詢效率。另外把文件監(jiān)控、健康檢查等功能產(chǎn)品化以提升易用性。
作者丨祝佳俊
來源丨嚴選技術團隊(ID:YanxuanTechProd)





