
前言
我們在日常開發中,一定遇見過某些SQL執行較慢的情況,我們俗稱“慢SQL”,如果你對系統的接口性能要求較高的話,一定不會放過這種SQL,肯定會想辦法進行解決,那么,導致慢 SQL 出現的原因,究竟可能都有哪些呢?
這是一道經典的面試題,就此我們來研究一番,下面我們就來好好看一下,原因可能出在哪里。
本篇我們將從如下幾個方面進行討論:
1.慢SQL捕獲
2.執行計劃分析
3.引擎參數配置分析
讓我們就此開啟本次慢SQL分析之旅,Let's go!
ps: 本篇文章的討論,主要基于MySQL8.0數據庫,Oracle等其他數據庫不在本篇討論范圍之列。
一、慢SQL捕獲
追查應用服務的慢SQL,首先需要追蹤哪些SQL可能是慢SQL,對于JAVA服務,很多數據庫中間件提供了慢SQL的追蹤能力,例如Alibaba Druid,會將服務運行過程中的慢SQL打印到日志文件,方便開發運維人員追查。
MySQL當然也提供了捕獲慢查詢的監控能力,記錄在MySQL中執行時間超過指定時間的SQL語句。
默認情況下,MySQL并沒有開啟慢日志,可以通過修改slow_query_log參數來打開慢日志。與慢日志相關的參數介紹如下:
- slow_query_log:是否啟用慢查詢日志,1表示開啟,0表示關閉,默認為關閉。
- slow_query_log_file:指定慢查詢日志位置及名稱,默認值為host_name-slow.log,可指定絕對路徑。
- long_query_time:慢查詢執行時間閾值,超過此時間會記錄,默認為10,取值范圍0~31536000,單位為秒。
- min_examined_row_limit:對于查詢掃描行數小于此參數的SQL,將不會記錄到慢查詢日志中,默認為0,最大值(bit-64)為18446744073709551615。
- log_output:慢查詢日志輸出目標,默認為FILE,即輸出到文件,取值為TABLE、FILE、NONE。
- log_timestamps:主要是控制 error log、slow log、genera log 日志文件中的顯示時區,默認使用UTC時區,取值為UTC、SYSTEM,建議改為 SYSTEM系統時區。
- log_queries_not_using_indexes:是否記錄所有未使用索引的查詢語句,默認為OFF。
- log_slow_admin_statements:慢速管理語句是否寫入慢日志中,管理語句包含 ALTER TABLE,ANALYZE TABLE, CHECK TABLE,CREATE INDEX, DROP INDEX,OPTIMIZE TABLE,REPAIR TABLE,默認為OFF即不寫入。
一般情況下,我們只需開啟慢日志記錄,配置下閾值時間,其余參數可按默認配置。對于閾值時間,可靈活調整,比如說可以設置為 1s 或 3s 。
1.慢查詢追蹤配置方式
MySQL提供了兩種配置慢查詢參數的方式,提供給開發者使用,下面我們依次來看一下。
第一種,將慢查詢參數配置寫入MySQL配置文件,永久生效:
# 慢查詢日志相關配置,可根據實際情況修改
vim /etc/my.cnf
[mysqld]
slow_query_log = 1
slow_query_log_file = /var/log/mysql/sql-slow.log
long_query_time = 1
log_timestamps = SYSTEM
log_output = FILE
第二種,MySQL Server中臨時開啟慢查詢功能,當MySQL Server重啟時,配置修改則全部失效并恢復原狀:
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL slow_query_log_file = '/var/log/mysql/sql-slow.log';
SET GLOBAL log_queries_not_using_indexes = 'ON';
SET SESSION long_query_time = 1;
SET SESSION min_examined_row_limit = 100;
如何查看下慢查詢日志是否開啟,以及慢查詢日志文件的位置:
mysql> show variables like '%slow_query_log%';
+---------------------+-----------------------------------------+
Variable_name | Value |
+---------------------+-----------------------------------------+
slow_query_log | ON |
slow_query_log_file | /var/lib/mysql/VM-16-14-centos-slow.log |
+---------------------+-----------------------------------------+
2 rows in set (0.00 sec)
下面我們具體看下,慢日志會記錄哪些內容?我們執行一條較慢的查詢SQL,來看下在慢日志中的體現。
# Time: 2022-11-02T09:23:37.004885Z
# User@Host: wtopps[wtopps] @ localhost [] Id: 10831
# Query_time: 1.609214 Lock_time: 0.003828 Rows_sent: 2050008 Rows_examined: 2150010
SET timestamp=1667381015;
SELECT A.* FROM `user` A LEFT JOIN grade B ON A.`id` = B.`user_id`;
對于每一組慢SQL,日志內容格式如下:
第一行記錄的是該條SQL執行的時刻(如果log_timestamps參數為UTC,則改時間會顯示UTC時區時間)。
第二行記錄的是執行該語句的用戶和IP以及鏈接id。
第三行的幾個字段含義如下:
- Query_time:語句執行時間,以秒為單位。
- Lock_time:獲取鎖的時間(以秒為單位)。
- Rows_sent:發送給Client端的行數。
- Rows_examined:服務器層檢查的行數(不計算存儲引擎內部的任何處理)
在8.0.14及以上版本可以打開log_slow_extra系統參數,收集更多信息。
mysql>set global log_slow_extra=on
# Time: 2023-02-10T13:07:50.617272Z
# User@Host: wtopps[wtopps] @ [111.197.236.164] Id: 19187
# Query_time: 91.511261 Lock_time: 0.000124 Rows_sent: 2050008 Rows_examined: 2150010 Thread_id: 19187 Errno: 0 Killed: 0 Bytes_received: 0 Bytes_sent: 58061725 Read_first: 2 Read_last: 0 Read_key: 2 Read_next: 0 Read_prev: 0 Read_rnd: 0 Read_rnd_next: 2150012 Sort_merge_passes: 0 Sort_range_count: 0 Sort_rows: 0 Sort_scan_count: 0 Created_tmp_disk_tables: 0 Created_tmp_tables: 0 Start: 2023-02-10T13:06:19.106011Z End: 2023-02-10T13:07:50.617272Z
SET timestamp=1676034379;
SELECT A.* FROM `user` A LEFT JOIN grade B ON A.`id` = B.`user_id`;
可以看到,當開啟log_slow_extra參數后,慢查詢日志中出現了大量的額外信息,其含義如下:
Thread_id:連接的標識;
Errno:SQL錯誤號,0表示沒有錯誤;
Killed:語句終止的錯誤號,0表示正常終止;
Bytes_received/sent:收到和發送的字節數;
Read_first:Handler_read_first的值,代表讀取索引中第一個條目的次數。反映查詢全索引掃描的次數。
Read_last:讀取索引最后一個key的次數;
Read_key:基于key讀取行的請求數,較大說明使用正確的索引
Read_next:按順序取下一行數據的次數,索引范圍查找和索引掃描時該值會增大;
Read_prev:按順序讀取上一行的請求數,order by desc查詢較優時該值較大;
Read_rnd:按固定位置讀取行的請求數,大量的回表、沒有索引的連接和對結果集排序時會增加;
Read_rnd_next:讀取數據文件下一行的次數,大量表掃描、未創建或合理使用索引時會增加;
Sort_range_count:使用范圍完成的排序次數;
Sort_rows:排序的行數;
Sort_scan_count:通過掃描表完成的排序次數;
Sort_merge_passes:排序算法合并的次數,如該值較大考慮增加sort_buffer_size的值
Created_tmp_disk_tables:創建內部磁盤臨時表的數量;
Created_tmp_tables:創建內部臨時表的數量;
Start/End:語句開始和結束時間
Tips:
在MariaDB中,可以開啟log_slow_verbosity參數,可以更加詳盡的打印出慢SQL的執行細節,該參數在MySQL8.0版本中并未支持,讀者感興趣可以自行查閱相關信息。
通過慢查詢日志,我們可以捕獲到具體的慢SQL,接下來,則要具體分析慢SQL產生的可能原因。
二、情況分析
1.為什么查詢會慢?
在嘗試編寫快速的查詢之前,需要清楚一點,真正重要是響應時間。如果把查詢看作是一個任務,那么它由一系列子任務組成,每個子任務都會消耗一定的時間。如果要優化查詢,實際上要優化其子任務,要么消除其中一些子任務,要么減少子任務的執行次數,要么讓子任務運行得更快。
MySQL在執行查詢的時候有哪些子任務,哪些子任務運行的速度很慢?這里很難給出完整的列表,通常來說,查詢的生命周期大致可以按照順序來看:
從客戶端,到服務器,然后在服務器上進行解析,生成執行計劃,執行,并返回結果給客戶端。其中“執行”可以認為是整個生命周期中最重要的階段,這其中包括了大量為了檢索數據到存儲引擎的調用以及調用后的數據處理,包括排序、分組等。
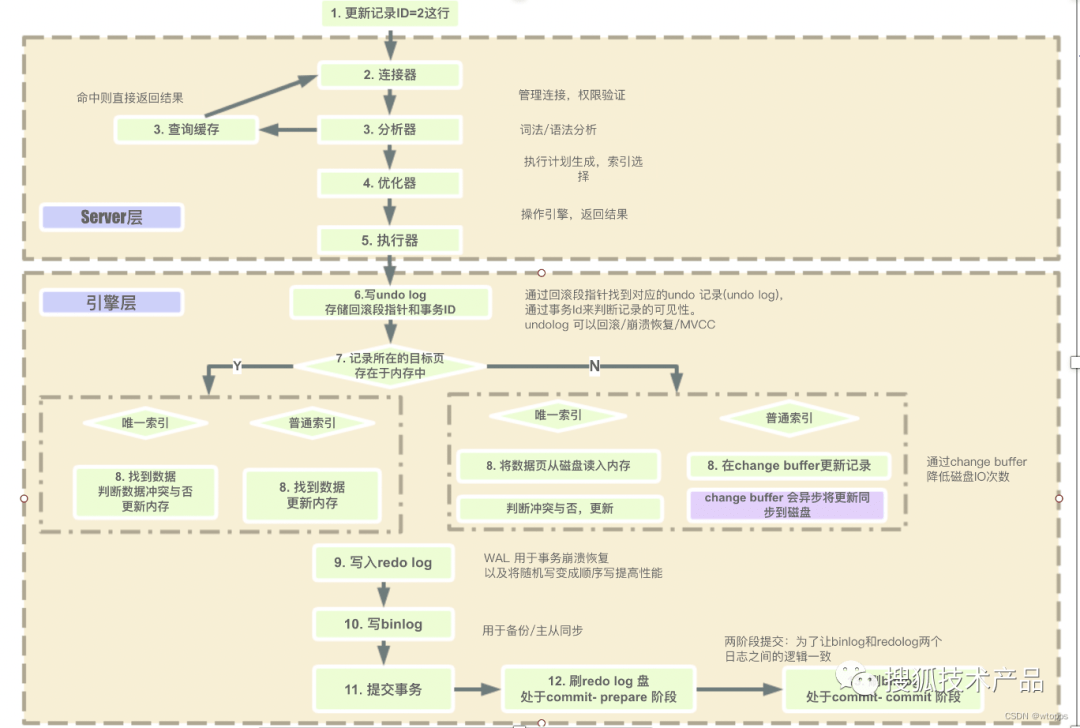
mysql執行過程
在完成這些任務的時候,查詢需要在不同的地方花費時間,包括網絡,CPU計算,生成統計信息和執行計劃、鎖等待(互斥等待)等操作,尤其是向底層存儲引擎檢索數據的調用操作,這些調用需要在內存操作、CPU操作和內存不足時導致的I/O操作上消耗時間。
根據存儲引擎不同,可能還會產生大量的上下文切換以及系統調用。
在每一個消耗大量時間的查詢案例中,大概率會出現一些不必要的額外操作、某些操作被額外地重復了很多次、某些操作執行得太慢等。優化查詢的目的就是減少和消除這些操作所花費的時間。
再次申明一點,對于一個查詢的全部生命周期,上面列的并不完整。這里我們只是想說明:了解查詢的生命周期、清楚查詢的時間消耗情況對于優化查詢有很大的意義。有了這些概念,我們再一起來看看如何優化查詢。
捕獲具體的慢查詢SQL后,我們需要對可能導致慢查詢的原因進行分析,我們可以從如下幾個角度,對問題進行拆解:
- SQL執行計劃分析
- 引擎參數配置分析
- 引擎參數配置分析(網絡,物理機配置,內存,機器負載I/O)
2.SQL執行計劃分析
查詢性能低下最基本的原因是訪問的數據太多。某些查詢可能不可避免地需要篩選大量數據,但在實際業務場景中,這并不常見。
大部分性能低下的查詢都可以通過減少訪問的數據量的方式進行優化。對于低效的查詢,我們發現通過下面兩個步驟來分析總是很有效:
- 確認應用程序是否在檢索大量超過需要的數據。這通常意味著訪問了太多的行,但有時候也可能是訪問了太多的列。
- 確認MySQL服務器層是否在分析大量超過需要的數據行。
有些查詢會請求超過實際需要的數據,然后這些多余的數據會被應用程序丟棄。這會給MySQL服務器帶來額外的負擔,并增加網絡開銷,另外也會消耗應用服務器的CPU和內存資源。
因此,合理的使用索引的重要性就凸顯出來,如果查詢中的查詢條件未命中索引字段,MySQL引擎則只能對全量的數據進行檢索,再根據查詢條件進行過濾,篩選出目標的數據集,這個過程是非常耗時且低效的。
接下來,我們將逐步對SQL執行的過程進行分析拆解,通過工具手段剖析慢查詢的具體原因。
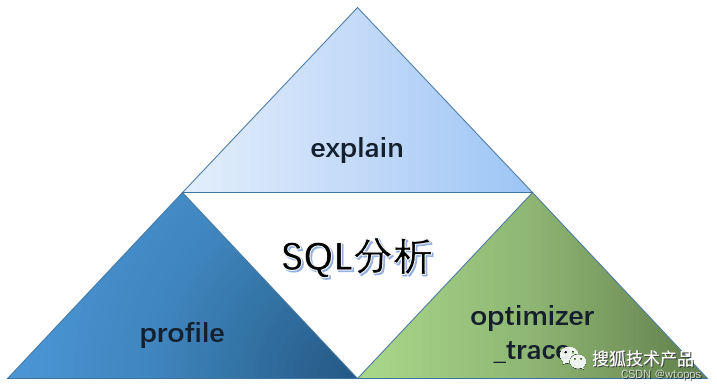
SQL分析三步走
3.explain執行計劃分析
對于SQL執行過程分析,最先登場的毫無疑問就是explain語句了,explain是我們在日常開發最常使用的分析命令。其使用方式,這里不再贅述,一般來說,95% 的慢查詢問題只需要explain就可以解決了。
對于explain執行計劃的分析,我們需要關注最簡單的衡量查詢開銷的兩個點:
- 掃描的行數
- 返回的行數
通過explain執行計劃可以獲得SQL在執行時預估的掃描行數以及返回行數的大概比例,這在一定程度上能夠說明該查詢找到需要的數據的效率高不高。
但這個指標也并不是絕對的,因為并不是所有的行的訪問代價都是相同的。較短的行的訪問速度更快,內存中的行也比磁盤中的行的訪問速度要快得多。
理想情況下掃描的行數和返回的行數應該是相同的。但實際情況中這種情況并不多見。
例如在做一個多表的join關聯查詢時,服務器必須要掃描多行才能生成結果集中的一行。掃描的行數對返回的行數的比率通常很小,一般在1:1和10:1之間,不過有時候這個值也可能非常非常大。
比值越大則意味著查詢效率越低,因為引擎執行掃描出的大部分數據行都會被丟棄,這也意味著需要執行更多的I/O操作,因此盡可能降低掃描的行數對返回的行數的比率,是我們對慢查詢優化的關鍵所在。
一般MySQL能夠使用如下三種方式應用where條件,從好到壞依次為:
- 在索引中使用where條件來過濾不匹配的記錄。這是在存儲引擎層完成的。
- 使用索引覆蓋掃描(在Extra列中出現了Using index)來返回記錄,直接從索引中過濾不需要的記錄并返回命中的結果。這是在MySQL服務器層完成的,但無須再回表查詢記錄。
- 從數據表中返回數據,然后過濾不滿足條件的記錄(在Extra列中出現Using Where)。這在MySQL服務器層完成,MySQL需要先從數據表讀出記錄然后過濾。
Extra中Using Index與Using Where,MySQL官方文檔的解釋如下:
Using Index
The column information is retrieved from the table using only information in the index tree without having to do an additional seek to read the actual row. This strategy can be used when the query uses only columns that are part of a single index.
Using Where
A WHERE clause is used to restrict which rows to match against the next table or send to the client. Unless you specifically intend to fetch or examine all rows from the table, you may have something wrong in your query if the Extra value is not Using where and the table join type is ALL or index.
使用explain判斷導致查詢慢的原因,判斷依據可以根據如下幾點:
- where查詢條件中的字段,是否是索引字段,索引字段是否滿足了最左匹配原則
- where查詢條件中是否對索引字段使用了函數處理
- 對索引字段使用函數操作,會使得索引失效
- where查詢條件中是否存在like %字段%情況
- like%%的全模糊匹配,會使得索引失效,如需使用like,請使用like字段%
- 對于select *的查詢,該表的字段數量為多少
- 對于巨型寬表,例如上百個字段的大表,select *是效率低下的選擇,實際業務中很少有情況會需要全部字段的情況,根據需要查詢特定的字段是非常必要的
- where查詢條件中是否使用or,如果使用了,or的字段是否是主鍵或者索引字段
- 對于主鍵或索引字段,or與in不存在性能差距,對于非索引字段,or的性能會低于in
- In many database servers, IN() is just a synonym for multiple OR clauses,
- because the two are logically equivalent. Not so in MySQL,
- which sorts the values in the IN() list and uses a fast binary search to see whether a value is in the list.
- This is O(Log n) in the size of the list, whereas an equivalent series of OR clauses is O(n) in the size of the list (i.e., much slower for large lists)
- 查詢是否使用了多個表(大于3張) 的join操作,join表的數據量級如何,是否使用了索引字段進行查詢
- 對于多表join的復雜聯合查詢,是可能產生慢SQL的重災區,join子表的順序決定了掃描結果集會有多大,需要結合explain進行分析判斷
- 實際業務場景中,也盡可能避免多表join操作,需要在表設計階段就做好冗余字段的考慮
- where查詢條件是否使用了分頁查詢,分頁深度是多大
- limit10, offset100000,MySQL在實際執行時,會查詢出100010條記錄,然后丟棄前100000條,性能會極為糟糕
- 對于深分頁查詢優化,當執行深度分頁時,可以帶入主鍵ID作為查詢條件,執行下一頁的查詢時,將上一頁最大的主鍵ID作為條件,id > last_page_max_id
綜上我們總結,SQL執行時其掃描的行數決定了執行的效率,而決定掃描行數的關鍵,則是索引的命中情況與索引的質量。
Tips:關于索引的一些小建議
- 唯一索引命名uk字段,普通索引命名idx字段,過長時可用首字母替代;
- 盡量避免三張表以上的join,對于多表join的情況,可以視情況考慮將一個大查詢拆分成多個子查詢,對結果集在業務層進行聚合處理。如必須要多表join的場景,特別注意多連表查詢的掃描行數問題以及索引的命中情況;
- varchar長字段建立索引,需要指定索引長度,根據文本區分度來決定長度;
- 避免左模糊,全模糊匹配;
- order by 字段放在索引最后列,避免filesort;
- 考慮利用覆蓋索引來進行查詢操作,避免回表;
- 性能優化目標,需要為range級別以上,最好是ref級別,或者const最好;
- 區分度高的列在索引最左邊;
- 避免字段類型不同造成的隱式轉換,導致索引失效。例如:varchar和數字類型;
- 根據大多數SQL來創建索引;
- 對于運行較久的大表,需要關注索引字段的區分度問題,當索引值出現了嚴重傾斜時,需要考慮優化拆分索引值。
4.PROFILE分析
通過使用explain分析SQL的執行計劃,我們可以看到SQL執行過程中是否使用索引,使用了哪些索引,索引掃描的行數等,但MySQL的慢查詢,并不一定慢在有沒有索引,SQL的執行環節中任意一環出了問題都會表現為查詢變慢,所以即使執行過程命中了索引,explain的結果也很完美,但是還是慢,怎么辦?
這時候,就需要profile工具來幫忙了,這個命令可以詳細列出SQL語句在每一個步驟消耗的時間,前提(缺點)是先執行一遍語句。
PROFILE默認是關閉的,所以需要在client端先打開,操作如下:
set session profiling = 1;
在實際的生產環境中,可能會需要加大profile的隊列,保證想要查看的profile結果還保存著,因此可以用如下操作來增加profile的隊列大小:
set session profiling_history_size = 50;
讓我們一起來看一下profile分析如何使用,我們先執行下面的SQL:
mysql> explain select * from user where name = '小六' and code = 300000003;
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
1 | SIMPLE | user | NULL | ALL | NULL | NULL | NULL | NULL | 2043040 | 1.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
這個一個典型的效果較差的查詢,type=ALL,沒有命中索引,執行了全表掃描,我們使用profile分析一下各階段的執行時間:
mysql> show profiles;
+----------+------------+---------------------------------------------------------------+
Query_ID | Duration | Query |
+----------+------------+---------------------------------------------------------------+
1 | 0.55695825 | select * from user where name = '小六' and code = 300000003 |
+----------+------------+---------------------------------------------------------------+
1 row in set, 1 warning (0.00 sec)
找到我們需要分析的語句,查詢執行耗時詳情:
mysql> show profile block io,cpu,memory,source for query 1;

profile執行耗時詳情
從profile執行結果中,我們可以清晰的看到一條SQL在每個執行階段的耗時、CPU使用率、IO等指標,幫助我們定位到慢查詢具體執行耗時的階段,對于該條SQL,執行過程中最耗時的部分是executing部分,executing階段包括了執行線程正在為SELECT讀取和處理數據行,并將數據發送到客戶端。
因為在這個狀態下發生的操作往往執行大量的磁盤讀取,所以它往往是在整個查詢的生命周期中運行時間最長的一個階段。
經過了對SQL語句進行explain與profile分析之后,一個SQL為什么慢,慢在哪里基本上可以定位出來了,那么最后的手段主要是解決什么問題呢?
我們將使用最終的分析工具,OPTIMIZER_TRACE。
5.OPTIMIZER_TRACE分析
OPTIMIZER_TRACE是MySQL 5.6添加的新功能,這個功能可以看到內部查詢計劃的TRACE信息,也就是MySQL在執行過程中的具體決策細節,從而可以知道MySQL是如何在眾多索引中的挑選最合適的索引。
如果我們通過執行計劃,發現MySQL選擇的索引并不符合我們的預期,就需要根據OPTIMIZER_TRACE的信息來判斷為什么會選擇它,是MySQL的配置原因,還是SQL某些地方寫的不好導致MySQL誤判。
開啟這個功能的方式如下:
set session optimizer_trace='enabled=on';
在客戶端執行一個EXPLAIN語句,生成一個執行計劃,然后在information_chema.optimizer_trace的表里面查找這一條語句對應的信息:
mysql> select * from information_schema.optimizer_trace;
explain select * from user where age = 21 | {
"steps": [
{
"join_preparation": {
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `user`.`id` AS `id`,`user`.`name` AS `name`,`user`.`age` AS `age`,`user`.`code` AS `code` from `user` where (`user`.`age` = 21)"
}
]
}
},
{
"join_optimization": {
"select#": 1,
"steps": [
{
"condition_processing": {
"condition": "WHERE",
"original_condition": "(`user`.`age` = 21)",
"steps": [
{
"transformation": "equality_propagation",
"resulting_condition": "multiple equal(21, `user`.`age`)"
},
{
"transformation": "constant_propagation",
"resulting_condition": "multiple equal(21, `user`.`age`)"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "multiple equal(21, `user`.`age`)"
}
]
}
},
{
"substitute_generated_columns": {
}
},
{
"table_dependencies": [
{
"table": "`user`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
]
}
]
},
{
"ref_optimizer_key_uses": [
{
"table": "`user`",
"field": "age",
"equals": "21",
"null_rejecting": true
}
]
},
{
"rows_estimation": [
{
"table": "`user`",
"range_analysis": {
"table_scan": {
"rows": 2043040,
"cost": 205676
},
"potential_range_indexes": [
{
"index": "PRIMARY",
"usable": false,
"cause": "not_Applicable"
},
{
"index": "idx_age",
"usable": true,
"key_parts": [
"age",
"id"
]
}
],
"setup_range_conditions": [
],
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
},
"skip_scan_range": {
"potential_skip_scan_indexes": [
{
"index": "idx_age",
"usable": false,
"cause": "query_references_nonkey_column"
}
]
},
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "idx_age",
"ranges": [
"21 <= age <= 21"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": true,
"using_mrr": false,
"index_only": false,
"in_memory": 0.788627,
"rows": 1,
"cost": 0.61,
"chosen": true
}
],
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
}
},
"chosen_range_access_summary": {
"range_access_plan": {
"type": "range_scan",
"index": "idx_age",
"rows": 1,
"ranges": [
"21 <= age <= 21"
]
},
"rows_for_plan": 1,
"cost_for_plan": 0.61,
"chosen": true
}
}
}
]
},
{
"considered_execution_plans": [
{
"plan_prefix": [
],
"table": "`user`",
"best_access_path": {
"considered_access_paths": [
{
"access_type": "ref",
"index": "idx_age",
"rows": 1,
"cost": 0.35,
"chosen": true
},
{
"access_type": "range",
"range_details": {
"used_index": "idx_age"
},
"chosen": false,
"cause": "heuristic_index_cheaper"
}
]
},
"condition_filtering_pct": 100,
"rows_for_plan": 1,
"cost_for_plan": 0.35,
"chosen": true
}
]
},
{
"attaching_conditions_to_tables": {
"original_condition": "(`user`.`age` = 21)",
"attached_conditions_computation": [
],
"attached_conditions_summary": [
{
"table": "`user`",
"attached": "(`user`.`age` = 21)"
}
]
}
},
{
"finalizing_table_conditions": [
{
"table": "`user`",
"original_table_condition": "(`user`.`age` = 21)",
"final_table_condition ": null
}
]
},
{
"refine_plan": [
{
"table": "`user`"
}
]
}
]
}
},
{
"join_explain": {
"select#": 1,
"steps": [
]
}
}
]
}
1 row in set (0.02 sec)
內容是非常長的 JSON格式,所以推薦把結果轉存到其他地方,然后用JSON的轉換工具來輔助查看,如果要看索引的選擇情況,就重點關注這個JSON的ref_optimizer_key_uses,rows_estimation及之后的部分,這里會展示索引選擇相關的信息,截取一部分結果作為示例:
{
"ref_optimizer_key_uses": [
{
"table": "`user`",
"field": "age",
"equals": "21",
"null_rejecting": true
}
]
}
"chosen_range_access_summary": {
"range_access_plan": {
"type": "range_scan",
"index": "idx_age",
"rows": 1,
"ranges": [
"21 <= age <= 21"
]
},
"rows_for_plan": 1,
"cost_for_plan": 0.61,
"chosen": true
}
chosen_range_access_summary部分的含義是在前一個步驟中分析了各類索引使用的方法及代價,得出了一定的中間結果之后,在summary階段匯總前一階段的中間結果確認最后的方案。
- range_access_plan:range掃描最終選擇的執行計劃。在該結構體中會給出執行計劃的type,使用的索引以及掃描行數。如果range_access_plan.type是index_roworder_intersect(即index merge)的話,在該結構體下還會列intersect_of結構體給出index merge的具體信息。
- rows_for_plan:該執行計劃的掃描行數
- cost_for_plan:該執行計劃的執行代價
- chosen:是否選擇該執行計劃
OPTIMIZER_TRACE的核心是在跟蹤記錄TRACE的JSON樹,通過這棵樹中的內容可以具體去分析優化器究竟做了什么事情,進行了哪些選擇,是基于什么原因做的選擇,選擇的結果及依據。這一系列都可以輔助驗證我們的一些觀點及優化,更好的幫助我們對我們的數據庫的實例進行調整。
由于OPTIMIZER_TRACE的內容非常復雜,本文由于篇幅的關系,無法在此對于每一個字段進行詳細的解讀,感興趣的讀者,可以參考MySQL官方文檔對于OPTIMIZER_TRACE的解讀。
三、引擎參數配置分析
上面的篇幅中,我們針對SQL層面進行了可能導致慢查詢的原因分析,MySQL的數據最終都會存儲在磁盤上,因此操作系統的I/O情況也會影響MySQL的運行性能,這一章節我們將從底層入手,從操作系統I/O層面分析MySQL執行性能問題。
1.I/O性能分析
linux系統查看 系統I/O情況,可以使用IOStat命令:
[root@VM-16-14-centos ~]# iostat -x 1 -m
Linux 3.10.0-1160.11.1.el7.x86_64 (VM-16-14-centos) 12/21/2022 _x86_64_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.82 0.00 0.67 0.07 0.00 98.44
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 1.67 0.04 2.49 0.00 0.02 17.55 0.01 2.34 3.74 2.31 0.29 0.07
scd0 0.00 0.00 0.00 0.00 0.00 0.00 7.10 0.00 0.89 0.89 0.00 0.88 0.00
avg-cpu自然就是CPU相關的指標,判斷IO問題時可以關注%iowait,其他指標的意義如下:
- r/s和w/s:合并過后的讀請求和寫請求的每秒請求數,可以當做IOPS來理解。
- rMB/s和wMB/s:磁盤的讀寫吞吐量。
- rrqm/s和wrqm/s:每秒合并的讀請求和寫請求數量。
- r_await和w_await:讀請求和寫請求的平均響應時間,包含真正的處理時間和隊列中的等待時間(ms)。
- avgrq-sz:平均每次設備I/O操作的數據大小 (扇區)。
- avgqu-sz:平均I/O隊列長度。
- await:平均每次設備I/O操作的等待時間 (毫秒)。
- scvtm:計算出來的平均IO響應時間,目前已經不準確,不用再關注。
- %util:如果使用了RAID或者SSD,則忽略這個指標,僅在單塊機械盤上準確。
一般來說,評價一塊IO設備(忽略機械盤的情況,沒有評價的意義)是否達到了高負載情況,可以看這幾個指標:r/s,w/s,rMB/s,wMB/s,r_await,w_await,avgqu-sz。
2.MySQL I/O參數
MySQL涉及到IO相關的參數會比較多,因此這里僅一部分經常用到的參數:
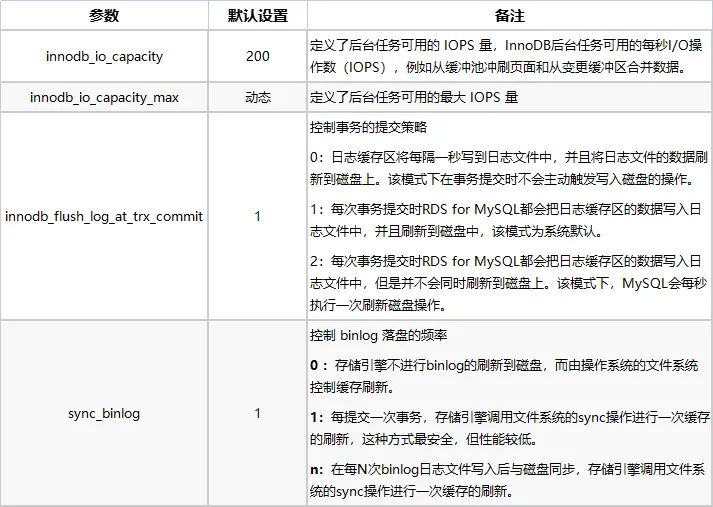
innodb_io_capacity和innodb_io_capacity_max是最直接限制IOPS的指標,大多數時候,SSD 可以設置成16000或者更高的數值,如果是云主機或者其他的共享存儲設備,則需要了解一下詳細的IOPS上限再具體調整。
trx_commit和 sync_binlog這兩個參數也放進來的原因是不同的參數組合對 IO的壓力也會有區別。
通常的用法是雙 1或者20(二零),參考官方文檔的描述,雙 1 在每次提交事務的時候都會刷盤,對IO的壓力要高不少;
20 則是滯后刷盤,對IO的壓力會較小,因此寫入QPS會高一些。
另外,可以關注到一個細節,innodb_io_capacity的描述對象是:后臺任務。這代表著 MySQL后臺的 flush,purge操作會受到這個參數設置的限制。
吞吐量和IOPS,一般情況下衡量IO系統性能最直觀的指標,并沒有特別的提及,主要原因還是判斷起來很簡單:如果iostat的指標已經達到或者接近了實際硬件的指標(比如達到了 75%),那么根據業務量增長的情況及早規劃硬件升級或者其他手段來分散讀寫壓力。
常規的手段,可以簡單的遵循以下場景來酌情使用:讀多寫少讀寫分離,寫多讀少拆庫拆表加緩存。
四、其他原因分析
1.網絡抖動
目前的互聯網應用服務,數據庫的部署與應用服務的部署,不會在一臺服務器上,那么應用服務器與數據庫服務器之間就需要通過網絡通信,一般情況來講,都會在同機房或同一個可用區進行部署,以保證網絡通信的質量。
但是難免可能會出現網絡抖動的情況,這種情況下,對應用服務來講,可能會出現一條SQL執行較慢的情況,但不是由于數據庫原因導致的,而是由于網絡原因導致的。
發現偶現的SQL執行慢,且SQL本身執行計劃沒有問題,可以從網絡的角度分析問題,在服務所在的機器ping數據庫服務器,查看響應時間,特別針對數據庫服務器與業務服務器跨城市的情況,如果沒有拉通專線訪問,會很容易出現網絡慢導致的問題。
2.單表數據量過大
上面我們提到了InnoDB的數據存儲方式是面向主鍵索引進行數據存儲的。InnoDB的數據表數量級超過幾千萬后,性能會出現下降,核心是由于B+Tree的數據結構導致的。
因此,當你的數據表超過幾千萬量級的時候,SQL執行即使全部命中的索引,也有可能出現執行慢的情況。
這個時候,建議考慮采用拆表。目前開源的優秀的分庫分表中間件有很多,例如sharing-JDBC、MyCat等,可以根據業務的實際情況進行選擇,這里就不過多的進行贅述。
總結
本篇,我們圍繞著一個問題:一條SQL執行較慢可能有哪些原因導致的?進行了研究,總結一下,大部分的慢查詢其實均由SQL書寫不當導致的,通過explain命令結合實際業務場景分析,可以解決絕大多數的慢查詢問題,對于一些疑難雜癥SQL,使用MySQL強大的SQL分析工具,也可以找出真正的問題原因。
另外,系統層面的分析也是必不可少的,作為開發人員,我們也需要掌握一些DBA的分析手段,檢查MySQL運行性能情況,保證數據庫服務的穩定運行。
>>>>參考資料
- 1.MySQL官方文檔The Slow Query Log:
- https://dev.mysql.com/doc/refman/5.7/en/slow-query-log.html
- https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html#sysvar_long_query_time
- https://dev.mysql.com/doc/refman/8.0/en/explain-output.html#explain-extra-information
- 2.MySQL or/in性能對比:
- https://www.cnblogs.com/chihirotan/p/7457204.html
- 3.MySQL explain結果Extra中"Using Index"與"Using where; Using index"區別探究:
- https://www.cnblogs.com/AcAc-t/p/mysql_explain_difference_between_using_index_and_using_where.html
- 4.MySQL General Thread States:
- https://dev.mysql.com/doc/refman/8.0/en/general-thread-states.html
- 5.innodb_flush_log_at_trx_commit和sync_binlog參數詳解:
- https://support.huaweicloud.com/bestpractice-rds/rds_02_0010.html
- 6.認識OPTIMIZER_TRACE:
- https://www.cnblogs.com/zhoujinyi/p/13889831.html
作者丨狐友宣光耀
來源丨公眾號:搜狐技術產品(ID:sohu-tech)





