
來源 | OSCHINA 社區
作者 | 華為云開發者聯盟
原文鏈接:https://my.oschina.NET/u/4526289/blog/10106268
本文分享自華為云社區《跑AI大模型的K8s與普通K8s有什么不同?》,作者:tsjsdbd。
得益于AI開始火的時候,云原生體系已經普及,所以當前絕大多數的AI底層都是基于Kubernetes集群進行的資源管理(不像大數據,早期大量使用Yarn進行資源管理,在云原生普及后,還得面臨Spark on K8s這種云原生改造)。

都知道云原生已經是Kubernetes的天下了,各大領域(大數據、互聯網,基因、制藥、時空、遙感、金融、游戲等)早已紛紛采納。那在面對大模型AI火熱的當下,咱們從程序員三大件“計算、存儲、網絡”出發,一起看看這種跑大模型AI的K8s與普通的K8s有什么區別?有哪些底層就可以構筑AI競爭的地方。
計算
Kubernetes是一個在大量節點上管理容器的系統,其主要功能總結起來,就是在想要啟動容器的時候,負責“找一個「空閑」節點,啟動容器”。但是它默認考慮的啟動因素(資源類)主要就是“CPU+內存”。就是容器指定“我要多少CPU+多少內存”,然后K8s找到符合這個要求的節點。
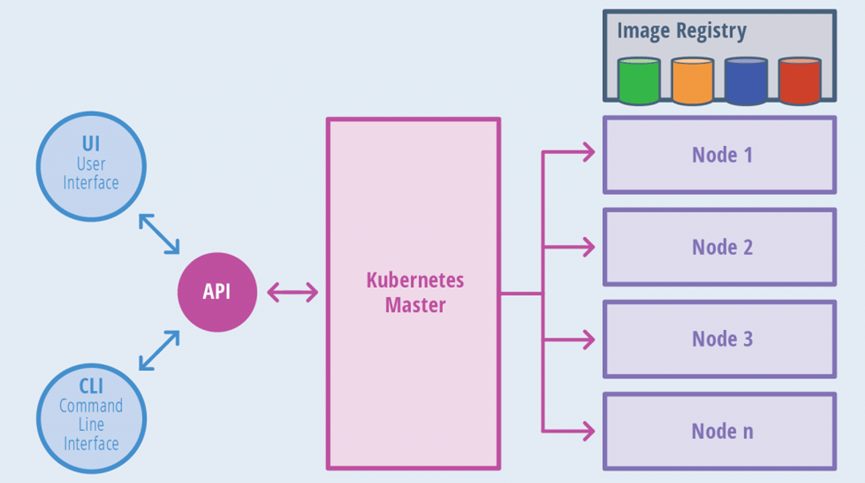
但是,當容器運行需要特殊“資源”的時候,K8s就熄火了。因為它不是認識“GPU”這種異構資源,不知道節點上面有多少“異構資源”(只統計剩余CPU+內存資源)。
K8s自己知道,異構資源千千萬,每種使用方法也不一樣,自己開發肯定搞不完。比如有RoCE網卡,GPU卡,NPU卡,FPGA,加密狗等等各種硬件。僅單純的GPU管理,就可以有“每個容器掛1個GPU”,或者“幾個容器共用1個GPU”,甚至“1個GPU切分成多個vGPU分別給不同容器用”多種用法。
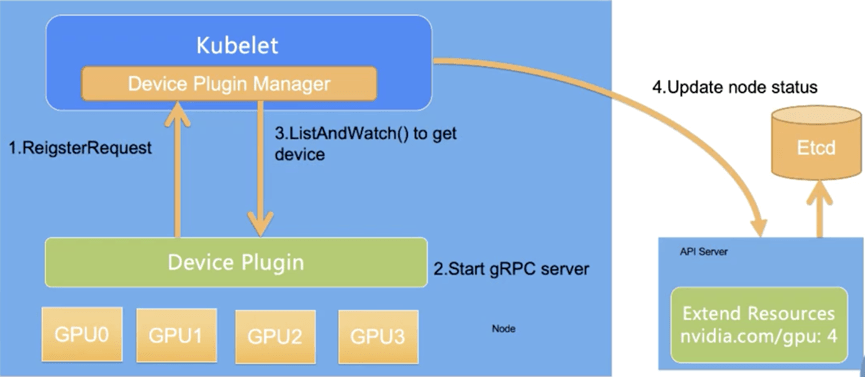
所以,為了成為一個通用的資源調度系統,它(K8s)搞了個插件框架,來輔助自己判斷節點有沒有“特殊資源”,叫做 Device-plugin插件。用戶需要自己完成這個Device-plugin的開發對接,來實時通知K8s節點上面GPU的使用情況,輔助K8s按需分配GPU算力。
總結就是咱們的AI集群里面,總會有一個GPU的Device-plugin用來輔助GPU調度。例如昇騰、含光等各家自研NPU,就算是最簡單的整卡調度,也得帶這個DP(Device-plugin)。

如果還需要MIG這樣利用vGPU功能來提升GPU的利用率的話,那么Device-plugin插件的實現也會復雜很多。因為A100之前沒有提供GPU虛擬化的標準實現,這個就看各家神通了。

其實目的都是大同小異的:就是增強Device-plugin插件邏輯,實現GPU資源的復用(顯存+算力隔離),來提升底層GPU整體的利用率。雖然K8s新版本1.27之后,可以使用DRA(Dynamic Resource Allocation)框架實現動態切分,但是當前絕大多數的集群,依然是使用DP完成這個邏輯。
而且,K8s設置的“異構資源”調度框架中,認為資源分配必須是“整數”的,即容器可以要1個GPU卡,但是不能要 0.5個GPU卡。所以想要實現多個容器,共用1個GPU卡的話(自己控制分時用,比如白天容器1用,晚上容器2用,這種性能比vGPU切分后用更好),還得增強DP邏輯(以及調度邏輯,后面會講)。
最后,異構硬件故障的檢測,任務的快速恢復,都需要這個DP的深入參與。
存儲
其實Kubernetes集群本身也不管存儲,主要管理的是容器“如何接入”存儲。通過引入PV和PVC概念,標準的K8s都可以做到將存儲掛載至容器中,使得容器里面的程序,像使用本地文件一樣的訪問遠端存儲。
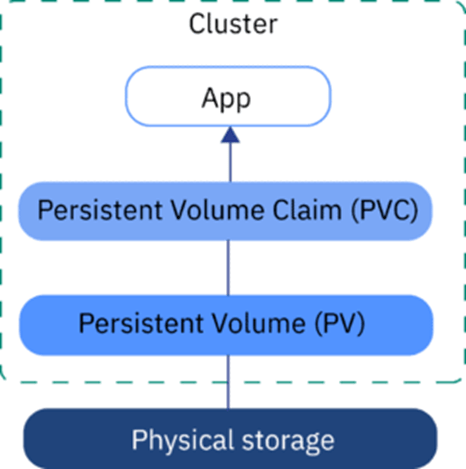
在大規模AI訓練場景下,樣本數據的大小還是很可觀的,基本都幾百T的級別。所以AI-Infrastructure對存儲的要求也會比較高。
更大的區別在于:訓練是多輪迭代來逼近目標范圍的,因為訓練數據量太大,數據無法全部放入內存,在每輪迭代結束后,需要重新從文件系統里讀取數據進行下一輪迭代的訓。即得重新訪問樣本進行一輪計算。那么如果每次都重新訪問“遠程”存儲,性能必將大受影響(100T數據,每個epoch重新讀一遍OBS桶,你想想那得多慢)。
所以如何將大量的樣本數據,就近緩存,就是AI+K8s系統需要重點考慮的問題。分布式緩存加速系統,就是其中一條路線。

常見的有Juicefs,Alluxio等產品,以及各云廠商提供的自研產品。它們的特點是:利用服務器本身就帶的高速存儲(比如nvme高速本地盤),來緩存樣本數據。并提供分布式文件系統,達到就近全量存儲的目的。這樣在多輪的epoch訓練中,可以大幅的提升樣本訪問速度,加快整體訓練進度。
所以建設or使用分布式緩存系統,也是AI平臺建設中的重要一環。
網絡
在Kubernetes的標準框架里,容器是只有1個網絡平面的。即容器里面,只有1個eth0網卡。所以無論是利用overlay實現容器隧道網絡,還是underlay實現容器網絡直通,其目的都是解決容器網絡“通與不通”的問題。
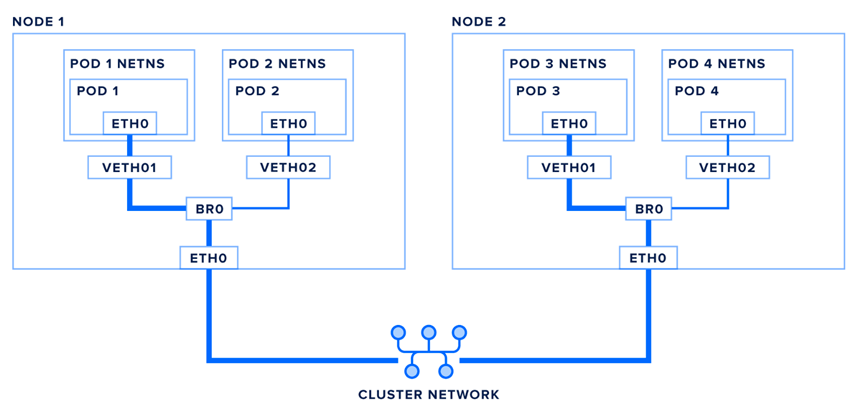
而大規模AI集群中,百億、千億級別參數量的大模型通常需要做分布式訓練,這時參數梯度等信息要在節點間交換,就需要使用RDMA網絡來傳遞。否則以普通以太網進行傳輸,其僅僅解決“通與不通”這種入門要求,參數信息傳的實在太慢了。
RDMA可以繞過TCP/IP協議棧,并且不需要CPU干預,直接從網卡硬件上開始網絡數據傳遞,網絡傳輸性能可以大幅的提升,大大加快訓練參數的交換。
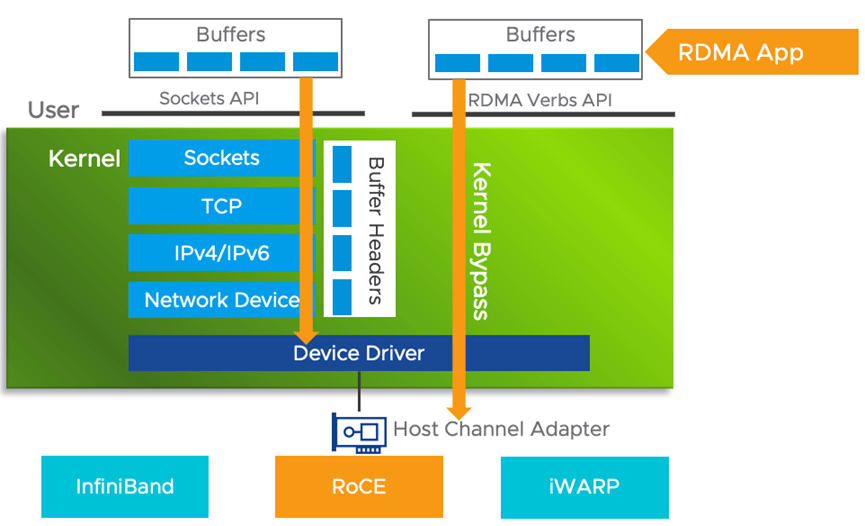
所以咱們的AI集群中,必須要將RDMA網絡管理起來,使得所有AI容器可以通過這條路,完成各種集合通信算法(AllReduce等)。
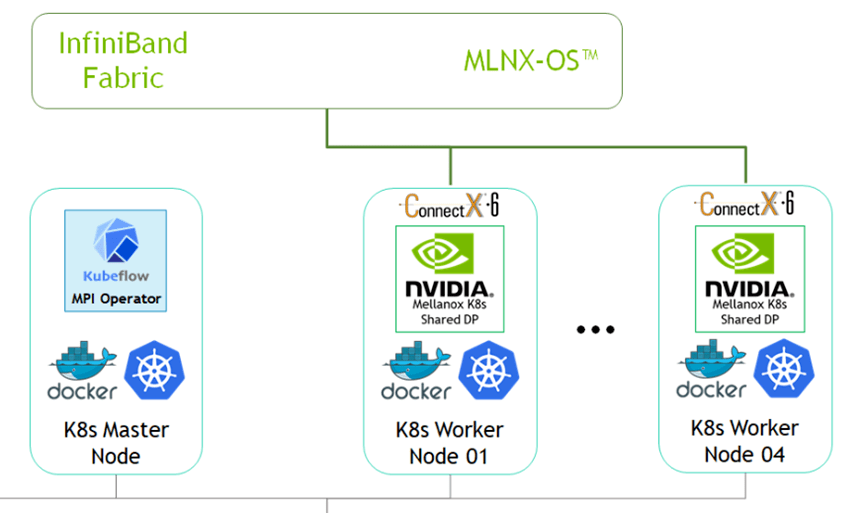
如上圖,除了「底部」那條咱們平時看到的容器網絡那條線外,頂部還有一個「參數面」網絡。一般成本考慮咱們都是走RoCE方案,即用IB網卡+以太網交換機(而不是IB專用交換機)實現。而且由于RDMA協議要求網絡是無損的(否則性能會受到極大的影響),而咱們要在以太網上實現無損網絡,就需要引入PFC(Priority-Based Flow Control)流控邏輯。
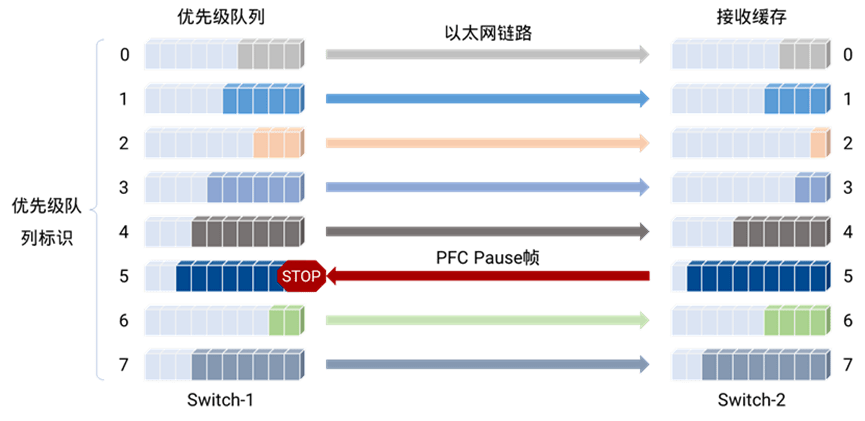
這個就需要同時在交換機和服務器RoCE網卡上,兩側同時配置PFC策略進行流控,以實現無損網絡。
可見,「參數面」網絡的管理,會比普通主機網絡,多一份PFC調優的復雜度。而且,由于NCCL性能直接影響訓練速度,所以定位NCCL性能掉速or調優NCCL性能,也是系統必須提供的運維能力之一。
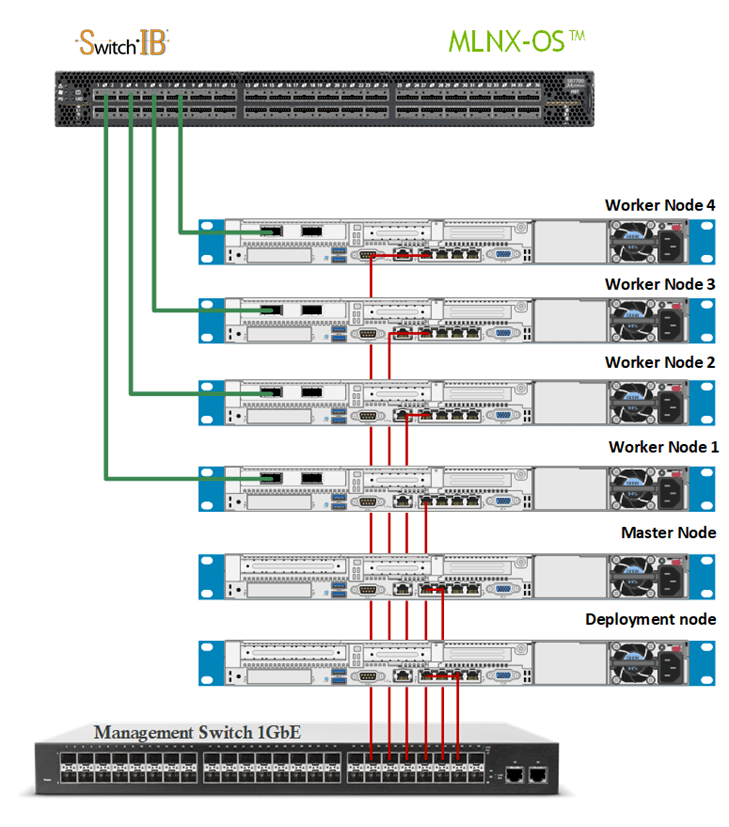
并且RoCE網卡的管理,也屬于“異構資源”,也需要開發Device-plugin來告知K8s如何分配這種RoCE網卡。而且GPU和RoCE網卡是需要進行聯合分配的,因為硬件連接關系,必須是靠近在一起的配對一起用,如下:
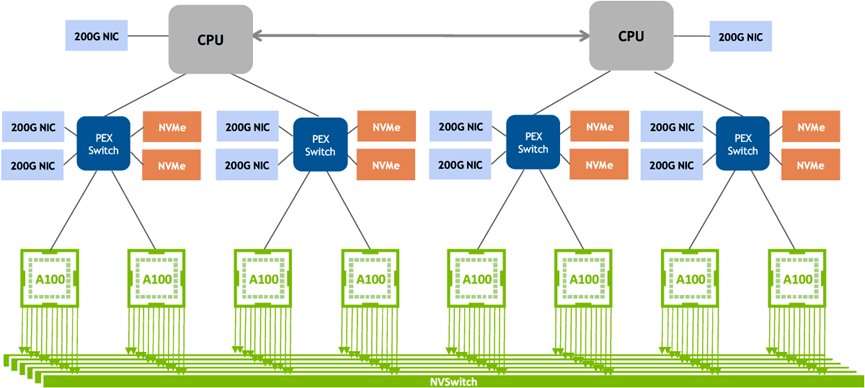
因此,除了「參數面」網絡設備的管理分配以外,還得關聯調度邏輯來感知這個RoCE網卡的硬件拓撲。
調度
標準K8s集群的容器調度,都是單個容器獨立考慮的:即取一個容器,找到其適合的節點,然后取下個容器調度。但是分布式AI訓練容器不一樣,它們是一組容器。這一組容器,必須同時運行,才可以進行集合通信,即所謂的All_or_Nothing。通常也會叫「Gang Scheduling」,這個是分布式AI場景的強訴求。否則會因為多個分布式作業在資源調度層面出現爭搶,導致出現資源維度的死鎖,結果是誰都沒法正常訓練。
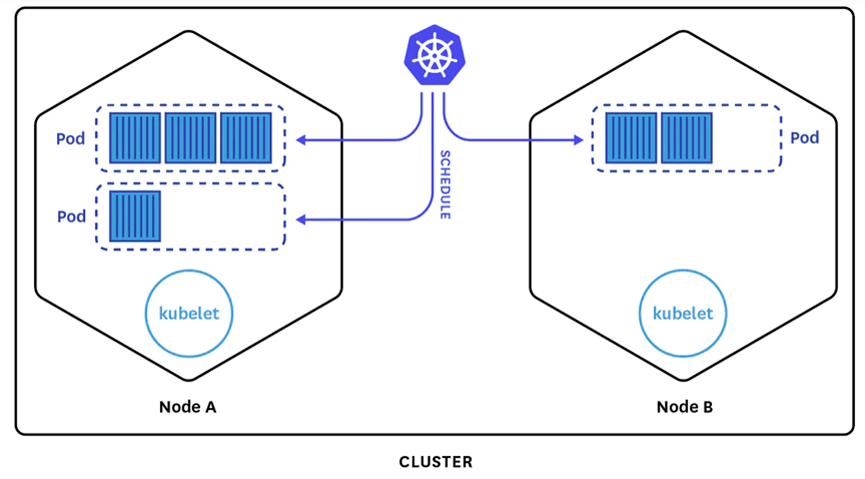
因此K8s自帶的Scheduler調度器對這種分布式AI訓練中的「pod-group」型資源調度就無能為力了。這時K8s提供的「調度插件」框架,又再次發揮作用。用戶可以自己開發調度器,集成到K8s集群中,實現自己的容器調度邏輯。
于是,各家又開始整活了。什么Coscheduling,Yunikorn,Volcano,Koordinator,Katalyst等紛紛上線。目的都差不多,先補Gang Scheduling基本功能,再補些MPI等輔助功能。

這里我們以Volcano為例,它除了完成分布式AI訓練中「Pod-group」這種容器組的調度,還實現了容器組之間「SSH免密登錄」,MPI任務組的「Hostfile文件」這些輔助實現。
小結
Kubernetes云原生管理平臺,已經成為AI數據中心的標準底座。由于AI-Infrastructure設備價格昂貴(參數面一根200Gb的網線要7000元,一臺8卡的GPU服務器,超150萬元),所以提升資源利用率是一個收益極大的途徑。
在提升資源利用率方法上,常見有(1)調度算法的增強和(2)業務加速 2種方式。
其中(1)調度增強上,又分Volcano這種pod-group組調度,來提升分布式訓練的資源利用率。以及通過Device-plugin來獲得vGPU算力切分或者多容器共用GPU卡的方式。
(2)業務加速路徑中,也有通過分布式緩存加速數據訪問的。以及通過參數面RDMA網絡來加速模型參數同步的。

以上這些就是唐老師小結的,與平常使用CPU類業務的K8s集群不太不一樣的地方。可見除了Kubernetes本身的復雜性外,要做好AI平臺底層的各項競爭力,還是需要投入不少人力的。對云原生AI-Infrastructure有興趣也可以多交流。





