
世界最強AI——ChatGPT可以通過各種考試,甚至輸出回答讓人難以辨別真假。
然而,它也有力所不及之處,那便是解決簡單的視覺邏輯難題。
在一項由屏幕上排列的一系列色彩鮮艷的塊組成的測試中,大多數(shù)人都能找出連接的圖案。

但是,根據(jù)研究人員今年 5 月的一份報告,GPT-4在一類圖案的測試中正確率僅為1/3,而在另一類圖案中正確率僅為3%。
 論文地址:https://arxiv.org/pdf/2305.07141.pdf
論文地址:https://arxiv.org/pdf/2305.07141.pdf
這項研究背后的團隊,旨在為了測試AI系統(tǒng)的能力提供一個更好的基準,并幫助解決GPT-4等大型語言模型的難題。
論文作者Melanie Mitchell表示,人工智能領域的人們正在為如何評估這些系統(tǒng)而苦苦掙扎。
AI評估如何有效?
在過去的兩三年里,LLM 在完成多項任務的能力上已經(jīng)超越了以前的人工智能系統(tǒng)。
它們的工作原理很簡單,就是根據(jù)數(shù)十億在線句子中單詞之間的統(tǒng)計相關性,在輸入文本時生成可信的下一個單詞。
對于基于LLM構(gòu)建的聊天機器人來說,還有一個額外的元素:人類訓練員提供了大量反饋,以調(diào)整機器人的反應。
令人驚嘆的是,這種類似于自動完成的算法是在大量人類語言存儲的基礎上訓練出來的,其能力的廣度令人嘆為觀止。
其他人工智能系統(tǒng)可能會在某項任務中擊敗 LLM,但它們必須在與特定問題相關的數(shù)據(jù)上進行訓練,無法從一項任務推廣到另一項任務。

哈佛大學的認知科學家Tomer Ullman表示,從廣義上講,對于LLM背后發(fā)生的事情,兩個陣營的研究人員持有截然相反的觀點。一些人將算法的成就歸因于推理或理解的閃光點。其他人(包括他自己和Mitchell等人)則要謹慎得多。
討論雙方的研究人員表示,像邏輯謎題這樣揭示人類與AI系統(tǒng)能力差異的測試,是朝著正確方向邁出的一步。
紐約大學認知計算科學家Brenden Lake說,這種基準測試有助于揭示當今機器學習系統(tǒng)的不足之處,并理清了人類智能的要素。
關于如何最好地測試LLM,以及這些測試意義的研究也很實用。
Mitchell說,如果要將LLM應用于現(xiàn)實世界的各個領域,比如醫(yī)學、法律。那么了解它們的能力極限就非常重要。
圖靈測試死了嗎?
長期以來,機器智能最著名的測試一直是圖靈測試。
圖靈測試是英國數(shù)學家和計算大師艾倫·圖靈在1950年提出,當時計算機還處于起步階段。
圖靈提出了一個評估,他稱之為「模仿游戲」。
在這個場景中,「人類法官」與一臺計算機、和一個看不見的人進行簡短的、基于文本的對話。
這個人類能可靠地檢測出哪臺是計算機嗎?圖靈表示,這是一個相當于「機器能否思考」的問題。

Mitchell指出,圖靈并沒有具體說明場景的許多細節(jié),因此沒有確切的標準可循。
其他研究人員認為,GPT-4和其他LLM現(xiàn)在很可能通過了「圖靈測試」,因為它們可以騙過很多人,至少是在短對話中。
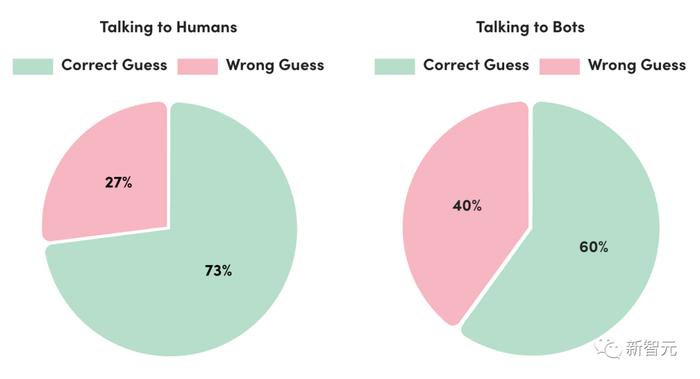
5月,AI21實驗室的研究人員報告說,超過150萬人玩過他們基于圖靈測試的在線游戲。
玩家正確識別機器人的比例僅為60%,這并不比偶然性好多少。
然而,在這種游戲中,熟悉LLM的研究人員可能仍然會獲勝。通過利用AI系統(tǒng)的已知弱點,就會很容易發(fā)現(xiàn)LLM。
關鍵是要讓LLM走出自己的「舒適區(qū)」。
谷歌軟件工程師François Chollet建議,向LLM演示一些場景,這些場景是LLM在其訓練數(shù)據(jù)中經(jīng)常看到的場景的變體。在許多情況下,LLM的回答方式是,吐出最有可能與訓練數(shù)據(jù)中的原始問題相關聯(lián)的單詞,而不是針對新情景給出的正確答案。
然而,Chollet和其他人對,把以欺騙為中心的測試作為計算機科學的目標持懷疑態(tài)度。
基準測試有危險
相反,研究人員在評估人工智能系統(tǒng)時,通常不采用圖靈測試,而是使用旨在評估特定能力(如語言能力、常識推理和數(shù)學能力)表現(xiàn)的基準。
越來越多的研究團隊也開始轉(zhuǎn)向,為人類設計的學術和專業(yè)考試。
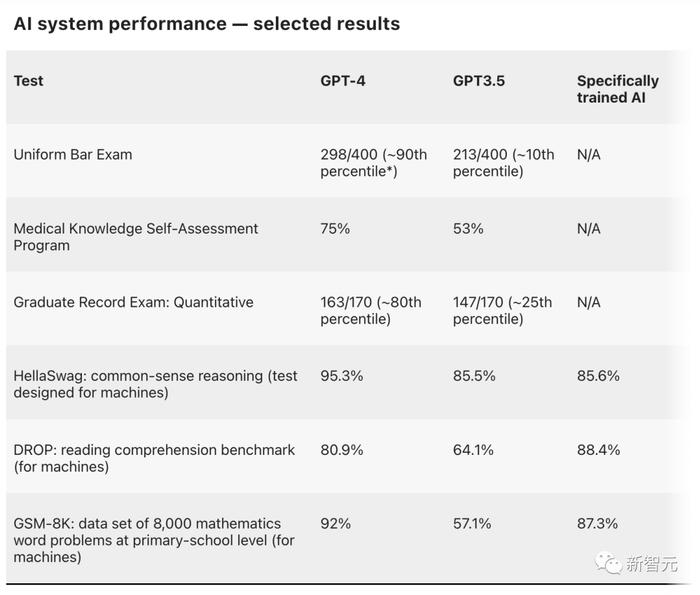
GPT-4發(fā)布時,OpenAI在一系列專為機器設計的基準測試中測試了其性能,包括閱讀理解、數(shù)學和編碼。
根據(jù)技術報告,GPT-4在其中大部分測試中都取得了優(yōu)異成績。
此外,GPT-4還參加了30項考試,GRE、評估美國醫(yī)生臨床知識現(xiàn)狀的考試、為美國高中生設計的各種特定科目的考試等等。
后來,有研究人員提到的一個挑戰(zhàn)是,模型是在大量文本中訓練出來的,它們可能已經(jīng)在訓練數(shù)據(jù)中看到過類似的問題,因此實際上可能是在尋找答案。這個問題其實被「污染」了。
研究人員還指出,LLM在考試問題上的成功可能一擊就破,可能無法轉(zhuǎn)化為在現(xiàn)實世界中所需的強大能力。
在解釋這些基準的含義時,還有一個更深層次的問題。
一個在考試中表現(xiàn)出色的人,一般可以被認為在其他認知測試中表現(xiàn)出色,并且掌握了某些抽象概念。
然而,LLM工作方式與人類截然不同。因此,用我們評判人類方式,來推斷人工智能系統(tǒng),并不總是有效的。
這可能是因為LLM只能從語言中學習。如果沒有在物理世界中,它們無法像人那樣體驗語言與物體、屬性和情感的聯(lián)系。
很明顯,他們理解單詞的方式與人類不同。
另一方面,LLM 也擁有人類所不具備的能力,比如,它們知道人類寫過的幾乎每一個單詞之間的聯(lián)系。
OpenAI的研究員Nick Ryder也認為,一項測試的表現(xiàn)可能,不會像獲得相同分數(shù)的人那樣具有普遍性。
他表示,我認為,我們不應該從對人類和大型語言模型的評估中得出任何等價的結(jié)論。OpenAI 的分數(shù) "并不代表人類的能力或推理能力。它的目的是說明模型在該任務中的表現(xiàn)如何。
人工智能研究人員表示,為了找出LLM的優(yōu)勢和劣勢,需要更廣泛和嚴格的審查。豐富多彩的邏輯謎題可能是其中的一個候選者。
邏輯謎題登場
2019年,在LLM爆發(fā)之前,Chollet在網(wǎng)上發(fā)布了,自己創(chuàng)建的一種新的人工智能系統(tǒng)邏輯測試,稱為抽象和推理語料庫(ARC) 。
解題者要看幾個方格變?yōu)榱硪环N圖案的可視化演示,并通過指出下一個方格將如何變換來表明他們已經(jīng)掌握了變化的基本規(guī)則。
Chollet表示,ARC 捕捉到了「人類智慧的標志」。從日常知識中進行抽象,并將其應用于以前從未見過的問題的能力。
當前,幾個研究團隊現(xiàn)在已經(jīng)使用ARC來測試LLM的能力,沒有一個能實現(xiàn)接近人類的表現(xiàn)。
Mitchell和她的同事制作了一系列新的謎題——被稱為ConceptARC——它們的靈感來自ARC,但在兩個關鍵方面有所不同。
ConceptARC測試更容易。Mitchell的團隊希望確保基準測試,不會錯過機器能力的進步,哪怕是很小的進步。另一個區(qū)別是,團隊選擇特定的概念進行測試,然后為每個主題的變體概念創(chuàng)建一系列謎題。
性能差意味著什么
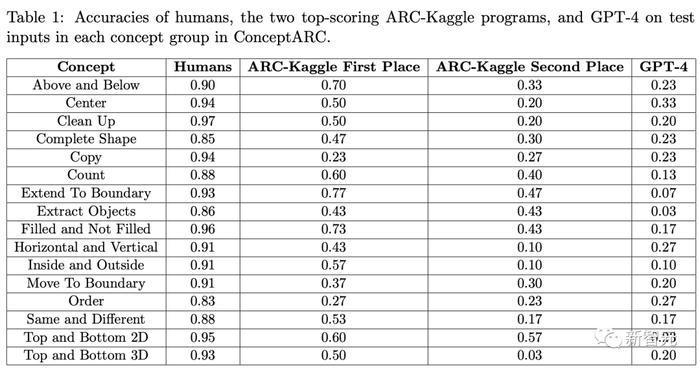
研究人員將ConceptARC任務分配給GPT-4和400名在線應征者。
人類在所有概念組中的平均得分率為 91%(其中一組為 97%);GPT-在一組中的得分率為33%,在所有其他組中得分不到30%。
研究人員證明,AI仍然無法接近人類的水平。然而令人驚訝的是,它能解決一些從未被訓練過的問題。
研究小組還測試了Chollet競賽中的領先聊天機器人。
總的來說,他們比GPT-4做得更好,但表現(xiàn)比人類差,在一個類別中得分最高,為77%,但在大多數(shù)類別中得分不到60%。
不過,Bowman表示,GPT-4在ConceptARC考試中的失利并不能證明它缺乏基本的抽象推理能力。
其實,ConceptARC對GPT-4有些不利,其中一個原因是它是一項視覺測試。
目前,GPT-4僅能接受文本作為輸,因此研究人員給GPT-4提供了代表圖像的數(shù)字數(shù)組。相比之下,人類參與者看到了圖像。
推理論證
Bowman指出,與其他實驗綜合起來表明,LLM至少已經(jīng)獲得了對抽象概念進行推理的基本能力。
但LLM的推理能力總體上是「參差不齊的」,比人類的推理能力更有限。不過,隨著LLM的參數(shù)規(guī)模擴大,推理能力相應地也會提高。
許多研究人員一致認為,測試LLM抽象推理能力和其他智力跡象的最佳方法,仍然是一個開放的、未解決的問題。





