擊這里在線咨詢客服")

2023年,科技圈最火的無疑是大模型。然而,大模型的真正商用落地還需要一定時間,但大模型的“上游”卻已經(jīng)感受到了火熱的氛圍。
什么是大模型的上游呢?有兩個關(guān)鍵的領(lǐng)域,一個是GPU,典型的如英偉達(dá),今年英偉達(dá)的股價和業(yè)績都受益頗深,這已經(jīng)廣為人知了。還有另一個隱藏的“大模型軍火商”也開始走向前臺,那就是向量數(shù)據(jù)庫。在google Trends上搜索Vector Database(向量數(shù)據(jù)庫),其關(guān)注度先顯著提升。
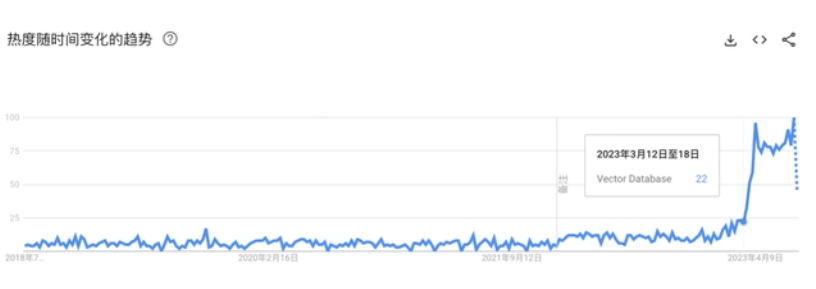
來源:Google Trends
僅在今年4月,就有多家向量數(shù)據(jù)庫公司獲得融資,典型的包括:Pinecone獲得1億美元B輪融資;Weaviate獲得5000萬美元B輪融資;Chroma獲1800萬美元種子輪融資;Qdrant獲750萬美元種子輪融資;Fabarta ArcVector,獲得億元人民幣的 Pre-A 輪融資。
除了初創(chuàng)公司相繼融資,諸如騰訊云、星環(huán)科技、聯(lián)匯科技等很多廠商都相繼推出向量數(shù)據(jù)庫產(chǎn)品。
一夜之間,向量數(shù)據(jù)庫成為數(shù)據(jù)庫領(lǐng)域最炙手可熱的明星。在人工智能技術(shù)的推動下,大數(shù)據(jù)變得越來越重要,而在大數(shù)據(jù)中尋找有用信息的最有效方法之一就是通過向量數(shù)據(jù)庫。
隨著向量數(shù)據(jù)庫技術(shù)的不斷發(fā)展,我們可以預(yù)見,它將在未來的大數(shù)據(jù)和人工智能領(lǐng)域發(fā)揮越來越重要的作用。本文將深入探討向量數(shù)據(jù)庫的內(nèi)涵、發(fā)展歷程、應(yīng)用場景以及與大模型的關(guān)系,同時也會對向量數(shù)據(jù)庫未來的發(fā)展趨勢進(jìn)行前瞻性分析。
向量數(shù)據(jù)庫與人工智能是一對“雙生子”
在信息化社會中,數(shù)據(jù)的產(chǎn)生、儲存和處理都成為了現(xiàn)代生活和工作中不可或缺的一部分。在這背景下,向量數(shù)據(jù)和向量數(shù)據(jù)庫出現(xiàn)并發(fā)展起來,為我們解決了大量的問題,但同時也引出了新的問題和挑戰(zhàn)。
首先,我們需要明白什么是向量數(shù)據(jù)。在人工智能時代,傳統(tǒng)的結(jié)構(gòu)化數(shù)據(jù)(如文本、數(shù)字等)已經(jīng)無法滿足我們的需求。而向量數(shù)據(jù),是一種高維數(shù)據(jù),它可以在多維空間中表示復(fù)雜的關(guān)系和模式,可以用來表示圖像、語音、視頻等非結(jié)構(gòu)化數(shù)據(jù),也可以用來表示深度學(xué)習(xí)模型的特征。
典型的向量數(shù)據(jù)包括:
圖像向量,通過深度學(xué)習(xí)模型提取的圖像特征向量,這些特征向量捕捉了圖像的重要信息,如顏色、形狀、紋理等,可以用于圖像識別、檢索等任務(wù);
文本向量,通過詞嵌入技術(shù)如word2Vec、BERT等生成的文本特征向量,這些向量包含了文本的語義信息,可以用于文本分類、情感分析等任務(wù);
語音向量,通過聲學(xué)模型從聲音信號中提取的特征向量,這些向量捕捉了聲音的重要特性,如音調(diào)、節(jié)奏、音色等,可以用于語音識別、聲紋識別等任務(wù)。
這些向量數(shù)據(jù)由于其高維性和稀疏性,不能有效地使用傳統(tǒng)的關(guān)系型數(shù)據(jù)庫(如MySQL)或者NoSQL數(shù)據(jù)庫(如MongoDB)進(jìn)行存儲和檢索。比如,如果把一個300維的文本向量作為一行數(shù)據(jù)存儲在MySQL中,那么在進(jìn)行高維空間的近鄰查詢(比如,找出與某個文本向量在語義上最相似的文本向量)時,性能會非常低下。
向量數(shù)據(jù)庫為向量數(shù)據(jù)提供了專門的存儲和索引機(jī)制。在向量數(shù)據(jù)庫中,向量數(shù)據(jù)被存儲為高維空間中的點(diǎn),數(shù)據(jù)庫會為這些點(diǎn)建立索引,常用的索引方法有KD-樹、BB-Tree、HNSW等。這些索引結(jié)構(gòu)使得向量數(shù)據(jù)庫可以高效地進(jìn)行向量間的相似度查詢,如余弦相似度、歐幾里得距離等,從而極大地提升了處理向量數(shù)據(jù)的效率。
向量數(shù)據(jù)庫的發(fā)展歷程可以大致劃分為三個階段:
第一階段是向量數(shù)據(jù)的初級階段,這個階段的向量數(shù)據(jù)庫主要是以文件形式存儲向量數(shù)據(jù),沒有有效的索引和查詢能力,典型的產(chǎn)品如早期的Lucene等。
第二階段是向量數(shù)據(jù)的發(fā)展階段,這個階段的向量數(shù)據(jù)庫開始使用KD樹等索引結(jié)構(gòu),可以實(shí)現(xiàn)一定的查詢性能,但是在高維空間的查詢效率還不高,典型的產(chǎn)品有FAISS、Annoy等。
第三階段是向量數(shù)據(jù)的成熟階段,這個階段的向量數(shù)據(jù)庫已經(jīng)可以實(shí)現(xiàn)高效的向量索引和查詢,可以處理海量的高維向量數(shù)據(jù),典型的產(chǎn)品有Milvus、Elasticsearch等。
需要指出的是,向量數(shù)據(jù)庫是伴隨著人工智能的發(fā)展而發(fā)展的,并在不斷滿足人工智能的數(shù)據(jù)存儲需求過程中持續(xù)演進(jìn)。
人工智能,尤其是深度學(xué)習(xí),經(jīng)歷了從小規(guī)模到大規(guī)模的變革,涉及的數(shù)據(jù)量也從MB級別增長到TB甚至PB級別,這引發(fā)了一個問題:如何有效地存儲和處理大規(guī)模的向量數(shù)據(jù)。這正是向量數(shù)據(jù)庫的強(qiáng)項(xiàng),它能夠處理如此大規(guī)模的數(shù)據(jù),并且在復(fù)雜查詢和實(shí)時響應(yīng)等方面也表現(xiàn)出色。
深度學(xué)習(xí)不僅推動了數(shù)據(jù)規(guī)模的擴(kuò)大,也使得數(shù)據(jù)查詢需求變得更加復(fù)雜。現(xiàn)在的深度學(xué)習(xí)應(yīng)用需要進(jìn)行的查詢不再只是簡單的精確匹配,而是需要進(jìn)行復(fù)雜的相似度查詢,例如找出與給定向量最相似的向量,或者查詢在一定范圍內(nèi)的所有向量。這些復(fù)雜的查詢需求已經(jīng)超出了傳統(tǒng)數(shù)據(jù)庫的處理能力,而向量數(shù)據(jù)庫則能夠提供滿足這些需求的解決方案。
此外,隨著深度學(xué)習(xí)在更多的領(lǐng)域得到應(yīng)用,比如在線推薦、廣告投放、自動駕駛等,實(shí)時響應(yīng)的需求也越來越強(qiáng)烈。在這些應(yīng)用中,系統(tǒng)必須能夠?qū)崟r處理大規(guī)模向量數(shù)據(jù),并且提供快速響應(yīng)。在這方面,向量數(shù)據(jù)庫憑借其高效的索引結(jié)構(gòu)和查詢算法,能夠?qū)崿F(xiàn)大規(guī)模向量數(shù)據(jù)的實(shí)時處理,滿足了這些實(shí)時性的需求。
越來越多的人工智能應(yīng)用需要處理跨模態(tài)的數(shù)據(jù),比如結(jié)合圖像、文本、音頻等不同類型的數(shù)據(jù)進(jìn)行分析和預(yù)測。這就要求數(shù)據(jù)庫不僅需要能夠處理單一模態(tài)的向量數(shù)據(jù),還需要支持跨模態(tài)向量數(shù)據(jù)的存儲和查詢,這也是向量數(shù)據(jù)庫未來的一個重要發(fā)展方向。
綜上,人工智能的發(fā)展催生了向量數(shù)據(jù)庫的需求,而向量數(shù)據(jù)庫的發(fā)展又反過來推動了人工智能的發(fā)展。在這種良性互動中,向量數(shù)據(jù)庫的應(yīng)用越來越廣泛,其在人工智能發(fā)展中的重要性也日益顯現(xiàn)。
大模型帶火了向量數(shù)據(jù)庫
在人工智能領(lǐng)域,最近的一個重要趨勢是大模型的興起。在大模型的世界里,我們面臨著處理和管理大規(guī)模向量數(shù)據(jù)的挑戰(zhàn),而向量數(shù)據(jù)庫,就是為了滿足這個需求而不斷發(fā)展著。
那么,向量數(shù)據(jù)庫跟大模型是什么關(guān)系呢?
帶著這個問題,數(shù)據(jù)猿采訪了聯(lián)匯科技首席科學(xué)家趙天成博士。趙博士認(rèn)為,向量數(shù)據(jù)庫和大模型技術(shù)兩者都是人工智能領(lǐng)域的重要技術(shù)基座。其中,向量數(shù)據(jù)庫提供了存儲、記憶能力,大模型提供了問題處理和分析能力。與傳統(tǒng)數(shù)據(jù)庫相比,向量數(shù)據(jù)庫使用向量化計算,高速地處理大規(guī)模的、高維的、復(fù)雜數(shù)據(jù),例如圖像、音頻和視頻等,并支持復(fù)雜查詢操作,擴(kuò)展到多個節(jié)點(diǎn),以處理更大規(guī)模的數(shù)據(jù)。
大模型具有的強(qiáng)大的學(xué)習(xí)和表示能力,能夠處理龐大和復(fù)雜的數(shù)據(jù),并從中提取出有用的特征和模式,并通過大規(guī)模的數(shù)據(jù)集預(yù)訓(xùn)練,加速迭代精進(jìn),提升模型性能,向量數(shù)據(jù)庫為大模型提供了高效的數(shù)據(jù)存儲和查詢支撐,是大模型落地應(yīng)用的重要條件。
大模型與向量數(shù)據(jù)庫兩項(xiàng)關(guān)鍵技術(shù)的深度融合應(yīng)用為通用人工智能(AGI)的實(shí)現(xiàn)提供了可靠路徑。以聯(lián)匯科技為例,依托技術(shù)創(chuàng)新,聯(lián)匯科技研發(fā)OmBot自主智能體,它集認(rèn)知、記憶、思考、行動四大核心能力,作為一種自動、自主的智能體,它能夠感知環(huán)境、自主決策并且具備短期與長期記憶的計算機(jī)模型,模仿人類大腦工作機(jī)制,根據(jù)任務(wù)目標(biāo),主動完成任務(wù)。
接下來,我們就向量數(shù)據(jù)庫對于大模型的應(yīng)用價值進(jìn)行更深入的展開分析:
GPT-4等大模型,通過學(xué)習(xí)大量的訓(xùn)練數(shù)據(jù),能夠提供高準(zhǔn)確度的預(yù)測和生成結(jié)果,從而在各種復(fù)雜的任務(wù)中表現(xiàn)出色。然而,這也帶來了大規(guī)模向量數(shù)據(jù)處理的需求,包括存儲、索引和查詢。傳統(tǒng)的數(shù)據(jù)庫技術(shù),無論是關(guān)系型數(shù)據(jù)庫還是NoSQL數(shù)據(jù)庫,都在處理這種類型的數(shù)據(jù)時面臨挑戰(zhàn)。
首先,大模型的訓(xùn)練需要大量的輸入數(shù)據(jù),這些數(shù)據(jù)通常是高維度的向量。傳統(tǒng)的數(shù)據(jù)庫在存儲這種高維度數(shù)據(jù)時,往往需要大量的存儲空間,而且查詢效率也相對較低。向量數(shù)據(jù)庫通過優(yōu)化的數(shù)據(jù)結(jié)構(gòu)和索引算法,可以高效地存儲和查詢大規(guī)模的向量數(shù)據(jù),從而大大提高了大模型訓(xùn)練的效率。
其次,在訓(xùn)練過程中,大模型需要根據(jù)輸入數(shù)據(jù)的相似度進(jìn)行學(xué)習(xí)。這需要數(shù)據(jù)庫提供高效的相似度查詢功能,而這是傳統(tǒng)數(shù)據(jù)庫往往無法滿足的。向量數(shù)據(jù)庫通過使用諸如KD樹、球樹等高效的索引結(jié)構(gòu),可以快速找出與給定向量最相似的數(shù)據(jù),從而支持大模型的訓(xùn)練需求。
此外,在模型訓(xùn)練完成后,需要對新的輸入數(shù)據(jù)進(jìn)行預(yù)測。這同樣需要高效的相似度查詢功能,以找出與新輸入數(shù)據(jù)最相似的訓(xùn)練數(shù)據(jù),然后基于這些數(shù)據(jù)進(jìn)行預(yù)測。向量數(shù)據(jù)庫在這方面同樣展現(xiàn)出了優(yōu)越的性能,從而支持了大模型在實(shí)際應(yīng)用中的部署。
在人工智能領(lǐng)域,通用大模型的微調(diào)成為了一種常見且有效的策略。這種策略允許模型學(xué)習(xí)一種更具體、更詳細(xì)的領(lǐng)域知識,從而能更好地解決領(lǐng)域內(nèi)的問題。然而,這個微調(diào)過程的成功在很大程度上依賴于向量數(shù)據(jù)庫的功能和性能。
當(dāng)我們將通用大模型微調(diào)為專用大模型時,這個過程需要對特定領(lǐng)域的大量數(shù)據(jù)進(jìn)行深入學(xué)習(xí)。這些數(shù)據(jù)通常包含大量高維度的特征向量,例如在自然語言處理中的詞向量、在圖像識別中的像素向量等。這些高維度向量數(shù)據(jù)的處理,傳統(tǒng)的數(shù)據(jù)庫無法滿足其性能需求,而向量數(shù)據(jù)庫卻能有效地管理這些數(shù)據(jù),支持對這些數(shù)據(jù)的高效檢索和查詢。
一個關(guān)鍵步驟是需要進(jìn)行大量的相似度查詢。為了尋找和給定向量最相似的向量,向量數(shù)據(jù)庫通常采用特定的索引結(jié)構(gòu),如KD樹、球樹等,這些索引結(jié)構(gòu)允許在大規(guī)模高維向量數(shù)據(jù)中進(jìn)行高效的近似最近鄰查找。這種查詢效率的提升,直接導(dǎo)致了模型微調(diào)過程的效率提升。微調(diào)過程中,模型需要頻繁地讀取數(shù)據(jù)進(jìn)行訓(xùn)練,向量數(shù)據(jù)庫可以提供高效的讀取能力。此外,模型訓(xùn)練過程中的更新數(shù)據(jù)也需要寫回數(shù)據(jù)庫,向量數(shù)據(jù)庫的高效寫入性能也能滿足這一需求。
以聯(lián)匯科技的向量數(shù)據(jù)庫產(chǎn)品Om-iBase為例,Om-iBase基于智能算法提取需存儲內(nèi)容的特征,使用AI深度學(xué)習(xí)模型和自監(jiān)督學(xué)習(xí)技術(shù),對文本、圖片、音頻和視頻等非結(jié)構(gòu)化數(shù)據(jù)進(jìn)行特征提取,有效實(shí)現(xiàn)非結(jié)構(gòu)化數(shù)據(jù)向量化存儲,并通過向量化編輯器、向量索引加速技術(shù)(ANN)、向量聚類、向量降緯、數(shù)據(jù)聚類、異常分析等核心技術(shù)與算法,確保向量分析的全面性和檢索的準(zhǔn)確性,實(shí)現(xiàn)數(shù)據(jù)庫的高性能檢索、高性能分析。此外,Om-iBase提供完整的SDK支持和靈活可配的插件體系,開發(fā)者可以最大化的自主發(fā)覺潛能。
總的來說,大模型的發(fā)展催生了向量數(shù)據(jù)庫的需求,而向量數(shù)據(jù)庫的發(fā)展又反過來推動了大模型的發(fā)展。這種良性循環(huán),使得向量數(shù)據(jù)庫在人工智能領(lǐng)域獲得了前所未有的關(guān)注和應(yīng)用,其重要性也日益突出。同時,向量數(shù)據(jù)庫的發(fā)展也帶來了一系列的技術(shù)挑戰(zhàn)和研究熱點(diǎn),包括如何提高存儲和查詢效率、如何支持復(fù)雜的查詢需求、如何提高易用性等,這將是未來研究的重要方向。
向量數(shù)據(jù)庫八大技術(shù)趨勢
面對著未來,向量數(shù)據(jù)庫的發(fā)展將會和大模型的發(fā)展更加緊密地結(jié)合,共同迎接一系列的新機(jī)遇和新挑戰(zhàn)。在這個過程中,向量數(shù)據(jù)庫的技術(shù)將會發(fā)展出一些重要的趨勢。在文章最后部分,我們總結(jié)出了向量數(shù)據(jù)庫的八大技術(shù)趨勢。
1、更好的分布式與并行計算能力
隨著數(shù)據(jù)規(guī)模的不斷擴(kuò)大以及大模型對計算能力的強(qiáng)烈需求,向量數(shù)據(jù)庫必須對分布式與并行計算能力進(jìn)行深度優(yōu)化。更高效的分布式與并行計算可以讓大規(guī)模向量數(shù)據(jù)在多個計算節(jié)點(diǎn)間進(jìn)行分配,使得查詢、排序等操作能夠并發(fā)進(jìn)行,大大縮短了計算時間。在具體實(shí)施上,分布式系統(tǒng)設(shè)計、數(shù)據(jù)切分策略、負(fù)載均衡算法等都將是挑戰(zhàn)與機(jī)遇。
2、實(shí)時處理能力提升
對于許多AI應(yīng)用來說,如自動駕駛、智能客服等,它們的決策過程需要在瞬息之間完成。這就要求向量數(shù)據(jù)庫有高效的實(shí)時處理能力,即使是對大規(guī)模的向量數(shù)據(jù),也能在最短的時間內(nèi)找到最匹配的結(jié)果。因此,優(yōu)化查詢算法、提升數(shù)據(jù)存取效率,甚至是實(shí)現(xiàn)實(shí)時數(shù)據(jù)更新,都將是實(shí)時處理能力提升所需面對的關(guān)鍵問題。
3、高級查詢功能
隨著用戶對數(shù)據(jù)處理需求的復(fù)雜化,傳統(tǒng)的簡單查詢方式已經(jīng)無法滿足需求。高級查詢功能,如范圍查詢、最近鄰查詢,甚至基于語義的查詢等,將是向量數(shù)據(jù)庫的必備功能。這不僅需要向量數(shù)據(jù)庫本身的技術(shù)突破,還需要與AI技術(shù)深度融合,通過理解數(shù)據(jù)的深層含義,提供更符合用戶需求的查詢結(jié)果。
4、硬件加速尤其是GPU加速
CPU在處理大規(guī)模向量數(shù)據(jù)時,可能會遇到瓶頸。為了更高效地處理數(shù)據(jù),硬件加速將是一種有效的解決方案。例如,利用GPU的強(qiáng)大并行計算能力,或者利用定制的AI芯片,都可以大大提高向量數(shù)據(jù)庫的處理能力。但這也會帶來新的挑戰(zhàn),比如如何將數(shù)據(jù)庫操作高效地映射到硬件操作,如何管理和調(diào)度硬件資源等。
5、針對不同類型大模型的性能優(yōu)化
不同類型的大模型對數(shù)據(jù)的處理和計算需求可能會有所不同。向量數(shù)據(jù)庫需要能夠針對這些差異進(jìn)行優(yōu)化,以提供最佳的性能。這可能包括特定類型模型的存儲優(yōu)化,或者是查詢優(yōu)化,甚至是針對特定類型模型的特殊查詢功能等。
6、多模態(tài)數(shù)據(jù)處理能力
隨著大模型向多模態(tài)發(fā)展,如圖文混合模型、音視頻混合模型等,對應(yīng)的數(shù)據(jù)也將會更為復(fù)雜多元。向量數(shù)據(jù)庫需要能夠有效地處理這些多模態(tài)數(shù)據(jù)。這不僅需要數(shù)據(jù)庫本身的技術(shù)突破,也需要和AI模型的深度融合,以理解和處理多模態(tài)數(shù)據(jù)中的關(guān)聯(lián)和交互。
7、提升向量數(shù)據(jù)庫的通用性和易用性
隨著向量數(shù)據(jù)庫的應(yīng)用場景不斷拓寬,提升其通用性和易用性成為一項(xiàng)重要任務(wù)。這包括提供更簡單的數(shù)據(jù)導(dǎo)入導(dǎo)出,提供更易用的查詢接口,以及提供更靈活的數(shù)據(jù)管理功能。同時,也需要提供豐富的文檔和示例,降低用戶的學(xué)習(xí)成本。
8、向量數(shù)據(jù)庫與深度學(xué)習(xí)、大模型的深度融合
未來,向量數(shù)據(jù)庫將和深度學(xué)習(xí)、大模型更緊密地結(jié)合,共同推動AI的發(fā)展。向量數(shù)據(jù)庫需要能夠理解大模型的需求,為其提供最合適的數(shù)據(jù)服務(wù)。而大模型也需要能夠利用向量數(shù)據(jù)庫的能力,以提高自身的效率和效果。這種融合可能會帶來許多新的可能性,例如模型和數(shù)據(jù)庫的聯(lián)合優(yōu)化,或者是數(shù)據(jù)庫自身的自動學(xué)習(xí)和優(yōu)化等。
在經(jīng)歷了大數(shù)據(jù)時代的高速蓬勃發(fā)展之后,向量數(shù)據(jù)庫已然成為新一輪技術(shù)浪潮中的明亮新星。這背后并非偶然,而是科技與時代需求的完美結(jié)合。在探索無垠的人工智能宇宙中,我們漸漸明白,每一個巨大的計算模型都需要一顆穩(wěn)固的“心臟”——一個可以儲存、檢索和管理高維向量數(shù)據(jù)的強(qiáng)大核心,而向量數(shù)據(jù)庫正是這顆“心臟”。
如今,我們站在巨人的肩膀上,俯瞰整個技術(shù)領(lǐng)域的壯麗風(fēng)景。OpenAI、阿里巴巴、百度、騰訊、星環(huán)科技、聯(lián)匯科技等企業(yè),都在為這片藍(lán)海注入新的活力與創(chuàng)意。未來的路,或許還很漫長,但有了向量數(shù)據(jù)庫和大模型這兩大引擎的雙重驅(qū)動,我們有信心跨越未知,追尋技術(shù)的極致,描繪出一個更為絢爛的數(shù)字世界。
文:一蓑煙雨 / 數(shù)據(jù)猿





