
前面的幾篇文章,作者深入探討過RLHF 的算法原理,今天站在一定高度討論,為什么需要RLHF 這么復雜的強化學習算法,為什么SL(監督學習) 不能達到這樣一個效果?
這篇文章就從Sebastian Raschka 推特上的分享的文章進行系統分析,還是來先看一下,RLHF 算法的過程。
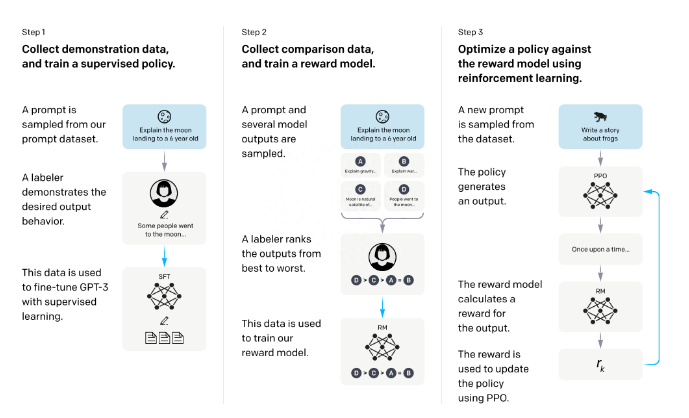
RLHF
原因一:如果使用監督學習,它只預測等級分數,不會產生連貫的反應,這樣的監督學習特點是模型就盡可能訓練集對應的響應上打高分( 輸入句子對決定了),即使響應是不連貫的。另一方面,RLHF 則被訓練來估計產生反應的質量(訓練集合是回答的排序),而不僅僅是排名分數,監督學習需要對回答打分輸入。
原因二:只使用監督學習將任務重新表述為一個受限的優化問題的想法(這里想表述的是,監督學習學習到的是一個固定答案,往往一個問題,可能有更好的回答響應,RLHF 需要模型具備這樣的泛化能力,監督學習沒有負反饋), 單純的監督學習,損失函數結合了輸出文本損失和獎勵分數項, 這將使生成的響應和排名的質量更高。但這種方法只有在目標正確產生問題——答案對時才能成功,很多創新問題的回答,模型往往給不出回答,這時候監督學習會使模型編造答案。但是累積獎勵對于實現用戶和 ChatGPT 之間的連貫對話(多輪對話)也是必要的,而監督學習無法提供這種獎勵,RLHF 由于在最終的狀態動作軌跡上,求優勢函數最大期望,天然適合這種多輪對話。
原因三:不選擇 SL 的第三個原因是,它使用交叉熵來優化標記級的損失。雖然在文本段落的標記水平上,改變反應中的個別單詞可能對整體損失只有很小的影響,但如果一個單詞被否定,產生連貫性對話的復雜任務可能會完全改變上下文。因此,僅僅依靠 SL 是不夠的,RLHF 對于考慮整個對話的背景和連貫性是必要的(RLHF 在全局進行優化,而不是單獨對某個詞生成的概率進行優化)。
原因四:監督學習可以用來訓練一個模型,但根據經驗發現 RLHF 往往表現得更好,實際實驗結果SL + RLHF 確實表現效果更好。
原因五:使用監督學習和強化學習結合對于實現最佳性能至關重要。在這些模型中,首先使用 SL 對模型進行微調,SL 階段允許模型學習任務的基本結構和內容,然后使用 RL 進一步更新, RLHF 階段則完善模型的反應以提高準確性。
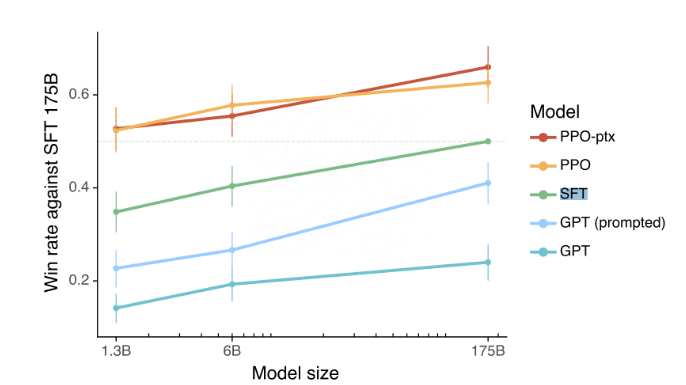
實際幾種效果





