擊這里在線咨詢客服")
現(xiàn)如今 redis 變得越來越流行,幾乎在很多項(xiàng)目中都要被用到,不知道你在使用 Redis 時(shí),有沒有思考過,Redis 到底是如何穩(wěn)定、高性能地提供服務(wù)的?
- 我使用 Redis 的場景很簡單,只使用單機(jī)版 Redis 會(huì)有什么問題嗎?
- 我的 Redis 故障宕機(jī)了,數(shù)據(jù)丟失了怎么辦?如何能保證我的業(yè)務(wù)應(yīng)用不受影響?
- 為什么需要主從集群?它有什么優(yōu)勢?
- 什么是分片集群?我真的需要分片集群嗎?
- ...
如果你對 Redis 已經(jīng)有些了解,肯定也聽說過「數(shù)據(jù)持久化、主從復(fù)制、哨兵、分片集群」這些概念,它們之間又有什么區(qū)別和聯(lián)系呢?
如果你存在這樣的疑惑,這篇文章,我會(huì)從 0 到 1,再從 1 到 N,帶你一步步構(gòu)建出一個(gè)穩(wěn)定、高性能的 Redis 集群。
在這個(gè)過程中,你可以了解到 Redis 為了做到穩(wěn)定、高性能,都采取了哪些優(yōu)化方案,以及為什么要這么做?
掌握了這些原理,這樣平時(shí)你在使用 Redis 時(shí),就能夠做到「游刃有余」。
一、從最簡單的開始:單機(jī)版 Redis
首先,我們從最簡單的場景開始。
假設(shè)現(xiàn)在你有一個(gè)業(yè)務(wù)應(yīng)用,需要引入 Redis 來提高應(yīng)用的性能,此時(shí)你可以選擇部署一個(gè)單機(jī)版的 Redis 來使用,就像這樣:
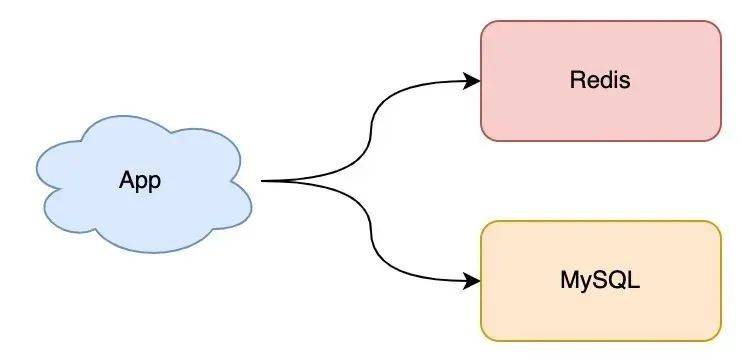
這個(gè)架構(gòu)非常簡單,你的業(yè)務(wù)應(yīng)用可以把 Redis 當(dāng)做緩存來使用,從 MySQL 中查詢數(shù)據(jù),然后寫入到 Redis 中,之后業(yè)務(wù)應(yīng)用再從 Redis 中讀取這些數(shù)據(jù),由于 Redis 的數(shù)據(jù)都存儲在內(nèi)存中,所以這個(gè)速度飛快。
如果你的業(yè)務(wù)體量并不大,那這樣的架構(gòu)模型基本可以滿足你的需求。是不是很簡單?
隨著時(shí)間的推移,你的業(yè)務(wù)體量逐漸發(fā)展起來了,Redis 中存儲的數(shù)據(jù)也越來越多,此時(shí)你的業(yè)務(wù)應(yīng)用對 Redis 的依賴也越來越重。
突然有一天,你的 Redis 因?yàn)槟承┰蝈礄C(jī)了,這時(shí)你的所有業(yè)務(wù)流量,都會(huì)打到后端 MySQL 上,MySQL 壓力劇增,嚴(yán)重的話甚至?xí)嚎?MySQL。
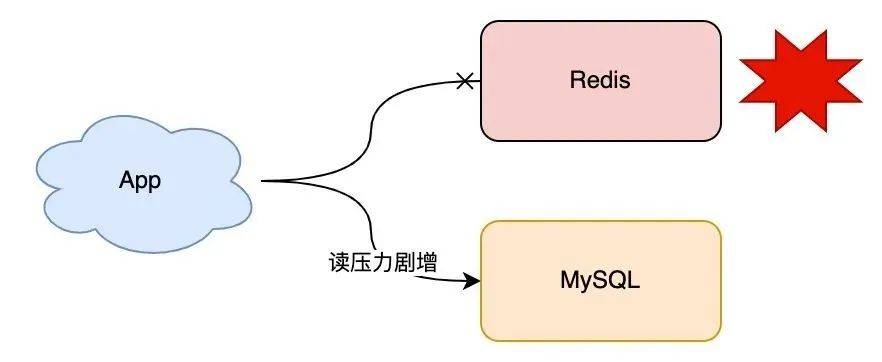
這時(shí)你應(yīng)該怎么辦?
我猜你的方案肯定是,趕緊重啟 Redis,讓它可以繼續(xù)提供服務(wù)。
但是,因?yàn)橹?Redis 中的數(shù)據(jù)都在內(nèi)存中,盡管你現(xiàn)在把 Redis 重啟了,之前的數(shù)據(jù)也都丟失了(假設(shè)沒開持久化)。重啟后的 Redis 雖然可以正常工作,但是由于 Redis 中沒有任何數(shù)據(jù),業(yè)務(wù)流量還是都會(huì)打到后端 MySQL 上,MySQL 的壓力還是很大。
有沒有什么好的辦法解決這個(gè)問題?
既然 Redis 只把數(shù)據(jù)存儲在內(nèi)存中,那是否可以把這些數(shù)據(jù)也寫一份到磁盤上呢?
如果采用這種方式,當(dāng) Redis 重啟時(shí),我們把磁盤中的數(shù)據(jù)快速「恢復(fù)」到內(nèi)存中,這樣它就可以繼續(xù)正常提供服務(wù)了。
是的,這是一個(gè)很好的解決方案,這個(gè)把內(nèi)存數(shù)據(jù)寫到磁盤上的過程,就是「數(shù)據(jù)持久化」。
二、數(shù)據(jù)持久化:有備無患
現(xiàn)在,你設(shè)想的 Redis 數(shù)據(jù)持久化是這樣的:

但是,數(shù)據(jù)持久化具體應(yīng)該怎么做呢?
我猜你最容易想到的一個(gè)方案是,Redis 每一次執(zhí)行寫操作,除了寫內(nèi)存之外,同時(shí)也寫一份到磁盤上,就像這樣:

沒錯(cuò),這是最簡單直接的方案。
但仔細(xì)想一下,這個(gè)方案有個(gè)問題:客戶端的每次寫操作,既需要寫內(nèi)存,又需要寫磁盤,而寫磁盤的耗時(shí)相比于寫內(nèi)存來說,肯定要慢很多!這勢必會(huì)影響到 Redis 的性能。
如何規(guī)避這個(gè)問題?
這時(shí)我們需要分析寫磁盤的細(xì)節(jié)問題了。
我們都知道,要把內(nèi)存數(shù)據(jù)寫到磁盤,其實(shí)是分 2 步的:
- 程序?qū)懳募?PageCache(write)
- 把 PageCache 刷到磁盤(fsync)
具體就是下圖這樣:

數(shù)據(jù)持久化最粗暴的思路就是上面提到的那樣,寫完 Redis 內(nèi)存后,同步寫 PageCache + fsync 磁盤,當(dāng)然,這樣肯定因?yàn)榇疟P拖慢整個(gè)寫入速度。
如何優(yōu)化?也很簡單,我們可以這樣做:Redis 寫內(nèi)存由主線程來做,寫內(nèi)存完成后就給客戶端返回結(jié)果,然后 Redis 用「另一個(gè)線程」去寫磁盤,這樣就可以避免主線程寫磁盤對性能的影響。

這種持久化方案,其實(shí)就是我們經(jīng)常聽到的 Redis AOF(Append Only File)。
Redis AOF 持久化提供了 3 種刷盤機(jī)制:
- appendfsync always:主線程同步 fsync
- appendfsync no:由 OS fsync
- appendfsync everysec:后臺線程每間隔1秒 fsync
解決了數(shù)據(jù)實(shí)時(shí)持久化,我們還會(huì)面臨另一個(gè)問題,數(shù)據(jù)實(shí)時(shí)寫入 AOF,隨著時(shí)間的推移,AOF 文件會(huì)越來越大,那使用 AOF 恢復(fù)時(shí)變得非常慢,這該怎么辦?
Redis 很貼心地提供了 AOF rewrite 方案,俗稱 AOF 「瘦身」,顧名思義,就是壓縮 AOF 的體積。
因?yàn)?AOF 里記錄的都是每一次寫命令,例如執(zhí)行 set k1 v1,set k1 v2,其實(shí)我們只關(guān)心數(shù)據(jù)的最終版本 v2 就可以了。AOF rewrite 正是利用了這個(gè)特點(diǎn),在 AOF 體積越來越大時(shí)(超過設(shè)定閾值),Redis 就會(huì)定期重寫一份新的 AOF,這個(gè)新的 AOF 只記錄數(shù)據(jù)的最終版本就可以了。
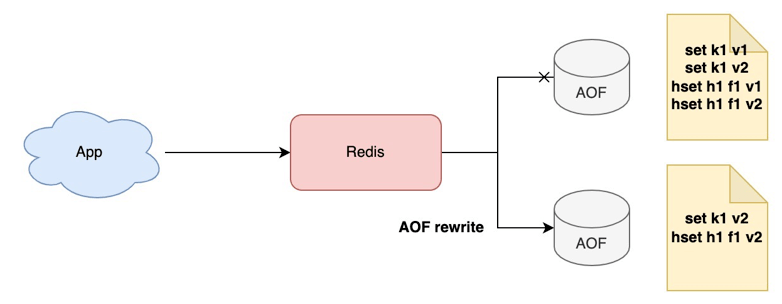
這樣就可以壓縮 AOF 體積。
除此之外,我們可以換個(gè)角度,思考一下還有什么方式可以持久化數(shù)據(jù)?
這時(shí)你就要結(jié)合 Redis 的使用場景來考慮了。
回憶一下,我們在使用 Redis 時(shí),通常把它用作什么場景?
是的,緩存。
把 Redis 當(dāng)做緩存來用,意味著盡管 Redis 中沒有保存全量數(shù)據(jù),對于不在緩存中的數(shù)據(jù),我們的業(yè)務(wù)應(yīng)用依舊可以通過查詢后端數(shù)據(jù)庫得到結(jié)果,只不過查詢后端數(shù)據(jù)的速度會(huì)慢一點(diǎn)而已,但對業(yè)務(wù)結(jié)果其實(shí)是沒有影響的。
基于這個(gè)特點(diǎn),我們的 Redis 數(shù)據(jù)持久化還可以用「數(shù)據(jù)快照」的方式來做。
那什么是數(shù)據(jù)快照呢?
簡單來講,你可以這么理解:
- 你把 Redis 想象成一個(gè)水杯,向 Redis 寫入數(shù)據(jù),就相當(dāng)于往這個(gè)杯子里倒水。
- 此時(shí)你拿一個(gè)相機(jī)給這個(gè)水杯拍一張照片,拍照的這一瞬間,照片中記錄到這個(gè)水杯中水的容量,就是水杯的數(shù)據(jù)快照。
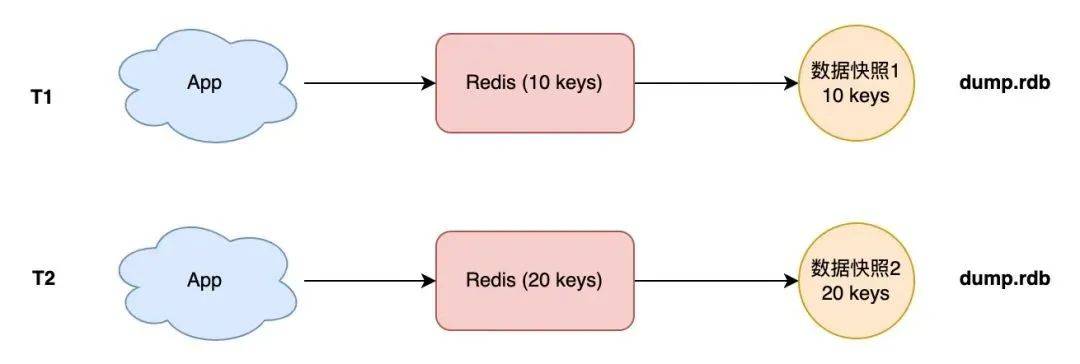
也就是說,Redis 的數(shù)據(jù)快照,是記錄某一時(shí)刻下 Redis 中的數(shù)據(jù),然后只需要把這個(gè)數(shù)據(jù)快照寫到磁盤上就可以了。
它的優(yōu)勢在于,只在需要持久化時(shí),把數(shù)據(jù)「一次性」寫入磁盤,其它時(shí)間都不需要操作磁盤。
基于這個(gè)方案,我們可以「定時(shí)」給 Redis 做數(shù)據(jù)快照,把數(shù)據(jù)持久化到磁盤上。
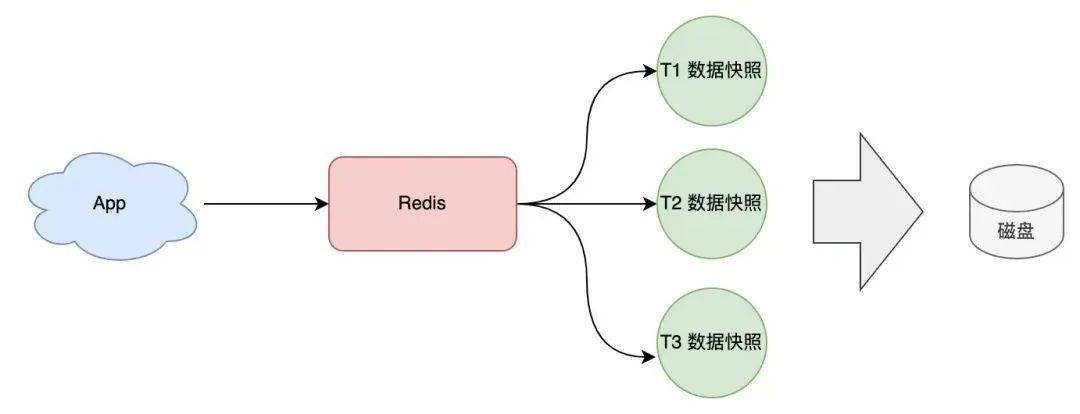
這種方案就是我們經(jīng)常聽到的 Redis RDB,RDB 采用「定時(shí)快照」的方式進(jìn)行數(shù)據(jù)持久化,它的優(yōu)點(diǎn)是:
- 持久化文件體積小(二進(jìn)制 + 壓縮)
- 寫盤頻率低(定時(shí)寫入)
缺點(diǎn)也很明顯,因?yàn)槭嵌〞r(shí)持久化,數(shù)據(jù)肯定沒有 AOF 實(shí)時(shí)持久化完整,如果你的 Redis 只當(dāng)做緩存,對于丟失數(shù)據(jù)不敏感(可從后端的數(shù)據(jù)庫查詢),那這種持久化方式是非常合適的。
如果讓你來選擇持久化方案,你可以這樣選擇:
- 業(yè)務(wù)對于數(shù)據(jù)丟失不敏感,選 RDB
- 業(yè)務(wù)對數(shù)據(jù)完整性要求比較高,選 AOF
理解了 RDB 和 AOF,我們再進(jìn)一步思考一下,有沒有什么辦法,既可以保證數(shù)據(jù)完整性,還能讓持久化文件體積更小,恢復(fù)更快呢?
回顧一下我們前面講到的,RDB 和 AOF 各自的特點(diǎn):
- RDB 以二進(jìn)制 + 數(shù)據(jù)壓縮方式存儲,文件體積小
- AOF 記錄每一次寫命令,數(shù)據(jù)最全
我們可否利用它們各自的優(yōu)勢呢?
當(dāng)然可以,這就是 Redis 的「混合持久化」。
要想數(shù)據(jù)完整性更高,肯定就不能只用 RDB 了,重點(diǎn)還是要放在 AOF 優(yōu)化上。
具體來說,當(dāng) AOF 在做 rewrite 時(shí),Redis 先以 RDB 格式在 AOF 文件中寫入一個(gè)數(shù)據(jù)快照,再把在這期間產(chǎn)生的每一個(gè)寫命令,追加到 AOF 文件中。
因?yàn)?RDB 是二進(jìn)制壓縮寫入的,這樣 AOF 文件體積就變得更小了。
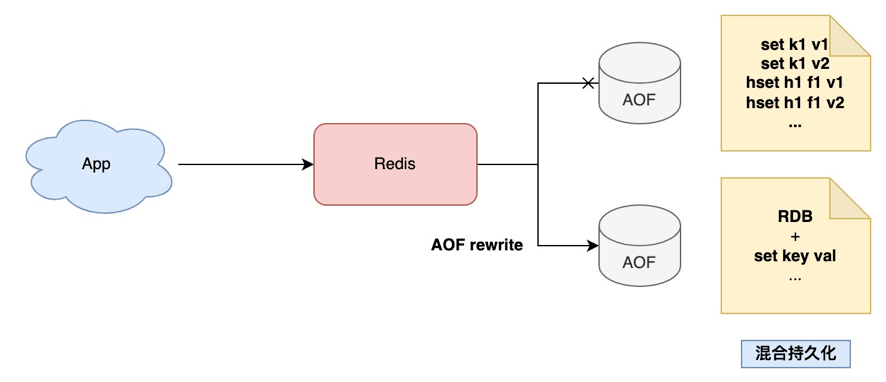
因?yàn)?AOF 體積進(jìn)一步壓縮,你在使用 AOF 恢復(fù)數(shù)據(jù)時(shí),這個(gè)恢復(fù)時(shí)間就會(huì)更短了!
Redis 4.0 以上版本才支持混合持久化。
注意:混合持久化是對 AOF rewrite 的優(yōu)化,這意味著使用它必須基于 AOF + AOF rewrite。
這么一番優(yōu)化,你的 Redis 再也不用擔(dān)心實(shí)例宕機(jī)了,當(dāng)發(fā)生宕機(jī)時(shí),你就可以用持久化文件快速恢復(fù) Redis 中的數(shù)據(jù)。
但這樣就沒問題了嗎?
仔細(xì)想一下,雖然我們已經(jīng)把持久化的文件優(yōu)化到最小了,但在恢復(fù)數(shù)據(jù)時(shí)依舊是需要時(shí)間的,在這期間你的業(yè)務(wù)應(yīng)用無法提供服務(wù),這怎么辦?
一個(gè)實(shí)例宕機(jī),只能用恢復(fù)數(shù)據(jù)來解決,那我們是否可以部署多個(gè) Redis 實(shí)例,然后讓這些實(shí)例數(shù)據(jù)保持實(shí)時(shí)同步,這樣當(dāng)一個(gè)實(shí)例宕機(jī)時(shí),我們在剩下的實(shí)例中選擇一個(gè)繼續(xù)提供服務(wù)就好了。
沒錯(cuò),這個(gè)方案就是接下來要講的「主從復(fù)制:多副本」。
三、主從復(fù)制:多副本
你可以部署多個(gè) Redis 實(shí)例,架構(gòu)模型就變成了這樣:
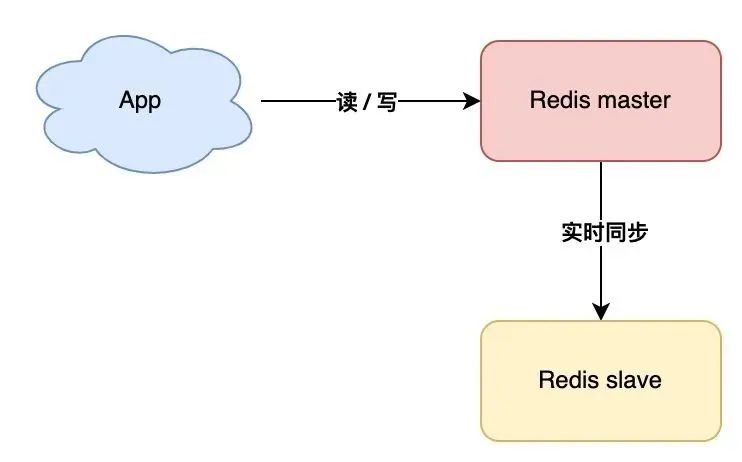
我們這里把實(shí)時(shí)讀寫的節(jié)點(diǎn)叫做 master,另一個(gè)實(shí)時(shí)同步數(shù)據(jù)的節(jié)點(diǎn)叫做 slave。
采用多副本的方案,它的優(yōu)勢是:
- 縮短不可用時(shí)間:master 發(fā)生宕機(jī),我們可以手動(dòng)把 slave 提升為 master 繼續(xù)提供服務(wù)
- 提升讀性能:讓 slave 分擔(dān)一部分讀請求,提升應(yīng)用的整體性能
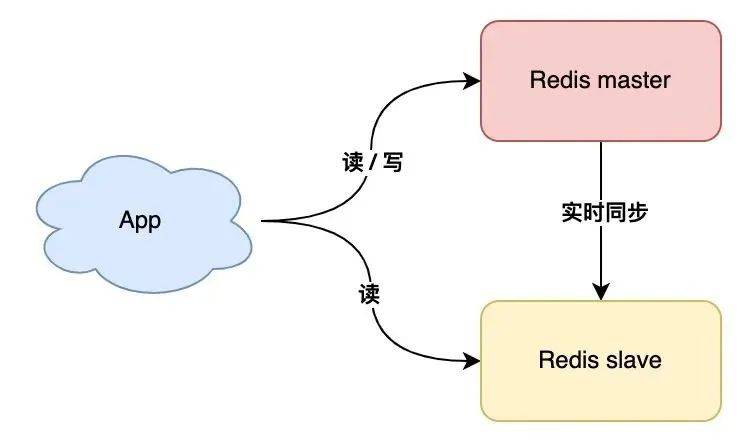
這個(gè)方案不錯(cuò),不僅節(jié)省了數(shù)據(jù)恢復(fù)的時(shí)間,還能提升性能。
但它的問題在于:當(dāng) master 宕機(jī)時(shí),我們需要「手動(dòng)」把 slave 提升為 master,這個(gè)過程也是需要花費(fèi)時(shí)間的。
雖然比恢復(fù)數(shù)據(jù)要快得多,但還是需要人工介入處理。一旦需要人工介入,就必須要算上人的反應(yīng)時(shí)間、操作時(shí)間,所以,在這期間你的業(yè)務(wù)應(yīng)用依舊會(huì)受到影響。
我們是否可以把這個(gè)切換的過程,變成自動(dòng)化?
四、哨兵:故障自動(dòng)切換
要想自動(dòng)切換,肯定不能依賴人了。
現(xiàn)在,我們可以引入一個(gè)「觀察者」,讓這個(gè)觀察者去實(shí)時(shí)監(jiān)測 master 的健康狀態(tài),這個(gè)觀察者就是「哨兵」。
具體如何做?
- 哨兵每間隔一段時(shí)間,詢問 master 是否正常
- master 正常回復(fù),表示狀態(tài)正常,回復(fù)超時(shí)表示異常
- 哨兵發(fā)現(xiàn)異常,發(fā)起主從切換
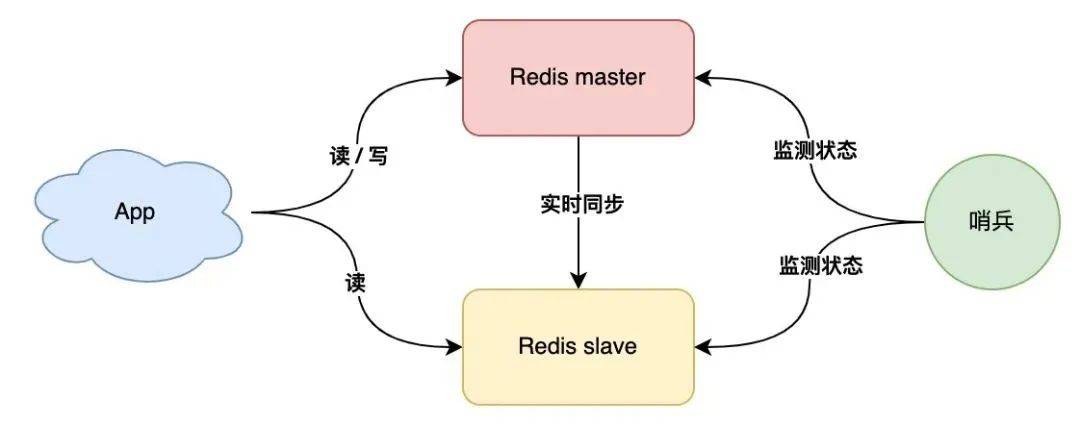
有了這個(gè)方案,就不需要人去介入處理了,一切就變得自動(dòng)化了,是不是很爽?
但這里還有一個(gè)問題,如果 master 狀態(tài)正常,但這個(gè)哨兵在詢問 master 時(shí),它們之間的網(wǎng)絡(luò)發(fā)生了問題,那這個(gè)哨兵可能會(huì)「誤判」。
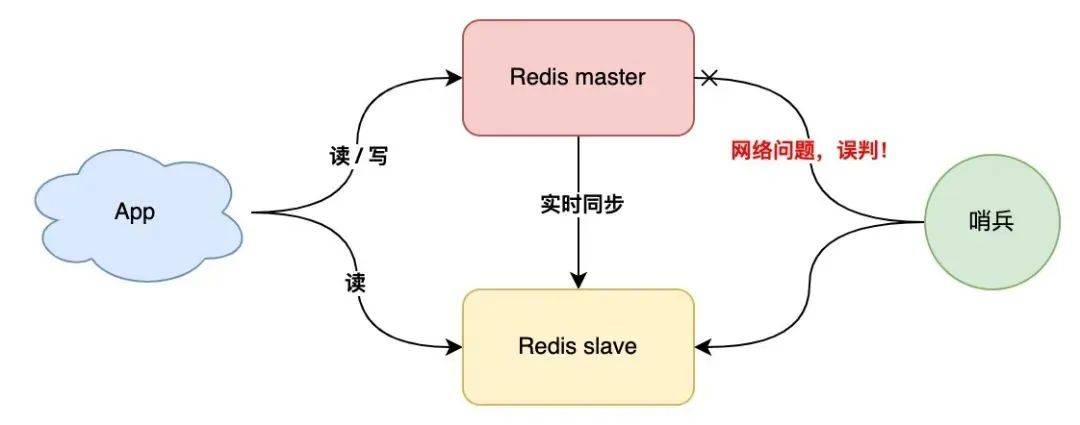
這個(gè)問題怎么解決?
既然一個(gè)哨兵會(huì)誤判,那我們可以部署多個(gè)哨兵,讓它們分布在不同的機(jī)器上,讓它們一起監(jiān)測 master 的狀態(tài),流程就變成了這樣:
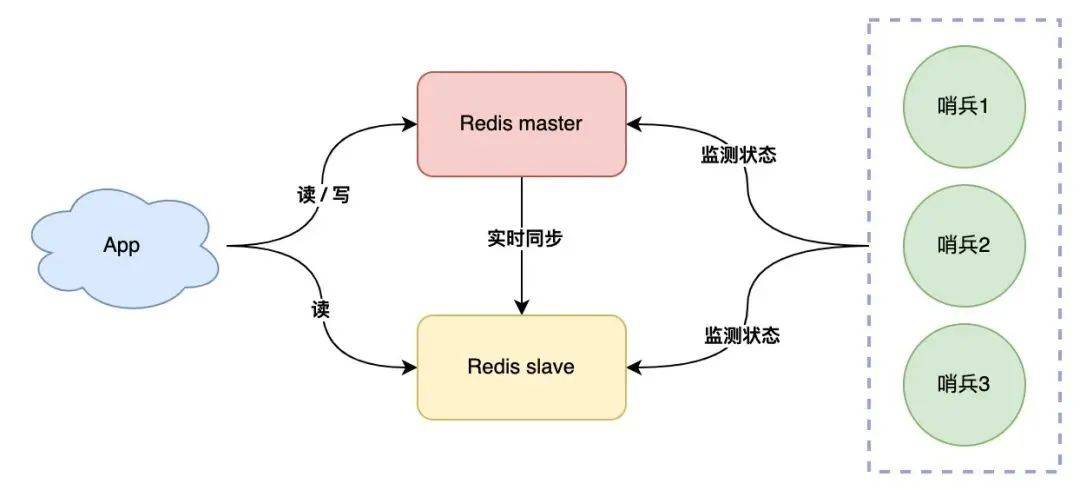
- 多個(gè)哨兵每間隔一段時(shí)間,詢問 master 是否正常
- master 正常回復(fù),表示狀態(tài)正常,回復(fù)超時(shí)表示異常
- 一旦有一個(gè)哨兵判定 master 異常(不管是否是網(wǎng)絡(luò)問題),就詢問其它哨兵,如果多個(gè)哨兵(設(shè)置一個(gè)閾值)都認(rèn)為 master 異常了,這才判定 master 確實(shí)發(fā)生了故障
- 多個(gè)哨兵經(jīng)過協(xié)商后,判定 master 故障,則發(fā)起主從切換
所以,我們用多個(gè)哨兵互相協(xié)商來判定 master 的狀態(tài),這樣,就可以大大降低誤判的概率。
哨兵協(xié)商判定 master 異常后,這里還有一個(gè)問題:由哪個(gè)哨兵來發(fā)起主從切換呢?
答案是,選出一個(gè)哨兵「領(lǐng)導(dǎo)者」,由這個(gè)領(lǐng)導(dǎo)者進(jìn)行主從切換。
問題又來了,這個(gè)領(lǐng)導(dǎo)者怎么選?
想象一下,在現(xiàn)實(shí)生活中,選舉是怎么做的?
是的,投票。
在選舉哨兵領(lǐng)導(dǎo)者時(shí),我們可以制定這樣一個(gè)選舉規(guī)則:
- 每個(gè)哨兵都詢問其它哨兵,請求對方為自己投票
- 每個(gè)哨兵只投票給第一個(gè)請求投票的哨兵,且只能投票一次
- 首先拿到超過半數(shù)投票的哨兵,當(dāng)選為領(lǐng)導(dǎo)者,發(fā)起主從切換
這個(gè)選舉的過程就是我們經(jīng)常聽到的:分布式系統(tǒng)領(lǐng)域中的「共識算法」。
什么是共識算法?
我們在多個(gè)機(jī)器部署哨兵,它們需要共同協(xié)作完成一項(xiàng)任務(wù),所以它們就組成了一個(gè)「分布式系統(tǒng)」。
在分布式系統(tǒng)領(lǐng)域,多個(gè)節(jié)點(diǎn)如何就一個(gè)問題達(dá)成共識的算法,就叫共識算法。
在這個(gè)場景下,多個(gè)哨兵共同協(xié)商,選舉出一個(gè)都認(rèn)可的領(lǐng)導(dǎo)者,就是使用共識算法完成的。
這個(gè)算法還規(guī)定節(jié)點(diǎn)的數(shù)量必須是奇數(shù)個(gè),這樣可以保證系統(tǒng)中即使有節(jié)點(diǎn)發(fā)生了故障,剩余超過「半數(shù)」的節(jié)點(diǎn)狀態(tài)正常,依舊可以提供正確的結(jié)果,也就是說,這個(gè)算法還兼容了存在故障節(jié)點(diǎn)的情況。
共識算法在分布式系統(tǒng)領(lǐng)域有很多,例如 Paxos、Raft,哨兵選舉領(lǐng)導(dǎo)者這個(gè)場景,使用的是 Raft 共識算法,因?yàn)樗銐蚝唵危乙子趯?shí)現(xiàn)。
好,到這里我們先小結(jié)一下。
你的 Redis 從最簡單的單機(jī)版,經(jīng)過數(shù)據(jù)持久化、主從多副本、哨兵集群,這一路優(yōu)化下來,你的 Redis 不管是性能還是穩(wěn)定性,都越來越高,就算節(jié)點(diǎn)發(fā)生故障,也不用擔(dān)心了。
Redis 以這樣的架構(gòu)模式部署,基本上就可以穩(wěn)定運(yùn)行很長時(shí)間了。
隨著時(shí)間的發(fā)展,你的業(yè)務(wù)體量開始迎來了爆炸性增長,此時(shí)你的架構(gòu)模型,還能夠承擔(dān)這么大的流量嗎?
我們一起來分析一下:
- 數(shù)據(jù)怕丟失:持久化(RDB/AOF)
- 恢復(fù)時(shí)間久:主從副本(副本隨時(shí)可切)
- 手動(dòng)切換時(shí)間長:哨兵集群(自動(dòng)切換)
- 讀存在壓力:擴(kuò)容副本(讀寫分離)
- 寫存在壓力:一個(gè) mater 扛不住怎么辦?
可見,現(xiàn)在剩下的問題是,當(dāng)寫請求量越來越大時(shí),一個(gè) master 實(shí)例可能就無法承擔(dān)這么大的寫流量了。
要想完美解決這個(gè)問題,此時(shí)你就需要考慮使用「分片集群」了。
五、分片集群:橫向擴(kuò)展
什么是「分片集群」?
簡單來講,一個(gè)實(shí)例扛不住寫壓力,那我們是否可以部署多個(gè)實(shí)例,然后把這些實(shí)例按照一定規(guī)則組織起來,把它們當(dāng)成一個(gè)整體,對外提供服務(wù),這樣不就可以解決集中寫一個(gè)實(shí)例的瓶頸問題嗎?
所以,現(xiàn)在的架構(gòu)模型就變成了這樣:
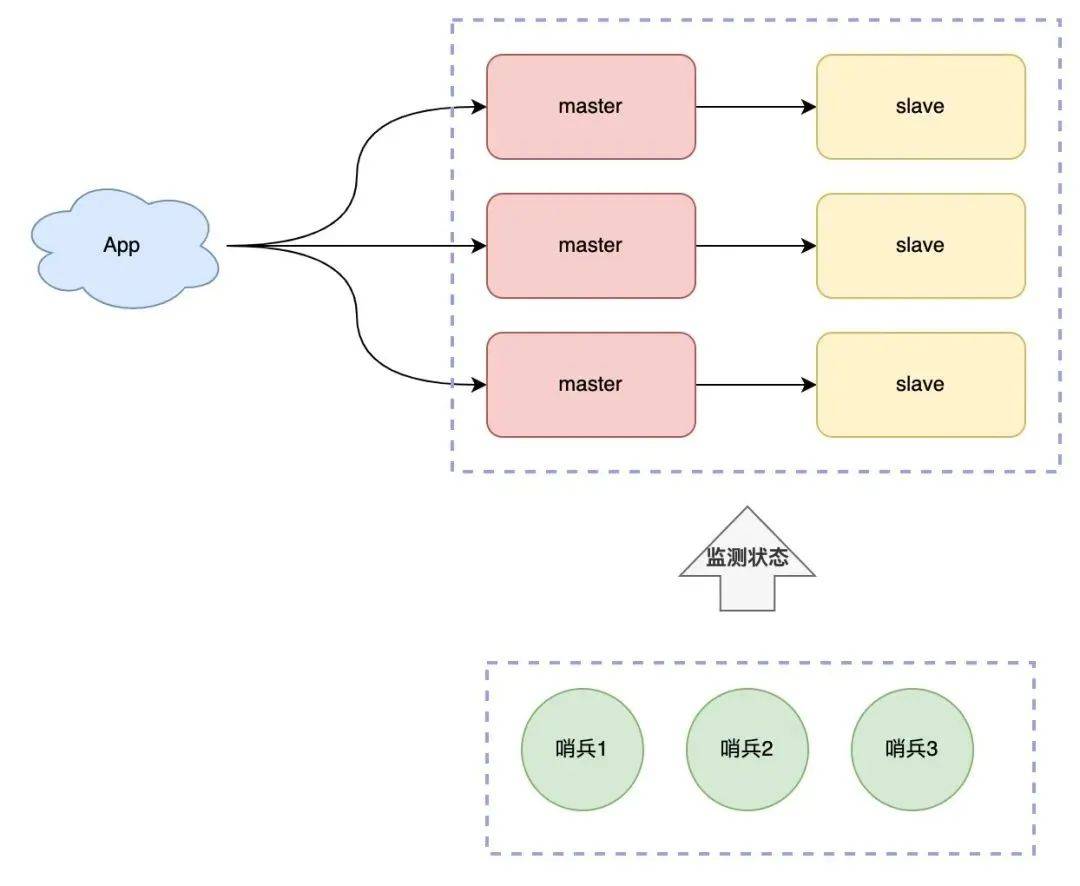
現(xiàn)在問題又來了,這么多實(shí)例如何組織呢?
我們制定規(guī)則如下:
- 每個(gè)節(jié)點(diǎn)各自存儲一部分?jǐn)?shù)據(jù),所有節(jié)點(diǎn)數(shù)據(jù)之和才是全量數(shù)據(jù)
- 制定一個(gè)路由規(guī)則,對于不同的 key,把它路由到固定一個(gè)實(shí)例上進(jìn)行讀寫
數(shù)據(jù)分多個(gè)實(shí)例存儲,那尋找 key 的路由規(guī)則需要放在客戶端來做,具體就是下面這樣:
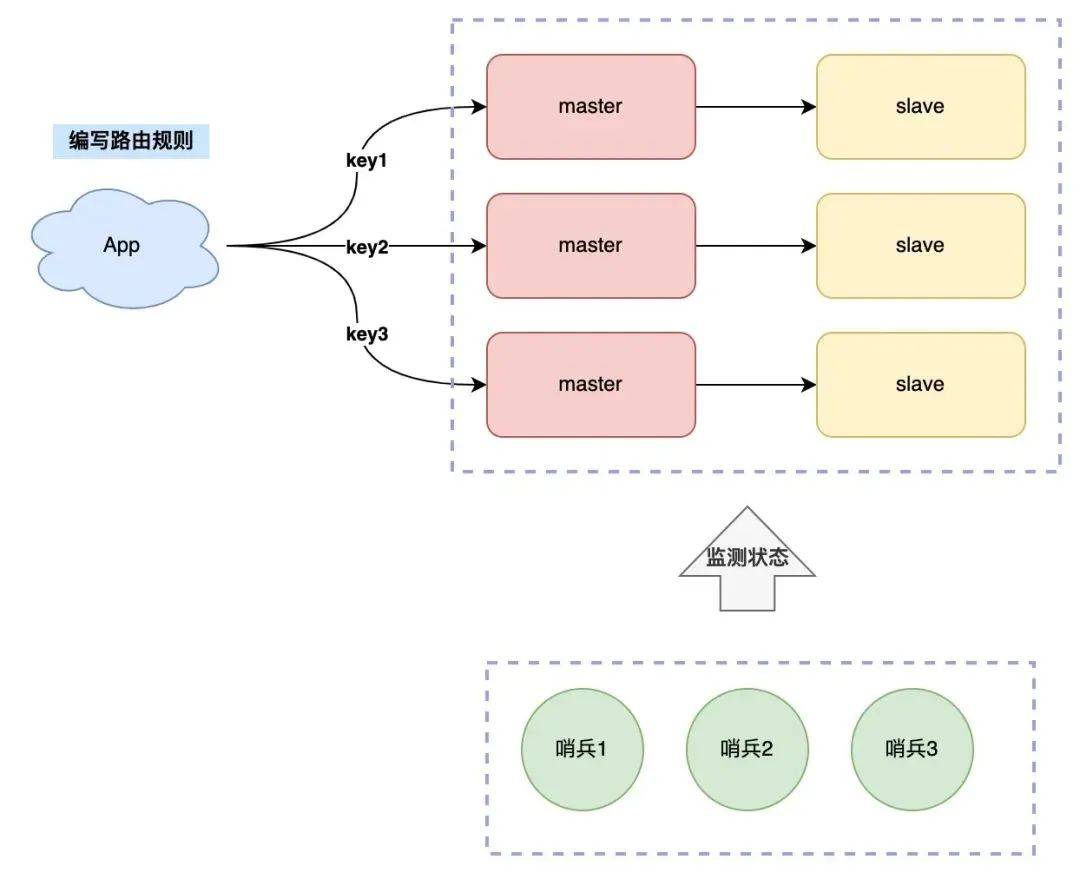
這種方案也叫做「客戶端分片」,這個(gè)方案的缺點(diǎn)是,客戶端需要維護(hù)這個(gè)路由規(guī)則,也就是說,你需要把路由規(guī)則寫到你的業(yè)務(wù)代碼中。
如何做到不把路由規(guī)則耦合在客戶端業(yè)務(wù)代碼中呢?
繼續(xù)優(yōu)化,我們可以在客戶端和服務(wù)端之間增加一個(gè)「中間代理層」,這個(gè)代理就是我們經(jīng)常聽到的 Proxy,路由轉(zhuǎn)發(fā)規(guī)則,放在這個(gè) Proxy 層來維護(hù)。
這樣,客戶端就無需關(guān)心服務(wù)端有多少個(gè) Redis 節(jié)點(diǎn)了,只需要和這個(gè) Proxy 交互即可。
Proxy 會(huì)把你的請求根據(jù)路由規(guī)則,轉(zhuǎn)發(fā)到對應(yīng)的 Redis 節(jié)點(diǎn)上,而且,當(dāng)集群實(shí)例不足以支撐更大的流量請求時(shí),還可以橫向擴(kuò)容,添加新的 Redis 實(shí)例提升性能,這一切對于你的客戶端來說,都是透明無感知的。
業(yè)界開源的 Redis 分片集群方案,例如 Twemproxy、Codis 就是采用的這種方案。
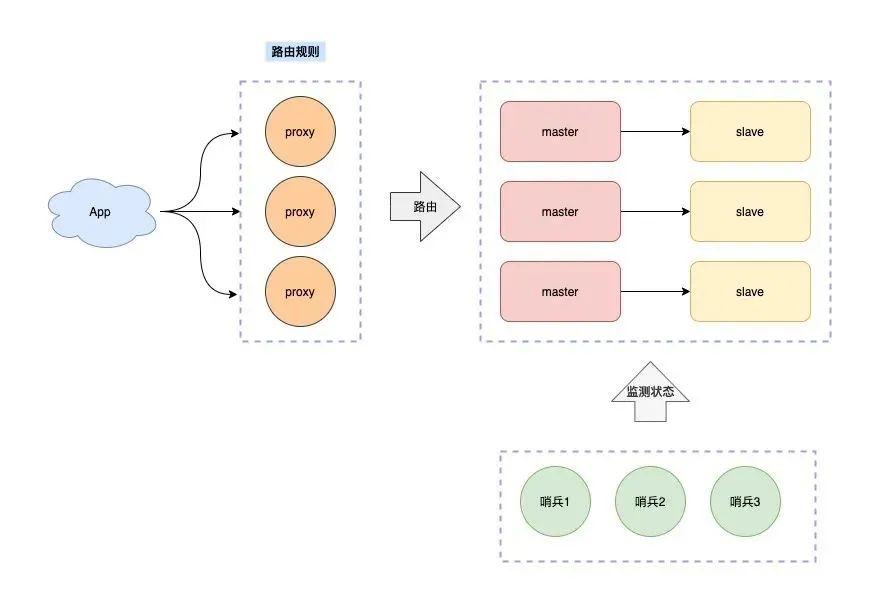
這種方案的優(yōu)點(diǎn)在于,客戶端無需關(guān)心數(shù)據(jù)轉(zhuǎn)發(fā)規(guī)則,只需要和 Proxy 打交道,客戶端像操作單機(jī) Redis 那樣去操作后面的集群,簡單易用。
架構(gòu)演進(jìn)到目前為止,路由規(guī)則無論是客戶端來做,還是 Proxy 來做,都是「社區(qū)」演進(jìn)出來的分片解決方案,它們的特點(diǎn)是集群中的 Redis 節(jié)點(diǎn),都不知道對方的存在,只有客戶端或 Proxy 才會(huì)統(tǒng)籌數(shù)據(jù)寫到哪里,從哪里讀取,而且它們都依賴哨兵集群負(fù)責(zé)故障自動(dòng)切換。
也就是說我們其實(shí)就是把多個(gè)孤立的 Redis 節(jié)點(diǎn),自己組合起來使用。
Redis 在 3.0 其實(shí)就推出了「官方」的 Redis Cluster 分片方案,但由于推出初期不穩(wěn)定,所以用的人很少,也因此業(yè)界涌現(xiàn)出了各種開源方案,上面講到的 Twemproxy、Codis 分片方案就是在這種背景下誕生的。
但隨著 Redis Cluster 方案的逐漸成熟,業(yè)界越來越多的公司開始采用官方方案(畢竟官方保證持續(xù)維護(hù),Twemproxy、Codis 目前都逐漸放棄維護(hù)了),Redis Cluster 方案比上面講到的分片方案更簡單,它的架構(gòu)如下。
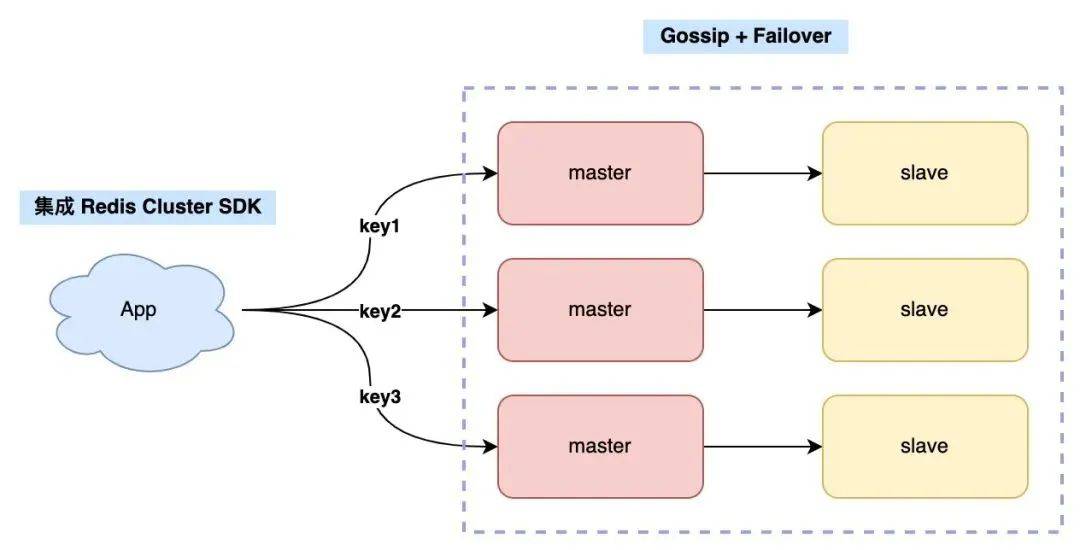
Redis Cluster 無需部署哨兵集群,集群內(nèi) Redis 節(jié)點(diǎn)通過 Gossip 協(xié)議互相探測健康狀態(tài),在故障時(shí)可發(fā)起自動(dòng)切換。
另外,關(guān)于路由轉(zhuǎn)發(fā)規(guī)則,也不需要客戶端自己編寫了,Redis Cluster 提供了「配套」的 SDK,只要客戶端升級 SDK,就可以和 Redis Cluster 集成,SDK 會(huì)幫你找到 key 對應(yīng)的 Redis 節(jié)點(diǎn)進(jìn)行讀寫,還能自動(dòng)適配 Redis 節(jié)點(diǎn)的增加和刪除,業(yè)務(wù)側(cè)無感知。
雖然省去了哨兵集群的部署,維護(hù)成本降低了不少,但對于客戶端升級 SDK,對于新業(yè)務(wù)應(yīng)用來說,可能成本不高,但對于老業(yè)務(wù)來講,「升級成本」還是比較高的,這對于切換官方 Redis Cluster 方案有不少阻力。
于是,各個(gè)公司有開始自研針對 Redis Cluster 的 Proxy,降低客戶端的升級成本,架構(gòu)就變成了這樣:
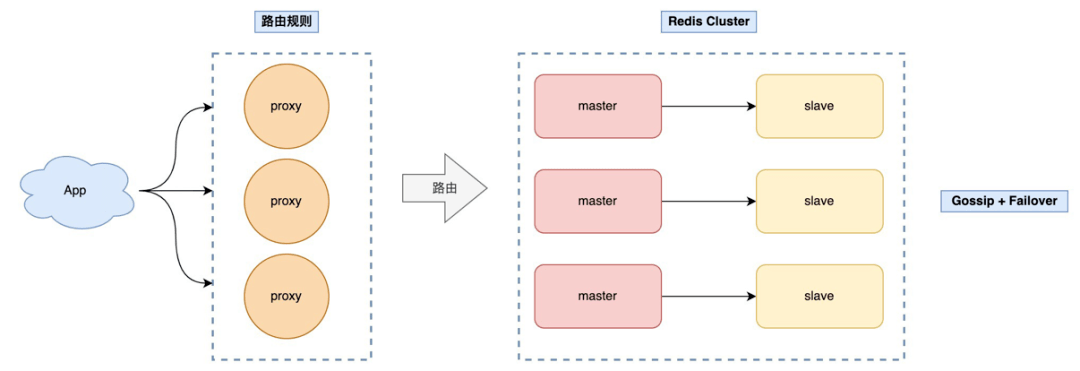
這樣,客戶端無需做任何變更,只需把連接地址切到 Proxy 上即可,由 Proxy 負(fù)責(zé)轉(zhuǎn)發(fā)數(shù)據(jù),以及應(yīng)對后面集群增刪節(jié)點(diǎn)帶來的路由變更。
至此,業(yè)界主流的 Redis 分片架構(gòu)已經(jīng)成型,當(dāng)你使用分片集群后,對于未來更大的流量壓力,也都可以從容面對了!
總結(jié)
總結(jié)一下,我們是如何從 0 到 1,再從 1 到 N 構(gòu)建一個(gè)穩(wěn)定、高性能的 Redis 集群的,從這之中你可以清晰地看到 Redis 架構(gòu)演進(jìn)的整個(gè)過程。
- 數(shù)據(jù)怕丟失:持久化(RDB/AOF)
- 恢復(fù)時(shí)間久:主從副本(副本隨時(shí)可切)
- 故障手動(dòng)切換慢:哨兵集群(自動(dòng)切換)
- 讀存在壓力:擴(kuò)容副本(讀寫分離)
- 寫存在壓力/容量瓶頸:分片集群
- 分片集群社區(qū)方案:Twemproxy、Codis(Redis 節(jié)點(diǎn)之間無通信,需要部署哨兵,可橫向擴(kuò)容)
- 分片集群官方方案:Redis Cluster (Redis 節(jié)點(diǎn)之間 Gossip 協(xié)議,無需部署哨兵,可橫向擴(kuò)容)
- 業(yè)務(wù)側(cè)升級困難:Proxy + Redis Cluster(不侵入業(yè)務(wù)側(cè))
至此,我們的 Redis 集群才得以長期穩(wěn)定、高性能的為我們的業(yè)務(wù)提供服務(wù)。
希望這篇文章可以幫你更好的理解 Redis 架構(gòu)的演進(jìn)之路。
作者丨KAIto
來源丨公眾號:水滴與銀彈(ID:waterdrop_bullet)





