

作者介紹
李慶豐,新浪微博研發中心高級總監。負責微博基礎架構和流媒體等研發方向,在高可用架構、視頻、直播等技術方向有豐富的研發實戰及管理經驗,同時作為微博技術新兵訓練營負責人,主導技術新人技術融入提升培訓體系。技術社區的擁護者,多次擔任業界前沿技術大會的講師及出品人。
分享概要
一、微博的業務場景和挑戰
二、如何構建高可用架構體系
- 容量問題
- 性能問題
- 依賴問題
- 容災問題
三、新的探索與展望
一、微博的業務場景和挑戰
微博是2009年上線的一款社交媒體平臺。剛開始微博的功能比較簡單,就是用戶關注了一些其他微博賬號,就可以在自己的信息流里看到相關用戶的動態微博。
為了滿足不同用戶的實際需求,微博的功能也變得越來越豐富,出現了多種信息流機制,比如基于關注關系進行信息分發的關注流、基于用戶興趣進行信息分發的推薦流,還有發現頁中大家都很關注的熱搜板塊等。
有人把微博比喻為一個大廣場,每當有社會熱點事件出現,首先都會在微博上發酵,然后用戶都集中來微博上關注事情進展,進行相關的熱議,因此也給技術架構帶來巨大的挑戰。
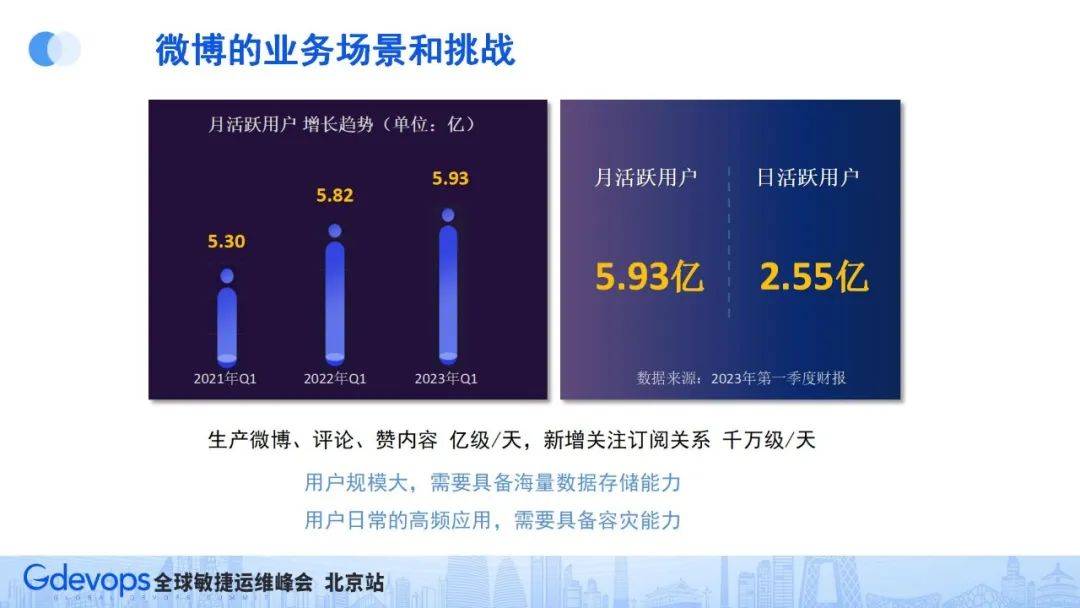
2023年第一季度財報顯示:微博活躍用戶MAU5.93億,DAU2.55億。如此大的用戶量,對技術架構就是一個不小的挑戰,微博用戶每天發布微博、評論、點贊等可以達到億級規模,每天新增的訂閱關注也在千萬級規模。
用戶規模大,首先要具備海量數據存儲能力,同時作為用戶日常的高頻應用,也要求具備一定的容災能力。所以在談到微博的高可用挑戰的時候,首先要關注的就是微博在什么情況下流量高、挑戰大。總結下來,微博有4個典型的流量場景:
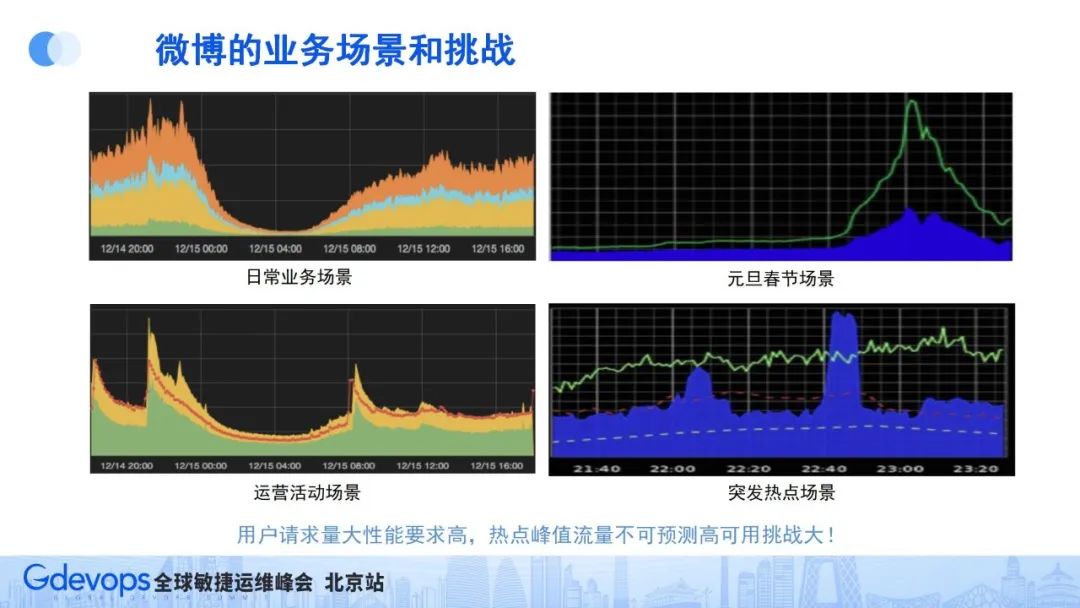
- 日常業務場景:微博用戶一般在中午和晚上比較活躍,所以從流量上看微博會有午高峰和晚高峰;
- 重大節假日場景:比如元旦、春節時期,微博也會有一個非常大的流量高峰;
- 運營活動場景:特別的一些運營活動,流量也會比較高;
- 突發熱點場景:這是對微博技術架構最大的挑戰。
前三個場景是可以預期的,可以提前準備,而突發熱點場景是不可預知的,且往往流量峰值非常高。
因此,從微博的業務情況和場景上看,高可用架構的挑戰可以歸納出四個主要問題:
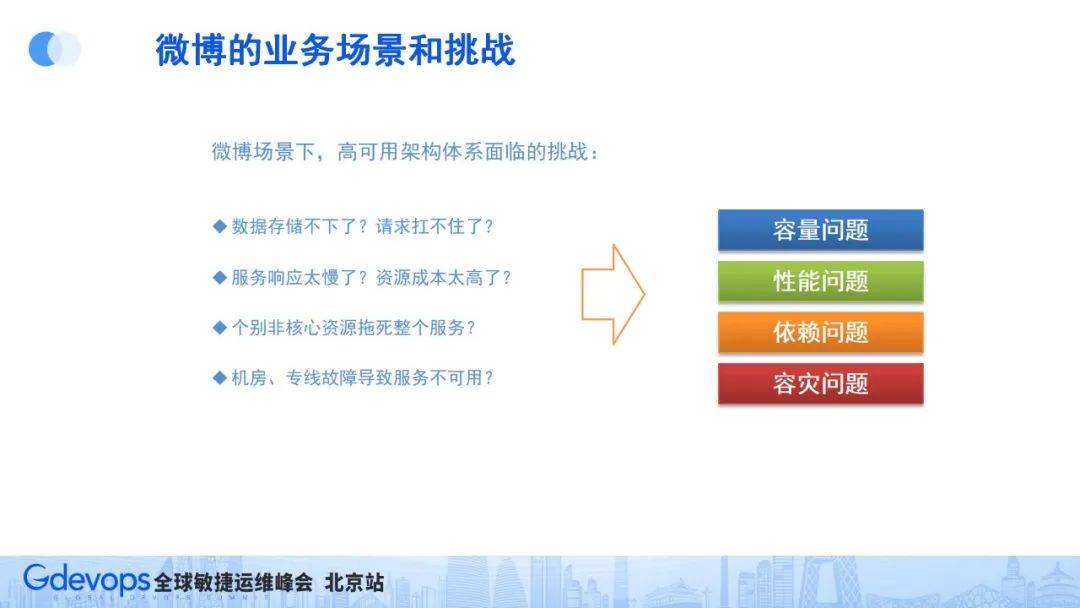
- 容量問題:數據存儲不下,請求量扛不住
微博從剛上線時的幾百萬用戶到現在幾億用戶量,博文內容數據也在不斷累積,數據量和存儲壓力越來越大;同時,隨著用戶規模增大,并發用戶請求量也會增大。
- 性能問題:服務響應太慢,資源成本太高
接口性能問題,不僅會影響用戶消費微博信息流的體驗,還會增加資源成本。
- 依賴問題:個別非核心資源拖死整個服務
就是邊緣業務功能有問題,影響了核心功能,這是不能接受的。
- 容災問題:機房、專線故障導致服務不可用
近幾年也經常聽說機房或專線故障導致某些服務不可用情況,作為用戶高頻使用的App,需要有一定的容災能力。
二、構建高可用架構體系
針對上面提到的問題和挑戰,對應的解決方案如下:

當然,解決問題最重要的一步是能夠提前感知和發現問題,因此需要有比較完備的監控體系,這就組成了我們的高可用架構體系(如下圖所示)。
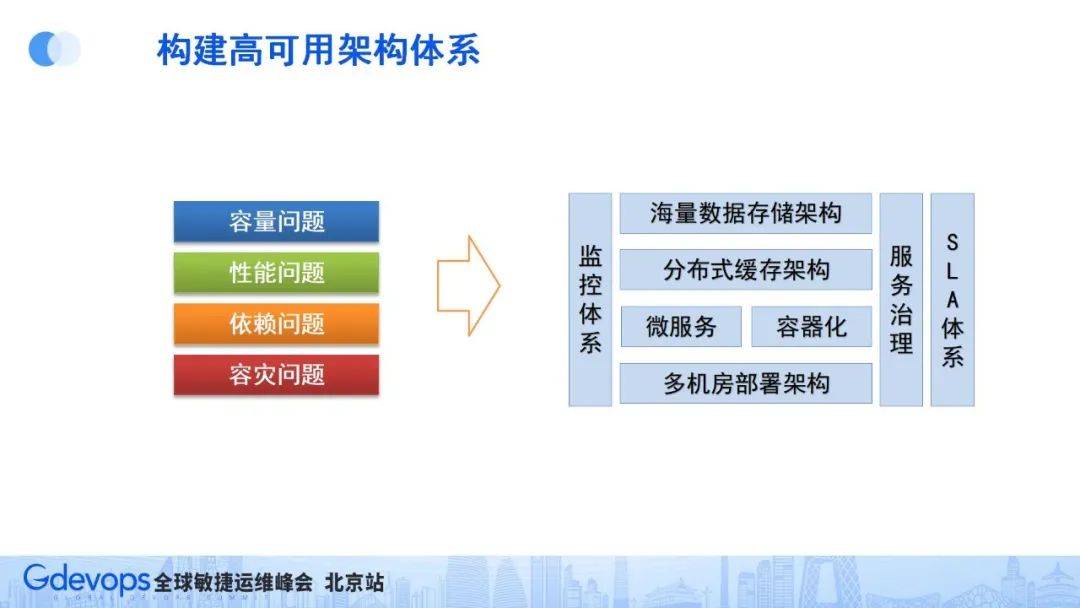
下面我們談談各個模塊的具體技術架構方案:
1、容量問題
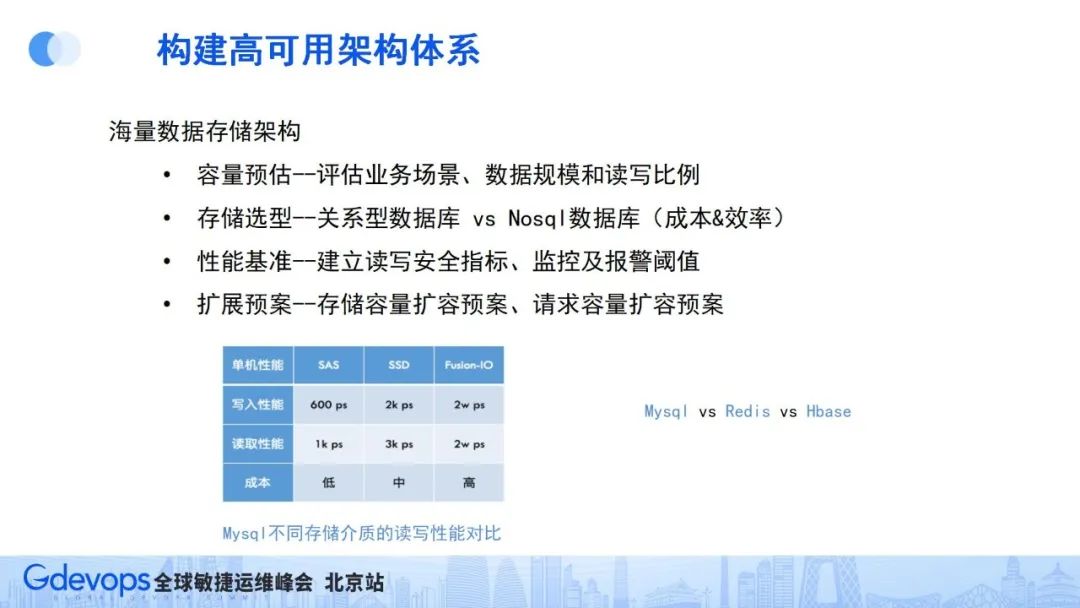
建設海量數據存儲架構要關注四個方面:首先是容量評估,根據業務規模和場景確定存儲容量和請求的讀寫比例和規模,接著就可以進行存儲組件選型(MySQL、redis等),然后就需要根據實際壓測數據,確定相關的容量安全閾值和請求量安全閾值,同時增加相關監控和報警,最后還要做好容量的可擴展預案,一旦存儲容量或請求容量達到安全閾值,能從容按照預案應對。
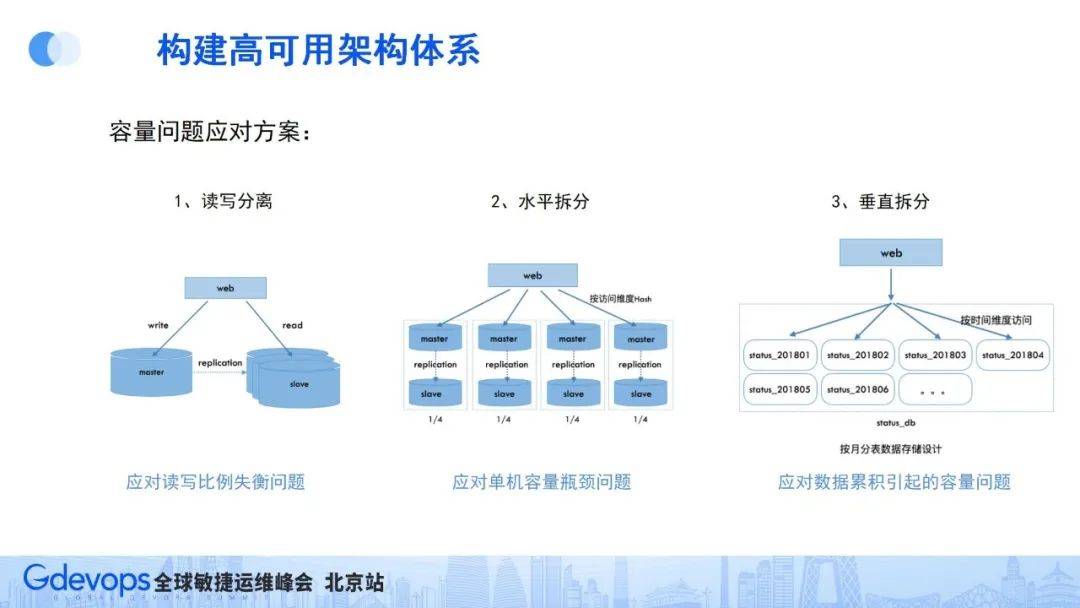
存儲容量的可擴展預案,需要提前做好三方面的準備:
- 讀寫分離:特別適合讀寫比例失衡的業務場景,方便將來針對性地進行容量擴展;
- 水平拆分:能夠把數據按hash存儲到多個存儲實例中,解決單機存儲容量的瓶頸問題;
- 垂直拆分:針對隨著時間會累積增加的內容存儲場景,提前按時間維度做好分庫或分表,應對隨著時間累積引起的存儲容量問題。
微博場景已經有十幾年的歷程,博文內容存儲量會隨著時間不斷增多,因為內容存儲按時間維度進行垂直拆分,每隔一段時間,就可以自然地增加新的數據庫實例,不斷擴展整體存儲容量。
2、性能問題
性能問題的主要應對方式是建設分布式緩存架構,也包含四個方面的建設。首先是容量評估(對應緩存要緩存什么數據,緩存數據有多大規模,增長趨勢如何等),有了這些評估情況,就可以進行緩存組件選型(本地緩存LocalCache還是分布式緩存,分布式緩存常見的還有memcached或redis等),原則上,如果緩存數據不多,能使用LocalCache搞定的就盡量用LocalCache,會相對簡單。
與此同時,因為互聯網產品用戶規模大,需要緩存的數據多,大部分情況都要用分布式緩存就來解決,所以緩存組件也需要建立性能基準,確定請求安全閾值,建立監控和報警機制,最后也要提前做好緩存容量可擴展預案。
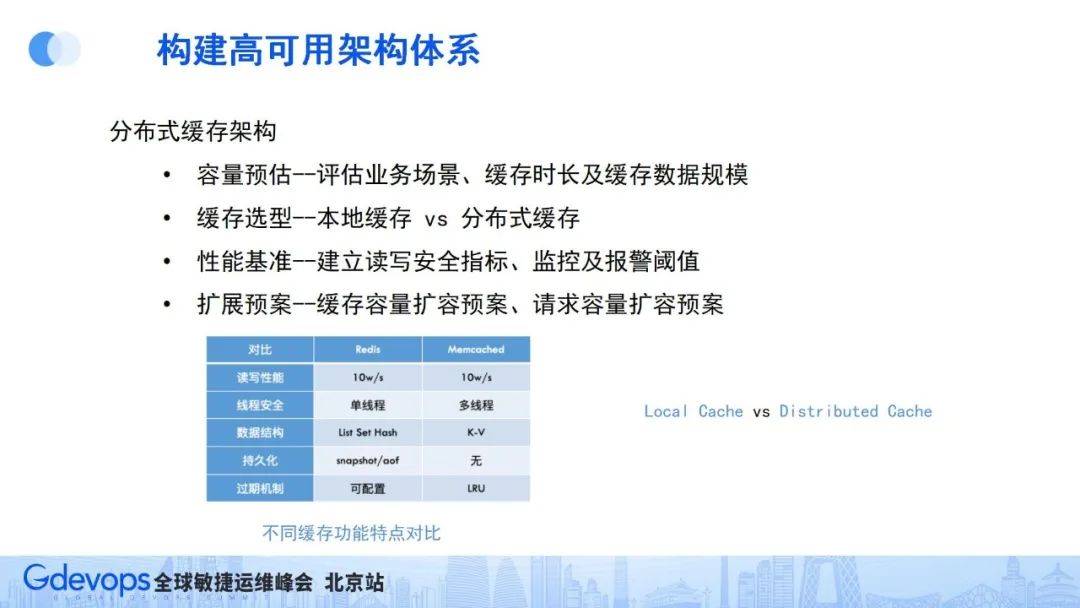
緩存容量的可擴展和保障預案主要從下面三個方面準備:
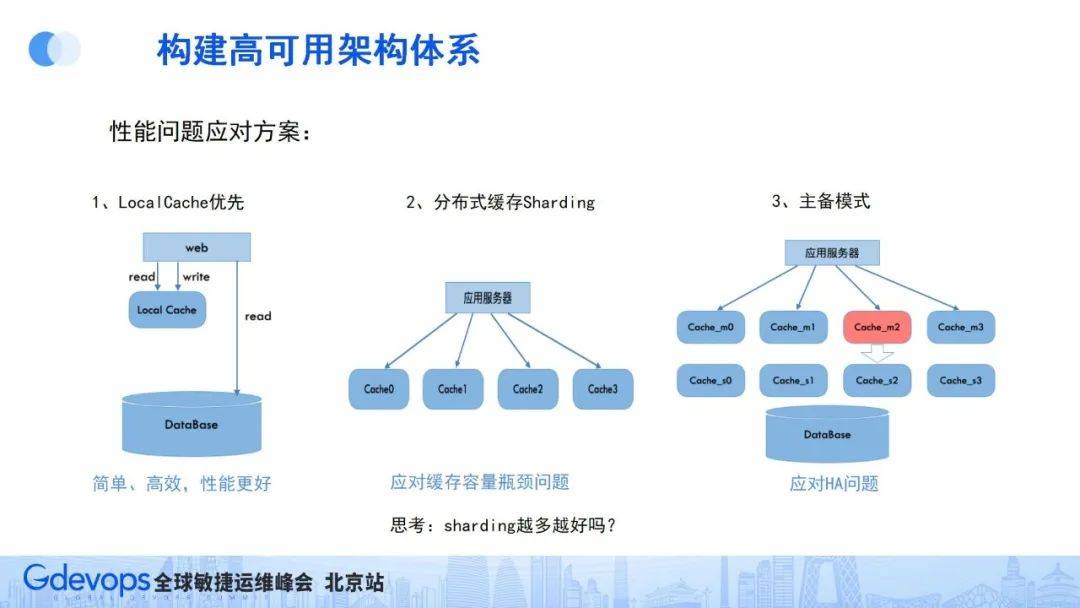
因本地緩存機制簡單高效、性能好,所以要優先使用本地緩存LocalCache;如果本地緩存放不下,就要使用分布式緩存,使用sharding分片把數據按指定hash規則放到對應緩存實例中;同時還需要考慮緩存高可用的問題,因為一旦緩存出了故障,就會有大量請求直接穿透數據庫,可能會直接把對應數據庫實例打掛,造成服務雪崩,一般預防措施是采用Master/Slave的主從模式。
3、依賴問題
系統一般都會有核心和非核心功能,它們之間會有調用關系,也就是有依賴關系。通常情況下,這種調用依賴會加上超時控制和重試機制,盡量降低依賴的影響。
同時,在核心功能內部,也會有核心服務模塊和非核心服務模塊、核心資源和非核心資源;因為這些服務模塊在一個JVM(以JAVA環境為例)或容器里,在運行環境中共享cpu、內存、磁盤,所以它們之間的很難避免互相影響。
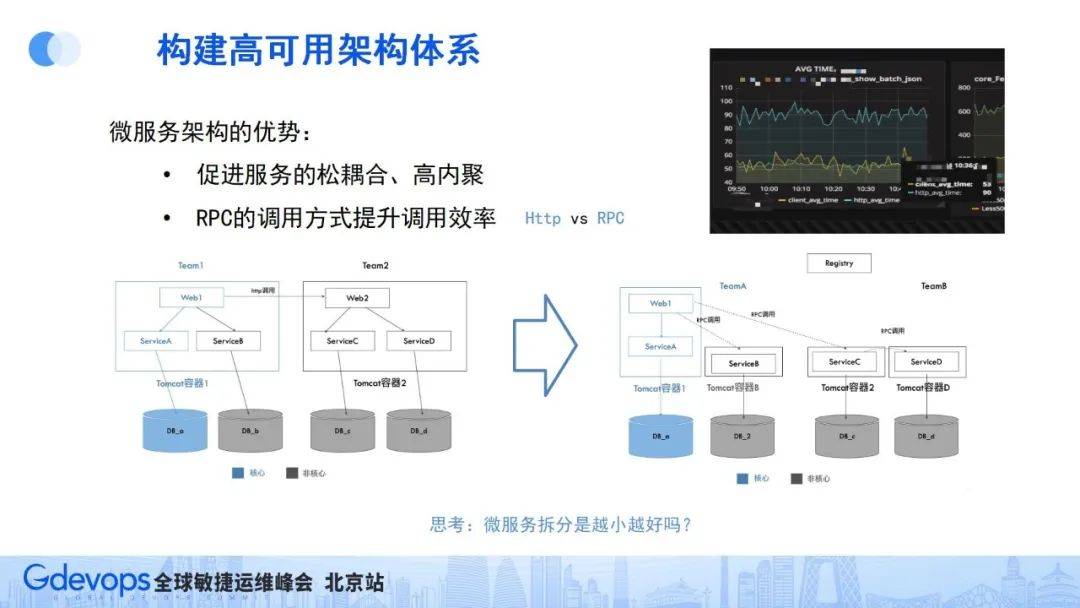
基于這種情況,我們通常會想到微服務架構。微服務架構在2012、2013年的時候就非常火,好的微服務架構要求實現松耦合、高內聚。
通過微服務的理念,把服務模塊拆得足夠細,再加上超時控制和容錯機制,相互之間的依賴會變輕量,但同時會帶來另一個問題——服務性能會變差。
通常HTTP調用相比JVM內部的進程調用耗時會慢很多,所以我們又引入了RPC調用方式來解決服務性能的問題。RPC的調用方式是在調用方和被調用方之間建立長連接通道,相比HTTP調用,省去了域名解析、握手建連流程,調用效率會高很多。
微博內部服務使用了php、GO、Java等不同的開發語言,為了能讓這些服務間實現高效的RPC調用,我們在2014年自研了跨語言RPC服務Motan,并于內部廣泛使用。目前這個RPC框架是已開源,已有5000+ star,感興趣的同學可以去了解和共同建設。Github地址:https://github.com/weibocom/motan
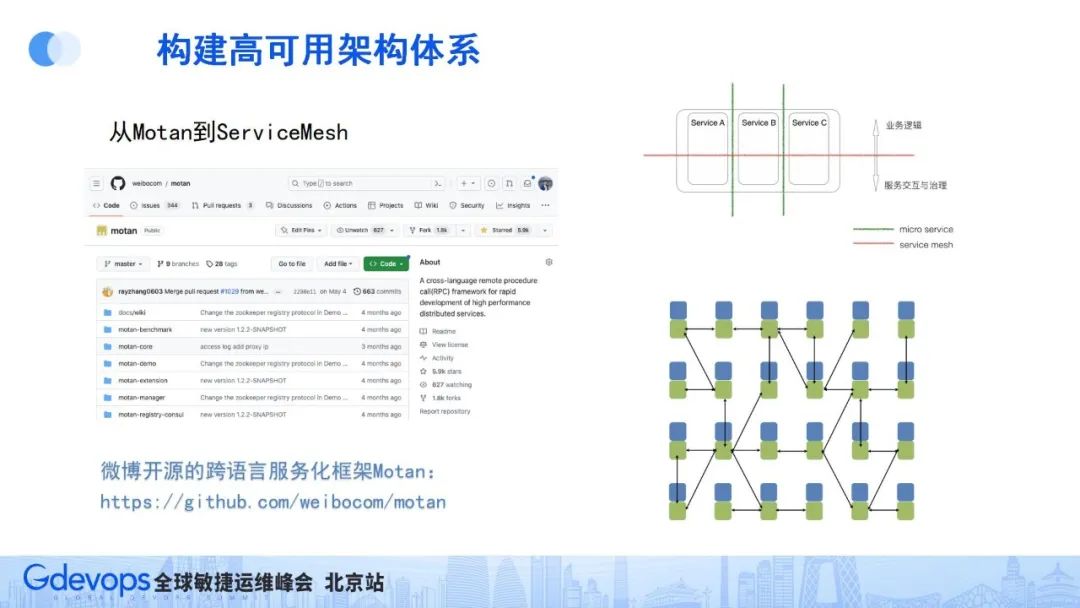
2017年左右出現了ServiceMesh技術,這是對微服務和RPC技術的一次理念升級。
因微博場景需要解決跨語言的問題,所以很早就在motan RPC框架基礎上,把服務治理能力抽象到一個Agent中,然后部署上下層成為基礎設施組件的一部分,這和業界ServiceMesh的部分理念不謀而合。
緊接著,我們在Motan框架基礎上建設了WeiboMesh服務組件。區別于原來的微服務,我們無需業務關心通用服務治理能力下層的基礎設施層,只要用了WeiboMesh,自然就具備了相關的通用服務治理能力,業務在調用接口的時候,就感覺在調用本地服務接口一樣方便。
下圖所示為WeiboMesh架構。我們把WeiboMesh服務直接打到基礎鏡像里,這樣在業務部署服務時,自然就有了服務網格的基礎通信能力、服務治理能力,業務間通過服務網格的通信基礎走長連接通道,更加方便高效。
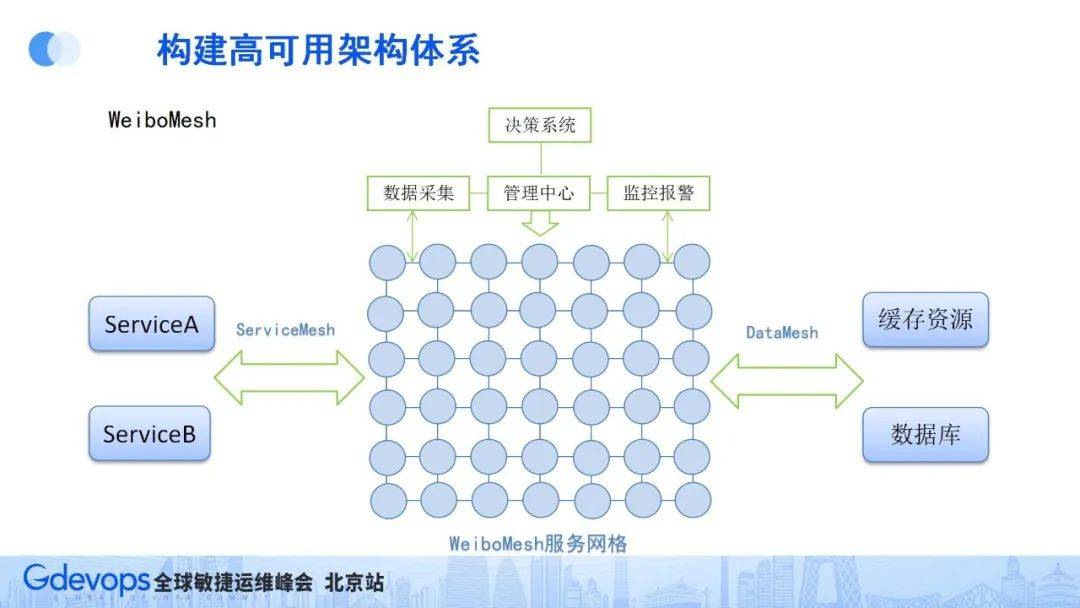
WeiboMesh的使用主要分成兩方面:一方面是服務間的調用(ServiceMesh);另一方面是資源調用(DataMesh)。
資源調用DataMesh對性能要求會更高一些,有了服務網格模式后,我們就能更好地監控到所有業務的資源調用情況,方便進行相關調用管理,比如資源流量調用等。有了這些監控數據和調度手段,就能夠在全站建立聯動策略和故障容災體系。
目前為止,我們通過微服務架構解決了服務依賴問題、通過Motan RPC調用解決了調用性能問題、通過ServiceMesh解決了服務治理通用化問題。但微服務還帶來了一個問題——運維復雜度問題。
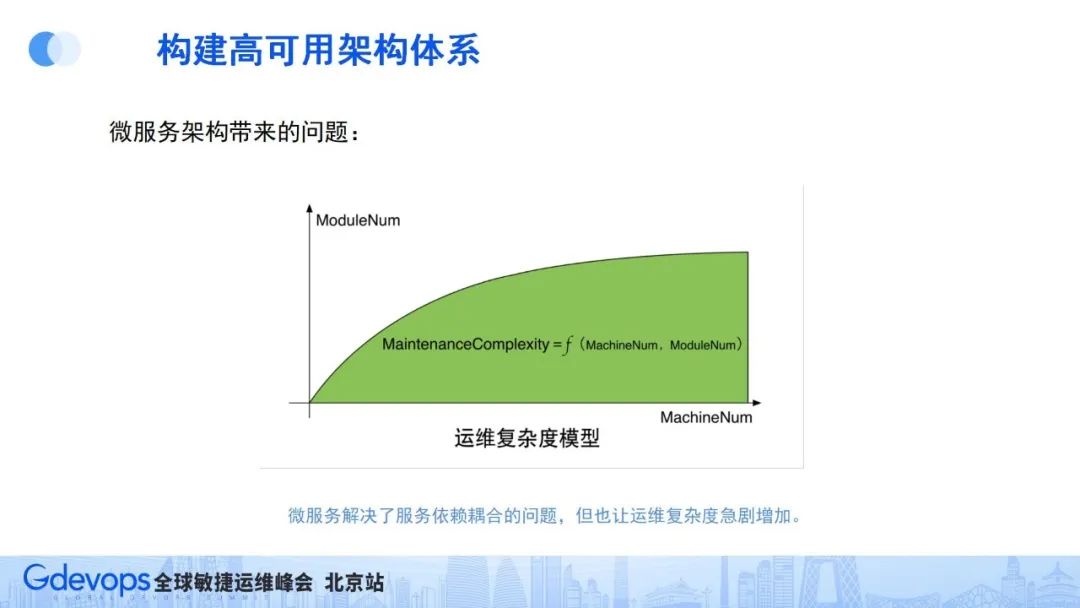
如上圖所示,運維復雜度取決于兩個因素:
- 服務規模:整個集群部署的服務器越多,運維復雜度就會越大;
- 服務種類:集群中的服務類型越多,運維復雜度也會隨之提升。
所以,微服務拆分之后,即使集群還是同樣的服務器規模,但是服務種類大幅增加了,運維復雜度也大幅增加了。
在2014年左右,Docker容器化技術正好出現了,其可以實現用非常小的成本解決運維復雜度的問題,微博作為國內最早一批大規模應用容器化技術的團隊,也享受著這一新技術的紅利。
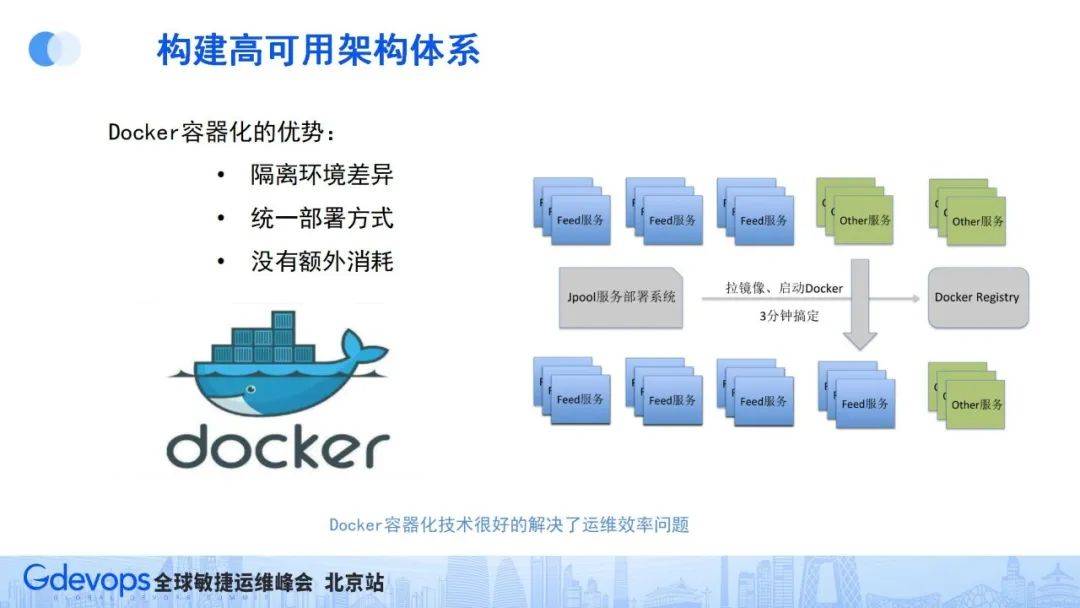
Docker容器化技術的優勢是可以隔離環境差異、實現統一的部署方式,同時還沒有太多額外消耗。統一部署方面,我們通過統一基礎鏡像的方式,解決組件和版本依賴問題。
如微博春晚擴容場景。因之前運維復雜度高,春節需要提前一個月準備采購機器和版本環境,不同服務還要檢查相關差異,而在2014年春節的時候,我們首次大規模應用容器化技術進行春晚抗峰擴容,利用容器化技術屏蔽系統環境和版本差異,擴容準備時間大幅縮短,很好地解決了微服務帶來的運維復雜度問題。
同時,伴隨著現在公有云廠商的出現,我們又有了新的想法。回顧微博4種典型流量場景,微博的流量高峰和低谷都非常明顯,如果按照高峰來部署服務器,資源成本會非常高,因此在運維效率得到一定的提升之后,我們只需部署基礎流量的服務器資源,出現流量高峰的時候再從公有云臨時借用一部分服務器,流量高峰過去后再歸還,這樣的策略大幅降低服務器成本。
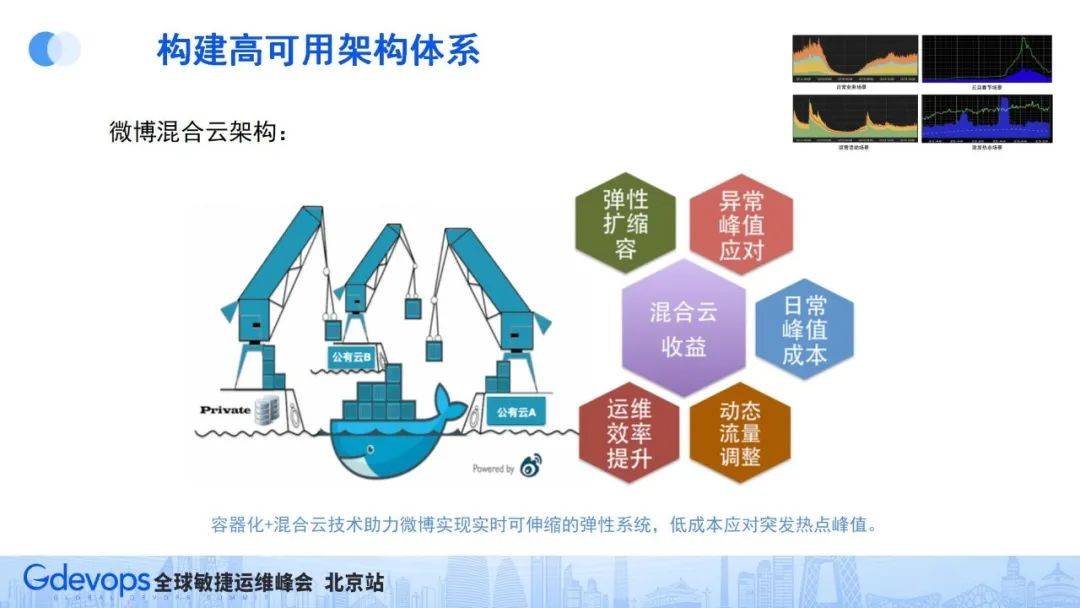
基于以上思路,我們通過容器化技術+公有云技術,并通過容器化技術屏蔽我們本地服務器和公有云服務器的環境差異,建設了微博的混合云架構。
混合云架構讓微博可以日常部署基礎的服務器資源,在各種流量高峰場景,還可以快速從公有云臨時借服務器部署,極大地降低服務運維資源成本。特別是在微博的突發熱點場景下,依托混合云技術的動態擴縮容能力,讓我們可以用相對較小的成本,很好地應對微博突發熱點流量。
4、容災問題
多機房部署是大型服務必須考慮的事情,因此機房容災的重要性在這幾年特別突出。有些公司因機房問題導致的故障甚至還上了熱搜,還因此受到了處罰,所以基礎運維負責人要尤為重視容災問題。

說到多機房容災架構,我們一定首先要了解一個古老而重要的理論——CAP理論(就是一致性、可用性、分區容忍性,同一時間場景只能滿足其二),對于社交場景一般是舍棄一致性,把一致性從強一致性降為最終一致性。
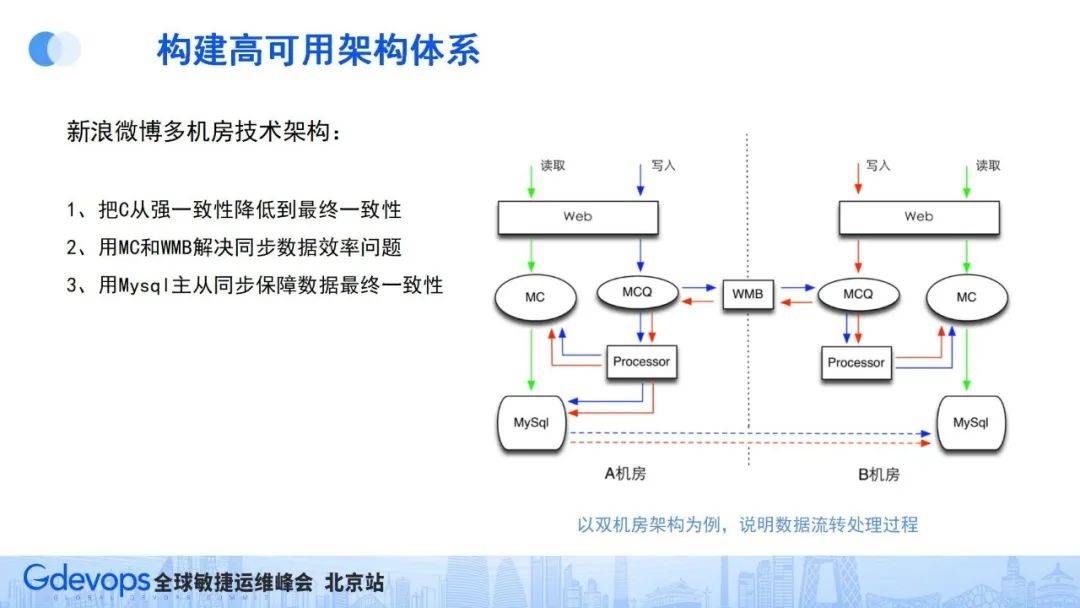
上圖是微博的簡化版多機房架構,這個架構主要解決三個問題:
- 一是把數據的強一致性降為最終一致性,多個機房之間的最終數據是通過數據主從同步的方式實現的,以此來保障機房數據的最終一致性;
- 二是通過自研的WMB消息總線服務,快速把消息進行機房間同步,保障機房間消息同步的高效、穩定、完整;
- 三是通過緩存機制,保障用戶實施看到不同機房間的消息內容,不過度依賴數據庫同步。
在這樣的架構下 ,即使某一機房出現問題,機房內部還能形成自運行生態,從而保障服務可用。
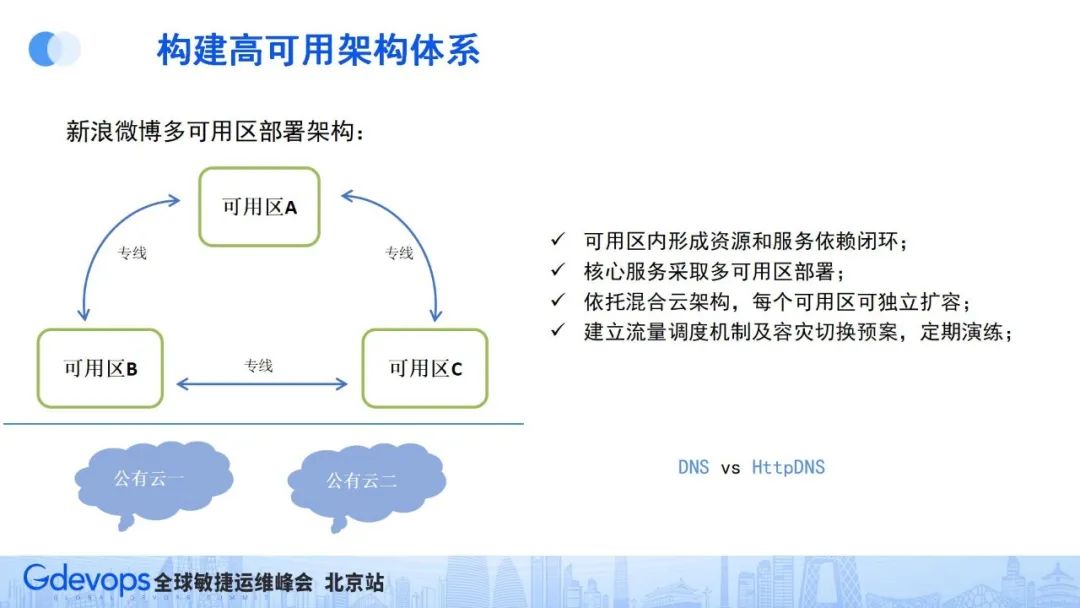
微博的機房較為分散,把幾個相近的機房稱為一個可用區,最終微博形成的是:三可用區+公有云架構。在可用區內部,服務和資源依賴形成閉環,同時不能強依賴可用區外的服務和資源,核心服務采用多可用區部署;同時依托混合云架構,讓每個可用區可獨立通過公有云隨時進行快速擴容;最終還要建立流量調用機制,并定期進行相關場景的容災演練。
5、監控體系、服務治理SLA體系
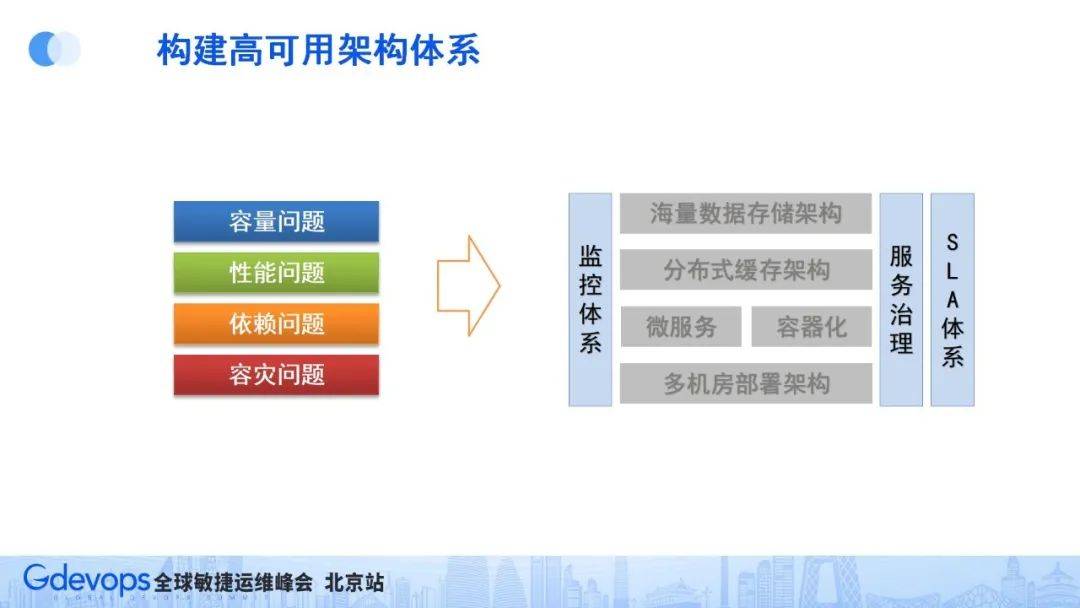
探討四大問題后,還需要探討監控體系、服務治理SLA體系問題。服務監控是整個高可用體系的眼睛,能夠及時發現問題并制定預案,服務治理也已完全融入ServiceMesh中,SLA體系作為重要的量化指標,對確保上下游建立良好默契、提高解決問題的效率有著重要作用。

高可用架構體系易于搭建,難在維護。隨著日常需求的不斷上線變更,系統架構也在不斷變化,原來的容災預案也可能會受影響而失效。因此,多機房架構需要持續地積累和傳承,最終把這個技術經驗轉化為基礎組件,形成平臺的技術體系。
有了平臺的技術體系,系統的可用性就無需過度依賴人的因素,只需服務部署在這個技術體系上,海量數據存儲、分布式緩存架構、混合云體系能力都可以渾然天成。
三、新的探索與展望
微博一直在建設PAAS平臺,未來,我們希望把平臺積累的技術經驗、技術組件集成到這個PAAS平臺上,業務開發同學把功能開發完成后,只要在git提交,就能自動進行CI/CD流程、進行服務部署。
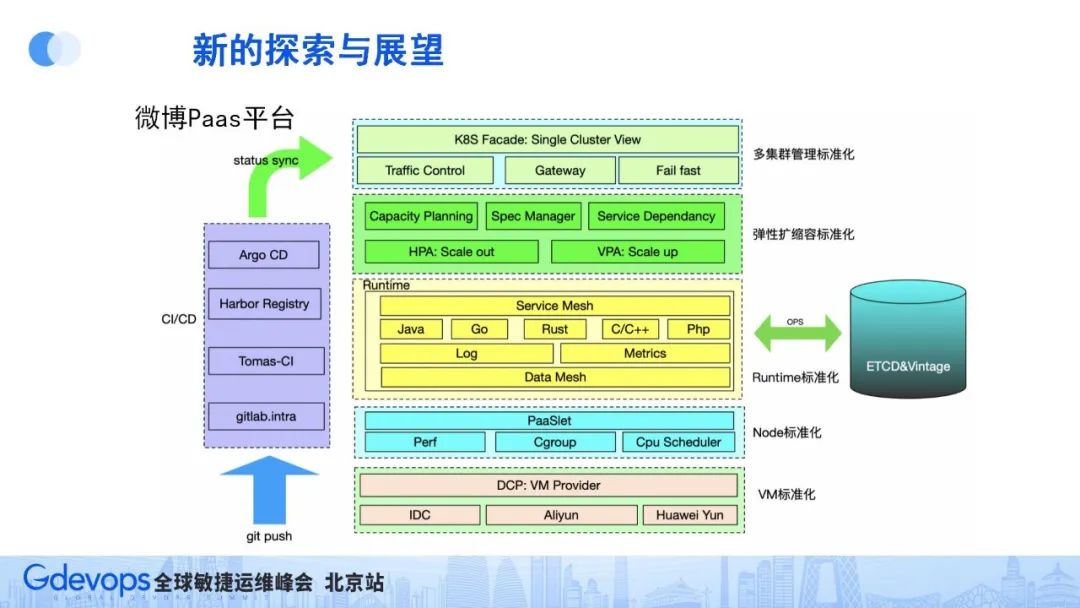
微博PAAS還以混合云技術為基礎,實現服務資源的動態擴縮容能力,通過容器化技術和K8s技術,管理并標準化服務Node節點,通過ServiceMesh和DataMesh組件,管理服務間調用和資源調用,包括繼承服務治理能力。通過Paaslet來進行資源的隔離和優先級調度,實現多類型服務混合部署,提升資源利用率。所有部署在PAAS平臺上的服務,都可以得到runtime的實時監測,可以及時發現服務運行時異常、保障服務穩定。
隨著AIGC的興起,我們也在積極探索AIGC代碼生成和異常監測方案,目前我們開發了WeCode組件,從代碼開發層面提升代碼質量保障服務穩定。
微博PAAS平臺建設方面已初具規模,也還在不斷完善,后續有機會再和大家分享。





