擊這里在線(xiàn)咨詢(xún)客服")
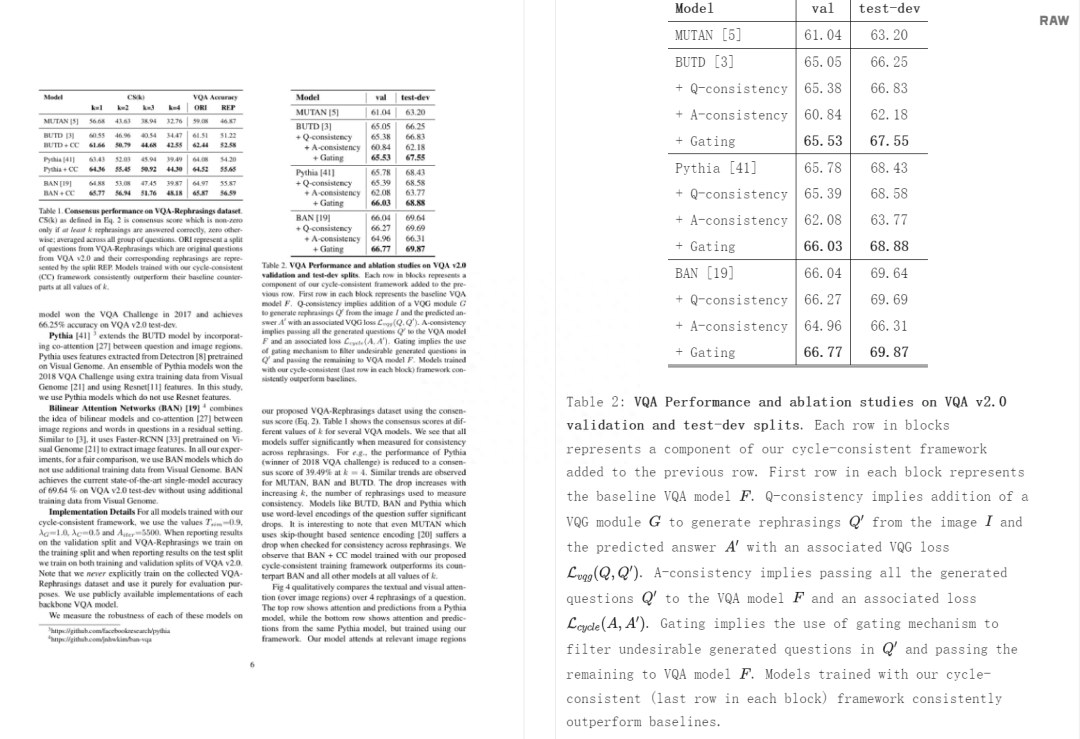
機(jī)器之心報(bào)道
編輯:陳萍、梓文
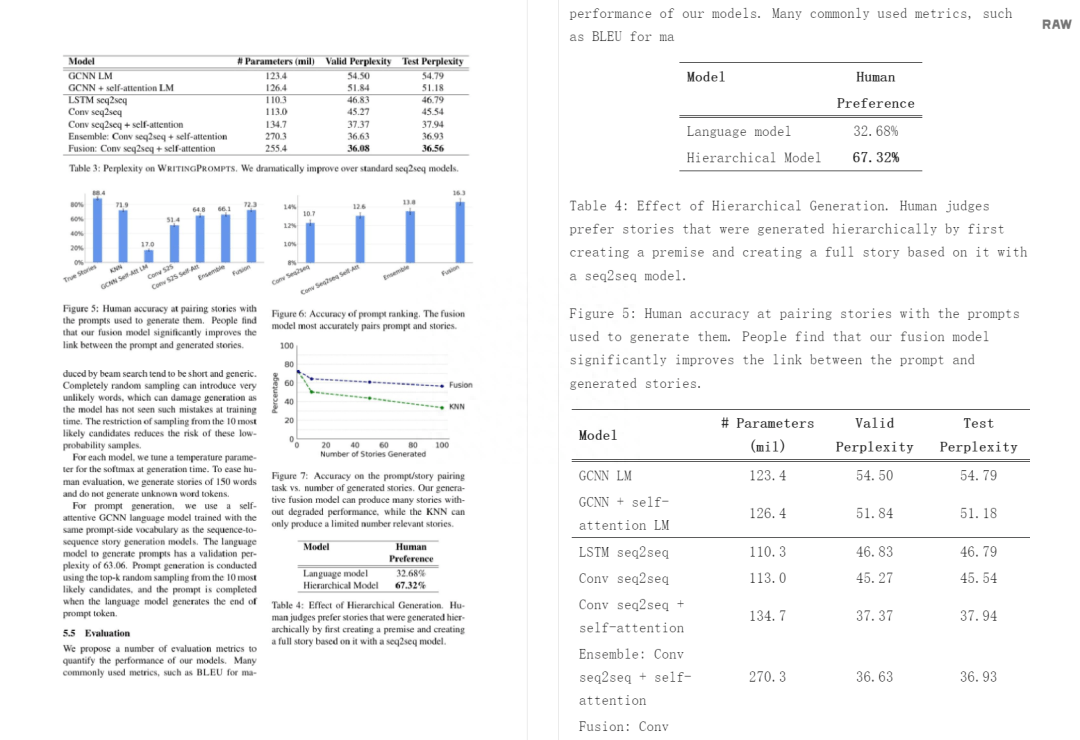
有了 Nougat,再也不用怕復(fù)雜的數(shù)學(xué)公式了。
我們平時(shí)在閱讀論文或者科學(xué)文獻(xiàn)時(shí),見(jiàn)到的文件格式基本上是 PDF(Portable Document Format)。據(jù)了解,PDF 成為互聯(lián)網(wǎng)上第二重要的數(shù)據(jù)格式,占總訪問(wèn)量的 2.4%。
然而,存儲(chǔ)在 PDF 等文件中的信息很難轉(zhuǎn)成其他格式,尤其對(duì)數(shù)學(xué)公式更是顯得無(wú)能為力,因?yàn)檗D(zhuǎn)換過(guò)程中很大程度上會(huì)丟失信息。就像下圖所展示的,帶有數(shù)學(xué)公式的 PDF,轉(zhuǎn)換起來(lái)就比較麻煩。

現(xiàn)在,Meta AI 推出了一個(gè) OCR 神器,可以很好的解決這個(gè)難題,該神器被命名為 Nougat。Nougat 基于 Transformer 模型構(gòu)建而成,可以輕松的將 PDF 文檔轉(zhuǎn)換為 MultiMarkdown,掃描版的 PDF 也能轉(zhuǎn)換,讓人頭疼的數(shù)學(xué)公式也不在話(huà)下。

- 論文地址:https://arxiv.org/pdf/2308.13418v1.pdf
- 項(xiàng)目主頁(yè):https://facebookresearch.Github.io/nougat/
Nougat 不但可以識(shí)別文本中出現(xiàn)的簡(jiǎn)單公式,還能較為準(zhǔn)確地轉(zhuǎn)換復(fù)雜的數(shù)學(xué)公式。

公式中出現(xiàn)的上標(biāo)、下標(biāo)等各種數(shù)學(xué)格式也分的清清楚楚:

Nougat 還能識(shí)別表格:
掃描產(chǎn)生畸變的文本也能處理:

不過(guò),Nougat 生成的文檔中不包含圖片,如下面的柱狀圖:
看到這,網(wǎng)友紛紛表示:(轉(zhuǎn)換)效果真是絕了。

方法概述
本文架構(gòu)是一個(gè)編碼器 - 解碼器 Transformer 架構(gòu),允許端到端的訓(xùn)練,并以 Donut 架構(gòu)為基礎(chǔ)。該模型不需要任何 OCR 相關(guān)輸入或模塊,文本由網(wǎng)絡(luò)隱式識(shí)別。該方法的概述見(jiàn)下圖 1。

該研究用到了 2 個(gè) Swin Transformer ,一個(gè)參數(shù)量為 350M,可處理的序列長(zhǎng)度為 4096,另一參數(shù)量為 250M,序列長(zhǎng)度為 3584。在推理過(guò)程中,使用貪婪解碼生成文本。
在圖像識(shí)別任務(wù)中,使用數(shù)據(jù)增強(qiáng)技術(shù)來(lái)提高泛化能力往往是有益的。由于本文只研究數(shù)字化的學(xué)術(shù)研究論文,因此需要使用一些變換來(lái)模擬掃描文件的不完美和多變性。這些變換包括侵蝕、擴(kuò)張、高斯噪聲、高斯模糊、位圖轉(zhuǎn)換、圖像壓縮、網(wǎng)格變形和彈性變換 。每種變換都有固定的概率應(yīng)用于給定的圖像。這些變換在 Albumentations 庫(kù)中實(shí)現(xiàn)。在訓(xùn)練過(guò)程中,研究團(tuán)隊(duì)也會(huì)通過(guò)隨機(jī)替換 token 的方式,對(duì)實(shí)際文本添加擾動(dòng)。

每種變換的效果概覽
數(shù)據(jù)集構(gòu)建與處理
據(jù)研究團(tuán)隊(duì)所知,目前還沒(méi)有 PDF 頁(yè)面和相應(yīng)源代碼的配對(duì)數(shù)據(jù)集,因此他們從 arXiv 上開(kāi)放獲取的文章中創(chuàng)建了自己的數(shù)據(jù)集。為了數(shù)據(jù)多樣性,數(shù)據(jù)集中還包括 PubMed Central (PMC) 開(kāi)放訪問(wèn)非商業(yè)數(shù)據(jù)集的一個(gè)子集。預(yù)訓(xùn)練期間,還加入了部分行業(yè)文檔庫(kù) (IDL)。
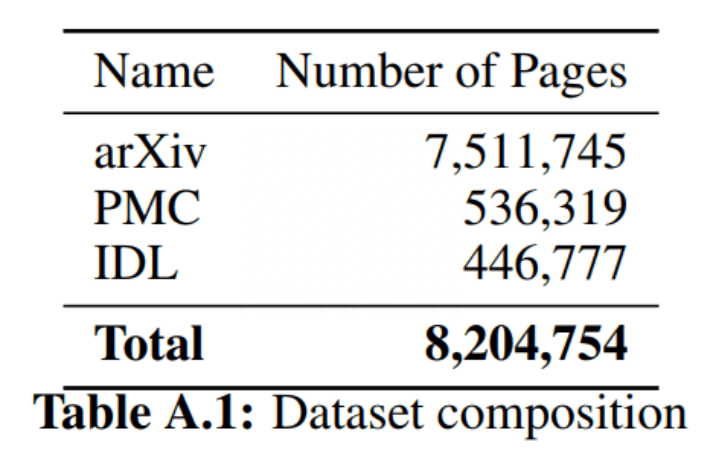
表 1 數(shù)據(jù)集構(gòu)成
在處理數(shù)據(jù)集的過(guò)程中,研究團(tuán)隊(duì)也將不同來(lái)源的數(shù)據(jù)進(jìn)行了合適的處理,下圖展示了他們對(duì) arXiv 文章進(jìn)行源代碼收集并編譯 PDF 的過(guò)程。詳細(xì)內(nèi)容請(qǐng)閱讀全文。

源文件被轉(zhuǎn)換成 html,然后再轉(zhuǎn)換成 Markdown。
研究團(tuán)隊(duì)根據(jù) PDF 文件中的分頁(yè)符分割 markdown 文件,并將每個(gè)頁(yè)面柵格化為圖像以創(chuàng)建最終配對(duì)的數(shù)據(jù)集。在編譯過(guò)程中,LaTeX 編譯器自動(dòng)確定 PDF 文件的分頁(yè)符。由于他們不會(huì)為每篇論文重新編譯 LaTeX 源文件,因此必須將源文件分割成若干部分,分別對(duì)應(yīng)不同的頁(yè)面。為此,他們使用 PDF 頁(yè)面上的嵌入文本,并將其與源文本進(jìn)行匹配。
但是,PDF 中的圖形和表可能并不對(duì)應(yīng)于它們?cè)谠创a中的位置。為了解決這個(gè)問(wèn)題,研究團(tuán)隊(duì)使用 pdffigures2 在預(yù)處理步驟中刪除這些元素。將識(shí)別出的字幕與 XML 文件中的字幕進(jìn)行比較,根據(jù)它們的 Levenshtein 距離進(jìn)行匹配。一旦源文檔被拆分為單獨(dú)的頁(yè)面,刪除的圖形和表就會(huì)重新插入到每一頁(yè)的末尾。為了更好地匹配,他們還使用 pylatexence -library 將 PDF 文本中的 unicode 字符替換為相應(yīng)的 LaTeX 命令。
詞袋匹配:首先,研究團(tuán)隊(duì)使用 MuPDF 從 PDF 中提取文本行,并對(duì)其進(jìn)行預(yù)處理,刪除頁(yè)碼和頁(yè)眉 / 頁(yè)腳。然后使用詞袋模型與 TF-IDF 向量化器和線(xiàn)性支持向量機(jī)分類(lèi)器。將模型擬合到以頁(yè)碼為標(biāo)簽的 PDF 行。然后,他們將 LaTeX 源代碼分成段落,并預(yù)測(cè)每個(gè)段落的頁(yè)碼。理想情況下,預(yù)測(cè)將形成階梯函數(shù),但在實(shí)踐中,信號(hào)將有噪音。為了找到最佳邊界點(diǎn),他們采用類(lèi)似于決策樹(shù)的邏輯,并最小化基于 Gini 不純度的度量:

其中
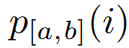
是在區(qū)間 [a,b] 中選擇具有預(yù)測(cè)頁(yè)碼 i 的元素的概率,該區(qū)間描述了哪些段落 (元素) 被考慮用于分割。
區(qū)間 [a, b] 的最佳拆分位置 t 為:

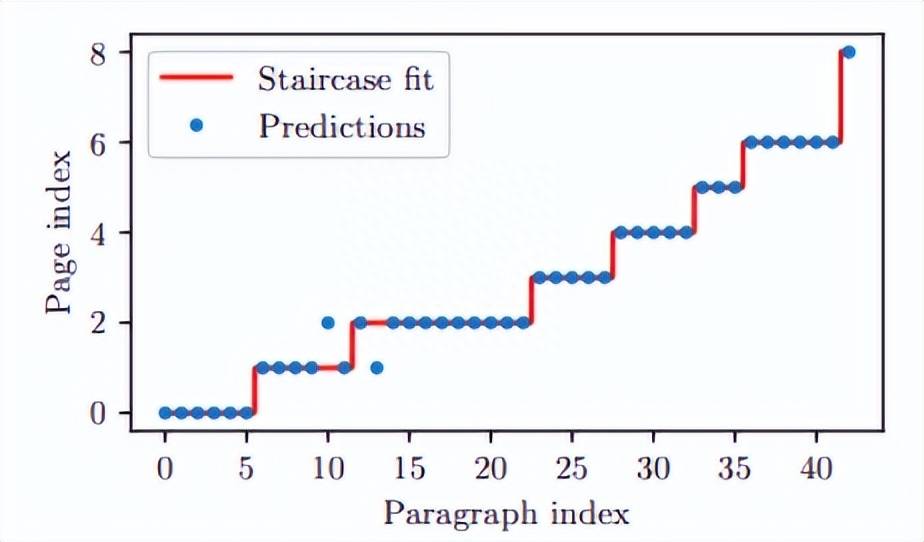
搜索過(guò)程從所有段落開(kāi)始,對(duì)于后續(xù)的每個(gè)分頁(yè),搜索區(qū)間的下界設(shè)置為前一個(gè)分頁(yè)位置。
模糊匹配:在第一次粗略的文檔分割之后,研究團(tuán)隊(duì)嘗試找到段落中的準(zhǔn)確位置。通過(guò)使用 fuzzysearch 庫(kù),將預(yù)測(cè)分割位置附近的源文本與嵌入的 PDF 文本的前一頁(yè)的最后一個(gè)句子和下一頁(yè)的第一個(gè)句子進(jìn)行比較,就可以達(dá)到這個(gè)目的。如果兩個(gè)分隔點(diǎn)在源文本中的相同位置,則認(rèn)為換頁(yè)是準(zhǔn)確的,得分為 1。另一方面,如果分割位置不同,則選擇具有最小歸一化 Levenshtein 距離的分割位置,并給出 1 減距離的分?jǐn)?shù)。要包含在數(shù)據(jù)集中,PDF 頁(yè)面的兩個(gè)分頁(yè)符的平均得分必須至少為 0.9。如此一來(lái),所有頁(yè)面的接受率約為 47%。
實(shí)驗(yàn)
實(shí)驗(yàn)中用到的文本包含三種類(lèi)別:純文本、數(shù)學(xué)表達(dá)式以及表格。
結(jié)果如表 1 所示。Nougat 優(yōu)于其他方法,在所有指標(biāo)中取得最高分,并且具有 250M 參數(shù)模型的性能與 350M 參數(shù)模型相當(dāng)。

下圖為 Nougat 優(yōu)對(duì)一篇論文的轉(zhuǎn)換結(jié)果:

Meta 表示,Nougat 在配備 NVIDIA A10G 顯卡和 24GB VRAM 機(jī)器上可并行處理 6 個(gè)頁(yè)面,生成速度在很大程度上取決于給定頁(yè)面上的文本量。在不進(jìn)行任何推理優(yōu)化的情況下,基礎(chǔ)模型每批次平均生成時(shí)間為 19.5s(token 數(shù)≈1400),與經(jīng)典方法(GROBID 10.6 PDF/s )相比速度還是非常慢的,但 Nougat 可以正確解析數(shù)學(xué)表達(dá)式。





