
誰也沒想到,向量數據庫會發展得這樣快!
時間回到 2018 年, FAIss 項目剛剛開源,Milvus 才寫下它的第一行代碼。我們也只預見到向量數據庫和嵌入式技術將會成為非結構化數據領域的關鍵研究工具。
很快,LLM 時代到來,從 BERT 到 GPT3,再到 GPT4 以及開源大模型 LLaMa,大模型能力日漸增強,生態逐步開發開放,加上向量提取技術的快速進步,人們越來越認識到高維向量在信息檢索和生成中的重要地位。生成型 AI 大模型通常需要使用相似性搜索和匹配的結果作為 Prompt,以便提供精準的回復、推薦或匹配結果,這種方法我們稱之為“檢索增強生成”。傳統的基于關鍵詞的搜索可能無法滿足復雜的語義和上下文需求,而隨著圖像、語音等多模態大模型的涌現,向量數據庫已經成為了大模型數據存儲的事實標準。
忽如一夜春風來,千樹萬樹梨花開。大型模型的爆發使得大模型數據存儲成為構建未來AI系統的關鍵環節,同時也催生了眾多向量數據庫的出現。除了較早誕生的向量數據庫 Milvus 和云服務 Zilliz Cloud,我們還看到了 Pinecone、Weaviate、Qdrant、Chroma 等形態各異的向量數據庫和云服務的涌現。與此同時,一些傳統數據庫廠商也紛紛加入向量處理能力的提供之列,如 PGVector、ElasticSearch、MongoDB 等都推出了對向量的支持(Lucene 對 Dense Vector 的支持進一步推動了這一趨勢)。
然而,隨著向量數據庫如雨后春筍般涌現,如何科學地評價和選擇一個優秀的向量數據庫,成為了一個備受討論和爭議的話題。
正如我們在評估大模型時會考慮其準確性、多樣性、泛化能力、推理性能等諸多指標一樣,本文也將嘗試從多個角度分析向量數據庫的異同,并為每種產品賦予獨特的價值定位。實際上,當我們撥開表面的迷霧,聚焦向量數據庫本質的時候,就會發現在向量數據庫的概念外殼下包含著各式各樣的內在要素。向量數據庫作為一個獨特的產品類別,其存在必然包含著特殊的價值,且一定會進化并分化出具有各自特點的產品。
01
向量數據庫- Just Another WrApper for Faiss?
根據微軟的定義,“向量數據庫是一種將數據存儲為高維向量的數據庫,高維向量是特征或屬性的數學表示。”拆解來看,向量數據庫有兩個關鍵要素,一是面向高維向量數據的處理能力,二是具備一個數據庫的基本能力,因此以下幾個因素是向量數據庫必須要具備的:
1)支持向量數據的增刪改查
2)高性能的向量檢索
3)支持數據的持久化
4)支持一種易用的查詢語言
除了上述的基本需求,我們還可以從許多角度來評估向量數據庫:系統的擴展性、彈性、可用性,所采用的向量檢索算法,是否支持標量過濾、混合查詢、多向量等功能,是否開源,是否提供云服務,以及是否有完善的生態支持等等。“并非所有的向量數據庫都天生平等”,在研究和選擇向量數據庫時,這些都是我們必須要考慮的因素。
Chroma 曾是一個建立在著名的實時 OLAP 數據庫 ClickHouse 之上的向量數據庫,盡管因此被批評為“只是在ClickHouse 上加了一個輕量級的封裝”,但這個剛成立一年的初創公司還是憑借其向量搜索功能獲得了 1800 萬美元的種子輪融資。Chroma 在底層深度依賴 ClickHouse 和 HNSWlib,只是在向量檢索上增加了一層 Python/ target=_blank class=infotextkey>Python 封裝。這種依賴第三方構建復雜軟件和服務的方法雖然快速,但會引發嚴重的性能問題,也會使得軟件迭代變得非常困難。
事實上,僅僅數月后,Chroma 就決定放棄對 ClickHouse 的依賴,轉而基于 SQLite 重建其查詢引擎。Chroma 的經歷證明,向量數據庫絕不是簡簡單單的功能組合,做好向量數據庫同樣需要良好的設計和大量的工程實踐。
0
2
傳統數據庫- 向量數據庫的終極選擇?
除了專屬向量數據庫,傳統數據庫也紛紛支持了向量檢索能力,包括 PostgreSQL、ElasticSearch 和 redis 等在內的數據庫廠商紛紛加入這一賽道。那么,向量數據庫是否會像很多 NoSQL 數據庫一樣,慢慢被關系型數據庫所取代呢?
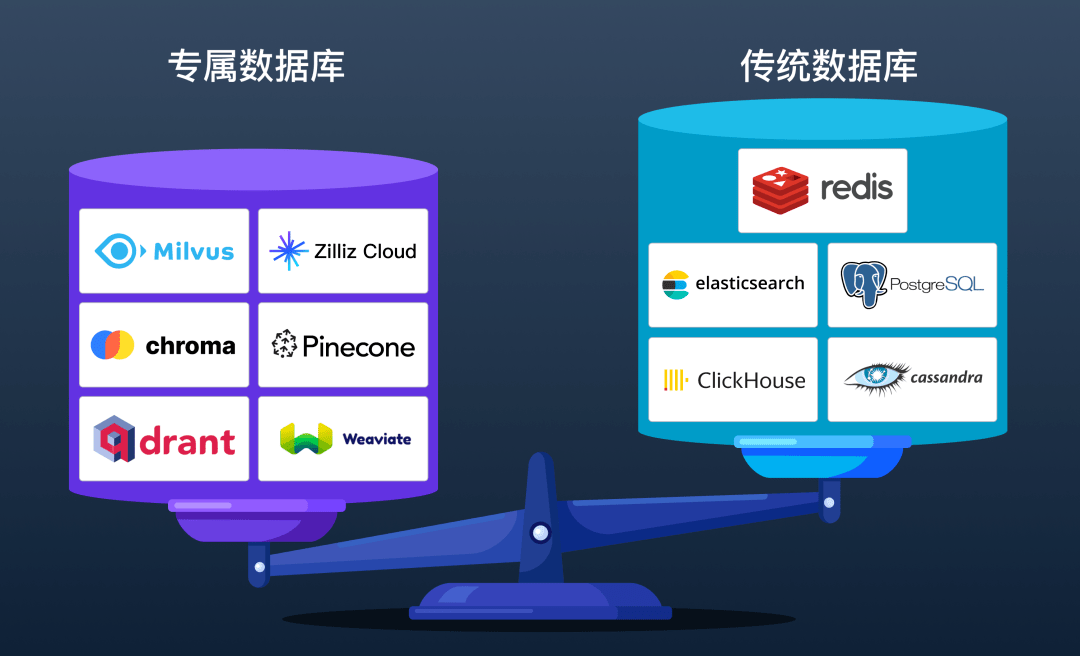
盡管傳統數據庫已經擴展其功能以支持向量搜索,專門的向量數據庫在許多方面仍具有突出優勢。首先,向量數據庫在易用性方面表現得更為優秀。雖然對于許多開發者而言 SQL 的學習成本相對較低,但傳統數據庫對 SQL 語法的兼容實際上成為了其功能迭代的包袱。相反,向量數據庫往往提供了更易于迭代和拓展的 Python、JAVA 和Restful API 接口,從而可以更方便地增加新的功能和語法。這使得向量數據庫能夠適應 AI 和大數據領域日新月異的變化,更符合開發者的需求。
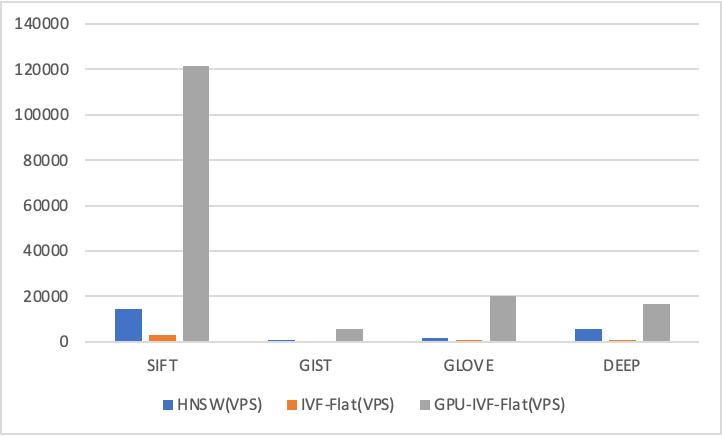
其次,向量數據庫在處理高維向量數據時通常能夠提供更高的性能。這種性能優勢不只是源于對向量索引的優化,更多地在于向量數據庫對算力資源的有效利用和對數據分布的深入理解。優秀的向量數據庫會基于 CPU SIMD、GPU 等算力進行優化,我們的測試結果顯示,GPU 索引的性能可能優于 CPU 的十倍以上。相比之下,傳統數據庫雖然增加了對向量數據的支持,但其能力往往受限于已有的系統架構,因此很難充分利用算力資源。同時,傳統數據庫也無法像專門針對向量數據設計的數據庫那樣,更有效地處理向量數據的分片、增量插入和刪除等問題。
向量數據庫的終極武器就是AI化,它不僅是DBfor AI的最佳實踐,查詢不需要100%準確的特性也使得向量數據庫成為了AIfor DB的理想試驗場。向量數據庫可以無縫地與 LLM 應用集成,提供一站式的數據管理和處理解決方案,成為多模態數據之間的重要橋梁,這一生態優勢是傳統數據庫難以超越的。同時,向量數據庫本身重度依賴Embedding、Ranking、Clustering 等機器學習技術,與傳統數據庫開發者之間存在較大的技術鴻溝,想完成跨界絕非易事。
正因為此,我們可以看到傳統數據庫在向量檢索領域并沒有太多驚艷的實踐案例,且或多或少地存在更新困難、性能慢、標量向量查詢無法打通、索引任務和查詢相互影響等問題。
03
優秀的向量數據庫,到底需要哪些能力?
那么,如何打造出一款出色的向量數據庫呢?在我看來,架構、算法、計算能力以及對場景的深入理解是關鍵。
首先,我們談論架構。向量數據庫與傳統數據庫有很多不同之處,例如,向量索引構建傾向于離線操作且消耗大量計算資源,這意味著將計算密集任務 Offload 到數據庫的概念在向量數據庫中能得到更好的實現。實現 Offload 計算任務的關鍵在于實現存儲計算分離,只有在系統完全無狀態化的情況下,才能解除數據和計算能力之間的耦合,實現真正的彈性。傳統的數據庫的架構設計并沒有考慮向量數據本身的特性,比如索引的不可變性、計算資源的消耗、內存使用成為主要瓶頸,這便帶來了一個問題——盡管傳統數據庫可以支持向量插件,但對增刪改查和存算分離等特性并不能進行有力的支持。
目前,絕大多數向量數據庫直接使用如 Faiss 或者 HNSW 這樣的向量檢索庫,這可以快速獲得不錯的性能。然而,隨著向量數據庫使用場景的復雜化,傳統向量索引在滿足開發者對于標量過濾、多向量混合查詢的需求方面變得力不從心,提升性能需要綜合考慮向量和標量之間的關系。每種向量索引在性能、成本、功能上各有優劣,無法一刀切,這也是我們決定重新自主研發向量數據查詢引擎的關鍵原因。
接下來,是底層硬件能力的應用。這也是向量數據庫與傳統數據庫的重大區別之一。近年來,隨著 NVMe,RDMA 等技術的發展和普及,傳統數據庫的瓶頸逐漸從磁盤和網絡轉向了 CPU,但其計算密度仍然遠遠低于向量數據庫所需的稠密向量距離計算。隨著圖索引越來越成為向量檢索的主流,它帶來的內存/IO 隨機訪問問題開始成為了向量數據庫進一步優化性能的關鍵挑戰。
最后,我們需要深度理解用戶場景。比如在大模型知識庫場景下,往往有多租戶查詢、行級權限管理、動態 Schema 等業務需求。對于訓練數據的檢索,則需要非常靈活的標量過濾能力,海量數據的離線導入能力以及磁盤索引的能力來降低海量數據的服務成本。如同十多年前的移動互聯網浪潮成就了MongoDB,這一波AIGC的浪潮也一定會給數據庫帶來更多場景的需求和新的挑戰。
04
做好 Vector Database - 我們是專業的!
如今 Milvus 即將迎來誕生的第五個年頭,全面更新的 2.3 版本于上周發布。Milvus 2.3 版本正式支持了GPU索引、RangeSearch、MMap加載數據等更多能力,幫助用戶進一步降低了向量檢索的使用成本。不僅如此,基于開源 Milvus 的托管云服務 Zilliz Cloud已在國內全面發布,用戶可以基于向量檢索服務和大模型 API 快速構建自己的 AIGC 應用。
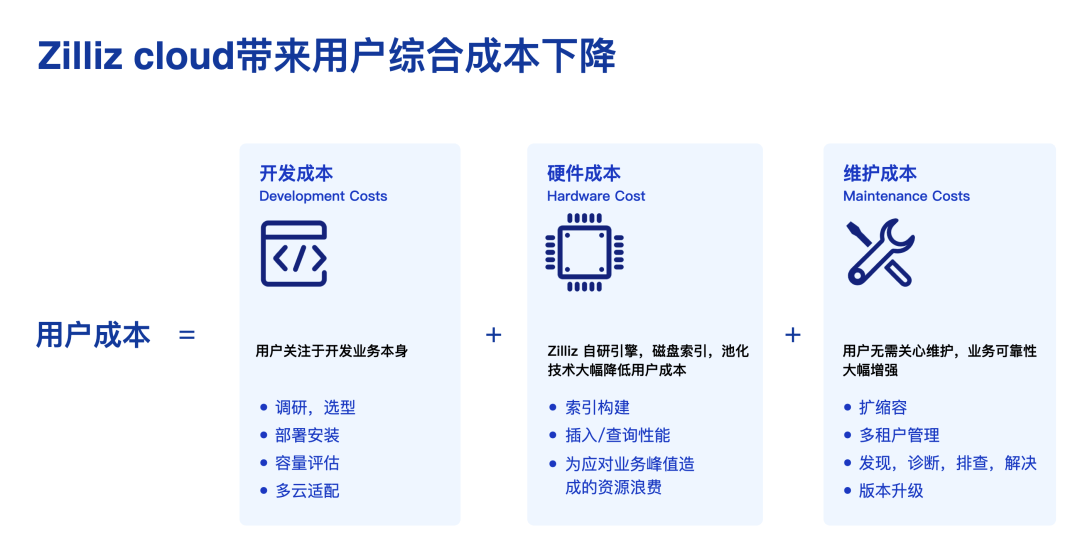
對比開源的 Milvus,Zilliz Cloud更強調降低用戶的總體成本,包括硬件成本,開發成本以及維護成本。這不僅有助于快速推出用戶應用以搶占市場份額,同時也確保了應用的穩定運行。
以下是 Zilliz Cloud 的主要優勢和提供的核心能力:
- 自研的 Cardinal 向量引擎:Zilliz Cloud 的 Cardinal 引擎優化了圖索引算法,支持內存和磁盤兩種模式。與開源的 SOTA 相比,Cardinal 引擎可以提供 3 倍以上的性能提升。此外,Cardinal 對于標量過濾和增量更新等場景也有獨特的優化方案,基于統計信息的過濾方案相對于傳統前過濾方案可以實現超過 10 倍的性能優化。關注向量數據庫性能的用戶,請參考 VectorDB Benchmark。(https://Github.com/zilliztech/VectorDBBench)
- 智能索引調優:在向量檢索中存在著 CAP 理論,即成本(Cost)、性能(Performance)和召回率(Accuracy)三者之間只能取其二。用戶在調整查詢參數時,除了需要關注這些指標,還需要考慮硬件資源、索引構建速度、TopK、數據分布、數據規模等因素。Zilliz Cloud 的 AutoIndex 技術可以根據用戶的數據分布和查詢動態選擇查詢參數,以實現最佳查詢性能。這不僅降低了用戶的使用成本,同時也可以大幅提升處理大數據集時的查詢性能。
- 數據服務:Zilliz Cloud 支持數據備份恢復、數據遷移、數據導入、數據導出等服務,它還將推出知識庫增強接口,幫助用戶更有效、安全和便捷地管理數據,如同操作傳統數據庫一樣。
- 跨云跨機房:Zilliz Cloud 高度依賴云基礎設施,以確保數據的高可靠性。其企業版默認采用 3AZ 容災策略,也將推出跨可用區域的容災能力,從而最大程度地保證服務的安全可用。針對需要海外部署和多云容災的用戶,Zilliz Cloud 目前已支持 AWS、GCP、阿里云等主流云服務廠商,并即將推出對 Azure、金山云的支持。
- SLA 保障:Zilliz Cloud 向用戶提供月 99.9% 的服務可用性保證。作為 Milvus 開源項目背后的商業化公司,Zilliz Cloud 集結了全球頂尖的工程師,能夠幫助用戶解決業務挑戰,保證服務的穩定性。
05
總結
向量數據庫作為大模型實現的重要補充,其價值不容忽視。隨著大模型的廣泛應用與實際落地,用戶對于數據庫的性能、擴展性和穩定性等方面的需求不斷提升。然而,在眾多向量數據庫中選擇一款最適合自身業務的,無疑是一個富有意義卻頗具挑戰性的任務。如果你正在尋找一款讓人省心、定價合理的向量數據庫,那么Zilliz Cloud無疑是最佳選擇,其高效穩定的特性,絕對能滿足你的各項需求。
更多詳情可以訪問 Https://zilliz.com.cn。





