

前言
如果嫌麻煩,你可以直接跳到正題觀看~
最近無論是在工作中的交談,還是在日常刷屏的新聞,鋪天蓋地的都是大模型。我橫豎是看不明白,費了大勁終于從字縫里看到了兩個字,玄學。仿佛回到了我的學生時代。
還記得6年前剛進入研究生實驗室時,師兄興奮的對我說:小伙子,歡迎來到我們的修仙世界!——當時學校跟英偉達合作,剛剛從英偉達那里弄了500塊Tesla顯卡,供各個實驗室申請使用。這,是我們嶄新的煉丹爐。經過3年的研究生生涯,我對深度學習的理解,僅僅到能夠使用深度學習模型的程度。期間也有一些小成績,包括一篇CCF B類會議論文和一篇KBS期刊(影響因子8.038) ,文章內容主要是使用LSTM對用戶興趣偏好和用戶興趣遷移建模,以此來搭建一個推薦算法模型。
我們通過對各種神經網絡模型的堆疊以及反復的對比實驗,確實發現LSTM模型的能夠在準確率、召回率等指標上有比較突出的效果。但是有一個很大的問題攔在我面前:我如何去解釋它?確實,我們沒法從直觀定性的角度去解釋,也沒有數學邏輯能解釋。索性我們當時就套用了大家統一的口徑,解釋說LSTM具有長短時記憶能力,因此能夠歸納隨著時間軸變化的數據規律。還好當時的審稿人并沒有對我們的解釋提出質疑,也可能不只是我一個,而是大家的論文都沒有很好的解釋它。
無論是簡單的FC、CNN、RNN、LSTM這些模型,還是當下最火的所謂的大模型依賴的Transformer模型,都是基于梯度下降和反向傳播進行訓練,至于為什么通過這樣的訓練就能讓模型中參數自動自洽,到如今也沒有人能夠證明。我們只是知道通過這樣去構造模型確實行之有效。
相反,很多傳統的機器學習算法,要么有嚴格的數學證明,要么是直觀就能觀察到算法的過程。相比于深度學習模型,我認為能夠提出這些傳統機器學習算法的前輩們更加值得敬佩。因此,本文主要是簡單的分享一個所謂「傳統機器學習算法」在實際業務中的使用場景。當然,我再次聲明我對深度學習的理解尚淺,如有表述不當之處,可以互相交流。

正題
在計劃域中,有很多很有意思的問題需要解決,包括如何制定中長期采購計劃?如何制定短期補貨計劃?倉庫庫存偏倉怎么辦,如何配平,是否需要調撥?我能預測一下未來一段時間某個貨能賣多少嗎?解決每一個問題,都能給供應鏈的效率和損益帶來巨大價值。
那我們以調撥計劃為例,看看這些算法是怎么優雅地解決這個問題的——這里說到的算法,都是傳統的機器學習算法。
?模型定義:如何用數學模型定義一個調撥業務,并將業務目標變成模型目標函數
為了降低問題的復雜度,便于大家理解,這里我們的對問題的定義進行了一定的簡化,比如不考慮未來銷售可能存在的波動、偏倉造成的銷售機會損失、貨物在運輸途中存在損毀概率等等。并且,下面的案例只給了一個調出倉、一個調入倉。實際業務中問題更復雜,定義約束也更多,求解的模型可能會不一樣。算法大佬們輕噴~
- 前置知識
偏倉:在倉庫存在全國各個倉分布不均衡,是否均衡的判斷標準是該倉覆蓋范圍內潛在的購買量和倉庫已有庫存量是否匹配
調撥:將貨物從A倉集中搬運到B倉
發貨:從倉庫出庫+運輸+末端派送至消費者
跨區發貨:消費者所在區域的倉缺貨需要換倉從其他大區的倉發貨給消費者
- 業務分析
-
當在倉庫存偏倉的時候,會造成跨區發貨,跨區發貨的快遞成本比非跨區發貨高
-
如果能提前通過集中調撥的方式將貨物配平(即批量的將貨物先配送到用戶所在的地區的倉),且滿足:單件集中調撥成本+單件發貨成本 < 單件跨區發貨成本
-
倉庫的出庫能力、收貨能力、干線運輸能力有上限限制
-
調出倉需要優先滿足本倉覆蓋范圍內的潛在消費者
- 建模
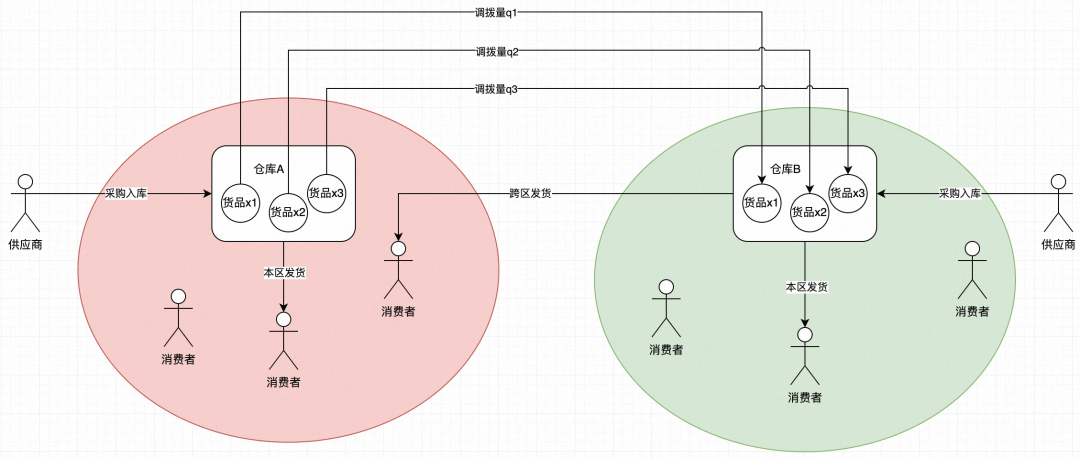
業務目標:我們要最小化貨物從倉庫到消費者手中的物流成本
成本函數:發貨成本
- 假設有N個貨品貨品
- 調出倉A
- 調入倉B
- 約束1:對任意一個貨品,從A倉調出量小于A倉庫存-A倉自身需求量,即,其中表示貨品從A倉的調出至B倉的量。表示貨品在A倉的庫存,在倉庫A覆蓋范圍內的預計售賣量表示貨品
- 約束2:對任意一個貨品,調入B倉的量小于B倉覆蓋范圍內的預計售賣量-B倉已有的在倉庫存,即,字符含義同上。
-
約束3:一次調撥的量,要小于A倉到B倉的干線運輸能力,即
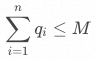
,其中是一個常量,表示最大的干線運輸能力
- 目標函數: 其中是個常量,表示貨品通過跨區發貨到消費者手中的發貨成本,是個常量,表示貨品從A倉調撥到B倉的調撥成本,表示提前將貨品從A倉調撥到B倉,避免跨區發貨而節省的成本。因此,我們要「最小化貨物從倉庫到消費者手中的物流成本」,即,最大化節省的金額。
宗上所述,模型定義如下:
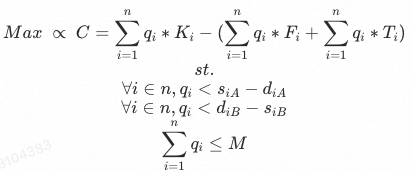
到這里,整個建模過程就結束了。實際上我們忽略了很多細節,但是并不影響我們理解這個調撥模型。至于模型怎么求得每一個調撥量以保證最大化收益,就要對這個模型進行求解了。
?模型求解:怎么才能算出目標函數最優時的參數解
- 明確求解目標
既然要求解,我們就要明確到底要求解什么?即,在上面定義的數學模型中要明確哪些是常量哪些是變量。
很明顯,我們需要求解的變量是,即每個貨品需要從A倉調撥多少件到B倉。這里為了方便解釋,我們就假設一共就兩個貨品,相應的我們需要求解的變量就。
- 求解算法
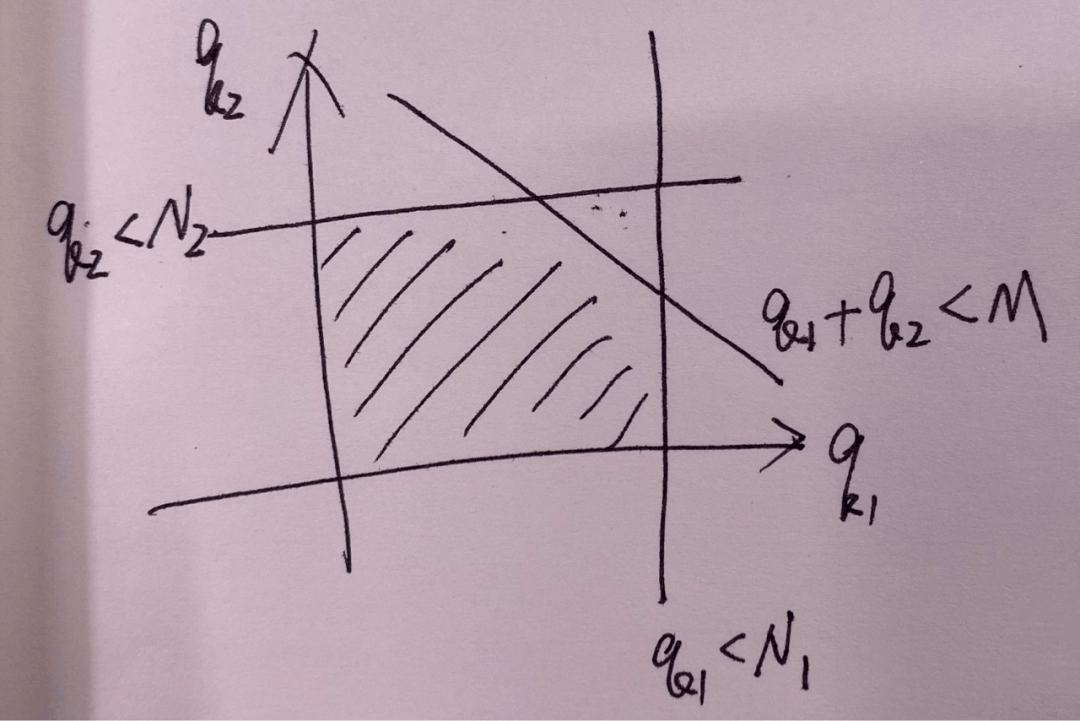
根據約束條件看,解空間就在坐標軸圈定的陰影范圍內。實際上,最簡單的求解方法就是暴力枚舉所有可能的結果,然后求出函數值最大時對應的參數即可。
當然了,現實的問題中求解的參數量一定是遠遠大于2個的,因此參數求解的時間復雜度呈指數級上升,以當前的算力,可能直到生命的盡頭可能都得不到答案。生命是寶貴的,對于這種問題,有沒有快速的解法呢?有,這里我們就要引出一個算法概念——啟發式搜索算法,這是一種算法理念的統稱,具體的實現有很多種,比如模擬退火算法、遺傳算法、蟻群算法等。宗旨就是在有限的時間內,得到一個近似的最優解。
這里以遺傳算法為例,我們來學習它的求解過程:
遺傳算法(G.NETic Algorithm)遵循『適者生存』、『優勝劣汰』的原則,是一類借鑒生物界自然選擇和自然遺傳機制的隨機化搜索算法。遺傳算法模擬一個人工種群的進化過程,通過選擇(Selection)、交叉(Crossover)以及變異(Mutation)等機制,在每次迭代中都保留一組候選個體,重復此過程,種群經過若干代進化后,理想情況下其適應度達到近似最優的狀態。算法具體邏輯可參考:https://zhuanlan.zhihu.com/p/460368294這類算法不僅很有效,而且是可理解可證明的。記得多年前,第一次接觸到這種算法類型的時候,深深地感受到了前人的智慧。
在實際應用中,我們可以使用一些現成的算法求解器,例如cplex。至此,通過問題定義、建模、求解。調撥模型中,從A倉到底要調撥多少量到B倉才能節省更多的成本的問題就解決了。

展望
面對一個需要優化的業務問題,傳統的思路是從問題定義、建模再到求解。而深度學習模型的思路是:
-
向量化:無論什么類型的數據,文字、圖片、視頻、聲音,首先是將數據向量化,比如文字可以使用word2vec轉換成一串01向量。
-
將訓練數據的目標結果也向量化:一般來說輸入的數據和目標結果是同一種數據類型,也可以不一樣。
-
選定目標函數:一般來說目標函數針對不同的任務類型有其固定的目標函數。比如常見的RMSE、Cross-Entropy、Categorical-Cross-Entropy等等。
-
訓練模型:將模型輸出的結果向量與目標結果向量代入目標函數,計算loss。同時計算梯度值,調整模型參數。直到在訓練集上的loss足夠小或者每次迭代的loss不再變低為止,訓練結束。
可以理解為,無論什么問題只要將數據向量化,就可以通過深度學習模型求解。其中建模的過程可以省略,模型求解也是固定的范式。然后問題就解決了,我對這種神經網絡模型也大為震撼。
人類的很多發明創造,都是從自然中學來的。比如機翼模仿的是鳥的翅膀,讓上下兩側的氣流速度不一樣來形成向上的氣壓差;疏水材料模仿的是荷葉表面紋理仿制的。前面提到的啟發式搜索算法,也是對自然界動植物等的模擬衍生出來的算法,原來很多問題在沒有數學的時候,就能夠通過生物本能的解決這個問題。同理,現在的深度學習模型,大家都說這是對人腦神經元與神經突觸的模擬,同樣的,我們接觸的聲音、視覺畫面、文字等等都是通通轉換成電信號,經過重重神經元之后,變成了我們可以理解的一個個具象的東西——一首歌、一部電影、一只小狗...... 神經網絡模型跟這確實也有異曲同工之妙。
所以我并不覺得神經網絡模型不對,只是我們對模仿的本體——大腦的科學認知都不夠,那么通過模仿出來的神經網絡模型讓人更加不可理解,不可證明、也不可證偽。或許,現在所謂的神經網絡模型壓根就是錯誤的?或許等我們的腦科學有更大進步的時候,會有一種全新的能夠科學證明的神經網絡模型出現?
現在很多人把深度學習當做一個框,什么都往里裝,以為深度學習就是萬能解藥,特別是一些神奇的大V發的文章,看多了總歸有些不適。我們現在使用大模型的過程,就像三體里的火雞科學家一樣,在黑夜中不斷摸索規律。至于這個規律是真理還是深坑,不得而知。大模型能發展到什么地步,那就要看后人的智慧了。

團隊介紹
我們是大淘寶技術-品牌供給技術部,目前主要負責消費電子、家裝家居、天貓優品等行業的供應鏈業務。團隊致力于解決采購、調撥、倉儲、履約等多環節的業務優化問題,為平臺商家和集團自營業務提供極致的供應鏈體驗。將仿真優化、運籌學、機器學習和智能AI算法與實際業務場景相結合,為供應鏈降本提效、提升消費者物流體驗提供一站式解決方案。





