
近年來,基于擴散模型(Diffusion Models)的圖像生成模型層出不窮,展現出令人驚艷的生成效果。然而,現有相關研究模型代碼框架存在過度碎片化的問題,缺乏統一的框架體系,導致出現「遷移難」、「門檻高」、「質量差」的代碼實現難題。
為此,中山大學人機物智能融合實驗室(HCP Lab)構建了 HCP-Diffusion 框架,系統化地實現了模型微調、個性化訓練、推理優化、圖像編輯等基于 Diffusion 模型的相關算法,結構如圖 1 所示。
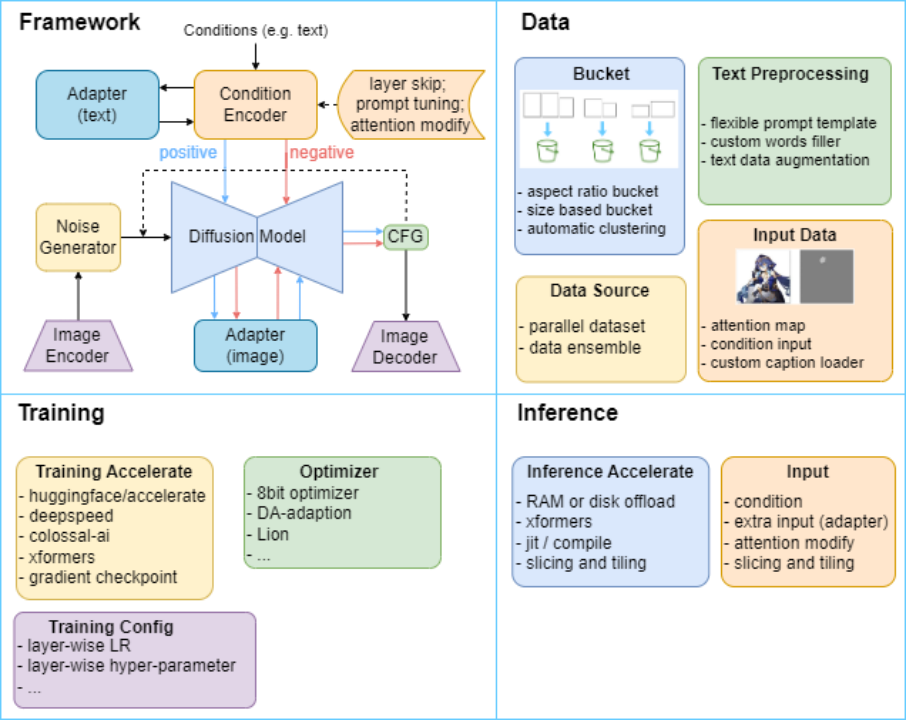
圖 1 HCP-Diffusion 框架結構圖,通過統一框架統一現有 diffusion 相關方法,提供多種模塊化的訓練與推理優化方法。
HCP-Diffusion 通過格式統一的配置文件調配各個組件和算法,大幅提高了框架的靈活性和可擴展性。開發者像搭積木一樣組合算法,而無需重復實現代碼細節。
比如,基于 HCP-Diffusion,我們可以通過簡單地修改配置文件即可完成 LoRA,DreamArtist,Contro.NET 等多種常見算法的部署與組合。這不僅降低了創新的門檻,也使得框架可以兼容各類定制化設計。
HCP-Diffusion 代碼工具:https://Github.com/7eu7d7/HCP-Diffusion
HCP-Diffusion 圖形界面:https://github.com/7eu7d7/HCP-Diffusion-webui
HCP-Diffusion:功能模塊介紹
框架特色
HCP-Diffusion 通過將目前主流的 diffusion 訓練算法框架模塊化,實現了框架的通用性,主要特色如下:
統一架構:搭建 Diffusion 系列模型統一代碼框架
算子插件:支持數據、訓練、推理、性能優化等算子算法,如 deepspeed, colossal-AI 和 offload 等加速優化
一鍵配置:Diffusion 系列模型可通過高靈活度地修改配置文件即可完成模型實現
一鍵訓練:提供 Web UI,一鍵訓練、推理
數據模塊
HCP-Diffusion 支持定義多個并行數據集,每個數據集可采用不同的圖像尺寸與標注格式,每次訓練迭代會從每個數據集中各抽取一個 batch 進行訓練,如圖 2 所示。此外,每個數據集可配置多種數據源,支持 txt、json、yaml 等標注格式或自定義標注格式,具有高度靈活的數據預處理與加載機制。
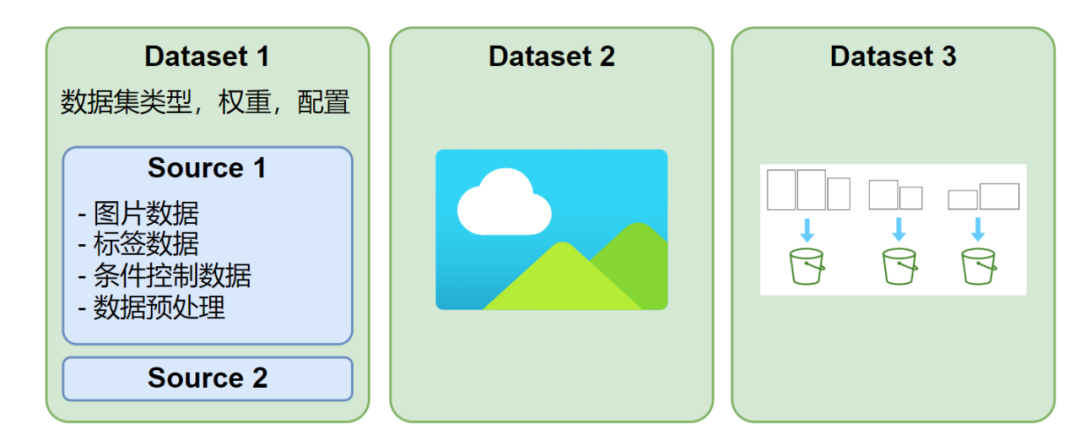 圖 2 數據集結構示意圖
圖 2 數據集結構示意圖
數據集處理部分提供帶自動聚類的 aspect ratio bucket,支持處理圖像尺寸各異的數據集。用戶無需對數據集尺寸做額外處理和對齊,框架會根據寬高比或分辨率自動選擇最優的分組方式。該技術大幅降低數據處理的門檻,優化用戶體驗,使開發者更專注于算法本身的創新。
而對于圖像數據的預處理,框架也兼容 torch vision, albumentations 等多種圖像處理庫。用戶可以根據需要在配置文件中直接配置預處理方式,或是在此基礎上拓展自定義的圖像處理方法。
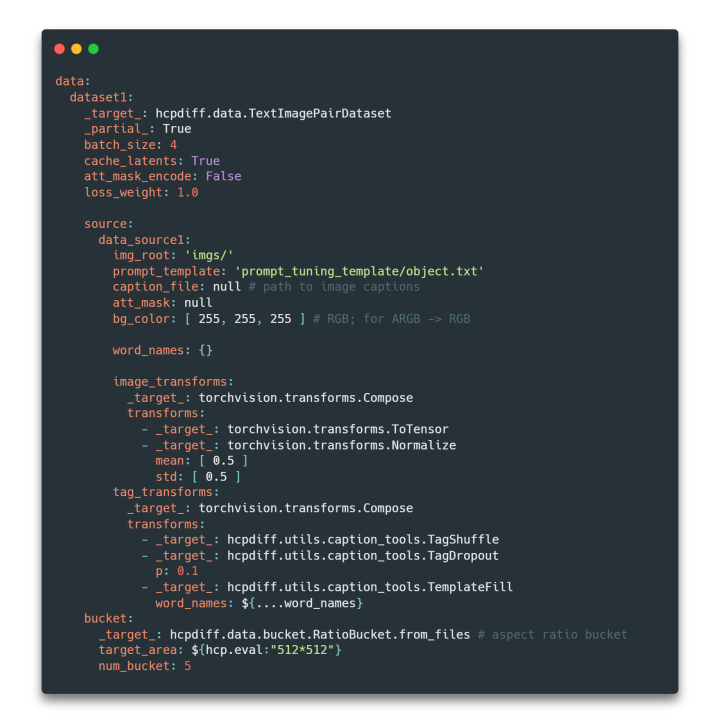
HCP-Diffusion 在文本標注方面,設計了靈活且清晰的 prompt 模板規范,可支持復雜多樣的訓練方法與數據標注。其對應用上述配置文件 source 目錄下的 word_names,里面可自定義下圖大括號中的特殊字符對應的嵌入詞向量與類別描述,以與 DreamBooth、DreamArtist 等模型兼容。

并且對于文本標注,也提供了按句擦除 (TagDropout) 或按句打亂 (TagShuffle) 等多種文本增強方法,可以減少圖像與文本數據間的過擬合問題,使生成的圖像更多樣化。
模型框架模塊
HCP-Diffusion 通過將目前主流的 diffusion 訓練算法框架模塊化,實現了框架的通用性。具體而言,Image Encoder,Image Decoder 完成圖像的編解碼,Noise Generator 產生前向過程的噪聲,Diffusion Model 實現擴散過程,Condition Encoder 對生成條件進行編碼,Adapter 微調模型與下游任務對齊,positive 與 negative 雙通道代表正負條件對圖像的控制生成。

如圖 5 所示,HCP-Diffusion 在配置文件中通過簡易的組合,即可實現 LoRA、ControlNet、DreamArtist 等多種主流訓練算法。同時支持對上述算法進行組合,例如 LoRA 和 Textual Inversion 同時訓練,為 LoRA 綁定專有觸發詞等。此外,通過插件模塊,可以輕松自定義任意插件,業已兼容目前所有主流方法接入。通過上述的模塊化,HCP-Diffusion 實現了對任意主流算法的框架搭建,降低了開發門檻,促進了模型的協同創新。
HCP-Diffusion 將 LoRA、ControlNet 等各種 Adapter 類算法統一抽象為模型插件,通過定義一些通用的模型插件基類,可以將所有這類算法統一對待,降低用戶使用成本和開發成本,將所有 Adapter 類算法統一。
框架提供四種類型的插件,可以輕松支持目前所有主流算法:
+ SinglePluginBlock: 單層插件,根據該層輸入改變輸出,比如 lora 系列。支持正則表達式 (re: 前綴) 定義插入層, 不支持 pre_hook: 前綴。
+ PluginBlock: 輸入層和輸出層都只有一個,比如定義殘差連接。支持正則表達式 (re: 前綴) 定義插入層, 輸入輸出層都支持 pre_hook: 前綴。
+ MultiPluginBlock: 輸入層和輸出層都可以有多個,比如 controlnet。不支持正則表達式 (re: 前綴), 輸入輸出層都支持 pre_hook: 前綴。
+ WrAppluginBlock: 替換原有模型的某個層,將原有模型的層作為該類的一個對象。支持正則表達式 (re: 前綴) 定義替換層,不支持 pre_hook: 前綴。
訓練、推理模塊
 圖 6 自定義優化器配置
圖 6 自定義優化器配置
HCP-Diffusion 中的配置文件支持定義 Python/ target=_blank class=infotextkey>Python 對象,運行時自動實例化。該設計使得開發者可以輕松接入任何 pip 可安裝的自定義模塊,例如自定義優化器,損失函數,噪聲采樣器等,無需修改框架代碼,如上圖所示。配置文件結構清晰,易于理解,可復現性強,有助于平滑連接學術研究和工程部署。
加速優化支持
HCP-Diffusion 支持 Accelerate、DeepSpeed、Colossal-AI 等多種訓練優化框架,可以顯著減少訓練時的顯存占用,加快訓練速度。支持 EMA 操作,可以進一步提高模型的生成效果和泛化性。在推理階段,支持模型 offload 和 VAE tiling 等操作,最低僅需 1GB 顯存即可完成圖像生成。

通過上述簡單的文件配置,即可無需耗費大量精力查找相關框架資源完成模型的配置,如上圖所示。HCP-Diffusion 模塊化的設計方式,將模型方法定義,訓練邏輯,推理邏輯等完全分離,配置模型時無需考慮訓練與推理部分的邏輯,幫助用戶更好的聚焦于方法本身。同時,HCP-Diffusion 已經提供大多數主流算法的框架配置樣例,只需對其中部分參數進行修改,就可以實現部署。
HCP-Diffusion:Web UI 圖像界面
除了可直接修改配置文件,HCP-Diffusion 已提供了對應的 Web UI 圖像界面,包含圖像生成,模型訓練等多個模塊,以提升用戶體驗,大幅降低框架的學習門檻,加速算法從理論到實踐的轉化。
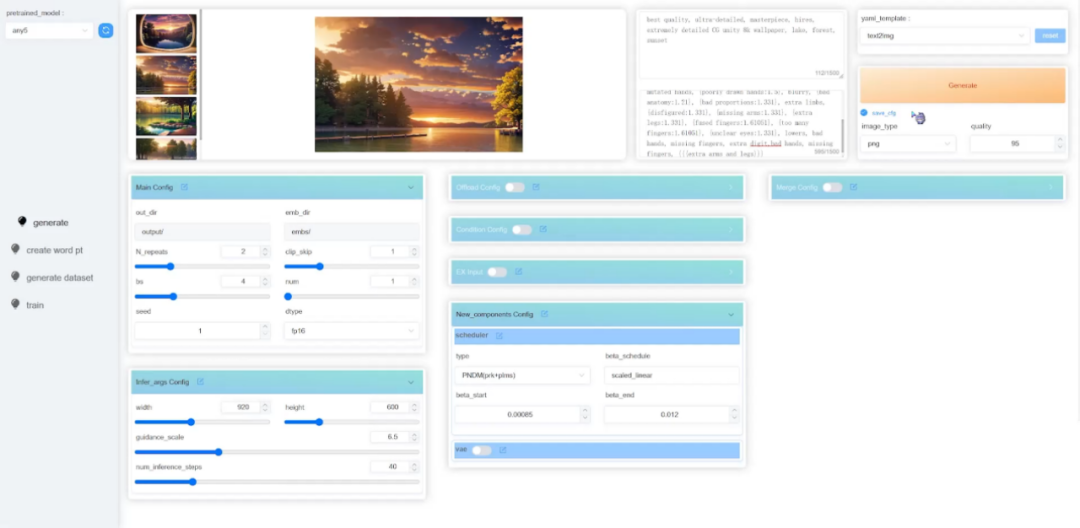 圖 8 HCP-Diffusion Web UI 圖像界面
圖 8 HCP-Diffusion Web UI 圖像界面
實驗室簡介
中山大學人機物智能融合實驗室 (HCP Lab) 由林倞教授于 2010 年創辦,近年來在多模態內容理解、因果及認知推理、具身學習等方面取得豐富學術成果,數次獲得國內外科技獎項及最佳論文獎,并致力于打造產品級的AI技術及平臺。實驗室網站:http://www.sysu-hcp.net





