擊這里在線咨詢客服")
都2023年,才來(lái)回答這個(gè)問(wèn)題,自然毫無(wú)懸念地選擇PyTorch,TensorFlow在大模型這一波浪潮中沒(méi)有起死回生,有點(diǎn)惋惜,現(xiàn)在GLM、GPT、LLaMA等各種大模型都是基于PyTorch框架構(gòu)建。這個(gè)事情已經(jīng)水落石出。
不過(guò)呢,我覺(jué)得可以一起去回顧下,在AI框架發(fā)展的過(guò)程中,都沉陷了哪些技術(shù)點(diǎn),為什么一開(kāi)始這么多人在糾結(jié)到底用哪個(gè)框架。
在前面的內(nèi)容主要是講述了AI框架在數(shù)學(xué)上對(duì)自動(dòng)微分進(jìn)行表達(dá)和處理,最后表示稱為開(kāi)發(fā)者和應(yīng)用程序都能很好地去編寫深度學(xué)習(xí)中神經(jīng)網(wǎng)絡(luò)的工具和庫(kù),整體流程如下所示:

除了要回答最核心的數(shù)學(xué)表示原理意外,實(shí)際上AI框架還要思考和解決許多問(wèn)題,如AI框架如何對(duì)實(shí)際的神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)多線程算子加速?如何讓程序執(zhí)行在GPU/NPU上?如何編譯和優(yōu)化開(kāi)發(fā)者編寫的代碼?因此,一個(gè)能夠商用版本的AI框架,需要系統(tǒng)性梳理每一層中遇到的具體問(wèn)題,以便提供相關(guān)更好的開(kāi)發(fā)特性:
前端(面向用戶):如何靈活的表達(dá)一個(gè)深度學(xué)習(xí)模型?
算子(執(zhí)行計(jì)算):如何保證每個(gè)算子的執(zhí)行性能和泛化性?
微分(更新參數(shù)):如何自動(dòng)、高效地提供求導(dǎo)運(yùn)算?
后端(系統(tǒng)相關(guān)):如何將同一個(gè)算子跑在不同的加速設(shè)備上?
運(yùn)行時(shí):如何自動(dòng)地優(yōu)化和調(diào)度網(wǎng)絡(luò)模型進(jìn)行計(jì)算?
本節(jié)內(nèi)容將會(huì)去總結(jié)AI框架的目的,其要求解決的技術(shù)問(wèn)題和數(shù)學(xué)問(wèn)題;了解了其目的后,真正地去根據(jù)時(shí)間的維度和和技術(shù)的維度梳理AI框架的發(fā)展脈絡(luò),并對(duì)AI框架的未來(lái)進(jìn)行思考。
AI框架的目的
神經(jīng)網(wǎng)絡(luò)是機(jī)器學(xué)習(xí)技術(shù)中一類具體算法分枝,通過(guò)堆疊基本處理單元形成寬度和深度,構(gòu)建出一個(gè)帶拓?fù)浣Y(jié)構(gòu)的高度復(fù)雜的非凸函數(shù),對(duì)蘊(yùn)含在各類數(shù)據(jù)分布中的統(tǒng)計(jì)規(guī)律進(jìn)行擬合。傳統(tǒng)機(jī)器學(xué)習(xí)方法在面對(duì)不同應(yīng)用時(shí),為了達(dá)到所需的學(xué)習(xí)效果往往需要重新選擇函數(shù)空間設(shè)計(jì)新的學(xué)習(xí)目標(biāo)。
相比之下,神經(jīng)網(wǎng)絡(luò)方法能夠通過(guò)調(diào)節(jié)構(gòu)成網(wǎng)絡(luò)使用的處理單元,處理單元之間的堆疊方式,以及網(wǎng)絡(luò)的學(xué)習(xí)算法,用一種較為統(tǒng)一的算法設(shè)計(jì)視角解決各類應(yīng)用任務(wù),很大程度上減輕了機(jī)器學(xué)習(xí)算法設(shè)計(jì)的選擇困難。同時(shí),神經(jīng)網(wǎng)絡(luò)能夠擬合海量數(shù)據(jù),深度學(xué)習(xí)方法在圖像分類,語(yǔ)音識(shí)別以及自然語(yǔ)言處理任務(wù)中取得的突破性進(jìn)展,揭示了構(gòu)建更大規(guī)模的神經(jīng)網(wǎng)絡(luò)對(duì)大規(guī)模數(shù)據(jù)進(jìn)行學(xué)習(xí),是一種有效的學(xué)習(xí)策略。
然而,深度神經(jīng)網(wǎng)絡(luò)應(yīng)用的開(kāi)發(fā)需要對(duì)軟件棧的各個(gè)抽象層進(jìn)行編程,這對(duì)新算法的開(kāi)發(fā)效率和算力都提出了很高的要求,進(jìn)而催生了 AI 框架的發(fā)展。AI框架可以讓開(kāi)發(fā)者更加專注于應(yīng)用程序的業(yè)務(wù)邏輯,而不需要關(guān)注底層的數(shù)學(xué)和計(jì)算細(xì)節(jié)。同時(shí)AI框架通常還提供可視化的界面,使得開(kāi)發(fā)者可以更加方便地設(shè)計(jì)、訓(xùn)練和優(yōu)化自己的模型。在AI框架之上,還會(huì)提供了一些預(yù)訓(xùn)練的網(wǎng)絡(luò)模型,可以直接用于一些常見(jiàn)的應(yīng)用場(chǎng)景,例如圖像識(shí)別、語(yǔ)音識(shí)別和自然語(yǔ)言處理等。
AI 框架的目的是為了在計(jì)算加速硬件(GPU/NPU)和AI集群上高效訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)而設(shè)計(jì)的可編程系統(tǒng),需要同時(shí)兼顧以下互相制約設(shè)計(jì)目標(biāo)可編程性與性能。
1.提供靈活的編程模型和編程接口
自動(dòng)推導(dǎo)計(jì)算圖:根據(jù)客戶編寫的神經(jīng)網(wǎng)絡(luò)模型和對(duì)應(yīng)的代碼,構(gòu)建自動(dòng)微分功能,并轉(zhuǎn)換為計(jì)算機(jī)可以識(shí)別和執(zhí)行的計(jì)算圖。
較好的支持與現(xiàn)有生態(tài)融合:AI應(yīng)用層出不窮,需要提供良好的編程環(huán)境和編程體系給開(kāi)發(fā)者方便接入,這里以PyTorch框架為例對(duì)外提供超過(guò)2000+ API。
提供直觀的模型構(gòu)建方式,簡(jiǎn)潔的神經(jīng)網(wǎng)絡(luò)計(jì)算編程語(yǔ)言:使用易用的編程接口,用高層次語(yǔ)義描述出各類主流深度學(xué)習(xí)模型和訓(xùn)練算法。而在編程范式主要是以聲明式編程和命令式編程為主,提供豐富的編程方式,能夠有效提提升開(kāi)發(fā)者開(kāi)發(fā)效率,從而提升AI框架的易用性。
2.提供高效和可擴(kuò)展的計(jì)算能力
自動(dòng)編譯優(yōu)化算法:為可復(fù)用的處理單元提供高效實(shí)現(xiàn),使得AI算法在真正訓(xùn)練或者推理過(guò)程中,執(zhí)行得更快,需要對(duì)計(jì)算圖進(jìn)行進(jìn)一步的優(yōu)化,如子表達(dá)式消除、內(nèi)核融合、內(nèi)存優(yōu)化等算法,支持多設(shè)備、分布式計(jì)算等。
根據(jù)不同體系結(jié)構(gòu)和硬件設(shè)備自動(dòng)并行化:體系結(jié)構(gòu)的差異主要是指針對(duì) GPU、NPU、TPU等AI加速硬件的實(shí)現(xiàn)不同,有必要進(jìn)行深度優(yōu)化,而面對(duì)大模型、大規(guī)模分布式的沖擊需要對(duì)自動(dòng)分布式化、擴(kuò)展多計(jì)算節(jié)點(diǎn)等進(jìn)行性能提升。
降低新模型的開(kāi)發(fā)成本:在添加新計(jì)算加速硬件(GPU/NPU)支持時(shí),降低增加計(jì)算原語(yǔ)和進(jìn)行計(jì)算優(yōu)化的開(kāi)發(fā)成本。
AI框架的發(fā)展
AI 框架作為智能經(jīng)濟(jì)時(shí)代的中樞,是 AI 開(kāi)發(fā)環(huán)節(jié)中的基礎(chǔ)工具,承擔(dān)著 AI 技術(shù)生態(tài)中操作系統(tǒng)的角色,是 AI 學(xué)術(shù)創(chuàng)新與產(chǎn)業(yè)商業(yè)化的重要載體,助力 AI 由理論走入實(shí)踐,快速進(jìn)入了場(chǎng)景化應(yīng)用時(shí)代,也是發(fā)展 AI 所必需的基礎(chǔ)設(shè)施之一。隨著重要性的不斷凸顯,AI 框架已經(jīng)成為了 AI 產(chǎn)業(yè)創(chuàng)新的焦點(diǎn)之一,引起了學(xué)術(shù)界、產(chǎn)業(yè)界的重視。
時(shí)間維度
結(jié)合 AI 的發(fā)展歷程,AI 框架在時(shí)間維度的發(fā)展大致可以分為四個(gè)階段,分別為1)2000 年初期的萌芽階段、2)2012~2014年的成長(zhǎng)階段、3)2015 年~2019 年的爆發(fā)階段,和4)2020 年以后深化階段。
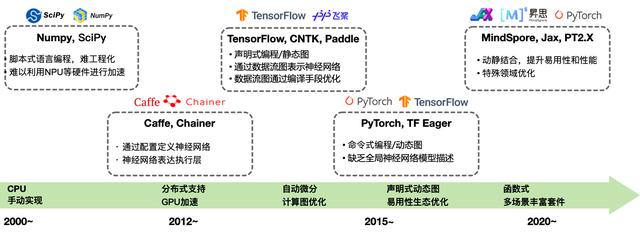
其在時(shí)間的發(fā)展脈絡(luò)與 AI ,特別是深度學(xué)習(xí)范式下的神經(jīng)網(wǎng)絡(luò)技術(shù)的異峰突起有非常緊密的聯(lián)系。
萌芽階段
在2020年前,早期受限于計(jì)算能力不足,萌芽階段神經(jīng)網(wǎng)絡(luò)技術(shù)影響力相對(duì)有限,因而出現(xiàn)了一些傳統(tǒng)的機(jī)器學(xué)習(xí)工具來(lái)提供基本支持,也就是 AI 框架的雛形,但這些工具或者不是專門為神經(jīng)網(wǎng)絡(luò)模型開(kāi)發(fā)定制的,或者 API 極其復(fù)雜對(duì)開(kāi)發(fā)者并不友好,且并沒(méi)有對(duì)異構(gòu)加速算力(如GPU/NPU等)進(jìn)行支持。缺點(diǎn)在于萌芽階段的 AI 框架并不完善,開(kāi)發(fā)者需要編寫大量基礎(chǔ)的工作,例如手寫反向傳播、搭建網(wǎng)絡(luò)結(jié)構(gòu)、自行設(shè)計(jì)優(yōu)化器等。
其以 Matlab 的神經(jīng)網(wǎng)絡(luò)庫(kù)為代表作品。

成長(zhǎng)階段
2012 年,Alex Krizhevsky 等人提出了 Ale.NET 一種深度神經(jīng)網(wǎng)絡(luò)架構(gòu),在 ImageNet 數(shù)據(jù)集上達(dá)到了最佳精度,并碾壓第二名提升15%以上的準(zhǔn)確率,引爆了深度神經(jīng)網(wǎng)絡(luò)的熱潮。
自此極大地推動(dòng)了 AI 框架的發(fā)展,出現(xiàn)了 Caffe、Chainer 和 Theano 等具有代表性的早期 AI 框架,幫助開(kāi)發(fā)者方便地建立復(fù)雜的深度神經(jīng)網(wǎng)絡(luò)模型(如 CNN、RNN、LSTM 等)。不僅如此,這些框架還支持多 GPU 訓(xùn)練,讓開(kāi)展更大、更深的模型訓(xùn)練成為可能。在這一階段,AI 框架體系已經(jīng)初步形成,聲明式編程和命令式編程為下一階段的 AI 框架發(fā)展的兩條截然不同的道路做了鋪墊。
爆發(fā)階段
2015 年,何愷明等人提出的 ResNet,再次突破了圖像分類的邊界,在 ImageNet 數(shù)據(jù)集上的準(zhǔn)確率再創(chuàng)新高,也凝聚了產(chǎn)業(yè)界和學(xué)界的共識(shí),即深度學(xué)習(xí)將成為下一個(gè)重大技術(shù)趨勢(shì)。
2016年 google 開(kāi)源了 TensorFlow 框架,F(xiàn)acebook AI 研究團(tuán)隊(duì)也發(fā)布了基于動(dòng)態(tài)圖的AI框架 PyTorch,該框架拓展自 Torch 框架,但使用了更流行的 Python/ target=_blank class=infotextkey>Python 進(jìn)行重構(gòu)整體對(duì)外 API。Caffe 的發(fā)明者加入了 Facebook(現(xiàn)更名為 Meta)并發(fā)布了 Caffe2 并融入了 PyTorch 的推理生態(tài);與此同時(shí),微軟研究院開(kāi)發(fā)了 CNTK 框架。Amazon 采用了這是華盛頓大學(xué)、CMU 和其他機(jī)構(gòu)的聯(lián)合學(xué)術(shù)項(xiàng)目 MXNet。國(guó)內(nèi)百度則率先布局了 PaddlePaddle 飛槳AI框架并于 2016 年發(fā)布。
在 AI 框架的爆發(fā)階段,AI系統(tǒng)也迎來(lái)了繁榮,而在不斷發(fā)展的基礎(chǔ)上,各種框架不斷迭代,也被開(kāi)發(fā)者自然選擇。經(jīng)過(guò)激烈的競(jìng)爭(zhēng)后,最終形成了兩大陣營(yíng),TensorFlow 和 PyTorch 雙頭壟斷。2019 年,Chainer 團(tuán)隊(duì)將他們的開(kāi)發(fā)工作轉(zhuǎn)移到 PyTorch,Microsoft 停止了 CNTK 框架的積極開(kāi)發(fā),部分團(tuán)隊(duì)成員轉(zhuǎn)而支持 PyTorch;Keras 被 TensorFlow 收編,并在 TensorFlow2.X 版本中成為其高級(jí) API 之一。

深化階段
隨著 AI 的進(jìn)一步發(fā)展,AI 應(yīng)用場(chǎng)景的擴(kuò)展以及與更多領(lǐng)域交叉融合進(jìn)程的加快,新的趨勢(shì)不斷涌現(xiàn),越來(lái)越多的需求被提出。
例如超大規(guī)模模型的出現(xiàn)(GPT-3、ChatGPT等),新的趨勢(shì)給 AI 框架提出了更高的要求。例如超大規(guī)模模型的出現(xiàn)(GPT-3、ChatGPT等);如對(duì)全場(chǎng)景多任務(wù)的支持、對(duì)異構(gòu)算力支持等。這就要求 AI 框架最大化的實(shí)現(xiàn)編譯優(yōu)化,更好地利用算力、調(diào)動(dòng)算力,充分發(fā)揮集群硬件資源的潛力。此外,AI 與社會(huì)倫理的痛點(diǎn)問(wèn)題也促使可信賴 AI 、或則 AI 安全在 AI 框架層面的進(jìn)步。
基于以上背景,現(xiàn)有的主流 AI 框架都在探索下一代 AI 框架的發(fā)展方向,如 2020 年華為推出昇思 MindSpore,在全場(chǎng)景協(xié)同、可信賴方 面有一定的突破;曠視推出天元 MegEngine,在訓(xùn)練推理一體化方面深度布局;PyTorch 捐贈(zèng)給 linux 基金會(huì),并面向圖模式提出了新的架構(gòu)和新的版本 PyTorch2.X。
在這一階段,AI 框架正向著全場(chǎng)景支持、大模型、分布式AI、 超大規(guī)模 AI、安全可信 AI 等技術(shù)特性深化探索,不斷實(shí)現(xiàn)新的突破。
技術(shù)維度
以技術(shù)維度的角度去對(duì) AI 框架進(jìn)行劃分,其主要經(jīng)歷了三代架構(gòu),其與深度學(xué)習(xí)范式下的神經(jīng)網(wǎng)絡(luò)技術(shù)發(fā)展和編程語(yǔ)言、及其編程體系的發(fā)展有著緊密的關(guān)聯(lián)。

第一代AI框架
第一代 AI 框架在時(shí)間上主要是在 2010 年前,面向需要解決問(wèn)題有:1)機(jī)器學(xué)習(xí) ML 中缺乏統(tǒng)一的算法庫(kù),2)提供穩(wěn)定和統(tǒng)一的神經(jīng)網(wǎng)絡(luò) NN 定義。其對(duì)應(yīng)的AI框架框架其實(shí)廣義上并不能稱為 AI 框架,更多的是對(duì)機(jī)器學(xué)習(xí)中的算法進(jìn)行了統(tǒng)一的封裝,并在一定程度上提供了少量的神經(jīng)網(wǎng)絡(luò)模型算法和API的定義。具體形態(tài)有2種:
第一種的主要特點(diǎn)的是以庫(kù)(Library)的方式對(duì)外提供腳本式編程,方便開(kāi)發(fā)者通過(guò)簡(jiǎn)單配置的形式定義神經(jīng)網(wǎng)絡(luò),并且針對(duì)特殊的機(jī)器學(xué)習(xí) ML、神經(jīng)網(wǎng)絡(luò)NN算法提供接口,其比較具有代表性意義的是 MATLAB 和 SciPy。另外還有針對(duì)矩陣計(jì)算提供特定的計(jì)算接口的 NumPy。優(yōu)點(diǎn)是:面向 AI 領(lǐng)域提供了一定程度的可編程性;支持CPU加速計(jì)算。
第二種的在編程方面,以CNN網(wǎng)絡(luò)模型為主,由常用的layers組成,如:Convolution, Pooling, BatchNorm, Activation等,都是以Layer Base為驅(qū)動(dòng),可以通過(guò)簡(jiǎn)單配置文件的形式定義神經(jīng)網(wǎng)絡(luò)。模型可由一些常用layer構(gòu)成一個(gè)簡(jiǎn)單的圖,AI 框架提供每一個(gè)layer及其梯度計(jì)算實(shí)現(xiàn)。這方面具有代表性的作品是 Torch、Theano 等AI框架。其優(yōu)點(diǎn)是提供了一定程度的可編程性,計(jì)算性能有一定的提升,部分支持 GPU/NPU 加速計(jì)算。
同時(shí),第一代 AI 框架的缺點(diǎn)也比較明顯,主要集中在1)靈活性和2)面向新場(chǎng)景支持不足。
首先是易用性的限制難以滿足深度學(xué)習(xí)的快速發(fā)展,主要是層出不窮的新型網(wǎng)絡(luò)結(jié)構(gòu),新的網(wǎng)絡(luò)層需要重新實(shí)現(xiàn)前向和后向計(jì)算;其次是第一代 AI 框架大部分使用非高級(jí)語(yǔ)言實(shí)現(xiàn),修改和定制化成本較高,對(duì)開(kāi)發(fā)者不友好。最后是新優(yōu)化器要求對(duì)梯度和參數(shù)進(jìn)行更通用復(fù)雜的運(yùn)算。
隨著生成對(duì)抗網(wǎng)絡(luò)模型 GAN、深度強(qiáng)化學(xué)習(xí) DRL、Stable Diffusion 等新的結(jié)構(gòu)出現(xiàn),基于簡(jiǎn)單的“前向+后向”的訓(xùn)練模式難以滿足新的訓(xùn)練模式。例如循環(huán)神經(jīng)網(wǎng)絡(luò) LSTM 需要引入控制流、對(duì)抗神經(jīng)網(wǎng)絡(luò) GAN 需要兩個(gè)網(wǎng)絡(luò)交替訓(xùn)練,強(qiáng)化學(xué)習(xí)模型 RL 需要和外部環(huán)境進(jìn)行交互等眾多場(chǎng)景沒(méi)辦法滿足新涌現(xiàn)的場(chǎng)景。

第二代AI框架
第二代AI框架在技術(shù)上,統(tǒng)一稱為基于數(shù)據(jù)流圖(DAG)的計(jì)算框架:將復(fù)雜的神經(jīng)網(wǎng)絡(luò)模型,根據(jù)數(shù)據(jù)流拆解為若干處理環(huán)節(jié),構(gòu)建數(shù)據(jù)流圖,數(shù)據(jù)流圖中的處理環(huán)節(jié)相互獨(dú)立,支持混合編排控制流與計(jì)算,以任務(wù)流為最終導(dǎo)向,AI 框架將數(shù)據(jù)流圖轉(zhuǎn)換為計(jì)算機(jī)可以執(zhí)行或者識(shí)別的任務(wù)流圖,通過(guò)執(zhí)行引擎(Runtime)解析任務(wù)流進(jìn)行處理環(huán)節(jié)的分發(fā)調(diào)度、監(jiān)控與結(jié)果回傳,最終實(shí)現(xiàn)神經(jīng)網(wǎng)絡(luò)模型的構(gòu)建與運(yùn)行。
以數(shù)據(jù)流圖描述深度神經(jīng)網(wǎng)絡(luò),前期實(shí)踐最終催生出了工業(yè)級(jí) AI 框架,如TensorFlow 和PyTorch,這一時(shí)期同時(shí)伴隨著如Chainer,DyNet等激發(fā)了 AI 框架設(shè)計(jì)靈感的諸多實(shí)驗(yàn)項(xiàng)目。TensorFlow 和 PyTorch 代表了現(xiàn)今 AI 框架框架的兩種不同的設(shè)計(jì)路徑:系統(tǒng)性能優(yōu)先改善靈活性,和靈活性易用性優(yōu)先改善系統(tǒng)性能。
這兩種選擇,隨著神經(jīng)網(wǎng)絡(luò)算法研究和應(yīng)用的更進(jìn)一步發(fā)展,又逐步造成了 AI 框架在具體技術(shù)實(shí)現(xiàn)方案的分裂。
第三代AI框架
在第三代 AI 框架中,面向通用化場(chǎng)景,如 CNN、LSTM、RNN 等場(chǎng)景開(kāi)始走向統(tǒng)一的設(shè)計(jì)架構(gòu),不同的AI框架在一定程度都會(huì)模仿或者參考 PyTorch 的動(dòng)態(tài)圖 Eager 模式,提升自身框架的易用性,使其更好地接入 AI 生態(tài)中。
目前在技術(shù)上一定程度開(kāi)始邁進(jìn)第三代AI框架,其主要面向設(shè)計(jì)特定領(lǐng)域語(yǔ)言(Domain-Specific Language,DSL)。最大的特性是:1)兼顧編程的靈活性和計(jì)算的高效性;2)提高描述神經(jīng)網(wǎng)絡(luò)算法表達(dá)能力和編程靈活性;3)通過(guò)編譯期優(yōu)化技術(shù)來(lái)改善運(yùn)行時(shí)性能。
具體面向不同的業(yè)務(wù)場(chǎng)景會(huì)有一些差異(即特定領(lǐng)域),如 JAX 是 Autograd 和 XLA 的結(jié)合,作為一個(gè)高性能的數(shù)值計(jì)算庫(kù),更是結(jié)合了可組合的函數(shù)轉(zhuǎn)換庫(kù),除了可用于AI場(chǎng)景的計(jì)算,更重要的是可以用于高性能機(jī)器學(xué)習(xí)研究。例如Taichi面向圖形圖像可微分編程,作為開(kāi)源并行計(jì)算框架,可以用于云原生的3D內(nèi)容創(chuàng)作。

AI框架的未來(lái)
應(yīng)對(duì)未來(lái)多樣化挑戰(zhàn),AI 框架有以下技術(shù)趨勢(shì):
全場(chǎng)景
AI 框架將支持端邊云全場(chǎng)景跨平臺(tái)設(shè)備部署
網(wǎng)絡(luò)模型需要適配部署到端邊云全場(chǎng)景設(shè)備,對(duì) AI 框架提出了多樣化、復(fù)雜化、碎片化的挑戰(zhàn)。隨著云服務(wù)器、邊緣設(shè)備、終端 設(shè)備等人工智能硬件運(yùn)算設(shè)備的不斷涌現(xiàn),以及各類人工智能運(yùn)算庫(kù)、中間表示工具以及編程框架的快速發(fā)展,人工智能軟硬件生態(tài)呈現(xiàn)多樣化發(fā)展趨勢(shì)。
但目前主流 AI 框架仍然分為訓(xùn)練部分和推理部分,兩者不完全兼容。訓(xùn)練出來(lái)的模型也不能通用,學(xué)術(shù)科研項(xiàng)目間難以合作延伸,造成了 AI 框架的碎片化。目前業(yè)界并沒(méi)有統(tǒng)一的中間表示層標(biāo)準(zhǔn),導(dǎo)致各硬件廠商解決方案存在一定差異,以致應(yīng)用模型遷移不暢,增加了應(yīng)用部署難度。因此,基于AI框架訓(xùn)練出來(lái)的模型進(jìn)行標(biāo)準(zhǔn)化互通將是未來(lái)的挑戰(zhàn)。
易用性
AI 框架將注重前端便捷性與后端高效性的統(tǒng)一
AI 框架需要提供更全面的 API 體系以及前端語(yǔ)言支持轉(zhuǎn)換能力,從而提升前端開(kāi)發(fā)便捷性。AI 框架需要能為開(kāi)發(fā)者提供完備度 高、性能優(yōu)異、易于理解和使用的 API 體系。
AI 框架需要提供更為優(yōu)質(zhì)的動(dòng)靜態(tài)圖轉(zhuǎn)換能力,從而提升后端運(yùn)行高效性。從開(kāi)發(fā)者使用 AI 框架來(lái)實(shí)現(xiàn)模型訓(xùn)練和推理部署的角度看,AI 框架需要能夠通過(guò)動(dòng)態(tài)圖的編程范式,來(lái)完成在模型訓(xùn)練的開(kāi)發(fā)階段的靈活易用的開(kāi)發(fā)體驗(yàn),以提升模型的開(kāi)發(fā)效率;通過(guò)靜態(tài)圖的方式來(lái)實(shí)現(xiàn)模型部署時(shí)的高性能運(yùn)行;同時(shí),通過(guò)動(dòng)態(tài)圖轉(zhuǎn)靜態(tài)圖的方式,來(lái)實(shí)現(xiàn)方便的部署和性能優(yōu)化。目前 PyTorch2.0 的圖編譯模式走在業(yè)界前列,不一定成為最終形態(tài),在性能和易用性方面的兼顧仍然有待進(jìn)一步探索。
大規(guī)模分布式
AI 框架將著力強(qiáng)化對(duì)超大規(guī)模 AI 的支持
OpenAI 于 2020 年 5 月發(fā)布 GPT-3 模型,包含 1750 億參數(shù),數(shù)據(jù)集(處理前)達(dá)到 45T, 在多項(xiàng) NLP 任務(wù)中超越了人類水平。隨之 Google 不斷跟進(jìn)分布式技術(shù),超大規(guī)模 AI 逐漸成為新的深度學(xué)習(xí)范式。
超大規(guī)模 AI 需要大模型、大數(shù)據(jù)、大算力的三重支持,對(duì) AI 框架也提出了新的挑戰(zhàn),
-
內(nèi)存:大模型訓(xùn)練過(guò)程中需要存儲(chǔ)參數(shù)、激活、梯度、優(yōu)化器狀態(tài),
-
算力:2000 億參數(shù)量的大模型為例,需要 3.6EFLOPS 的算力支持,必要構(gòu)建 AI 計(jì)算集群滿足算力需求
-
通信:大模型并行切分到集群后,模型切片之間會(huì)產(chǎn)生大量通信,從而通信就成了主要的瓶頸
-
調(diào)優(yōu):E 級(jí) AI 算力集群訓(xùn)練千億參數(shù)規(guī)模,節(jié)點(diǎn)間通信復(fù)雜,要保證計(jì)算正確性、性能和可用性,手動(dòng)調(diào)試難以全面兼顧,需要更自動(dòng)化的調(diào)試調(diào)優(yōu)手段
-
部署:超大規(guī)模 AI 面臨大模型、小推理部署難題,需要對(duì)大模型進(jìn)行完美壓 縮以適應(yīng)推理側(cè)的部署需求
科學(xué)計(jì)算
AI框架將進(jìn)一步與科學(xué)計(jì)算深度融合交叉
傳統(tǒng)科學(xué)計(jì)算領(lǐng)域亟需 AI 技術(shù)加持融合。計(jì)算圖形可微編程,類似Taichi這樣的語(yǔ)言和框架,提供可微物理引擎、可微渲染引擎等新功能。因此未來(lái)是一個(gè)AI與科學(xué)計(jì)算融合的時(shí)代,傳統(tǒng)的科學(xué)計(jì)算將會(huì)結(jié)合AI的方法去求解既定的問(wèn)題。至于AI與科學(xué)計(jì)算結(jié)合,看到業(yè)界在探索三個(gè)方向:
利用 AI 神經(jīng)網(wǎng)絡(luò)進(jìn)行建模替代傳統(tǒng)的計(jì)算模型或者數(shù)值模型,目前已經(jīng)有很大的進(jìn)展了,如拿了戈登貝爾獎(jiǎng)的分子動(dòng)力學(xué)模型DeepMD。
AI求解,模型還是傳統(tǒng)的科學(xué)計(jì)算模型,但是使用深度學(xué)習(xí)算法來(lái)求解,這個(gè)方向已經(jīng)有一定的探索,目前看到不少基礎(chǔ)的科學(xué)計(jì)算方程已經(jīng)有對(duì)應(yīng)的AI求解方法,比如PINNs、PINN-Net等,當(dāng)然現(xiàn)在挑戰(zhàn)還很大,特別是在精度收斂方面,如果要在AI框架上使用AI求解科學(xué)計(jì)算模型,最大的挑戰(zhàn)主要在前端表達(dá)和高性能的高階微分。
使用AI框架來(lái)加速方程的求解,科學(xué)計(jì)算的模型和方法都不變的前提下,與深度學(xué)習(xí)使用同一個(gè)框架來(lái)求解,其實(shí)就是把AI框架看成面向張量計(jì)算的通用分布式計(jì)算框架。
本節(jié)總結(jié)
-
本節(jié)內(nèi)容回顧了AI框架在時(shí)間維度和技術(shù)維度的發(fā)展趨勢(shì)
-
技術(shù)上初代AI框架解決AI編程問(wèn)題,第二代加速科研和產(chǎn)業(yè)落地,第三代結(jié)合特定領(lǐng)域語(yǔ)言和任務(wù)
-
一起學(xué)習(xí)了AI框架隨著的軟硬件的發(fā)展升級(jí)而共同發(fā)展,展望AI框架的未來(lái)





