擊這里在線咨詢客服")
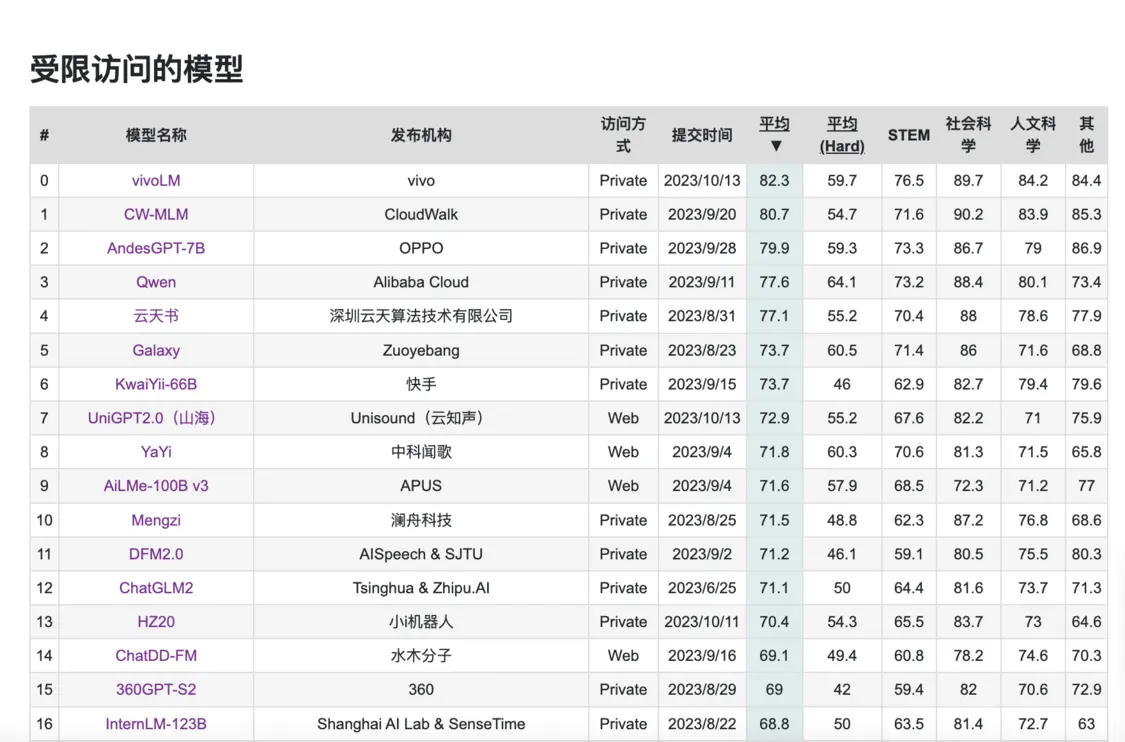
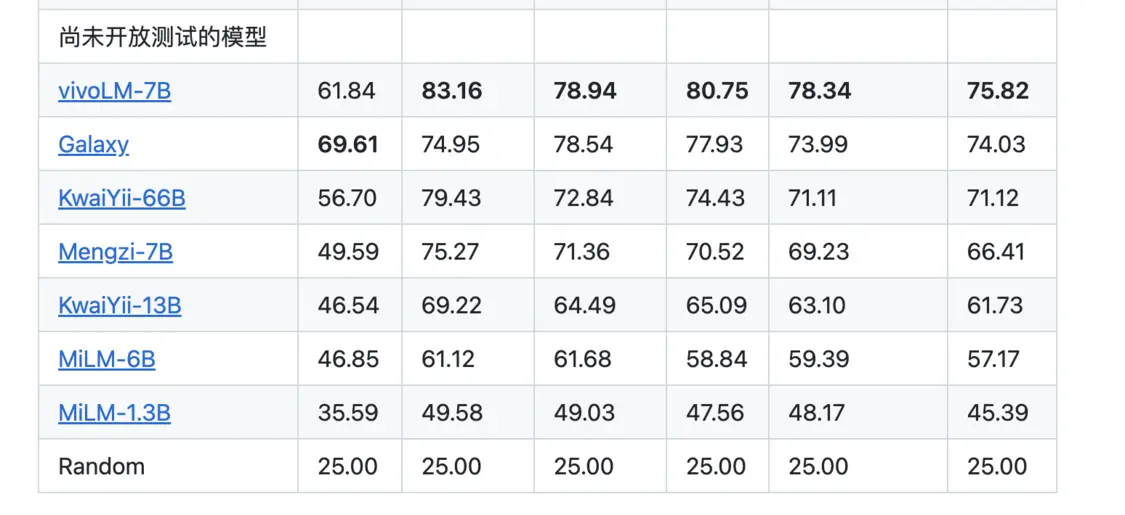
10月16日,C-Eval大模型評測榜單更新,榜單顯示,vivo自研大模型在C-Eval全球中文榜單中排名第一。vivo相關(guān)負(fù)責(zé)人透露,vivo自研AI大模型將會在即將發(fā)布的OriginOS 4系統(tǒng)中被首次應(yīng)用,其中包括十億、百億、千億三個(gè)不同參數(shù)量級的5款自研大模型,全面覆蓋核心應(yīng)用場景。
C-Eval榜單是由清華大學(xué)、上海交通大學(xué)和愛丁堡大學(xué)合作構(gòu)建的面向中文語言模型的綜合性考試評測集,涵蓋52個(gè)不同學(xué)科,共有13948道多項(xiàng)選擇題,是目前較為權(quán)威的中文AI大模型評測榜單。CMMLU數(shù)據(jù)集則是一個(gè)綜合性的中文評估基準(zhǔn),由MBZUAI、上海交通大學(xué)、微軟亞洲研究院共同推出,在評估語言模型在中文語境下的知識和推理能力方面極具權(quán)威性。
【來源:鳳凰網(wǎng)科技】





