

企業中一般存在「在線服務」和「離線任務」兩種類型工作負載。在降本增效的大背景下,如何通過技術為不同業務完成較為精準的資源配置成為企業制勝的法寶。然而,這并非一蹴而就,需要不斷的探索和實踐。
知乎在采用金山云在離線混部解決方案Colocation(以下簡稱“Colo”)前,就已嘗試多種優化IT資源成本的方法,例如根據數據指標手動或自動降低服務資源配置、潮汐調度等,直到選擇混部方案后,知乎才實現了更精確化的管理調度、更合理的資源隔離,以及更高效的運維效率。
本文將對知乎早期優化路徑進行簡要分析,并將重點置于Colo在知乎大數據場景混部中的具體使用方式,以及該方案為知乎帶來的價值。
知乎采用混部前的成本優化路徑
知乎的成本優化路徑經歷了早期和中期兩個階段,兩個階段的優化在當時背景下利用率有所提升,但最終都未能達到理想的效果。
早期階段:系統化資源利用提升
在進行系統化資源利用提升前,需要通過建立的完善的數據指標和應用指標系統,通知業務方自動或主動降低資源配置。在早期資源利用率不合理的場景下,該方案是一種直接高效的資源優化手段,但其屬于被動式的處理手段,并不能做到資源的最優配置。(如下圖)

中期階段:潮汐調度
與離線任務相比,在線業務具有明顯的波峰波谷,可利用潮汐調度來實現資源的優化配置。利用K8s的VPA(Vertical Pod Autoscaler)、HPA(Horizontal Pod Autoscaler)組件,可在低峰和高峰時分別為工作負載進行縮容和擴容。同時利用K8s的CA調度器(Cluster Autoscaler)實現基于pod的擴縮,而在集群容量不足時擴容新的node節點。(如下圖)

存在的問題:
盡管以上兩個階段均在一定程度上提升了資源利用率,但在這兩個階段中知乎離線集群與在線集群完全獨立不互通,離線集群和在線集群的資源利用率均存在明顯的周期性波動,具有明顯的潮汐效應。
離線集群在凌晨0點至8點之間的資源利用率達到95%以上,處于滿負荷運行狀態,而在線集群同期內的資源利用率會下降至30%以下。這種周期性變化使得離線集群凌晨資源存在短缺,在線集群資源利用率嚴重不足,集群整體平均利用率在27%-30%左右。
現階段知乎大數據場景采用Colo實現在離線業務混部后
現階段,知乎大數據場景多集群打通了在線集群與離線集群的互聯互通。離線任務調度平臺提交任務到YARN Federation中的YARN Router節點,Router節點連接決策服務,決策服務依據任務畫像和其他邊界條件確定的規則,最終將符合規則的低優離線任務運行至在線集群中,實現在離線混部調度。(如下圖)
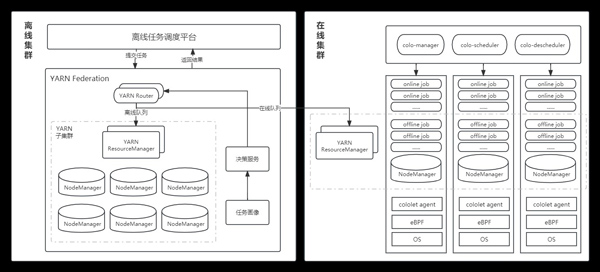
知乎大數據場景低優離線任務調度至在線集群后,在線集群中在離線業務的混部通過Colo管理與調度,Colo通過調度與重調度能力、CPU/Memory/BLKIO/網絡帶寬等資源隔離及資源動態調整壓制、資源沖突檢測與處理、實際負載感知調度能力、eBPF關鍵內核指標的采集和利用等關鍵技術,保證了在離線混部節點間均衡調度、節點不過載、在線服務穩定性、敏感型業務不受干擾、離線資源及時回收等問題。Colo通過Colo-manager、Colo-scheduler、Colo-Descheduler、cololet等組件,采取削峰填谷的方式,提高在線集群資源利用率,降低離線集群在夜間的超負荷運轉狀況,實現服務器資源利用率大幅提升,從而減少了企業IT開支。(Colo架構如下圖)

Colo在知乎大數據場景混部中的具體使用方式:
使用Colo調度系統進行在離線業務混部時,根據不同業務場景可通過配置Colo的Priority(優先級)與QoS(服務質量)的關鍵字段字段進行部署。在知乎大數據場景混部的應用中,Colo將業務做多個分級,優先保障高級別業務。具體如下:
數據庫/消息隊列等中間件服務:單獨處理,不參與混部
LSR類(Priority:colo-prod + QoS:LSR):知乎較高敏感型在線服務,可以接受犧牲資源彈性而換取更好的確定性(如CPU綁核),對應用時延要求極高。QOS對應Guarantee
LS類(Priority:colo-prod + QoS:LS):知乎典型的在線服務,通常對應用的延遲、資源質量要求較高,運行時間較長,也需要保證一定的資源彈性能力。QOS對應Burstable
BE類(Priority:colo-batch + QoS:BE):知乎混部場景中的低優離線任務,通常表現為對資源質量有相當的忍耐度,對延遲不敏感,運行時間相對較短。QOS對應BestEffort
知乎大數據場景混部方案Colo的落地價值:
在離線混部方案Colo已在知乎大數據場景下完成大規模核心業務落地,部署節點數量超過3000多個。不僅實現了知乎多個集群全天資源利用率均值的大幅提升,白天實時利用率也保持在一個較高的水平,且服務器節點之間的負載均衡也得到了明顯改善。






