
這篇博文中提出的建議并不新鮮。事實上許多組織已經(jīng)投入了數(shù)年時間和昂貴的數(shù)據(jù)工程團(tuán)隊的工作,以慢慢構(gòu)建這種架構(gòu)的某個版本。我知道這一點,因為我以前在Uber和LinkedIn做過這樣的工程師。我還與數(shù)百個組織合作,在開源社區(qū)中構(gòu)建它并朝著類似的目標(biāo)邁進(jìn)。
早在 2011 年 LinkedIn 上,我們就開始使用專有數(shù)據(jù)倉庫[1]。隨著像“你可能認(rèn)識的人[2]”這樣的數(shù)據(jù)科學(xué)/機器學(xué)習(xí)應(yīng)用程序的構(gòu)建,我們穩(wěn)步轉(zhuǎn)向Apache Avro上的數(shù)據(jù)湖[3],Apache Pig可以訪問MapReduce作為分析、報告、機器學(xué)習(xí)和數(shù)據(jù)應(yīng)用程序的事實來源。幾年后,我們在Uber[4]也面臨著同樣的挑戰(zhàn),這一次是交易數(shù)據(jù)和真正的實時業(yè)務(wù),天氣或交通可以立即影響定價或預(yù)計到達(dá)時間。我們通過構(gòu)建 Apache Hudi 構(gòu)建了一個事務(wù)性數(shù)據(jù)湖,作為 Parquet、Presto、Spark、Flink 和 Hive 上所有數(shù)據(jù)的入口點,然后它甚至在那個術(shù)語被創(chuàng)造出來之前就提供了世界上第一個數(shù)據(jù)湖倉一體。
如今企業(yè)面臨的架構(gòu)挑戰(zhàn)不是選擇一種正確的格式或計算引擎。主要的格式和引擎可能會隨著時間的推移而變化,但這種底層數(shù)據(jù)架構(gòu)經(jīng)受住了時間的考驗,因為它在各種用例中具有通用性,允許用戶為每個用例選擇正確的選擇。這篇博文敦促讀者主動考慮將這種不可避免的架構(gòu)作為組織數(shù)據(jù)戰(zhàn)略的基礎(chǔ)。
云數(shù)據(jù)架構(gòu)被打破
根據(jù)我的經(jīng)驗,一個組織的云數(shù)據(jù)之旅遵循今天熟悉的情節(jié)。獎?wù)录軜?gòu)[5]提供了一種很好的方法來概念化這一點,因為數(shù)據(jù)會針對不同的用例進(jìn)行轉(zhuǎn)換。典型的“現(xiàn)代數(shù)據(jù)棧”是通過使用點對點數(shù)據(jù)集成工具將操作數(shù)據(jù)復(fù)制到云數(shù)據(jù)倉庫上的“青銅”層而誕生的。然后這些數(shù)據(jù)隨后被清理,質(zhì)量審核,并準(zhǔn)備成“銀”層。然后,一組批處理 ETL 作業(yè)將這些銀數(shù)據(jù)轉(zhuǎn)換為事實、維度和其他模型,最終創(chuàng)建一個“黃金”數(shù)據(jù)層,為分析和報告提供支持。
組織也在探索新的用例,例如機器學(xué)習(xí)、數(shù)據(jù)科學(xué)和新興的 AI/LLM應(yīng)用程序。這些用例通常需要大量數(shù)據(jù),因此團(tuán)隊將添加新的數(shù)據(jù)源,如事件流(例如點擊流事件、GPS 日志等),其規(guī)模是現(xiàn)有數(shù)據(jù)庫復(fù)制規(guī)模的 10-100 倍。
支持高吞吐量事件數(shù)據(jù)引入了對廉價云存儲和數(shù)據(jù)湖的大規(guī)模水平計算可擴展性的需求。但是,雖然數(shù)據(jù)湖支持僅追加工作負(fù)載(無合并),但它幾乎不支持處理數(shù)據(jù)庫復(fù)制。當(dāng)涉及到高吞吐量的可變數(shù)據(jù)流(如 NoSQL 存儲、文檔存儲或新時代的關(guān)系數(shù)據(jù)庫)時,當(dāng)前的數(shù)據(jù)基礎(chǔ)架構(gòu)系統(tǒng)都沒有足夠的支持。
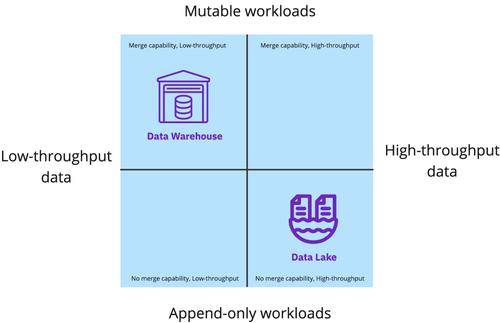
由于每種方法都有特定于某些工作負(fù)載類型的優(yōu)勢,因此組織最終會同時維護(hù)數(shù)據(jù)倉庫和數(shù)據(jù)湖。為了在源之間整合數(shù)據(jù),它們將定期在數(shù)據(jù)倉庫和數(shù)據(jù)湖之間復(fù)制數(shù)據(jù)。數(shù)據(jù)倉庫具有快速查詢功能,可服務(wù)于商業(yè)智能 (BI) 和報告用例,而數(shù)據(jù)湖支持非結(jié)構(gòu)化存儲和低成本計算,可服務(wù)于數(shù)據(jù)工程、數(shù)據(jù)科學(xué)和機器學(xué)習(xí)用例。
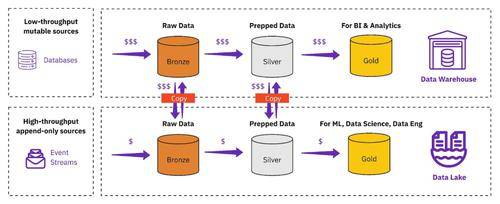
維持如圖 2 所示的架構(gòu)具有挑戰(zhàn)性、成本高昂且容易出錯。在湖和倉庫之間定期復(fù)制數(shù)據(jù)會導(dǎo)致數(shù)據(jù)過時且不一致。治理成為所有相關(guān)人員頭疼的問題,因為訪問控制在系統(tǒng)之間是分散的,并且必須在數(shù)據(jù)的多個副本上管理數(shù)據(jù)刪除(GDPR)。更不用說團(tuán)隊對這些不同的管道中的每一個都處于困境,所有權(quán)很快就會變得模糊不清。這給組織帶來了以下挑戰(zhàn):
o• 供應(yīng)商鎖定:高價值運營數(shù)據(jù)的真實來源通常是專有數(shù)據(jù)倉庫,這會創(chuàng)建鎖定點。
o• 昂貴的引入和數(shù)據(jù)準(zhǔn)備:雖然數(shù)據(jù)倉庫為可變數(shù)據(jù)提供了合并功能,但對于上游數(shù)據(jù)庫或流數(shù)據(jù)的快速增量數(shù)據(jù)引入,它們的性能很差。倉庫中針對黃金層計算進(jìn)行了優(yōu)化的昂貴高級計算引擎,例如針對星型架構(gòu)優(yōu)化的 SQL 引擎,甚至用于青銅層(數(shù)據(jù)引入)層和銀牌(數(shù)據(jù)準(zhǔn)備)層,它們不會增加價值。隨著組織規(guī)模的擴大,這通常會導(dǎo)致青銅層和銀層的成本不斷膨脹。
o• 浪費的數(shù)據(jù)復(fù)制:隨著新用例的出現(xiàn),組織會重復(fù)他們的工作,在用例中跨冗余的銅牌和銀牌層浪費存儲和計算資源。例如,引入/復(fù)制相同的數(shù)據(jù)一次用于分析,一次用于數(shù)據(jù)科學(xué),浪費了工程和云資源。考慮到組織還預(yù)配多個環(huán)境(如開發(fā)、暫存和生產(chǎn)),整個基礎(chǔ)架構(gòu)的復(fù)合成本可能令人震驚。此外,GDPR、CCPA 和數(shù)據(jù)優(yōu)化等合規(guī)性法規(guī)的執(zhí)行成本在通過不同入口點流入的相同數(shù)據(jù)的多個副本中多次產(chǎn)生。
o• 數(shù)據(jù)質(zhì)量差:單個團(tuán)隊經(jīng)常重新設(shè)計基礎(chǔ)數(shù)據(jù)基礎(chǔ)架構(gòu),以便以零碎的方式攝取、優(yōu)化和準(zhǔn)備數(shù)據(jù)。由于缺乏資源,這些努力令人沮喪地減慢了投資回報率或完全失敗,使整個組織的數(shù)據(jù)質(zhì)量面臨風(fēng)險,因為數(shù)據(jù)質(zhì)量的強弱取決于最薄弱的數(shù)據(jù)管道。
數(shù)據(jù)湖倉一體興起
在我領(lǐng)導(dǎo) Uber 數(shù)據(jù)平臺團(tuán)隊期間親身感受到了這種破碎架構(gòu)的痛苦。在湖和倉庫之間復(fù)制數(shù)據(jù)的大型、緩慢的批處理作業(yè)將數(shù)據(jù)延遲到 24 小時以上,這減慢了我們的整個業(yè)務(wù)速度。最終隨著業(yè)務(wù)的增長,架構(gòu)無法有效擴展,我們需要一個更好的解決方案,可以增量處理數(shù)據(jù)。
2016 年,我和我的團(tuán)隊創(chuàng)建了 Apache Hudi,它最終使我們能夠?qū)?shù)據(jù)湖的低成本、高吞吐量存儲和計算與倉庫的合并功能相結(jié)合。數(shù)據(jù)湖倉一體(或我們當(dāng)時稱之為事務(wù)性數(shù)據(jù)湖)誕生了。
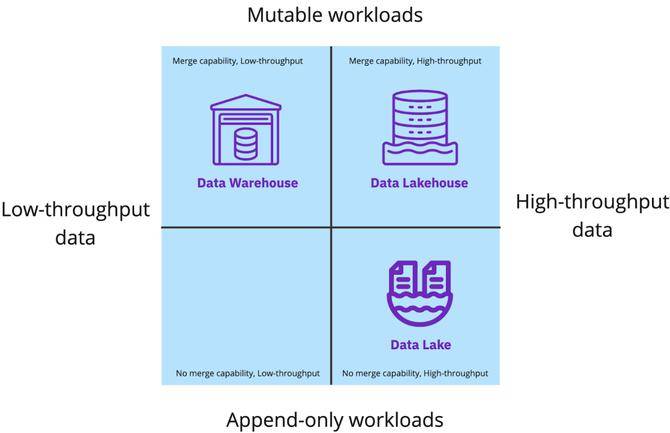
數(shù)據(jù)湖倉一體為云存儲中的數(shù)據(jù)湖添加了事務(wù)層,使其具有類似于數(shù)據(jù)倉庫的功能,同時保持了數(shù)據(jù)湖的可擴展性和成本狀況。現(xiàn)在可以使用強大的功能,例如支持使用主鍵的更新插入和刪除的可變數(shù)據(jù)、ACID 事務(wù)、通過數(shù)據(jù)聚類和小文件處理進(jìn)行快速讀取的優(yōu)化、表回滾等。
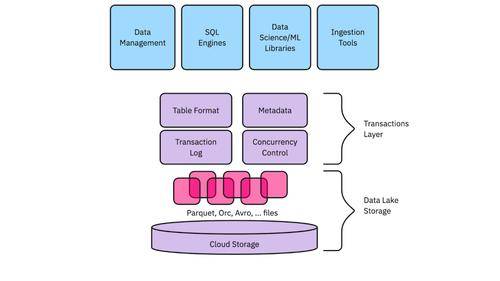
最重要的是它最終使將所有數(shù)據(jù)存儲在一個中心層中成為可能。數(shù)據(jù)湖倉一體能夠存儲以前存在于倉庫和湖中的所有數(shù)據(jù),無需維護(hù)多個數(shù)據(jù)副本。在Uber這意味著我們可以毫不拖延地運行欺詐模型,實現(xiàn)當(dāng)日向司機付款。我們可以跟蹤最新的交通情況,甚至天氣模式,以實時更新預(yù)計到達(dá)時間的預(yù)測。
然而實現(xiàn)如此強大的結(jié)果不僅僅是選擇表格格式或編寫作業(yè)或 SQL 的練習(xí);它需要一個平衡良好、經(jīng)過深思熟慮的數(shù)據(jù)架構(gòu)模式,并考慮到未來。我將這種架構(gòu)稱為“通用數(shù)據(jù)湖倉一體”。
通用數(shù)據(jù)湖倉一體架構(gòu)
通用數(shù)據(jù)湖倉一體架構(gòu)將數(shù)據(jù)湖倉一體置于數(shù)據(jù)基礎(chǔ)架構(gòu)的中心提供快速、開放且易于管理的商業(yè)智能、數(shù)據(jù)科學(xué)等事實來源。
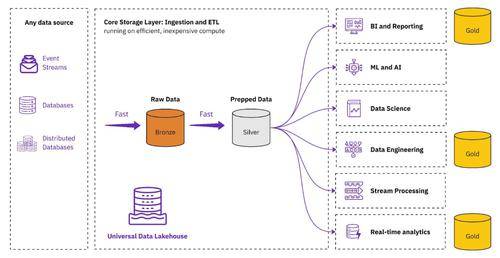
通過采用通用數(shù)據(jù)湖倉一體架構(gòu),組織可以克服以前無法克服的脫節(jié)架構(gòu)的挑戰(zhàn),該架構(gòu)在湖和倉庫之間不斷復(fù)制數(shù)據(jù)。數(shù)以千計同時使用數(shù)據(jù)湖和數(shù)據(jù)倉庫的組織可以通過采用此架構(gòu)獲得以下好處:
統(tǒng)一數(shù)據(jù)
通用數(shù)據(jù)湖倉一體體系結(jié)構(gòu)使用數(shù)據(jù)湖倉一體作為組織云帳戶中的事實來源,并以開源格式存儲數(shù)據(jù)。此外湖倉一體可以處理復(fù)雜的分布式數(shù)據(jù)庫的規(guī)模,而這些數(shù)據(jù)庫以前對于數(shù)據(jù)倉庫來說過于繁瑣。
確保數(shù)據(jù)質(zhì)量
這個通用數(shù)據(jù)層在數(shù)據(jù)流中提供了一個方便的入口點,用于執(zhí)行數(shù)據(jù)質(zhì)量檢查、對半結(jié)構(gòu)化數(shù)據(jù)進(jìn)行架構(gòu)化以及在數(shù)據(jù)生產(chǎn)者和使用者之間強制執(zhí)行任何數(shù)據(jù)協(xié)定。數(shù)據(jù)質(zhì)量問題可以在青銅層和銀層中得到遏制和糾正,從而確保下游表始終建立在新鮮的高質(zhì)量數(shù)據(jù)之上。這種數(shù)據(jù)流的簡化簡化了體系結(jié)構(gòu),通過將工作負(fù)載遷移到經(jīng)濟高效的計算來降低成本,并消除了數(shù)據(jù)刪除等重復(fù)的合規(guī)性工作。
降低成本
由于來自數(shù)據(jù)庫的操作數(shù)據(jù)和大規(guī)模事件數(shù)據(jù)都在單個青銅層和銀層中存儲和處理,因此引入和數(shù)據(jù)準(zhǔn)備可以在低成本計算上運行一次。我們已經(jīng)看到了令人印象深刻的例子,通過將 ELT 工作負(fù)載遷移到數(shù)據(jù)湖倉一體上的此架構(gòu),云數(shù)據(jù)倉庫成本節(jié)省了數(shù)百萬美元。以開放格式保存數(shù)據(jù),可以在所有三個層中分?jǐn)偹袛?shù)據(jù)優(yōu)化和管理成本,從而為數(shù)據(jù)平臺節(jié)省大量成本。
更快的性能
通用數(shù)據(jù)湖倉一體通過兩種方式提高性能。首先它專為可變數(shù)據(jù)而設(shè)計,可快速攝取來自變更數(shù)據(jù)捕獲 (CDC)、流數(shù)據(jù)和其他來源的更新。其次它打開了一扇門,將工作負(fù)載從大型臃腫的批處理轉(zhuǎn)移到增量模型,以提高速度和效率。Uber 通過使用 Hudi 進(jìn)行增量 ETL,節(jié)省了 ~80% 的總體計算成本。它們同時提高了性能、數(shù)據(jù)質(zhì)量和可觀測性。
讓客戶自由選擇計算引擎
與十年前不同,今天的數(shù)據(jù)需求并不止于傳統(tǒng)的分析和報告。數(shù)據(jù)科學(xué)、機器學(xué)習(xí)和流數(shù)據(jù)是財富 500 強公司和初創(chuàng)公司的主流和無處不在。新興的數(shù)據(jù)用例(如深度學(xué)習(xí))LLMs正在帶來各種新的計算引擎,這些引擎具有針對每個工作負(fù)載獨立優(yōu)化的卓越性能/體驗。預(yù)先選擇一個倉庫或湖引擎的傳統(tǒng)做法拋棄了云提供的所有優(yōu)勢;借助通用數(shù)據(jù)湖倉一體可以輕松地為每個用例按需啟動合適的計算引擎。
通用數(shù)據(jù)湖倉一體架構(gòu)使數(shù)據(jù)可以跨所有主要數(shù)據(jù)倉庫和數(shù)據(jù)湖查詢引擎進(jìn)行訪問,并與任何目錄集成,這與之前將數(shù)據(jù)存儲與一個計算引擎相結(jié)合的方法發(fā)生了重大轉(zhuǎn)變。這種架構(gòu)能夠使用最適合每個獨特工作的引擎,在BI和報告、機器學(xué)習(xí)、數(shù)據(jù)科學(xué)和無數(shù)更多用例中無縫構(gòu)建專門的下游“黃金”層。例如 Spark 非常適合數(shù)據(jù)科學(xué)工作負(fù)載,而數(shù)據(jù)倉庫則經(jīng)過傳統(tǒng)分析和報告的實戰(zhàn)考驗。除了技術(shù)差異之外,定價和向開源的轉(zhuǎn)變在組織采用計算引擎的過程中起著至關(guān)重要的作用。
例如沃爾瑪在 Apache Hudi 上構(gòu)建了他們的湖倉一體,確保他們可以通過以開源格式存儲數(shù)據(jù)來輕松利用新技術(shù)。他們使用通用數(shù)據(jù)湖倉一體架構(gòu),使數(shù)據(jù)使用者能夠使用各種技術(shù)(包括 Hive 和 Spark、Presto 和 Trino、BigQuery 和 Flink)查詢湖倉一體。
奪回數(shù)據(jù)的所有權(quán)
所有真實數(shù)據(jù)源數(shù)據(jù)都以開源格式保存在組織云存儲桶的青銅層和銀層中。
數(shù)據(jù)的可訪問性不是由供應(yīng)商鎖定的不透明第三方系統(tǒng)決定。這種架構(gòu)能夠靈活地在組織的云網(wǎng)絡(luò)內(nèi)(而不是在供應(yīng)商的帳戶中)運行數(shù)據(jù)服務(wù),以加強安全性并支持高度監(jiān)管的環(huán)境。
此外可以自由地使用開放數(shù)據(jù)服務(wù)或購買托管服務(wù)來管理數(shù)據(jù),從而避免數(shù)據(jù)服務(wù)的鎖定點。
簡化訪問控制
由于數(shù)據(jù)使用者在湖倉一體中對青銅和白銀數(shù)據(jù)的單個副本進(jìn)行操作,訪問控制變得更加易于管理和實施。數(shù)據(jù)沿襲已明確定義,團(tuán)隊不再需要跨多個不相交的系統(tǒng)和數(shù)據(jù)副本管理單獨的權(quán)限。
為工作負(fù)載選擇合適的技術(shù)
雖然通用數(shù)據(jù)湖倉一體架構(gòu)非常有前途,但一些關(guān)鍵技術(shù)選擇對于在實踐中實現(xiàn)其優(yōu)勢至關(guān)重要。
當(dāng)務(wù)之急是盡快在銀層提供攝取的數(shù)據(jù),因為任何延遲現(xiàn)在都會阻礙多個用例。為了實現(xiàn)數(shù)據(jù)新鮮度和效率的組合,組織應(yīng)選擇非常適合流式處理和增量處理的數(shù)據(jù)湖倉一體技術(shù)。這有助于處理棘手的寫入模式,例如在青銅層引入期間的隨機寫入,以及利用更改流以增量方式更新銀牌表,而無需一次又一次地重新處理青銅層。
雖然我可能持有一些偏見,但我和我的團(tuán)隊圍繞這些通用數(shù)據(jù)湖倉一體原則構(gòu)建了 Apache Hudi。Hudi 經(jīng)過實戰(zhàn)考驗,通常被認(rèn)為是最適合這些工作負(fù)載的,同時還提供豐富的開放數(shù)據(jù)服務(wù)層,以保留構(gòu)建與購買的可選性。此外 Hudi 在數(shù)據(jù)湖之上解鎖了流數(shù)據(jù)處理模型,以大幅減少運行時間和傳統(tǒng)批處理 ETL 作業(yè)的成本。我相信在未來的道路上通用數(shù)據(jù)湖倉一體架構(gòu)也可以建立在為這些需求提供類似或更好的支持的未來技術(shù)之上。
最后 .NETable 是通用數(shù)據(jù)湖倉一體架構(gòu)的另一個構(gòu)建塊。它通過簡單的目錄集成實現(xiàn)了跨主要湖倉一體表格式(Apache Hudi、Apache Iceberg 和 Delta Lake)的互操作性,允許跨計算引擎自由設(shè)置數(shù)據(jù),并以不同格式構(gòu)建下游黃金層。這些好處已經(jīng)得到了沃爾瑪[6]等財富 10 強企業(yè)的驗證。
下一步
在這篇博客中介紹了通用數(shù)據(jù)湖倉一體作為構(gòu)建云數(shù)據(jù)基礎(chǔ)設(shè)施的新方式。在此過程中我們只是給數(shù)百家組織(包括通用電氣、TikTok、亞馬遜和沃爾瑪、迪士尼、Twilio、Robinhood、Zoom 等大型企業(yè))使用數(shù)據(jù)湖倉一體技術(shù)(如 Apache Hudi)構(gòu)建的數(shù)據(jù)架構(gòu)并概述了這些架構(gòu)。這種方法比許多公司目前維護(hù)的混合架構(gòu)更簡單、更快速、成本更低。它實現(xiàn)了存儲和計算的真正分離,同時支持在數(shù)據(jù)中使用同類計算引擎的實用方法。在未來幾年我們相信在對數(shù)據(jù)的需求不斷增長的推動下,它只會越來越受歡迎,包括 ML 和 AI 的增長、云成本的上升、復(fù)雜性的增加以及對數(shù)據(jù)團(tuán)隊的需求不斷增加。
雖然我堅信“在相同數(shù)據(jù)上為正確的工作負(fù)載提供正確的引擎”原則,但今天以客觀和科學(xué)的方式做出這一選擇并非易事。這是由于缺乏標(biāo)準(zhǔn)化的功能比較和基準(zhǔn)測試、缺乏對關(guān)鍵工作負(fù)載的共同理解以及其他因素。在本系列的后續(xù)博客文章中,我們將分享 Universal Data Lakehouse 如何跨數(shù)據(jù)傳輸模式(批處理、CDC 和流式處理)工作,以及它如何以“更好地協(xié)同工作”的方式與不同的計算引擎(如 Amazon Redshift、Snowflake、BigQuery 和 Databricks)協(xié)同工作。
Onehouse 提供的托管云服務(wù)提供交鑰匙體驗以構(gòu)建本博客中概述的通用數(shù)據(jù)湖倉一體架構(gòu)。像 Apna 這樣的用戶已經(jīng)將數(shù)據(jù)新鮮度從幾小時提高到幾分鐘,并通過削減他們的數(shù)據(jù)集成工具并用 Onehouse 取代倉庫來存儲他們的青銅和白銀數(shù)據(jù),從而顯著降低了成本。借助通用數(shù)據(jù)湖倉一體架構(gòu),他們的分析師可以繼續(xù)使用倉庫對湖倉一體中存儲的數(shù)據(jù)進(jìn)行查詢。





